Před několika týdny byl tým SQLskills v Tampě na naší akci Performance Tuning Immersion Event (IE2) a já jsem pokrýval základní linie. Základní linie je téma, které je mému srdci blízké a drahé, protože je z mnoha důvodů tak cenné. Dva z těchto důvodů, které vždy zmiňuji, ať už vyučuji nebo pracuji s klienty, jsou používání základních linií k řešení problémů s výkonem a pak také trendy využití a poskytování odhadů plánování kapacity. Ale jsou také nezbytné, když provádíte ladění nebo testování výkonu – ať už považujete své stávající metriky výkonu za základní hodnoty, nebo ne.
Během modulu jsem zkontroloval různé zdroje dat, jako je Performance Monitor, DMV a data trasování nebo XE, a objevila se otázka týkající se zatížení dat. Konkrétně šlo o to, zda je lepší načíst data do tabulky bez indexů a poté je po dokončení vytvořit, než mít indexy na místě během načítání dat. Moje odpověď byla:„Obvykle ano“. Moje osobní zkušenost byla taková, že to tak je vždy, ale nikdy nevíte, na jaké varování nebo jednorázový scénář může někdo narazit, když změna výkonu není taková, jaká byla očekávána, a jako všechny otázky týkající se výkonu nevíte s jistotou, dokud to neotestujete. Dokud si pro jednu metodu nestanovíte základní linii a pak neuvidíte, zda se druhá metoda oproti této základní linii zlepší, budete pouze hádat. Myslel jsem, že by bylo zábavné testovat tento scénář nejen dokázat, co očekávám, že je pravda, ale také ukázat, jaké metriky bych zkoumal, proč a jak je zachytit. Pokud jste již dříve testovali výkon, je to pravděpodobně starý klobouk. Ale pro ty. z vás nových v této praxi projdu procesem, který následuji, abych vám pomohl začít. Uvědomte si, že existuje mnoho způsobů, jak odvodit odpověď na otázku:„Která metoda je lepší?“ Očekávám, že tento proces převezmete, upravíte a časem si jej přizpůsobíte.
Co se snažíte dokázat?
Prvním krokem je rozhodnout se, co přesně testujete. V našem případě je to přímočaré:je rychlejší načíst data do prázdné tabulky a poté přidat indexy, nebo je rychlejší mít indexy v tabulce během načítání dat? Ale pokud chceme, můžeme zde přidat nějakou variaci. Zvažte čas potřebný k načtení dat do hromady a pak vytvoření seskupených a neseskupených indexů oproti času, který zabere načtení dat do seskupeného indexu, a poté vytvoření neklastrovaných indexů. Je rozdíl ve výkonu? Byl by faktor shlukování klíč? Očekávám, že zatížení dat způsobí fragmentaci existujících indexů bez klastrů, takže možná chci vidět, jaký dopad má přestavba indexů po zatížení na celkovou dobu trvání. Je důležité tento krok co nejvíce pojmout a být velmi konkrétní, co chcete měřit, protože to určí, jaká data zachytíte. V našem příkladu budou naše čtyři testy:
Test 1: Načtěte data do hromady, vytvořte seskupený index, vytvořte neklastrované indexy
Test 2: Načtěte data do seskupeného indexu, vytvořte neklastrované indexy
Test 3: Vytvořte seskupený index a neklastrované indexy, načtěte data
Test 4: Vytvořte seskupený index a neklastrované indexy, načtěte data, znovu sestavte neklastrované indexy
Co potřebujete vědět?
V našem scénáři je naší primární otázkou „jaká metoda je nejrychlejší“? Proto chceme měřit trvání a k tomu potřebujeme zachytit čas začátku a čas konce. Mohli bychom to tak nechat, ale možná budeme chtít porozumět tomu, jak vypadá využití zdrojů pro jednotlivé metody, nebo možná budeme chtít znát nejvyšší čekání, počet transakcí nebo počet uváznutí. Data, která jsou nejzajímavější a nejrelevantnější, budou záviset na tom, jaké procesy porovnáváte. Zachycení počtu transakcí není pro naši datovou zátěž až tak zajímavé; ale pro změnu kódu to může být. Protože vytváříme indexy a přestavujeme je, zajímá mě, kolik IO generuje každá metoda. I když je nakonec pravděpodobně rozhodujícím faktorem celková doba trvání, pohled na IO může být užitečný nejen k tomu, abyste pochopili, která možnost generuje nejvíce IO, ale také k tomu, zda úložiště databáze funguje podle očekávání.
Kde jsou data, která potřebujete?
Jakmile určíte, jaká data potřebujete, rozhodněte se, odkud budou zachycena. Zajímá nás trvání, takže chceme zaznamenat čas, kdy každý test zatížení dat začíná a kdy končí. Zajímá nás také IO a můžeme tato data čerpat z více míst – na mysl přicházejí čítače Performance Monitor a sys.dm_io_virtual_file_stats DMV.
Pochopte, že tato data můžeme získat ručně. Než spustíme test, můžeme vybrat proti sys.dm_io_virtual_file_stats a uložit aktuální hodnoty do souboru. Můžeme si poznamenat čas a pak spustit test. Po dokončení si znovu zaznamenáme čas, znovu se zeptáme sys.dm_io_virtual_file_stats a vypočítáme rozdíly mezi hodnotami pro měření IO.
V této metodice je řada nedostatků, konkrétně to, že ponechává značný prostor pro chyby; co když si zapomenete poznamenat čas zahájení nebo zapomenete zachytit statistiky souboru, než začnete? Mnohem lepším řešením je automatizovat nejen provádění skriptu, ale také sběr dat. Můžeme například vytvořit tabulku, která obsahuje informace o našem testu – popis toho, co test je, kdy začal a kdy skončil. Statistiky souborů můžeme zahrnout do stejné tabulky. Pokud shromažďujeme další metriky, můžeme je přidat do tabulky. Nebo může být snazší vytvořit samostatnou tabulku pro každou sadu dat, kterou zachytíme. Pokud například ukládáme statistická data souborů do jiné tabulky, musíme každému testu přidělit jedinečné ID, abychom mohli náš test porovnat se správnými statistickými daty souboru. Při zachycování statistik souborů musíme zachytit hodnoty pro naši databázi předtím, než začneme, a poté poté, a vypočítat rozdíl. Tyto informace pak můžeme uložit do vlastní tabulky spolu s jedinečným ID testu.
Ukázkové cvičení
Pro tento test jsem vytvořil prázdnou kopii tabulky Sales.SalesOrderHeader s názvem Sales.Big_SalesOrderHeader a použil jsem variantu skriptu, který jsem použil ve svém rozdělovacím příspěvku k načtení dat do tabulky v dávkách přibližně 25 000 řádků. Zde si můžete stáhnout skript pro načítání dat. Spustil jsem to čtyřikrát pro každou variaci a také jsem měnil celkový počet vložených řádků. Pro první sadu testů jsem vložil 20 milionů řádků a pro druhou sadu jsem vložil 60 milionů řádků. Údaje o trvání nejsou překvapivé:
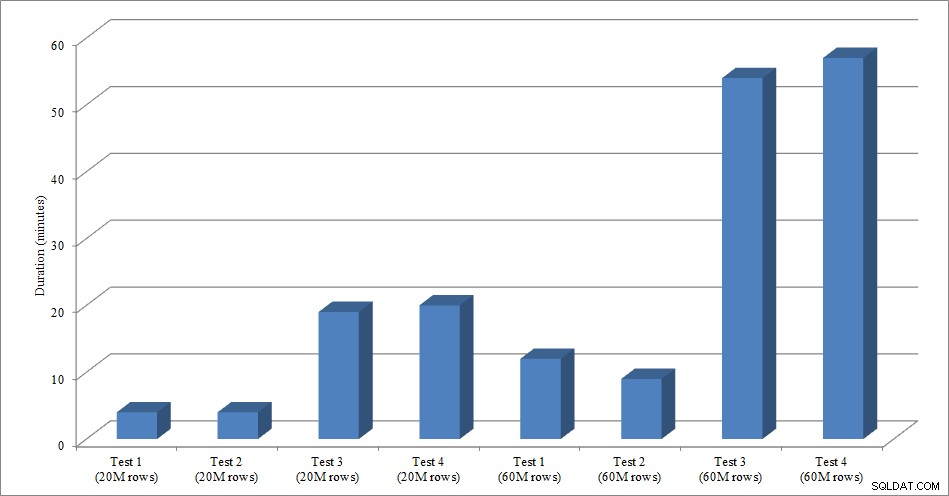
Trvání načítání dat
Načítání dat bez neklastrovaných indexů je mnohem rychlejší než načítání s již zavedenými neklastrovanými indexy. Zajímavé je, že pro načtení 20 milionů řádků bylo celkové trvání mezi Testem 1 a Testem 2 přibližně stejné, ale Test 2 byl rychlejší při načítání 60 milionů řádků. V našem testu byl naším shlukovacím klíčem SalesOrderID, což je identita, a proto dobrý shlukovací klíč pro naši zátěž, protože je vzestupná. Pokud bychom místo toho měli shlukovací klíč, který byl GUID, mohla by být doba načítání vyšší kvůli náhodným vkládáním a rozdělením stránek (další varianta, kterou bychom mohli otestovat).
Napodobují data IO trend v datech trvání? Ano, s rozdíly, zda jsou indexy již na místě, nebo ne, ještě více přehnané:
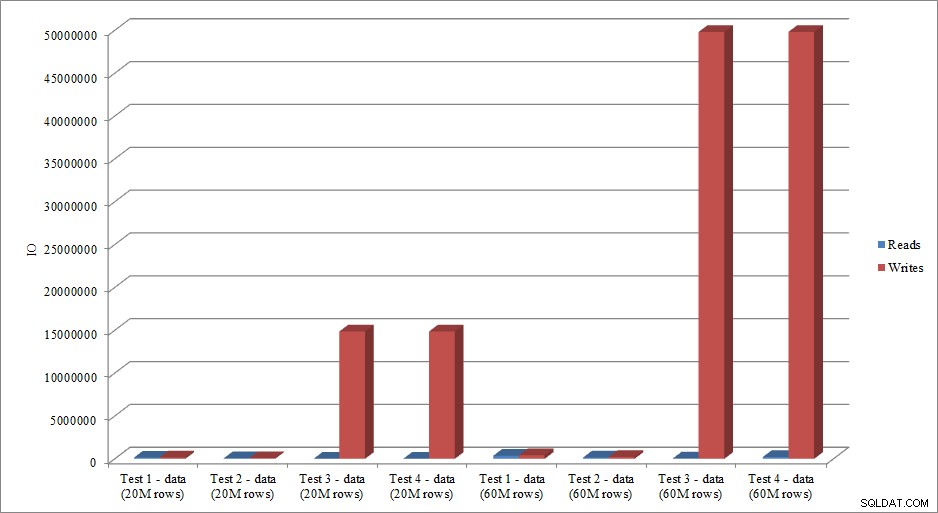
Čtení a zápis načítání dat
Metoda, kterou jsem zde představil pro testování výkonu nebo měření změn výkonu na základě úprav kódu, designu atd., je pouze jednou z možností, jak zachytit základní informace. V některých scénářích to může být přehnané. Máte-li jeden dotaz, který se snažíte vyladit, nastavení tohoto procesu pro zachycování dat může trvat déle, než vyladění dotazu! Pokud jste provedli nějaké ladění dotazů, pravděpodobně máte ve zvyku zaznamenávat data STATISTICS IO a STATISTICS TIME spolu s plánem dotazů a poté porovnávat výstup při provádění změn. Dělám to roky, ale nedávno jsem objevil lepší způsob… SQL Sentry Plan Explorer PRO. Ve skutečnosti, poté, co jsem dokončil všechny zátěžové testy, které jsem popsal výše, jsem prošel a znovu provedl své testy prostřednictvím PE a zjistil jsem, že dokážu zachytit informace, které jsem chtěl, aniž bych musel nastavovat tabulky sběru dat.
V rámci Plan Explorer PRO máte možnost získat skutečný plán – PE spustí dotaz proti vybrané instanci a databázi a vrátí plán. A s ním získáte všechna další skvělá data, která PE poskytuje (časové statistiky, čtení a zápisy, IO podle tabulky), stejně jako statistiky čekání, což je příjemný přínos. S použitím našeho příkladu jsem začal prvním testem – vytvořením haldy, načtením dat a následným přidáním seskupeného indexu a neklastrovaných indexů – a poté jsem spustil možnost Získat skutečný plán. Po dokončení jsem upravil svůj test skriptu 2 a znovu spustil možnost Získat skutečný plán. Zopakoval jsem to u třetího a čtvrtého testu, a když jsem skončil, měl jsem toto:
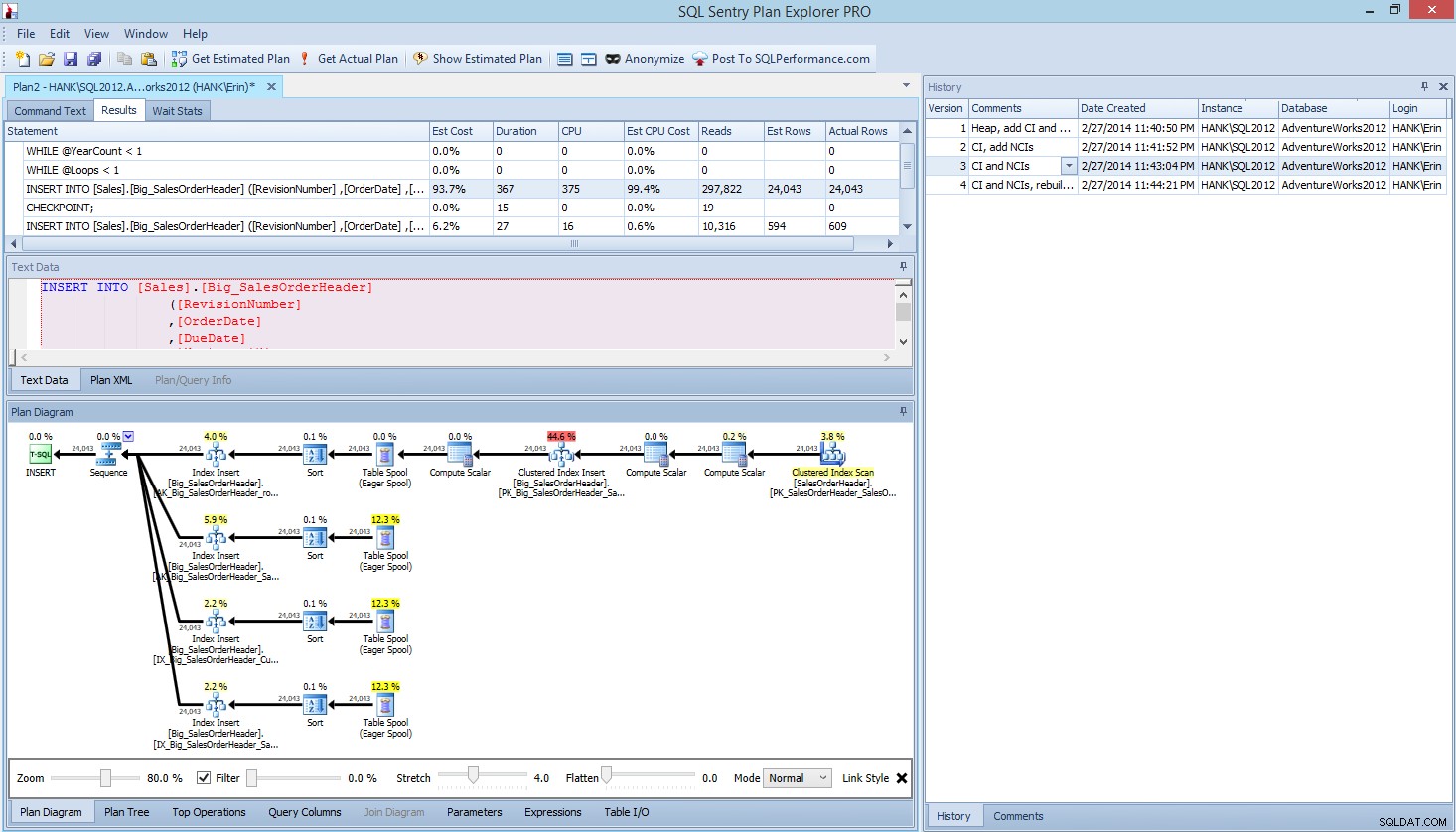
Plánujte zobrazení Explorer PRO po provedení 4 testů
Všimli jste si podokna historie na pravé straně? Pokaždé, když jsem upravil svůj kód a znovu získal skutečný plán, uložilo to novou sadu informací. Mám možnost uložit tato data jako soubor .pesession, abych je mohl sdílet s jiným členem mého týmu, nebo se vrátit později a procházet různými testy a podle potřeby procházet různými příkazy v dávce a dívat se na různé metriky, např. jako trvání, CPU a IO. Na snímku obrazovky výše jsem zvýraznil INSERT z Testu 3 a plán dotazů zobrazuje aktualizace všech čtyř neshlukovaných indexů.
Shrnutí
Stejně jako u mnoha úloh na serveru SQL existuje mnoho způsobů, jak zachytit a zkontrolovat data, když spouštíte testy výkonu nebo provádíte ladění. Čím méně manuálního úsilí musíte vynaložit, tím lépe, protože vám zbyde více času na skutečné provedení změn, pochopení dopadu a pak přejít k dalšímu úkolu. Bez ohledu na to, zda přizpůsobíte skript pro zachycování dat nebo necháte nástroj třetí strany, aby to udělal za vás, kroky, které jsem nastínil, jsou stále platné:
- Definujte, co chcete zlepšit
- Rozsah testování
- Určete, jaká data lze použít k měření zlepšení
- Rozhodněte se, jak data zachytit
- Pokud je to možné, nastavte automatizovanou metodu testování a zachycování
- Testujte, vyhodnocujte a podle potřeby opakujte
Šťastné testování!