Úvod
Bez ohledu na to, jak moc se snažíme navrhovat a vyvíjet aplikace, chyby se vždy vyskytnou. Existují dvě obecné kategorie – syntaktické nebo logické chyby mohou být buď programové chyby, nebo důsledky nesprávného návrhu databáze. V opačném případě se může zobrazit chyba kvůli nesprávnému zadání uživatele.
T-SQL (programovací jazyk SQL Server) umožňuje zpracování obou typů chyb. Můžete ladit aplikaci a rozhodnout se, co musíte udělat, abyste se v budoucnu vyhnuli chybám.
Většina aplikací vyžaduje protokolování chyb, implementaci uživatelsky přívětivého hlášení chyb a, je-li to možné, zpracovávat chyby a pokračovat ve spouštění aplikace.
Uživatelé řeší chyby na úrovni příkazů. To znamená, že když spustíte dávku SQL příkazů a problém se stane v posledním příkazu, vše, co tomuto problému předchází, se zapíše do databáze jako implicitní transakce. Možná to není to, co si přejete.
Relační databáze jsou optimalizovány pro dávkové provádění příkazů. Proto musíte provést dávku příkazů jako jednu jednotku a selhat všechny příkazy, pokud jeden příkaz selže. Toho lze dosáhnout pomocí transakcí. Tento článek se zaměří jak na zpracování chyb, tak na transakce, protože tato témata spolu úzce souvisí.
Zpracování chyb SQL
Abychom mohli simulovat výjimky, musíme je vytvářet opakovatelným způsobem. Začněme tím nejjednodušším příkladem – dělení nulou:
SELECT 1/0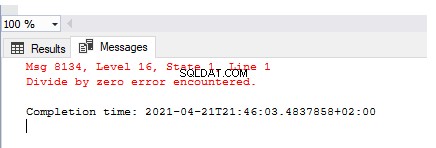
Výstup popisuje vyvolanou chybu – Zjištěna chyba dělení nulou . Tato chyba však nebyla zpracována, zaznamenána ani upravena tak, aby vytvořila uživatelsky přívětivou zprávu.
Zpracování výjimek začíná vložením příkazů, které chcete provést, do bloku BEGIN TRY…END TRY.
SQL Server zpracovává (zachycuje) chyby v bloku BEGIN CATCH…END CATCH, kde můžete zadat vlastní logiku pro protokolování nebo zpracování chyb.
Příkaz BEGIN CATCH musí následovat bezprostředně po příkazu END TRY. Provedení je pak předáno z bloku TRY do bloku CATCH při prvním výskytu chyby.
Zde se můžete rozhodnout, jak zacházet s chybami, zda chcete protokolovat data o vyvolaných výjimkách nebo vytvořit uživatelsky přívětivou zprávu.
SQL Server má vestavěné funkce, které vám mohou pomoci získat podrobnosti o chybě:
- ERROR_NUMBER():Vrátí počet chyb SQL.
- ERROR_SEVERITY():Vrací úroveň závažnosti, která označuje typ problému a jeho úroveň. Úrovně 11 až 16 může ovládat uživatel.
- ERROR_STATE():Vrací číslo chybového stavu a poskytuje další podrobnosti o vyvolané výjimce. Číslo chyby použijete k vyhledání konkrétních podrobností o chybě ve znalostní bázi společnosti Microsoft.
- ERROR_PROCEDURE():Vrací název procedury nebo spouštěče, ve kterém byla vyvolána chyba, nebo NULL, pokud se chyba v proceduře nebo spouštěči nevyskytla.
- ERROR_LINE():Vrátí číslo řádku, na kterém došlo k chybě. Může to být číslo řádku procedur nebo spouštěčů nebo číslo řádku v dávce.
- ERROR_MESSAGE():Vrací text chybové zprávy.
Následující příklad ukazuje, jak zacházet s chybami. První příklad obsahuje Dělení nulou chyba, zatímco druhý výrok je správný.
BEGIN TRY
PRINT 1/0
SELECT 'Correct text'
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH

Pokud je druhý příkaz proveden bez zpracování chyb (SELECT ‚Správný text‘), bude úspěšný.
Protože implementujeme vlastní zpracování chyb v bloku TRY-CATCH, provádění programu je předáno bloku CATCH po chybě v prvním příkazu a druhý příkaz nebyl nikdy proveden.
Tímto způsobem můžete upravit text zadaný uživateli a kontrolovat, co se stane, pokud dojde k chybě lépe. Například zaznamenáváme chyby do tabulky protokolů pro další analýzu.
Používání transakcí
Obchodní logika může určit, že vložení prvního příkazu selže, když selže druhý příkaz, nebo že budete muset opakovat změny prvního příkazu při selhání druhého příkazu. Použití transakcí vám umožní provést dávku příkazů jako jednu jednotku, která buď selže, nebo uspěje.
Následující příklad ukazuje použití transakcí.
Nejprve vytvoříme tabulku pro testování uložených dat. Potom použijeme dvě transakce uvnitř bloku TRY-CATCH k simulaci toho, co se děje, pokud část transakce selže.
Příkaz CATCH použijeme s příkazem XACT_STATE(). Funkce XACT_STATE() se používá ke kontrole, zda transakce stále existuje. V případě, že se transakce automaticky vrátí zpět, ROLLBACK TRANSACTION vytvoří novou výjimku.
Získejte kořist na níže uvedeném kódu:
-- CREATE TABLE TEST_TRAN(VALS INT)
BEGIN TRY
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(1);
COMMIT TRANSACTION
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(2);
INSERT INTO TEST_TRAN(VALS) VALUES('A');
INSERT INTO TEST_TRAN(VALS) VALUES(3);
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() > 0 ROLLBACK TRANSACTION
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
SELECT * FROM TEST_TRAN
-- DROP TABLE TEST_TRAN
Obrázek ukazuje hodnoty v tabulce TEST_TRAN a chybové zprávy:
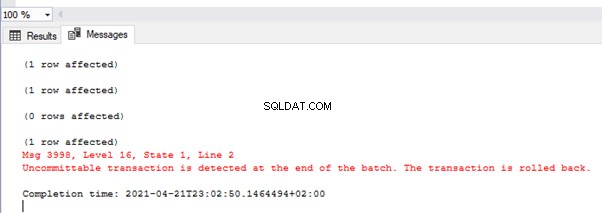
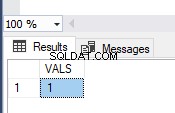
Jak vidíte, byla potvrzena pouze první hodnota. Ve druhé transakci jsme měli chybu převodu typu ve druhém řádku. Celá dávka se tedy vrátila zpět.
Tímto způsobem můžete kontrolovat, jaká data vstupují do databáze a jak se zpracovávají dávky.
Generování vlastní chybové zprávy v SQL
Někdy chceme vytvořit vlastní chybové zprávy. Obvykle jsou určeny pro scénáře, kdy víme, že může nastat problém. Můžeme vytvořit vlastní zprávy, které říkají, že se něco stalo, aniž bychom uváděli technické podrobnosti. K tomu používáme klíčové slovo THROW.
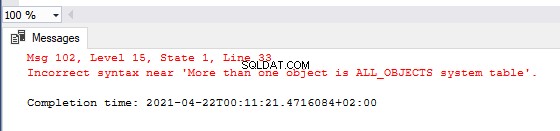
BEGIN TRY
IF ( SELECT COUNT(sys.all_objects) > 1 )
THROW ‘More than one object is ALL_OBJECTS system table’
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
Nebo bychom rádi měli katalog vlastních chybových zpráv pro kategorizaci a konzistenci monitorování a hlášení chyb. SQL Server nám umožňuje předdefinovat kód chybové zprávy, závažnost a stav.
K přidání vlastních chybových zpráv se používá uložená procedura s názvem „sys.sp_addmessage“. Můžeme jej použít k vyvolání chybové zprávy na více místech.
Můžeme zavolat RAISERROR a odeslat číslo zprávy jako parametr místo toho, abychom napevno zakódovali stejné podrobnosti o chybě na více místech v kódu.
Spuštěním vybraného kódu zespodu přidáme vlastní chybu do SQL Server, vyvoláme ji a poté použijeme sys.sp_dropmessage pro zrušení zadané uživatelem definované chybové zprávy:
exec sys.sp_addmessage @msgnum=55000, @severity = 11,
@msgtext = 'My custom error message'
GO
RAISERROR(55000,11,1)
GO
exec sys.sp_dropmessage @msgnum=55000
GO
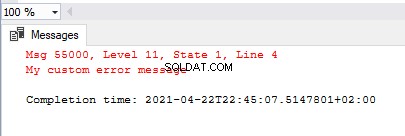
Také můžeme zobrazit všechny zprávy v SQL Server spuštěním formuláře dotazu níže. Naše vlastní chybová zpráva je viditelná jako první položka v sadě výsledků:
SELECT * FROM master.dbo.sysmessages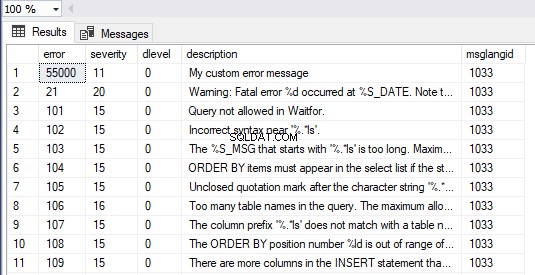
Vytvořte systém pro protokolování chyb
Vždy je užitečné zaznamenat chyby pro pozdější ladění a zpracování. Můžete také umístit spouštěče do těchto protokolovaných tabulek a dokonce si nastavit e-mailový účet a být trochu kreativní ve způsobu upozorňování lidí, když dojde k chybě.
Pro protokolování chyb vytváříme tabulku s názvem DBError_Log , který lze použít k uložení podrobných dat protokolu:
CREATE TABLE DBError_Log
(
DBError_Log_ID INT IDENTITY(1, 1) PRIMARY KEY,
UserName VARCHAR(100),
ErrorNumber INT,
ErrorState INT,
ErrorSeverity INT,
ErrorLine INT,
ErrorProcedure VARCHAR(MAX),
ErrorMessage VARCHAR(MAX),
ErrorDateTime DATETIME
);
Pro simulaci mechanismu protokolování vytváříme GenError uložená procedura, která generuje Dělení nulou chyba a zaznamená chybu do DBError_Log tabulka:
CREATE PROCEDURE dbo.GenError
AS
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
INSERT INTO dbo.DBError_Log
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE()
);
END CATCH
GO
EXEC dbo.GenError
SELECT * FROM dbo.DBError_Log
DBError_Log tabulka obsahuje všechny informace, které potřebujeme k odladění chyby. Poskytuje také další informace o postupu, který chybu způsobil. Ačkoli se to může zdát jako triviální příklad, můžete tuto tabulku rozšířit o další pole nebo ji použít k naplnění vlastními výjimkami.
Závěr
Pokud chceme udržovat a ladit aplikace, chceme alespoň nahlásit, že se něco pokazilo, a také to pod kapotou přihlásit. Když máme aplikaci na produkční úrovni, kterou používají miliony uživatelů, klíčem k ladění problémů za běhu je konzistentní a ohlašovatelné zpracování chyb.
I když bychom mohli zaznamenat původní chybu do protokolu chyb databáze, uživatelé by měli vidět přátelštější zprávu. Bylo by tedy vhodné implementovat vlastní chybové zprávy, které jsou vrženy do volajících aplikací.
Ať implementujete jakýkoli návrh, musíte protokolovat a zpracovávat uživatelské a systémové výjimky. Tento úkol není se serverem SQL obtížný, ale je třeba jej naplánovat od začátku.
Přidání operací zpracování chyb do databází, které již běží v produkci, může znamenat vážné předělání kódu a těžko dohledatelné problémy s výkonem.