Poznámka:Tento článek ukazuje migraci modelu relační databáze (RDB) na hvězdicové schéma pomocí IDE Eclipse pro Voracity (a jeho zahrnutých produktů), IRI Workbench, po představení obou architektur. Pokud máte zájem o migraci RDB nebo dat do modelu Data Vault 2.0, v květnu 2019 bude v konsorciu World Wide Data Vault uveden nový průvodce Workbench; přihlaste se k odběru blogu IRI a získejte tyto podrobné pokyny, jakmile budou zveřejněny!
Datový sklad (DW) je sbírka dat extrahovaných z provozního nebo transakčního systému v podniku, transformovaných za účelem odstranění nekonzistencí a následně uspořádaných tak, aby podporovaly rychlou analýzu a/nebo vytváření sestav. DW vyžaduje schéma nebo logický popis a grafické znázornění provozní databáze. Tento článek se těchto témat dotýká a zároveň poskytuje návod, jak přejít z konvenčního schématu relační databáze na oblíbené schéma DW s názvem hvězdné schéma.
Hvězdové schéma vs. relační
Většina relačních datových struktur je znázorněna v diagramech entit-relationship (ER). ER diagram se používá při vývoji koncepčních modelů pro systém správy databází online pro zpracování transakcí (OLTP). Je to zdroj, ze kterého je přeložena struktura tabulky.
Hvězdicové schéma je však široce přijímaným standardem pro základní strukturu tabulek datového skladu. Jeho jednoduchý hvězdicový tvar (při ER-diagramu) ukazuje tabulku faktů (obsahující transakční hodnoty nebo míry) uprostřed a tabulky dimenzí (obsahující popisné nebo atributivní hodnoty), které z ní vyzařují. Obvykle je tabulka faktů ve třetí normální formě (3NF), zatímco rozměrové tabulky jsou denormalizované.
Základní rozdíly mezi entitně-relačním (ER) modelem a hvězdným modelem jsou tyto:
- Modely ER používají logické a fyzické struktury pro normalizovaný návrh databáze
- Modely dimenzí používají fyzickou strukturu pro návrh denormalizované databáze
Chcete-li vidět, jak může software IRI de/normalizovat data pomocí pivotování řádků a sloupců, klikněte sem.
Pozadí procesu převodu
V tomto článku demonstruji, jak převést data z relačního modelu na hvězdu pomocí úloh, které byste měli definovat víceméně ručně, ale lze je vytvářet a spouštět automaticky a lze je snadno upravovat.
Zde uvidíte data a specifikace úloh IRI 4GL – vyjádřené ve skriptech „SortCL“[1] – které mapují data do tabulek dimenzí a spojují data do centrální tabulky faktů. SortCL je základní program pro manipulaci a mapování dat v platformě IRI Voracity pro správu dat a ETL. Klíčem je zde však pochopení metodologie a mapování v mých úlohách SortCL, nikoli syntaxe skriptování.
Bezplatné grafické uživatelské rozhraní Eclipse, IRI Workbench, poskytuje editor SortCL, který zohledňuje syntaxi, stejně jako grafické obrysy a dialogy, diagramy pracovních postupů a mapování a intuitivní průvodce úlohami, pomocí kterých lze tyto skripty automaticky sestavit nebo upravit, pokud to nechcete ručně. Pro informaci, IRI používá stejná metadata a GUI pro profilování a vytváření diagramů databází, generování testovacích dat, provádění ETL, formátování zpráv, maskování PII, zachycování změněných dat, migraci a replikaci dat, čištění a ověřování dat atd.
Workbench používá pro Eclipse vylepšenou verzi zásuvného modulu Data Tools Platform (DTP) pro připojení k databázím přes JDBC a pro umožnění operací SQL a výměny metadat IRI v pohledu Data Source Explorer (DSE). V tomto případě Workbench podporuje:
- vytvoření a naplnění omezených testovacích (zdrojových) tabulek Oracle prostřednictvím SortCL (nebo úloh IRI RowGen podle tohoto článku)
- mapování dat tabulky entit na tabulky dimenzí pomocí SortCL
- mapování prvků faktu jako n-árního vztahu k přiřazení základní tabulky dimenzí; tj. provedením vícetabulkového spojení v SortCL za účelem vytvoření tabulky faktů
- vyplnění všech cílových tabulek (hvězdové schéma)
- ER diagramy zdrojového a cílového schématu
Typy entit v mém původním relačním modelu jsou:Dept, Emp, Project, Category, Item, Item_Use a Sale:
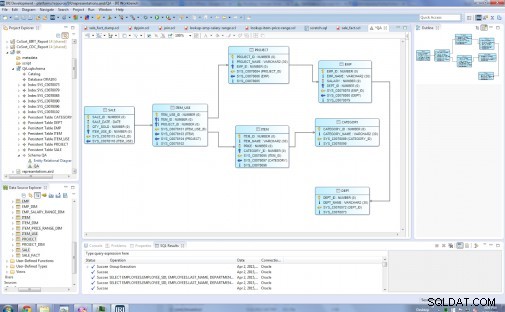
Před …
Následující diagram ukazuje konečný model hvězdy s osmi tabulkami rozměrů a jednou tabulkou faktů. Tabulky dimenzí jsou: Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, Category_Dim, Item_Price_Range_Dim, Item_Dim. Tabulka faktů uprostřed je Sale_Fact, která obsahuje klíče ke všem tabulkám dimenzí.

… Po
Kroky převodu
- Definujte a vytvořte tabulku faktů
Struktura tabulky Sale_Fact je uvedena v tomto dokumentu. Primární klíč je sales_id a zbytek atributů jsou cizí klíče zděděné z tabulek Dimension. Používám databázi Oracle (ačkoli funguje jakýkoli RDB) připojenou k Workbench DSE (přes JDBC) a SortCL pro transformaci a mapování dat ( přes ODBC). Vytvořil jsem své tabulky ve skriptech SQL upravených ve výstřižku SQL společnosti DSE a spouštěných ve Workbench.
- Definujte a vytvořte tabulky dimenzí
Pomocí stejné techniky a metadat uvedených výše vytvořte tyto tabulky dimenzí, které v dalším kroku obdrží relační data namapovaná z úloh SortCL:tabulka Category_Dim, Dept to Dept_Dim, Project to Project_Dim, Item to Item_Dim a Emp to Emp_Dim. Můžete spustit tento .SQL program se všemi CREATE logikou najednou a vytvořit tabulky.
- Přesuňte původní data tabulky Entity do tabulek dimenzí
Definujte a spusťte zde zobrazené úlohy SortCL, abyste namapovali data (test vytvořený RowGen) z relačního schématu do tabulek dimenzí pro schéma Hvězda. Konkrétně tyto skripty načítají data z tabulky Category do tabulky Category_Dim , Dept to Dept_Dim, Project do Project_Dim, Item do Item_Dim a Emp do Emp_Dim.
- Vyplňte tabulku faktů
Použijte SortCL ke spojení dat z původních tabulek entit Sale, Emp, Project, Item_Use, Item, Category a připravte data pro novou tabulku Sale_Fact . Zde použijte druhý skript (připojit se k úloze).
Abychom vylepšili náš příklad, použijeme také SortCL k zavedení nových dimenzionálních dat do hvězdného schématu, o které se bude opírat i moje tabulka faktů. Ve výše uvedeném hvězdicovém diagramu můžete vidět tyto dodatečné tabulky, které nebyly v mém relačním schématu:Emp_Salary_Range_Dim a Item_Price_Range_Dim. Tyto tabulky jsou vytvořeny ve stejném souboru .SQL pro tabulky faktů a další tabulky dimenzí.
Tabulka Faktů potřebuje údaje emp_salary_range_id a item_price_range_id z těchto tabulek, aby reprezentovala rozsah hodnot v těchto tabulkách dimenzí. Když například načtu hodnoty rozměrových cen do datového skladu, chci je přiřadit k cenovému rozpětí:
| Item_Price | ID rozsahu | Název_rozsahu | Konec_rozsahu |
|---|---|---|---|
| 1 | Nízká | 1 | 100 |
| 2 | Střed | 101 | 500 |
| 3 | Vysoká | 501 | 999 |
Nejjednodušší způsob, jak přiřadit ID rozsahu ve skriptu úlohy (který připravuje data pro mou tabulku Sale_Fact), je použít příkaz IF-THEN-ELSE ve výstupní sekci. Viz tento článek o hodnotách segmentů pro pozadí.
Každopádně jsem celou tuto úlohu vytvořil pomocí CoSort New Join Job průvodce ve Workbench. A jakmile jsem to spustil, moje tabulka faktů byla naplněna:
 Zobrazení tabulky Sale_Fact v IRI Workbench DSE
Zobrazení tabulky Sale_Fact v IRI Workbench DSE
Závěr
Hlavní výhodou reprezentace dimenzionálních dat je snížení složitosti databázové struktury. Díky tomu je pro lidi snazší porozumět databázi a zapisovat do ní dotazy tím, že se minimalizuje počet tabulek, a tedy i počet požadovaných spojení. Jak již bylo zmíněno dříve, dimenzionální modely také optimalizují výkon dotazů. Má však slabost i sílu. Pevná struktura hvězdicového schématu omezuje dotazy. Protože to usnadňuje psaní nejběžnějších dotazů, omezuje také způsob, jakým lze data analyzovat.
GUI IRI Workbench pro Voracity má výkonnou a komplexní sadu nástrojů, které zjednodušují integraci dat, včetně vytváření, údržby a rozšiřování datových skladů. S tímto intuitivním a snadno použitelným rozhraním Voracity usnadňuje rychlé, flexibilní, komplexní vytváření procesů ETL (extrakce, transformace, načítání) zahrnujících datové struktury napříč různými platformami.
V operacích ETL jsou data extrahována z různých zdrojů, transformována samostatně a načtena do datového skladu a případně dalších cílů. Budování procesu ETL je potenciálně jedním z největších úkolů budování skladu; je to složité a časově náročné. Přístup IRI ETL podporuje tento proces vysoce účinným a na databázi nezávislým způsobem tím, že provádí veškerou integraci dat a přípravu v systému souborů.
[1] Pokud jste pes na syntaxi, vezměte na vědomí, že skripty SortCL používané v produktu IRI CoSort nebo platformě IRI Voracity podporují stejnou syntaxi a definice dat jako IRI RowGen pro generování testovacích dat, IRI NextForm pro migraci dat a IRI FieldShield pro maskování dat. Všechny tyto nástroje jsou podporovány v grafickém uživatelském rozhraní IRI Workbench a jejich metadata lze také sdílet a spravovat týmem pro řízení verzí, vedení úloh/dat a zabezpečení v cloudu.
[2] Zobrazení E-R diagramů v IRI Workbench:
- Vyberte Nový projekt IRI a vytvořte novou složku
- Vyberte tuto složku a zvýrazněte všechny použitelné databázové tabulky v Průzkumníku zdrojů dat; poté klikněte pravým tlačítkem na IRI, Nový ER-diagram
- Bude vytvořen soubor (Schema.QA)
- Klikněte pravým tlačítkem na tento soubor a vyberte Nová reprezentace, Nový diagram vztahu entit.
[3] Prvky ER diagramu, které ilustrují takové modely, zahrnují:
- definované typy entit
- definované atributy
- vztah mezi typy entit
- celkový obrázek nebo koncepční diagram
[4] IRI FACT a SQL*Loader jsou možnosti hromadné extrakce a načítání.