V tomto článku pokračuji ve zkoumání řešení problému sladění nabídky a poptávky. Děkujeme Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie, Ian a Peter Larsson za zaslání vašich řešení.
Minulý měsíc jsem se zabýval řešeními založenými na revidovaném přístupu intervalových křižovatek oproti klasickému. Nejrychlejší z těchto řešení spojil nápady Kamila, Lucy a Daniela. Sjednotil dva dotazy s nesouvislými sargable predikáty. Dokončení řešení trvalo 1,34 sekundy proti 400 000 řádkovému vstupu. To není příliš ošuntělé, vezmeme-li v úvahu, že řešení založené na klasickém přístupu k intervalovým křižovatkám trvalo 931 sekund na stejném vstupu. Připomeňme si, že Joe přišel s geniálním řešením, které se opírá o klasický přístup k průsečíkům intervalů, ale optimalizuje logiku shody tím, že intervaly seskupuje na základě největší délky intervalu. Se stejným 400 000 řádkovým vstupem trvalo dokončení Joeova řešení 0,9 sekundy. Záludná část tohoto řešení spočívá v tom, že jeho výkon klesá s rostoucí délkou největšího intervalu.
Tento měsíc zkoumám fascinující řešení, která jsou rychlejší než řešení Kamil/Luca/Daniel Revised Intersections a jsou neutrální vůči délce intervalu. Řešení v tomto článku vytvořili Brian Walker, Ian, Peter Larsson, Paul White a já.
Všechna řešení v tomto článku jsem testoval proti vstupní tabulce Aukce se 100 000, 200 000, 300 000 a 400 000 řádky a s následujícími indexy:
-- Index pro podporu řešení VYTVOŘIT UNIKÁTNÍ NEZAHRNUTÝ INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Kód, ID) INCLUDE(Množství); -- Povolit dávkový režim Window Aggregate VYTVOŘIT NEZAHRNUTÝ INDEX SLOUPCE idx_cs ON dbo.Auctions(ID) KDE ID =-1 A ID =-2;
Při popisu logiky řešení budu předpokládat, že tabulka Aukce je vyplněna následující malou sadou ukázkových dat:
ID Kód Množství----------- ---- ---------1 D 5,0000002 D 3,0000003 D 8,0000005 D 2,0000006 D 8,0000007 D 0,00 D 4,0000008 0,0000000 2,0000004000 S 2,0000005000 S 4,0000006000 S 3,0000007000 S 2,000000
Následující je požadovaný výsledek pro tato ukázková data:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5,0000002 1000 3,0000003 2000 6,03000003 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Řešení Briana Walkera
Vnější spojení se poměrně běžně používají v řešeních dotazování SQL, ale pokud je používáte, používáte ty jednostranné. Při výuce o vnějších spojeních často dostávám otázky s žádostí o příklady praktických případů použití úplných vnějších spojení a není jich tolik. Brianovo řešení je krásným příkladem praktického případu použití úplných vnějších spojů.
Zde je Brianův úplný kód řešení:
PUSTIT TABULKU, POKUD EXISTUJE #MyPairings; CREATE TABLE #MyPairings( DemandID INT NENÍ NULL, SupplyID INT NENÍ NULL, TradeQuantity DECIMAL(19,06) NOT NULL); WITH D AS( VYBERTE A.ID, SOUČET (A.Množství) NAD (ODDĚLENÍ PODLE A.KÓDU POŘADÍ PODLE ŘÁDKŮ A.ID BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) JAKO Spouští OD dbo.Auctions JAKO A KDE A.Kód ='D'),S AS( VYBERTE A.ID, SUM(A.Množství) NAD (ODDĚLENÍ PODLE A.KÓDU POŘADÍ PODLE ŘÁDKŮ A.ID BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) JAKO Spuštění OD dbo.Auctions JAKO A KDE A.Kód ='S'),W AS( VYBERTE D.ID JAKO ID poptávky, S.ID JAKO ID nabídky, ISNULL(D.Běží, S.Běhá) JAKO Běhá OD D FULL JOIN S ON D.Running =S.Běží),Z JAKO( VYBERTE PŘÍPAD, KDY JE W.DemandID NOT NULL THEN W.DemandID ELSE MIN(W.DemandID) OVER (POŘADÍ PODLE W.Running ŘÁDKŮ MEZI AKTUÁLNÍM ŘÁDKEM A NEODPOVĚDNÝM NÁSLEDUJÍCÍM) KONČÍ JAKO ID poptávky, PŘÍPAD, KDY W.SupplyID NENÍ NULL THEN W.SupplyID ELSE MIN ) PŘES (POŘADÍTE PODLE W.Running ROWS MEZI AKTUÁLNÍM ŘÁDKEM A NÁSLEDUJÍCÍM NEZAPOMENUTÝM) KONČÍ JAKO SupplyID, W.Running FROM W)INSERT #MyPair ings( DemandID, SupplyID, TradeQuantity ) SELECT Z.DemandID, Z.SupplyID, Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0,0) JAKO TradeQuantity OD Z KDE Z.DemandID NENÍ NULL AND Z.SupplyID NENÍ NULL;
Upravil jsem Brianovo původní použití odvozených tabulek s CTE kvůli přehlednosti.
CTE D vypočítává celkové množství poptávky ve výsledkovém sloupci nazvaném D.Running a CTE S vypočítá průběžná množství celkové nabídky ve výsledkovém sloupci nazvaném S.Running. CTE W poté provede úplné vnější spojení mezi D a S, přičemž porovná D.Running s S.Running a vrátí první nenulovou hodnotu mezi D.Running a S.Running jako W.Running. Zde je výsledek, který získáte, pokud zadáte dotaz na všechny řádky z W seřazené podle Spuštění:
DemandID SupplyID běží----------- ----------- ----------1 NULL 5,0000002 1000 8,000000NULL 2000 14,0000003 30000 1600 NULL 5000 22,000000NULL 6000 25,0000006 NULL 26,000000NULL 7000 27,0000007 NULL 30,0000008 NULL 32,000000
Myšlenka použít úplné vnější spojení založené na predikátu, který porovnává celkové součty poptávky a nabídky, je geniální! Většina řádků v tomto výsledku – v našem případě prvních 9 – představuje párování výsledků s trochou chybějících výpočtů. Řádky s koncovými ID NULL jednoho z druhů představují položky, které nelze porovnat. V našem případě představují poslední dva řádky položky poptávky, které nelze spárovat s položkami nabídky. Zbývá tedy vypočítat DemandID, SupplyID a TradeQuantity párů výsledků a odfiltrovat položky, které nelze porovnat.
Logika, která vypočítává výsledek DemandID a SupplyID, se provádí v CTE Z následovně (za předpokladu řazení ve W spuštěním):
- DemandID:pokud DemandID není NULL, pak DemandID, jinak minimální DemandID začínající aktuálním řádkem
- SupplyID:pokud SupplyID není NULL, pak SupplyID, jinak minimální SupplyID začínající aktuálním řádkem
Zde je výsledek, který získáte, pokud zadáte dotaz na Z a seřadíte řádky podle Spuštění:
DemandID SupplyID Běžící----------- ----------- ----------1 1000 5,0000002 1000 8,0000003 2000 14,0000003 3000 060.0 22,0000006 6000 25,0000006 7000 26,0000007 7000 27,0000007 NULL 30,0000008 NULL 32,000000
Vnější dotaz odfiltruje ze Z řádky představující položky jednoho druhu, které nelze porovnat s položkami druhého druhu, a to tak, že zajistí, aby ID poptávky i ID nabídky nebyly NULL. Obchodní množství výsledných párů se vypočítá jako aktuální průběžná hodnota minus předchozí průběžná hodnota pomocí funkce LAG.
Zde je to, co se zapíše do tabulky #MyPairings, což je požadovaný výsledek:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5,0000002 1000 3,0000003 2000 6,03000003 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Plán tohoto řešení je znázorněn na obrázku 1.
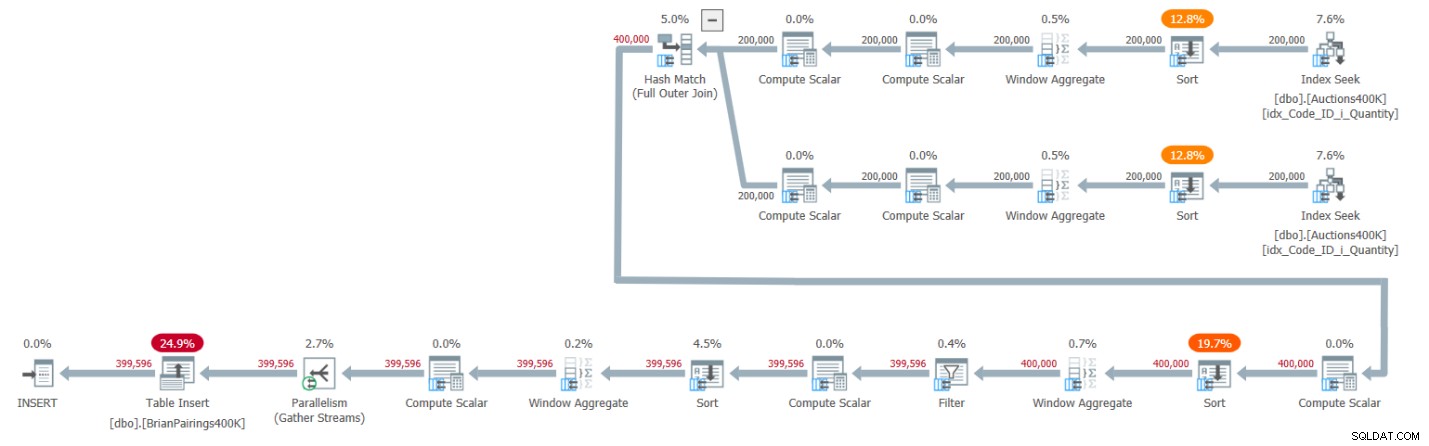 Obrázek 1:Plán dotazů pro Brianovo řešení
Obrázek 1:Plán dotazů pro Brianovo řešení
Horní dvě větve plánu počítají průběžné součty poptávky a nabídky pomocí operátoru Window Aggregate v dávkovém režimu, každá po načtení příslušných položek z podpůrného indexu. Jak jsem vysvětlil v předchozích článcích této série, protože index již má řádky uspořádané tak, jak je potřebují operátoři Window Aggregate, myslíte si, že explicitní operátory řazení by neměly být vyžadovány. SQL Server však v současné době nepodporuje účinnou kombinaci paralelní operace indexu zachování pořadí před paralelním operátorem agregace oken v dávkovém režimu, takže v důsledku toho před každým z paralelních operátorů agregace oken předchází explicitní paralelní operátor řazení.
Plán používá ke zpracování úplného vnějšího spojení spojení hash v dávkovém režimu. Plán také používá dva dodatečné operátory agregace oken v dávkovém režimu, kterým předcházejí explicitní operátory řazení pro výpočet funkcí okna MIN a LAG.
To je docela efektivní plán!
Zde jsou doby běhu, které jsem získal pro toto řešení proti vstupním velikostem v rozmezí od 100 000 do 400 000 řádků v sekundách:
100 K:0,368200 K:0,845300 K:1,255400 K:1,315
Itzikovo řešení
Dalším řešením této výzvy je jeden z mých pokusů o její vyřešení. Zde je úplný kód řešení:
PUSTIT TABULKU, POKUD EXISTUJE #MyPairings; S C1 AS( VYBERTE *, SOUČET (Množství) NAD (ODDĚLENÍ PODLE KÓDU ŘADIT PODLE ŘÁDKŮ ID BEZ PŘEDCHÁZEJÍCÍCH) JAKO SOUČET MNOŽSTVÍ Z dbo.Auctions),C2 AS( VYBRAT *, SOUČET (Množství * Kód PŘÍPADU KDYŽ 'D' THEN -1 KDYŽ 'S' POTOM 1 KONEC) NAD (POŘADÍ PODLE SOUČETNÍ MNOŽSTVÍ, ŘÁDKY kódu PŘEDCHOZÍ BEZ OMEZENÍ) JAKO Úroveň zásob, ZPOŽDĚNÍ (Součet Množství, 1, 0,0) NAD (POŘADÍ PODLE SOUČTU, Kód) JAKO PŘEDCHOZÍ SOUČET, MAX (PŘÍPAD, KDYŽ Kód ='D' POTOM KONEC ID) PŘED (POŘADÍ PODLE SOUČETNÍHO MNOŽSTVÍ, PŘEDCHOZÍ ŘÁDKY KÓDU) JAKO PrevDemandID, MAX (PŘÍPAD, KDYKÓD ='S' THEN ID KONEC) NAD (POŘADÍ PODLE SOUČETNÍHO POČTU, ŘÁDKY kódu PŘEDCHOZÍ BEZ ŘADY) JAKO PrevSupplyID, MIN (CASE WH) ='D' THEN ID END) NAD (POŘADÍ PODLE SOUČETNÍHO MNOŽSTVÍ, Kód ŘÁDKY MEZI AKTUÁLNÍM ŘÁDKEM A NÁSLEDUJÍCÍ BEZ ODPOVĚDNOSTI) JAKO NextDemandID, MIN (PŘÍPAD, KDYŽ Kód ='S' THEN ID KONEC) NAD (POŘADÍ PODLE SOUČTU, Kód ŘÁDKY MEZI AKTUÁLNÍMI ŘÁDKY A NÁSLEDUJÍCÍ BEZ OMEZENÍ) AS NextSupplyID FROM C1),C3 AS( SELECT *, CASE Code WHEN 'D ' THEN ID WHEN 'S' THEN CASE WHEN StockLevel> 0 THEN NextDemandID ELSE PrevDemandID KONEC JAKO ID poptávky, CASE Code WHEN 'S' THEN ID WHEN 'D' THEN CASE WHEN StockLevel <=0 THEN NextSupplyID Supply ELSE Prev SumQty - PrevSumQty AS TradeQuantity Z C2) VYBERTE ID poptávky, ID nabídky, ID obchodu, DO #MyPairingsFROM C3WHERE TradeQuantity> 0,0 A ID poptávky NENÍ NULL A ID nabídky NENÍ NULL;
CTE C1 se dotazuje na tabulku Aukcí a používá funkci okna k výpočtu celkového množství poptávky a nabídky, přičemž zavolá výsledný sloupec SumQty.
CTE C2 se dotazuje C1 a vypočítává řadu atributů pomocí okenních funkcí na základě SumQty a řazení kódu:
- StockLevel:Aktuální stav zásob po zpracování každého záznamu. To se vypočítá tak, že se přiřadí záporné znaménko poptávanému množství a kladné znaménko dodávanému množství a sečte se tato množství až po aktuální položku včetně.
- PrevSumQty:Hodnota SumQty předchozího řádku.
- PrevDemandID:Poslední ID poptávky bez NULL.
- PrevSupplyID:Poslední ID dodávky, které nemá hodnotu NULL.
- NextDemandID:Další ID poptávky bez NULL.
- NextSupplyID:Další ID dodávky bez NULL.
Zde je obsah C2 seřazený podle SumQty and Code:
ID Kód Množství Součet Množství SkladLevel PředchozíSoučetMnožství PrevDemandID PrevSupplyID NextDemandID NextSupplyID----- ---- --------- ---------- ---------- -- ----------- ------------ ------------ ------------- ----------- 1 D 5,000000 5,000000 -5,000000 0,000000 1 NULL 1 10002 D 3,000000 8.000000 -8,000000 5.000000 2 NULL 2 10001000 S 8.000000 8,000000 0,000000 8,000000 2 000 3 10002000 S 6,000000 D 8,000000 16.000000 -2,000000 14.000000 3 2000 3 30003000 S 2.000000 16,000000 0,000000 16.000000 3 3000 5 30005 D 2,000000 18.0000 -2,000000 16,000000 5 3000 5 40004000 S 2.000000 18.0000 5 4000 6 40005000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 50006000 S 3.000000 25.000000 7.000000 22.000000 5 6000 6 60006 D 8.000000 26.000000 -1.000000 25.000000 6 6000 6 70007000 S 2.000000 27.000000 1.000000 26.000000 6 7000 7 70007 D 4.000000 30.000000 -3.000000 27.000000 7 7000 7 NULL8 D 2.000000 32,000000 -5,000000 30,000000 8 7000 8 NULL
CTE C3 se dotazuje C2 a vypočítává výsledky párování DemandID, SupplyID a TradeQuantity, než odstraní některé nadbytečné řádky.
Výsledný sloupec C3.DemandID se vypočítá takto:
- Pokud je aktuální záznam záznamem poptávky, vraťte ID požadavku.
- Pokud je aktuální položka položka dodávky a aktuální úroveň zásob je kladná, vraťte ID NextDemandID.
- Pokud je aktuální položka položka dodávky a aktuální úroveň zásob není kladná, vraťte PrevDemandID.
Výsledný sloupec C3.SupplyID se vypočítá takto:
- Pokud je aktuální položkou spotřební materiál, vraťte SupplyID.
- Pokud je aktuální položka poptávkou a aktuální úroveň zásob není kladná, vraťte NextSupplyID.
- Pokud je aktuální položka poptávkou a aktuální úroveň zásob je kladná, vraťte PrevSupplyID.
Výsledek TradeQuantity se vypočítá jako SumQty aktuálního řádku mínus PrevSumQty.
Zde je obsah sloupců relevantních pro výsledek z C3:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5,0000002 1000 3,0000002 1000 0,0200003 0,00000003 6.0000003 3000 2,0000003 3000 0,0000005 4000 2,0000005 4000 0,0000006 5000 4.0000006 6000 3,0000006 7000 1,0000007 7000 1,0000007 NULL 3,0000008 NULL 2.000000
Vnějšímu dotazu zbývá odfiltrovat nadbytečné řádky z C3. Patří mezi ně dva případy:
- Když jsou průběžné součty obou druhů stejné, položka dodávky má nulové obchodní množství. Pamatujte, že objednávání je založeno na SumQty a Code, takže když jsou průběžné součty stejné, položka poptávky se objeví před položkou nabídky.
- Koncové záznamy jednoho druhu, které nelze přiřadit k záznamům druhého druhu. Takové položky jsou reprezentovány řádky v C3, kde buď DemandID je NULL, nebo SupplyID je NULL.
Plán tohoto řešení je znázorněn na obrázku 2.
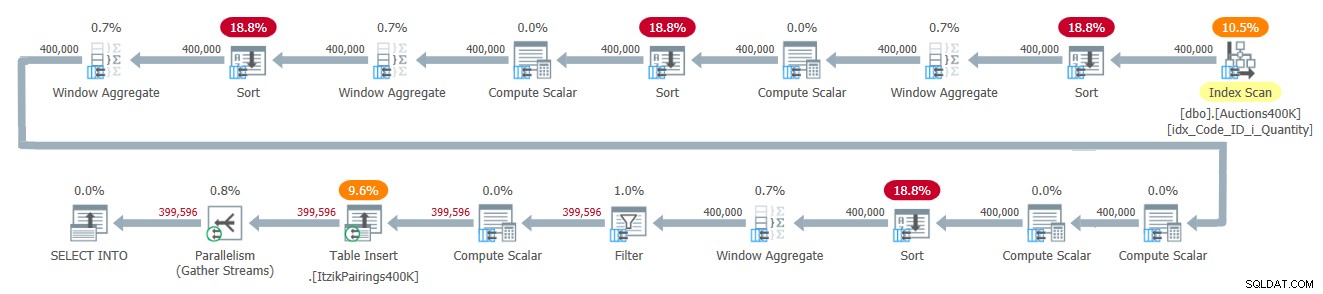 Obrázek 2:Plán dotazů pro Itzikovo řešení
Obrázek 2:Plán dotazů pro Itzikovo řešení
Plán aplikuje jeden průchod vstupními daty a používá čtyři operátory agregace oken v dávkovém režimu ke zpracování různých výpočtů v okně. Všem operátorům Window Aggregate předcházejí explicitní operátory řazení, i když pouze dva z nich jsou zde nevyhnutelné. Další dva mají co do činění se současnou implementací operátoru Window Aggregate v paralelním dávkovém režimu, který se nemůže spoléhat na paralelní vstup pro zachování objednávky. Jednoduchý způsob, jak zjistit, které operátory řazení jsou z tohoto důvodu, je vynutit si sériový plán a zjistit, které operátory řazení zmizí. Když tímto řešením vynutím sériový plán, první a třetí operátor Sort zmizí.
Zde jsou doby běhu v sekundách, které jsem získal pro toto řešení:
100 tis.:0,246200 tis.:0,427300 tis.:0,616400 tis.:0,841>
Ianovo řešení
Ianovo řešení je krátké a účinné. Zde je úplný kód řešení:
PUSTIT TABULKU, POKUD EXISTUJE #MyPairings; S A AS ( SELECT *, SUM(Množství) NAD (ODDĚLENÍ PODLE KÓDU ŘADÍ PODLE ŘÁDKŮ ID BEZ PŘEDCHÁZEJÍCÍCH) JAKO Kumulativní množství OD dbo.Auctions), B AS ( SELECT Kumulativní množství, Kumulativní množství - MAS (Kumulativní počet,1Množství,0 OBJEDNÁVKA) PODLE Kumulativního množství) JAKO Obchodní množství, MAX (PŘÍPAD, KDYŽ Kód ='D' POTOM KONEC ID) JAKO ID poptávky, MAX (PŘÍPAD, KDYŽ Kód ='S' POTOM KONEC ID) JAKO ID nabídky ZE SKUPINY PODLE kumulativního množství, ID/ID – falešné seskupení zlepšit odhad řádku -- (počet řádků aukcí místo 2 řádků)), C AS ( -- doplňte NULL s další nabídkou/poptávkou -- FIRST_VALUE(ID) IGNOROVAT NULOVÉ PŘED ... -- bylo by lepší, ale to bude fungovat, protože ID jsou v pořadí kumulativního množství VYBERTE MIN (ID poptávky) NAD (POŘADÍ PODLE ŘÁDKŮ kumulativního množství MEZI AKTUÁLNÍM ŘÁDKEM A NEZÁMEDNĚNÝM NÁSLEDUJÍCÍM) JAKO ID poptávky, MIN (ID nabídky) NAD (POŘADÍ PODLE kumulativního Q počet ŘÁDKŮ MEZI AKTUÁLNÍM ŘÁDKEM A NÁSLEDUJÍCÍM NEZÁVISLÝM) JAKO SupplyID, TradeQuantity Z B)VYBERTE ID poptávky, ID nabídky, TradeQuantityINTO #MyPairingsFROM CWHERE SupplyID NENÍ NULL -- ořízněte nesplněné požadavky A ID poptávky NENÍ NULL; -- ořízněte nepoužitý spotřební materiál
Kód v CTE A se dotazuje na tabulku Aukce a vypočítává celkové množství poptávky a nabídky pomocí funkce okna a pojmenuje výsledný sloupec Kumulativní množství.
Kód v CTE B dotazuje CTE A a seskupuje řádky podle CumulativeQuantity. Toto seskupení dosahuje podobného efektu jako Brianovo vnější spojení na základě průběžných součtů poptávky a nabídky. Ian také přidal fiktivní výraz ID/ID do sady seskupení, aby zlepšil původní odhadovanou mohutnost seskupení. Na mém počítači to také vedlo k použití paralelního plánu namísto sériového.
V seznamu SELECT kód vypočítá DemandID a SupplyID načtením ID příslušného typu položky ve skupině pomocí agregace MAX a výrazu CASE. Pokud ID ve skupině není, výsledek je NULL. Kód také vypočítá sloupec výsledků nazvaný TradeQuantity jako aktuální kumulativní množství mínus předchozí, získané pomocí funkce okna LAG.
Zde je obsah B:
CumulativeQuantity TradeQuantity ID poptávky SupplyId------------------- -------------- ---------- -------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 100014.000000 6.000000 NULL 200016.000000 2.000000 3 300018.000000 2.000000 5 400022.000000 4.000000 NULL 500025.000000 3.000000 NULL 600026.000000 1.000000 6 NULL27.000000 1.000000 NULL 700030.000000 3.000000 7 NULL32.000000 2.000000 8 NULL
Kód v CTE C se pak dotazuje na CTE B a vyplní NULL ID poptávky a nabídky dalšími ID poptávky a nabídky, která nejsou NULL, pomocí funkce okna MIN s rámcem ŘÁDKY MEZI AKTUÁLNÍM ŘÁDKEM A NÁSLEDUJÍCÍ NEZÁVISLÉ.
Zde je obsah C:
Množství ID nabídky ID nabídky --------- --------- --------------1 1000 5,000000 2 1000 3,000000 3 2000 6,000000 2 300 5 4000 2,000000 6 5000 4,000000 6 6000 3,000000 6 7000 1,000000 7 7000 1,000000 7 NULL 3,000000 3,000000 8.0Posledním krokem, který zpracuje vnější dotaz proti C, je odstranění záznamů jednoho druhu, které nelze porovnat se záznamy druhého druhu. To se provádí odfiltrováním řádků, kde buď SupplyID je NULL, nebo DemandID je NULL.
Plán tohoto řešení je znázorněn na obrázku 3.
Obrázek 3:Plán dotazů pro Ianovo řešení
Tento plán provede jedno skenování vstupních dat a používá tři paralelní operátory agregace oken v dávkovém režimu k výpočtu různých funkcí okna, všem předcházejí paralelní operátory řazení. Dvěma z nich se nelze vyhnout, jak si můžete ověřit vynucením sériového plánu. Plán také používá operátor Hash Aggregate pro zpracování seskupení a agregace v CTE B.
Zde jsou doby běhu v sekundách, které jsem získal pro toto řešení:
100 K:0,214200 K:0,363300 K:0,546400 K:0,701
Řešení Petra Larssona
Řešení Petera Larssona je úžasně krátké, sladké a vysoce účinné. Zde je kompletní kód Peterova řešení:
PUSTIT TABULKU, POKUD EXISTUJE #MyPairings; WITH cteSource(ID, Code, RunningQuantity)AS( SELECT ID, Code, SUM(Množství) NAD (ODDĚLENÍ PODLE kódu ORDER BY ID) AS RunningQuantity FROM dbo.Auctions)SELECT ID poptávky, ID nabídky, TradeQuantityINTO #MyPairingsFROM (VYBRAT MIN Kód ='D' THEN ID ELSE 2147483648 END) OVER (OBJEDNEJTE PODLE Průběžného množství, Kód ŘÁDKŮ MEZI AKTUÁLNÍM ŘÁDKEM A NÁSLEDUJÍCÍM NEZAPOMENUTÝM) JAKO ID poptávky, MIN(PŘÍPAD, KDYŽ Kód ='S' PAK ID JINÉ 214874ant 364874ant 364874ant Kód ŘÁDKY MEZI AKTUÁLNÍM ŘÁDKEM A NEODPOVĚDNÝM NÁSLEDUJÍCÍM) JAKO SupplyID, RunningQuantity - COALESCE(LAG(RunningQuantity) OVER (ORDER BY RunningQuantity, Code), 0,0) AS TradeQuantity OD cteSource ) A 48 TradeQuantity OD cteSource ) AS48 Obchod <44A213 DemCTE cteSource se dotazuje na tabulku Aukcí a používá funkci okna k výpočtu průběžné celkové poptávky a množství nabídky, přičemž volá výsledkový sloupec RunningQuantity.
Kód definující odvozenou tabulku d se dotazuje cteSource a vypočítává výsledky párování DemandID, SupplyID a TradeQuantity, než odstraní některé nadbytečné řádky. Všechny funkce okna použité v těchto výpočtech jsou založeny na RunningQuantity a Code ordering.
Sloupec výsledků d.DemandID je vypočítán jako minimální ID poptávky počínaje aktuálním nebo 2147483648, pokud není žádné nalezeno.
Sloupec výsledků d.SupplyID je vypočítán jako minimální ID dodávky počínaje aktuálním nebo 2147483648, pokud není žádné nalezeno.
Výsledek TradeQuantity se vypočítá jako hodnota RunningQuantity aktuálního řádku mínus hodnota RunningQuantity předchozího řádku.
Zde je obsah d:
Množství nabídky ID poptávky--------- ----------- --------------1 1000 5,0000002 1000 3,0000003 1000 0,0000003 03 00003 0000 2.0000005 3000 0,0000005 4000 2,0000006 4000 0,0000006 5000 4.0000006 6000 3,0000006 7000 1,0000007 7000 1,0000007 2147483648 3.0000008 2147483648 2,000000Co zbývá pro vnější dotaz, je odfiltrovat nadbytečné řádky z d. Jedná se o případy, kdy je obchodní množství nulové, nebo záznamy jednoho druhu, které nelze spárovat se záznamy druhého druhu (s ID 2147483648).
Plán tohoto řešení je znázorněn na obrázku 4.
Obrázek 4:Plán dotazů pro Petrovo řešení
Stejně jako Ianův plán, i Peterův plán spoléhá na jedno skenování vstupních dat a používá tři paralelní operátory agregace oken v dávkovém režimu k výpočtu různých funkcí oken, kterým všem předcházejí paralelní operátory řazení. Dvěma z nich se nelze vyhnout, jak si můžete ověřit vynucením sériového plánu. V Peterově plánu není potřeba seskupeného agregovaného operátora jako v Ianově plánu.
Petrův kritický poznatek, který umožnil tak krátké řešení, byl poznatek, že u relevantního záznamu jednoho z druhů se vždy později objeví odpovídající ID druhého druhu (na základě řazení RunningQuantity a Code). Poté, co jsem viděl Petrovo řešení, měl jsem pocit, že jsem věci ve svém příliš komplikoval!
Zde jsou doby běhu v sekundách, které jsem získal pro toto řešení:
100 K:0,197200 K:0,412300 K:0,558400 K:0,696
Řešení Paula Whitea
Naše poslední řešení vytvořil Paul White. Zde je úplný kód řešení:
PUSTIT TABULKU, POKUD EXISTUJE #MyPairings; VYTVOŘIT TABULKU #MyPairings( DemandID integer NOT NULL, SupplyID integer NOT NULL, TradeQuantity decimal(19, 6) NOT NULL);GO INSERT #MyPairings WITH (TABLOCK)(DemandID, SupplyID, TradeQuantity)SELECT,Q3.Demand Q3.TradeQuantityFROM ( SELECT Q2.DemandID, Q2.SupplyID, TradeQuantity =-- Překrytí intervalů CASE WHEN Q2.Code ='S' THEN CASE WHEN Q2.CumDemand>=Q2.IntEnd THEN Q2.IntLength QHEN Q2.CUMDem IntStart THEN Q2.CumDemand - Q2.IntStart ELSE 0.0 END WHEN Q2.Code ='D' THEN CASE WHEN Q2.CumSupply>=Q2.IntEnd THEN Q2.IntLength WHEN Q2.CumSupply> Q2.QNup2CumSupply> Q2.QNup2C.Start. IntStart ELSE 0.0 KONEC KONEC FROM ( SELECT Q1.Code, Q1.IntStart, Q1.IntEnd, Q1.IntLength, DemandID =MAX(IIF(Q1.Code ='D', Q1.ID, 0)) PŘES ( OBJEDNAT OD Q1.IntStart, Q1.ID ŘÁDKY BEZ OMEZENÍ PŘEDCHOZÍ), SupplyID =MAX(IIF(Q1.Code ='S', Q1.ID, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ŘÁDKY NEVZATÉ PŘEDCHOZÍ), CumSupply =SUM(IIF(Q1.Code ='S', Q1.IntLength, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ŘÁDKY BEZ OMEZENÍ PŘEDCHOZÍM), CumDemand =SUM(IIF(Q1.Code ='D', Q1.IntLength, 0)) NAD ( OBJEDNAT PODLE Q1.IntStart, Q1.ID ŘÁDKŮ BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) OD ( -- Intervaly poptávky VYBERTE A.ID, A.Kód, IntStart =SOUČET(A.Množství) NAD ( ŘADÍ PODLE ŘÁDKŮ A.ID NEVYPOJENÉ PŘEDCHOZÍM) - A. Množství, IntEnd =SUM(A.Množství) NAD (POŘADÍ PODLE ŘÁDKŮ A.ID BEZ PŘEDCHOZÍ), IntLength =A.Množství OD dbo.Auctions AS A WHERE A.Code ='D' UNION ALL -- Intervaly dodávek VYBERTE A.ID, A.Code, IntStart =SUMA(A.Množství) NAD (POŘADÍ PODLE A.ID ŘÁDKŮ BEZ OMEZENÍ PŘEDCHOZÍM) - A.Quantity, IntEnd =SUM(A.Qantity) NAD ( OBJEDNÁVKA PODLE A.ID ŘÁDKŮ BEZ OMEZENÍ PŘEDCHOZÍM), IntLength =A.Množství OD dbo.Aukce AS A WHERE A.Code ='S' ) AS Q1 ) AS Q2) AS Q3WHERE Q3.TradeQuantity> 0;Kód definující odvozenou tabulku Q1 používá dva samostatné dotazy k výpočtu intervalů poptávky a nabídky na základě průběžných součtů a tyto dva sjednocuje. Pro každý interval kód vypočítá jeho začátek (IntStart), konec (IntEnd) a délku (IntLength). Zde je obsah Q1 seřazený podle IntStart a ID:
ID kód IntStart IntEnd IntLength----- ---- ---------- ---------- ----------1 D 0,000000 5.000000 5.0000001000 S 0.000000 8.000000 8.0000002 D 5.000000 8.000000 3.0000003 D 8.000000 16.000000 8.0000002000 S 8.000000 14.000000 6.0000003000 S 14.000000 16.000000 2.0000005 D 16.000000 18.000000 2.0000004000 S 16.000000 18.000000 2.0000006 D 18.000000 26.000000 8.0000005000 S 18.000000 22.000000 4.0000006000 S 22.000000 25.000000 3.0000007000 S 25.000000 27.000000 2.0000007 D 26.000000 30.000000 4.0000008 D 30,000000 32,000000 2,000000Kód definující odvozenou tabulku Q2 se dotazuje na Q1 a počítá výsledkové sloupce nazvané DemandID, SupplyID, CumSupply a CumDemand. Všechny funkce okna používané tímto kódem jsou založeny na IntStart a ID řazení a na rámu PŘEDCHOZÍ BEZ ODPOVĚDNOSTI ŘÁDKY (všechny řádky až po aktuální).
DemandID je maximální ID poptávky až do aktuálního řádku nebo 0, pokud žádné neexistuje.
SupplyID je maximální ID dodávky až do aktuálního řádku nebo 0, pokud žádné neexistuje.
CumSupply je kumulativní množství dodávek (délky intervalů dodávek) až do aktuálního řádku.
CumDemand je kumulativní množství poptávky (délky intervalu poptávky) až do aktuálního řádku.
Zde je obsah Q2:
Kód IntStart IntEnd IntLength ID poptávky ID nabídky CumSupply CumDemand---- ---------- ---------- --------- ----- 0.0 D 0.000000 5.000000 5.000000 1 0 0.000000 5.000000 5.000000 S 0.000000 8.0000 0,000000 0.000000 0.000000 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000D 18.000000 26.000000 0 0,000000 6 4000 18,000000 26,000000S 18,000000 22,000000 4,000000 6 5000 22,000000 26,000000 S 20,03 25.000000 26.000000 25,000000 27.000000 2.000000 6 7000 27.000000 26.0000d 26.000000 30.000000 4.000000 7000 27.000000 30.000000d 30.000000 32,000000 2,000000 8 7000 27.000000 32,000000Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K:0.187200K:0.331300K:0.369400K:0.425These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Závěr
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]