V tomto článku pokračuji v pokrytí řešení lákavé výzvy Petera Larssona, která spojuje nabídku s poptávkou. Ještě jednou děkujeme Lucovi, Kamilu Kosnovi, Danielu Brownovi, Brianu Walkerovi, Joe Obbishovi, Raineru Hoffmannovi, Paulu Whiteovi, Charliemu a Peteru Larssonovi za zaslání vašich řešení.
Minulý měsíc jsem se zabýval řešením založeným na intervalových průsecích pomocí klasického testu intervalového průniku založeného na predikátu. Toto řešení budu označovat jako klasické křižovatky . Klasický přístup k průsečíkům intervalů vede k plánu s kvadratickým měřítkem (N^2). Prokázal jsem jeho špatný výkon proti vzorovým vstupům v rozsahu od 100 000 do 400 000 řádků. Dokončení řešení trvalo 931 sekund proti vstupu 400 000 řádků! Tento měsíc začnu tím, že vám stručně připomenu řešení z minulého měsíce a proč se škáluje a funguje tak špatně. Poté představím přístup založený na revizi testu intervalového průniku. Tento přístup použili Luca, Kamil a možná i Daniel a umožňuje řešení s mnohem lepším výkonem a škálováním. Toto řešení budu označovat jako revidované křižovatky .
Problém s klasickým testem křižovatky
Začněme rychlou připomínkou řešení z minulého měsíce.
Použil jsem následující indexy na vstupní tabulce dbo.Auctions k podpoře výpočtu průběžných součtů, které vytvářejí intervaly poptávky a nabídky:
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
Následující kód má kompletní řešení implementující přístup klasických intervalových průniků:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
CREATE UNIQUE CLUSTERED INDEX idx_cl_ES_ID ON #Supply(EndSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S WITH (FORCESEEK)
ON D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply; Tento kód začíná výpočtem intervalů poptávky a nabídky a jejich zápisem do dočasných tabulek nazvaných #Poptávka a #Nabídka. Kód pak vytvoří seskupený index na #Supply s EndSupply jako úvodním klíčem pro co nejlepší podporu testu křižovatky. Nakonec kód spojí #Supply a #Demand a identifikuje obchody jako překrývající se segmenty protínajících se intervalů pomocí následujícího predikátu spojení založeného na klasickém testu průniku intervalů:
D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply
Plán tohoto řešení je znázorněn na obrázku 1.
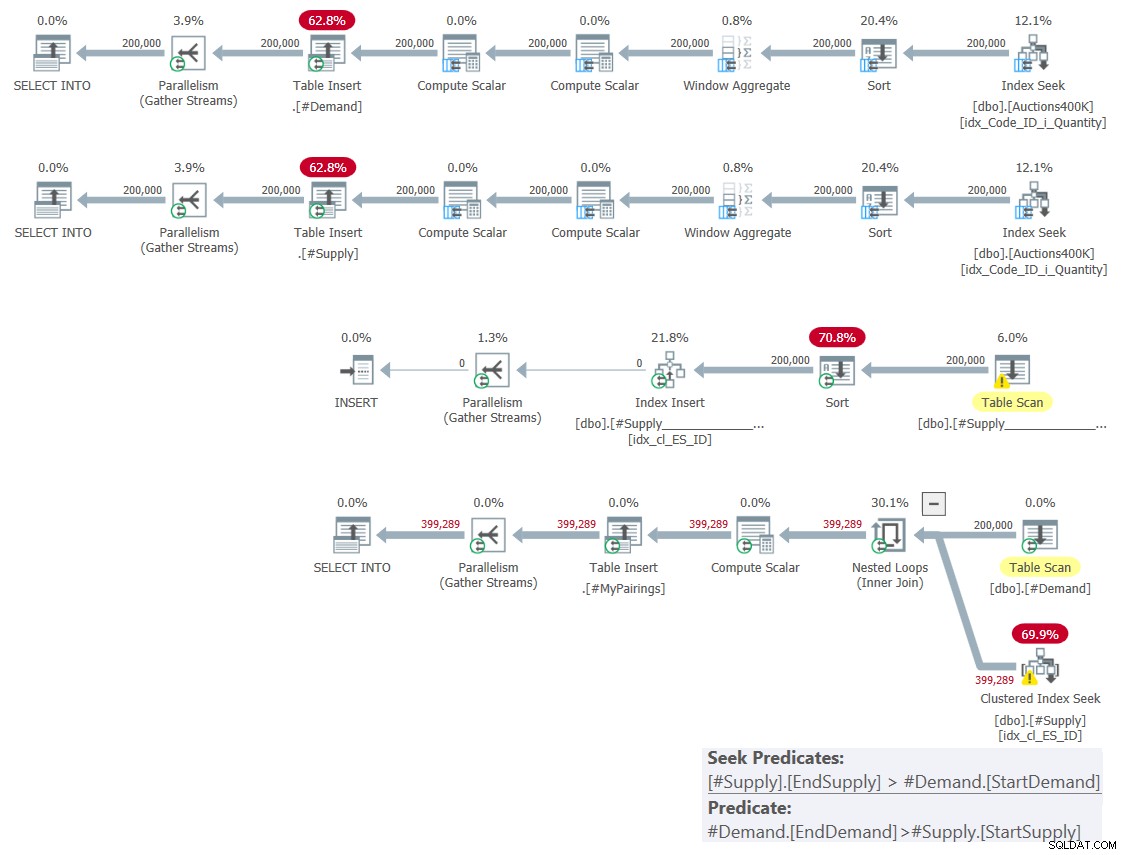 Obrázek 1:Plán dotazů pro řešení založené na klasických křižovatkách
Obrázek 1:Plán dotazů pro řešení založené na klasických křižovatkách
Jak jsem vysvětlil minulý měsíc, ze dvou zahrnutých rozsahových predikátů může být pouze jeden použit jako vyhledávací predikát v rámci operace vyhledávání indexu, zatímco druhý musí být použit jako zbytkový predikát. Jasně to vidíte na plánu posledního dotazu na obrázku 1. Proto jsem se obtěžoval vytvořit pouze jeden index na jedné z tabulek. Také jsem vynutil použití hledání v indexu, který jsem vytvořil pomocí nápovědy FORCESEEK. V opačném případě by optimalizátor mohl skončit ignorováním tohoto indexu a vytvořením vlastního pomocí operátoru Index Spool.
Tento plán má kvadratickou složitost, protože každý řádek na jedné straně — #poptávka v našem případě — bude muset indexové hledání zpřístupnit v průměru polovinu řádků na druhé straně — #v našem případě nabídka — na základě predikátu hledání a identifikovat konečné shody použitím zbytkového predikátu.
Pokud vám stále není jasné, proč má tento plán kvadratickou složitost, možná by vám mohlo pomoci vizuální zobrazení díla, jak je znázorněno na obrázku 2.
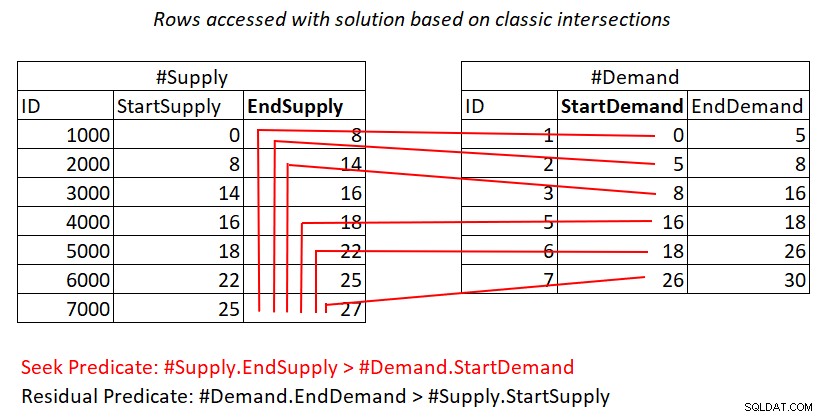 Obrázek 2:Ukázka práce s řešením založeným na klasických křižovatkách
Obrázek 2:Ukázka práce s řešením založeným na klasických křižovatkách
Tento obrázek znázorňuje práci vykonanou spojením Nested Loops v plánu pro poslední dotaz. Halda #Demand je vnější vstup spojení a seskupený index na #Supply (s hlavním klíčem EndSupply) je vnitřním vstupem. Červené čáry představují aktivity vyhledávání indexu provedené na řádku v #Demand v indexu na #Supply a řádky, ke kterým přistupují v rámci prohledávání rozsahu v indexovém listu. Směrem k extrémně nízkým hodnotám StartDemand v #Demand musí mít skenování rozsahu přístup ke všem řádkům v #Supply. Směrem k extrémně vysokým hodnotám StartDemand v #Demand potřebuje skenování rozsahu dosáhnout téměř nulových řádků v #Supply. V průměru potřebuje skenování rozsahu získat přístup k přibližně polovině řádků v #Supply na požadovaný řádek. U D řádků poptávky a S řádků nabídky je počet zpřístupněných řádků D + D*S/2. To je navíc k nákladům na hledání, která vás dostanou do odpovídajících řádků. Například při plnění dbo.Auctions 200 000 řádky poptávky a 200 000 řádky nabídky to znamená, že spojení Nested Loops zpřístupní 200 000 řádků poptávky + 200 000*200 000/2 řádků nabídky nebo 200 000 02000 0200000000000200000000000 Probíhá zde spousta opětovného skenování zásobovacích řádků!
Pokud se chcete držet myšlenky intervalových křižovatek, ale dosáhnout dobrého výkonu, musíte přijít na způsob, jak snížit množství vykonané práce.
Ve svém řešení Joe Obbish seřadil intervaly na základě maximální délky intervalu. Tímto způsobem byl schopen snížit počet řádků, které spojení potřebovalo ke zpracování, a spoléhat se na dávkové zpracování. Jako finální filtr použil klasický intervalový průsečíkový test. Joeovo řešení funguje dobře, pokud maximální délka intervalu není příliš vysoká, ale doba běhu řešení se zvyšuje se zvyšující se maximální délkou intervalu.
Takže, co ještě můžete udělat…?
Revidovaný test křižovatky
Luca, Kamil a možná i Daniel (tam byla nejasná část o jeho zveřejněném řešení kvůli formátování webu, takže jsem to musel hádat) použili revidovaný test intervalového průniku, který umožňuje mnohem lepší využití indexování.
Jejich průnikový test je disjunkcí dvou predikátů (predikátů oddělených operátorem OR):
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply >= D.StartDemand AND S.StartSupply < D.EndDemand)
V angličtině se buď oddělovač začátku poptávky protíná s intervalem nabídky inkluzivním, exkluzivním způsobem (včetně začátku a bez konce); nebo se oddělovač začátku nabídky protíná s intervalem poptávky inkluzivním, exkluzivním způsobem. Chcete-li, aby byly dva predikáty disjunktní (neměly se překrývající se případy), ale přesto byly úplné a pokrývaly všechny případy, můžete ponechat operátor =pouze v jednom nebo druhém, například:
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand)
Tento revidovaný test intervalové křižovatky je docela pronikavý. Každý z predikátů může potenciálně efektivně využívat index. Zvažte predikát 1:
D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
Za předpokladu, že vytvoříte krycí index na #Demand s StartDemand jako úvodním klíčem, můžete potenciálně získat spojení Nested Loops použitím práce znázorněné na obrázku 3.
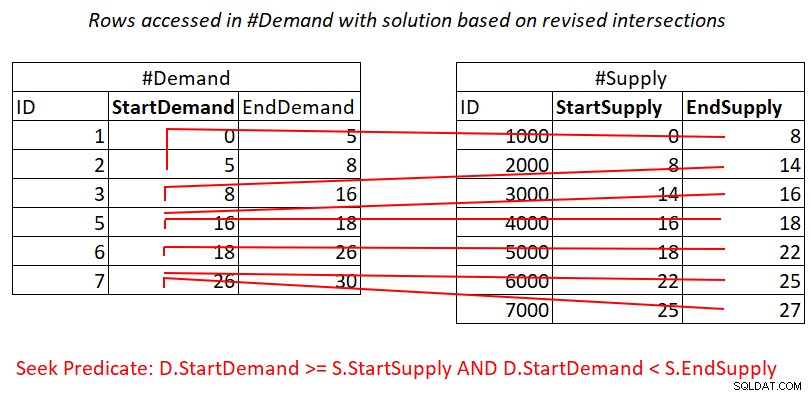
Obrázek 3:Ilustrace teoretické práce potřebné ke zpracování predikátu 1
Ano, stále platíte za vyhledávání v #Demand indexu za řádek v #Supply, ale rozsah skenuje v indexovém listovém přístupu téměř nesouvislé podmnožiny řádků. Žádné opětovné skenování řádků!
Podobná situace je s predikátem 2:
S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
Za předpokladu, že vytvoříte krycí index na #Supply s StartSupply jako úvodním klíčem, můžete potenciálně získat spojení Nested Loops použitím práce znázorněné na obrázku 4.
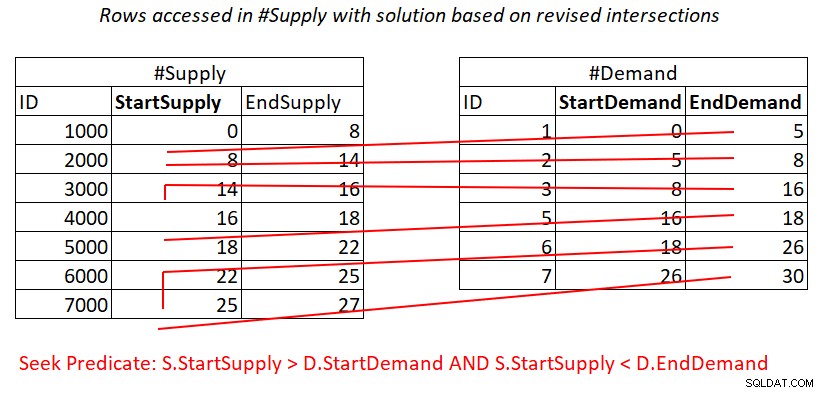
Obrázek 4:Ilustrace teoretické práce potřebné ke zpracování predikátu 2
Také zde platíte za vyhledávání v #Supply indexu za řádek v #Demand, a pak rozsah skenuje v indexovém listu přístup k téměř nesouvislým podmnožinám řádků. Opět žádné opětovné skenování řádků!
Za předpokladu D řádků poptávky a S řádků nabídky lze práci popsat jako:
Number of index seek operations: D + S Number of rows accessed: 2D + 2S
Je tedy pravděpodobné, že největší část nákladů zde tvoří I/O náklady spojené s hledáním. Ale tato část práce má lineární škálování ve srovnání s kvadratickým škálováním klasického dotazu na intersekce intervalů.
Samozřejmě musíte vzít v úvahu předběžné náklady na vytvoření indexu na dočasných tabulkách, které mají n log n škálování kvůli souvisejícímu řazení, ale tuto část platíte jako předběžnou součást obou řešení.
Zkusme tuto teorii uvést do praxe. Začněme vyplněním dočasných tabulek #Poptávka a #nabídka intervaly poptávky a nabídky (stejně jako u klasických průsečíků intervalů) a vytvořením podpůrných indexů:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID); Plány naplnění dočasných tabulek a vytvoření indexů jsou znázorněny na obrázku 5.
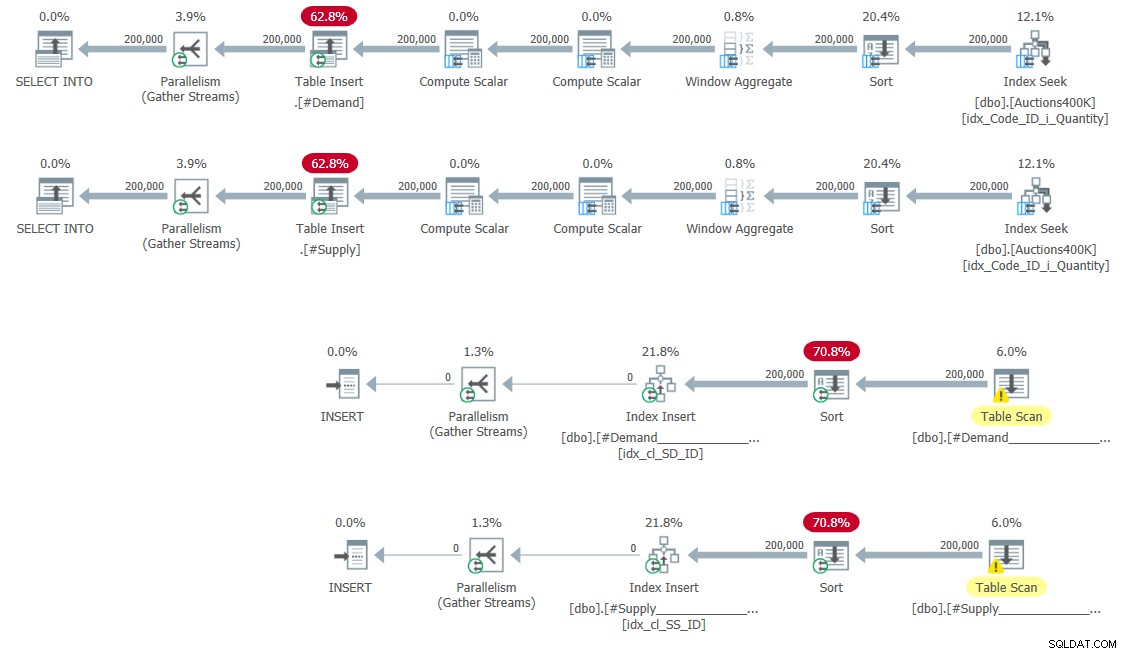
Obrázek 5:Plány dotazů pro naplnění dočasných tabulek a vytváření indexy
Žádné překvapení.
Nyní k závěrečnému dotazu. Můžete být v pokušení použít jeden dotaz s výše zmíněnou disjunkcí dvou predikátů, například takto:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON (D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand); Plán pro tento dotaz je znázorněn na obrázku 6.
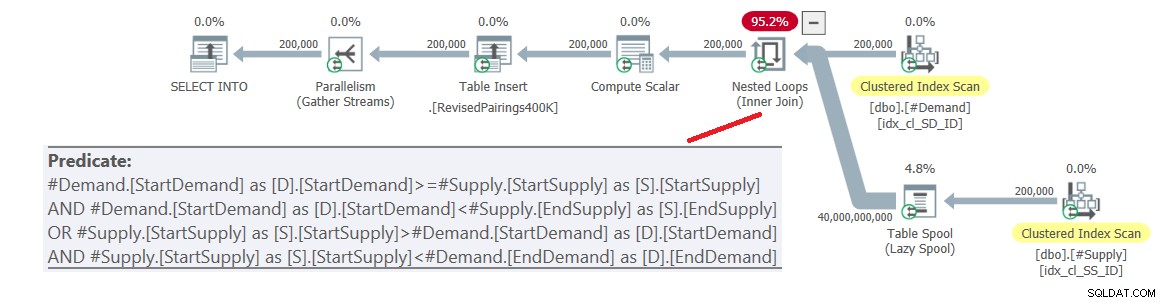
Obrázek 6:Plán dotazu pro konečný dotaz s použitím revidovaného průniku test, zkuste 1
Problém je v tom, že optimalizátor neví, jak tuto logiku rozdělit na dvě samostatné činnosti, z nichž každá zpracovává jiný predikát a efektivně využívá příslušný index. Takže to skončí úplným kartézským součinem dvou stran, přičemž všechny predikáty se použijí jako zbytkové predikáty. S 200 000 řádky poptávky a 200 000 řádky nabídky spojení zpracuje 40 000 000 000 řádků.
Luca, Kamil a možná i Daniel využili prozíravý trik, který rozdělil logiku na dva dotazy a sjednotil jejich výsledky. Zde je důležité používat dva nesouvislé predikáty! Místo operátora UNION můžete použít operátor UNION ALL, čímž se vyhnete zbytečným nákladům na hledání duplikátů. Zde je dotaz implementující tento přístup:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; Plán pro tento dotaz je znázorněn na obrázku 7.
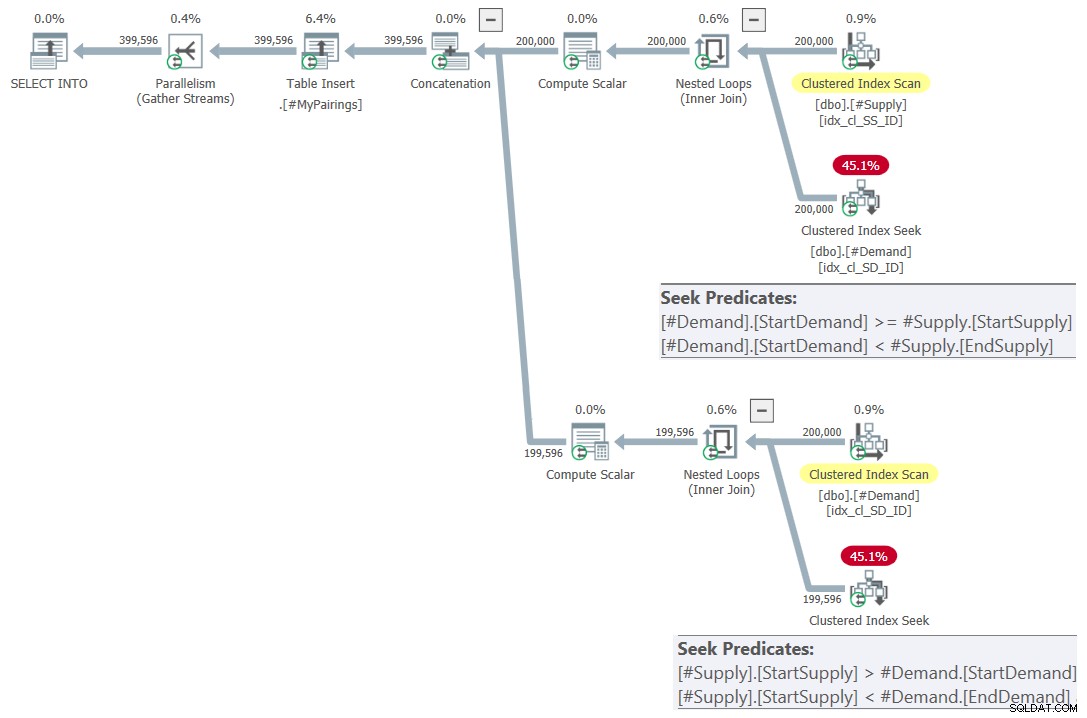
Obrázek 7:Plán dotazu pro konečný dotaz s použitím revidovaného průniku test, zkuste 2
Tohle je prostě nádhera! není to tak? A protože je to tak krásné, zde je celé řešení od začátku, včetně vytváření dočasných tabulek, indexování a finálního dotazu:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; Jak již bylo zmíněno dříve, budu toto řešení označovat jako revidované křižovatky .
Kamilovo řešení
Mezi řešeními Lucy, Kamila a Daniela bylo Kamilovo nejrychlejší. Zde je Kamilovo kompletní řešení:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #supply, #demand;
GO
CREATE TABLE #demand
(
DemandID INT NOT NULL,
DemandQuantity DECIMAL(19, 6) NOT NULL,
QuantityFromDemand DECIMAL(19, 6) NOT NULL,
QuantityToDemand DECIMAL(19, 6) NOT NULL
);
CREATE TABLE #supply
(
SupplyID INT NOT NULL,
QuantityFromSupply DECIMAL(19, 6) NOT NULL,
QuantityToSupply DECIMAL(19,6) NOT NULL
);
WITH demand AS
(
SELECT
a.ID AS DemandID,
a.Quantity AS DemandQuantity,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromDemand,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToDemand
FROM dbo.Auctions AS a WHERE Code = 'D'
)
INSERT INTO #demand
(
DemandID,
DemandQuantity,
QuantityFromDemand,
QuantityToDemand
)
SELECT
d.DemandID,
d.DemandQuantity,
d.QuantityFromDemand,
d.QuantityToDemand
FROM demand AS d;
WITH supply AS
(
SELECT
a.ID AS SupplyID,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromSupply,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToSupply
FROM dbo.Auctions AS a WHERE Code = 'S'
)
INSERT INTO #supply
(
SupplyID,
QuantityFromSupply,
QuantityToSupply
)
SELECT
s.SupplyID,
s.QuantityFromSupply,
s.QuantityToSupply
FROM supply AS s;
CREATE UNIQUE INDEX ix_1 ON #demand(QuantityFromDemand)
INCLUDE(DemandID, DemandQuantity, QuantityToDemand);
CREATE UNIQUE INDEX ix_1 ON #supply(QuantityFromSupply)
INCLUDE(SupplyID, QuantityToSupply);
CREATE NONCLUSTERED COLUMNSTORE INDEX nci ON #demand(DemandID)
WHERE DemandID is null;
DROP TABLE IF EXISTS #myPairings;
CREATE TABLE #myPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
INSERT INTO #myPairings(DemandID, SupplyID, TradeQuantity)
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 end
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #demand AS d
INNER JOIN #supply AS s
ON (d.QuantityFromDemand < s.QuantityToSupply
AND s.QuantityFromSupply <= d.QuantityFromDemand)
UNION ALL
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 END
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #supply AS s
INNER JOIN #demand AS d
ON (s.QuantityFromSupply < d.QuantityToDemand
AND d.QuantityFromDemand < s.QuantityFromSupply); Jak můžete vidět, je velmi blízko revidovanému řešení křižovatek, o kterém jsem hovořil.
Plán konečného dotazu v Kamilově řešení je znázorněn na obrázku 8.
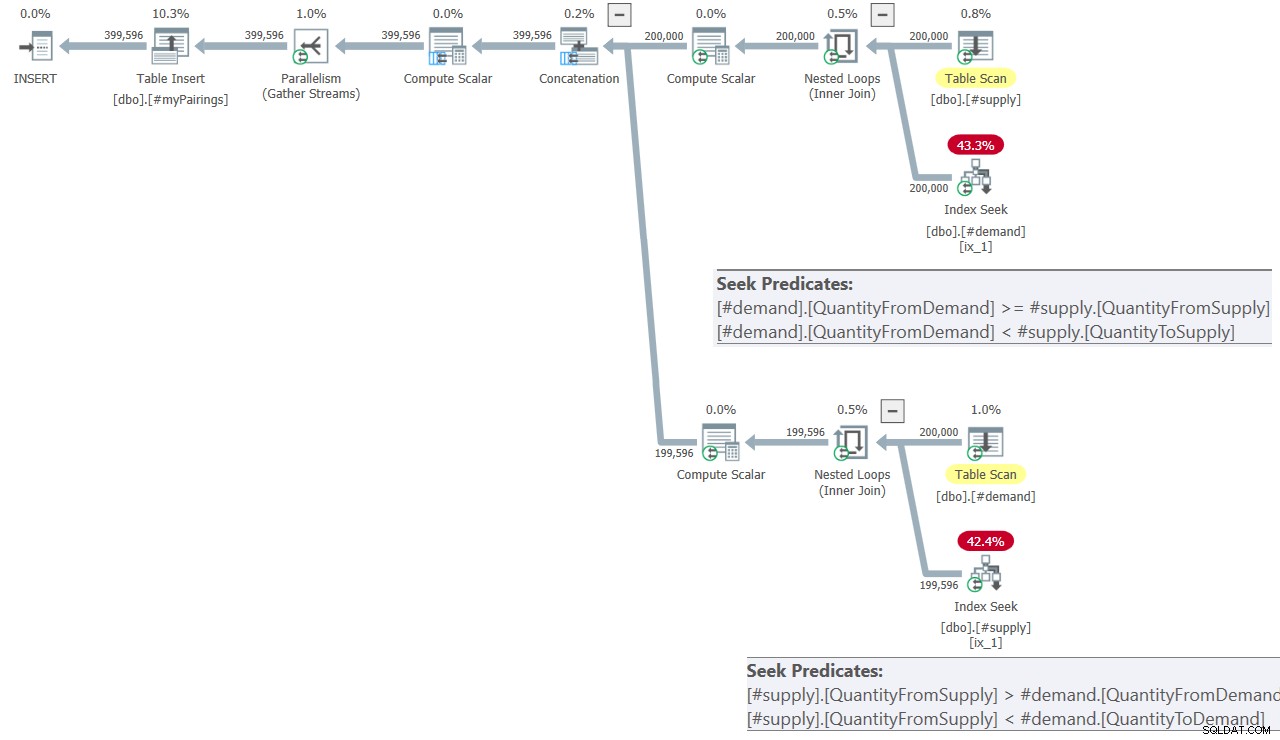
Obrázek 8:Plán dotazů pro finální dotaz v Kamilově řešení
Plán vypadá docela podobně jako plán na obrázku 7.
Test výkonu
Připomeňme, že dokončení klasického řešení křižovatek trvalo 931 sekund proti vstupu se 400 tisíci řádky. To je 15 minut! Je to mnohem, mnohem horší než řešení kurzoru, jehož dokončení na stejném vstupu trvalo asi 12 sekund. Obrázek 9 obsahuje údaje o výkonu včetně nových řešení popisovaných v tomto článku.
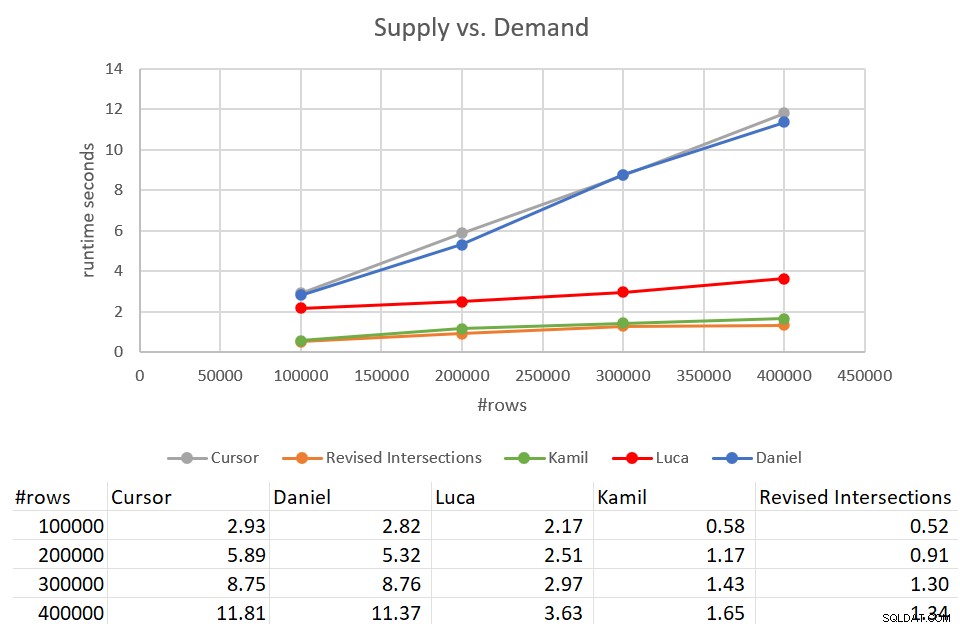
Obrázek 9:Test výkonu
Jak vidíte, Kamilovo řešení a podobné revidované řešení křižovatek trvalo asi 1,5 sekundy, než bylo dokončeno proti zadání 400 000 řádků. To je docela slušné zlepšení ve srovnání s původním řešením založeným na kurzoru. Hlavní nevýhodou těchto řešení jsou I/O náklady. S vyhledáváním na řádek, pro vstup 400 000 řádků, tato řešení provedou více než 1,35 milionu čtení. Ale také by to mohlo být považováno za naprosto přijatelné náklady vzhledem k dobré době běhu a škálování, které získáte.
Co bude dál?
Náš první pokus o vyřešení problému srovnávání nabídky a poptávky se spoléhal na klasický intervalový průnikový test a dostal plán se špatným výkonem s kvadratickým škálováním. Mnohem horší než řešení založené na kurzoru. Na základě poznatků od Lucy, Kamila a Daniela pomocí revidovaného testu intervalového průniku byl náš druhý pokus významným vylepšením, které využívá indexování efektivně a funguje lépe než řešení založené na kurzoru. Toto řešení však zahrnuje značné I/O náklady. Příští měsíc budu pokračovat ve zkoumání dalších řešení.
[ Přejít na:Původní výzva | Řešení:Část 1 | Část 2 | část 3]