Ve svých letošních příspěvcích jsem diskutoval o prudkých reakcích na různé typy čekání a v tomto příspěvku budu pokračovat v tématu statistiky čekání a diskutovat o PAGEIOLATCH_XX Počkejte. Říkám "počkej", ale existuje opravdu několik druhů PAGEIOLATCH čeká, což jsem označil XX na konci. Nejběžnější příklady jsou:
PAGEIOLATCH_SH– (SH jsou) čekají na přenesení stránky datového souboru z disku do oblasti vyrovnávací paměti, aby bylo možné přečíst její obsahPAGEIOLATCH_EXneboPAGEIOLATCH_UP– (EX včetně nebo NAHORU date) čeká na přenesení stránky datového souboru z disku do oblasti vyrovnávacích pamětí, aby bylo možné upravit její obsah
Z nich je zdaleka nejběžnějším typem PAGEIOLATCH_SH .
Když je tento typ čekání na serveru nejrozšířenější, prudká reakce je taková, že I/O subsystém musí mít problém, a proto by se mělo zaměřit vyšetřování.
První věc, kterou musíte udělat, je porovnat PAGEIOLATCH_SH počet a doba čekání oproti vaší základní linii. Pokud je objem čekání víceméně stejný, ale trvání každého čekání na čtení se výrazně prodloužilo, pak bych se obával problému I/O subsystému, například:
- Špatná konfigurace/porucha na úrovni I/O subsystému
- Latence sítě
- Další I/O zátěž způsobující spory s naší zátěží
- Konfigurace replikace/zrcadlení synchronního I/O subsystému
Podle mých zkušeností je vzorem často číslo PAGEIOLATCH_SH Čekání se podstatně zvýšilo od základního (normálního) množství a doba čekání se také prodloužila (tj. doba pro čtecí I/O se prodloužila), protože velký počet čtení přetěžuje I/O subsystém. Toto není problém I/O subsystému – to je SQL Server, který řídí více I/O, než by měl. Fokus se nyní potřebuje přepnout na SQL Server, aby se zjistila příčina nadbytečných I/O.
Příčiny velkého počtu čtených I/O
SQL Server má dva typy čtení:logické I/O a fyzické I/O. Když část Access Methods Storage Engine potřebuje přistupovat ke stránce, požádá fond vyrovnávacích pamětí o ukazatel na stránku v paměti (tzv. logický I/O) a fond vyrovnávacích pamětí zkontroluje prostřednictvím svých metadat, zda je tato stránka již v paměti.
Pokud je stránka v paměti, fond vyrovnávacích pamětí udává metodám přístupu ukazatel a I/O zůstane logickým I/O. Pokud stránka není v paměti, fond vyrovnávacích pamětí vydá „skutečný“ I/O (nazývaný fyzický I/O) a vlákno musí čekat na dokončení – dojde k PAGEIOLATCH_XX Počkejte. Jakmile se I/O dokončí a ukazatel je k dispozici, vlákno je upozorněno a může pokračovat v běhu.
V ideálním světě by se celá vaše pracovní zátěž vešla do paměti, a tak jakmile se fond vyrovnávacích pamětí „zahřeje“ a pojme veškerou pracovní zátěž, není potřeba žádné další čtení, pouze zápis aktualizovaných dat. Není to však ideální svět a většina z vás takový luxus nemá, takže některá čtení jsou nevyhnutelná. Dokud se počet přečtení bude pohybovat kolem vašeho základního množství, není problém.
Když je náhle a neočekávaně vyžadováno velké množství čtení, je to známkou toho, že došlo k významné změně v pracovní zátěži, množství paměti vyrovnávací paměti dostupné pro ukládání kopií stránek v paměti nebo v obojím.
Zde jsou některé možné základní příčiny (nejedná se o vyčerpávající seznam):
- Tlak externí paměti Windows na SQL Server způsobí, že správce paměti sníží velikost fondu vyrovnávacích pamětí
- Naplánujte nafouknutí mezipaměti způsobující vypůjčení další paměti z fondu vyrovnávacích pamětí
- Plán dotazů provádějící prohledávání tabulky/seskupeného indexu (místo hledání indexu) z důvodu:
- zvýšení objemu pracovní zátěže
- problém s čicháním parametrů
- požadovaný index bez klastrů, který byl zrušen nebo změněn
- implicitní konverze
Jedním vzorem, který je třeba hledat a který by naznačoval, že příčinou je skenování tabulky/shlukovaného indexu, je také velký počet CXPACKET čeká spolu s PAGEIOLATCH_SH čeká. Toto je běžný vzorec, který označuje výskyt velkých paralelních prohledávání tabulek/shlukovaných indexů.
Ve všech případech se můžete podívat na to, jaký plán dotazů způsobuje PAGEIOLATCH_SH čeká pomocí sys.dm_os_waiting_tasks a další DMV a kód k tomu můžete získat v mém příspěvku na blogu zde. Pokud máte k dispozici monitorovací nástroj třetí strany, může vám pomoci identifikovat viníka, aniž byste si ušpinili ruce.
Ukázkový pracovní postup s SQL Sentry a Plan Explorer
V jednoduchém (samozřejmě vykonstruovaném) příkladu předpokládejme, že jsem na klientském systému používajícím sadu nástrojů SQL Sentry a v zobrazení řídicího panelu SQL Sentry uvidíme prudký nárůst počtu I/O čekání, jak je znázorněno níže:
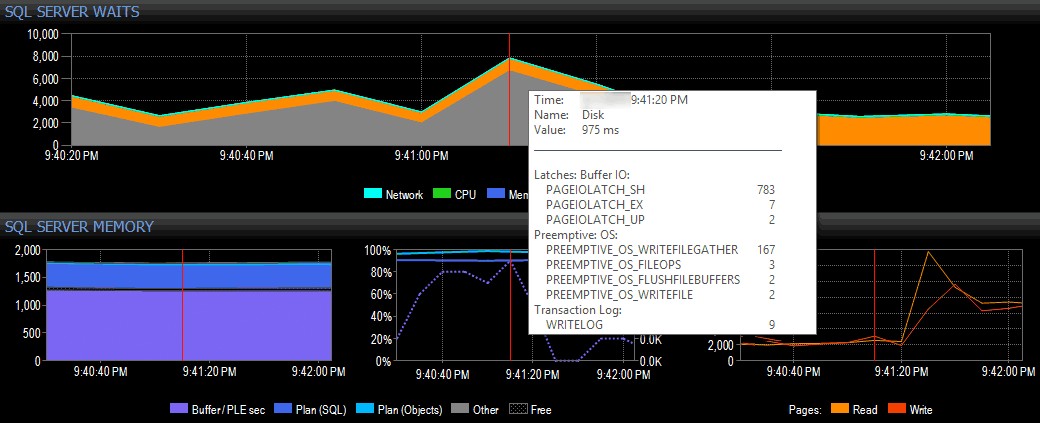
Zjištění špičky v I/O čekání v SQL Sentry
Rozhodnu se to prozkoumat tak, že kliknu pravým tlačítkem na vybraný časový interval kolem doby špičky a poté přeskočím na zobrazení Top SQL, které mi ukáže nejdražší dotazy, které byly provedeny:
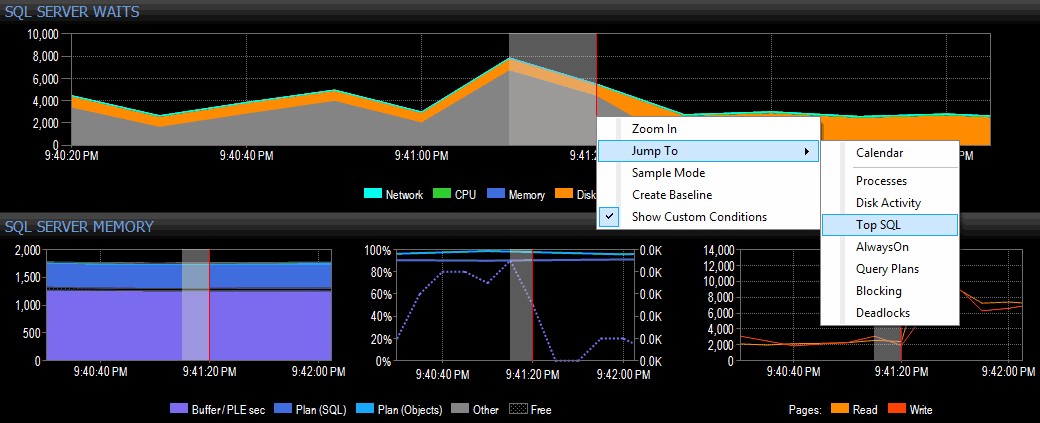
Zvýraznění časového rozsahu a přechod do Top SQL
V tomto zobrazení mohu vidět, které dlouhotrvající dotazy nebo dotazy s vysokým I/O byly spuštěny v době, kdy došlo ke špičce, a pak se rozhodnout proniknout do jejich plánů dotazů (v tomto případě existuje pouze jeden dlouhotrvající dotaz, který běžel téměř minutu):
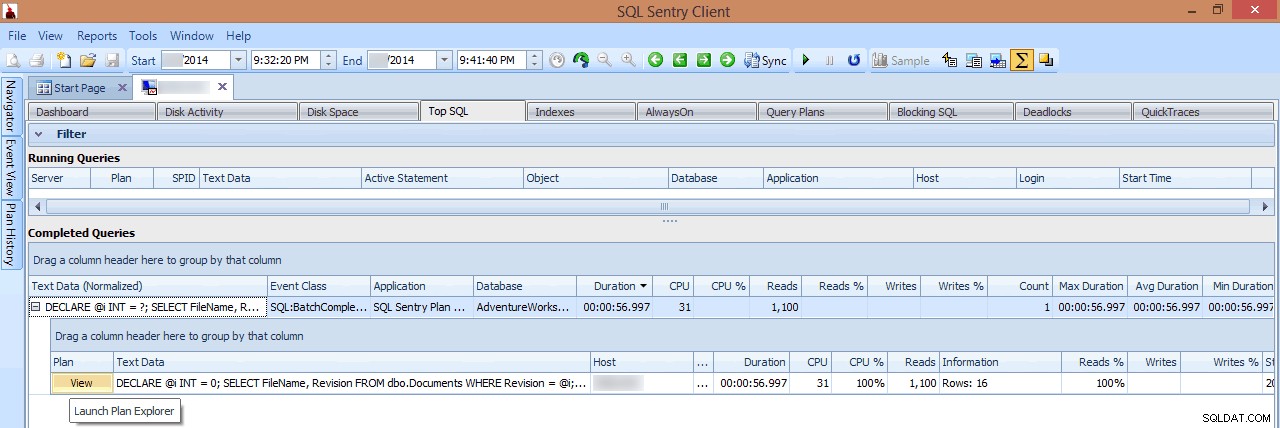
Kontrola dlouhotrvajícího dotazu v Top SQL
Pokud se podívám na plán v klientovi SQL Sentry nebo jej otevřu v SQL Sentry Plan Explorer, okamžitě vidím několik problémů. Počet čtení potřebných k vrácení 7 řádků se zdá být příliš vysoký, rozdíl mezi odhadovanými a skutečnými řádky je velký a plán ukazuje indexové skenování tam, kde bych očekával hledání:
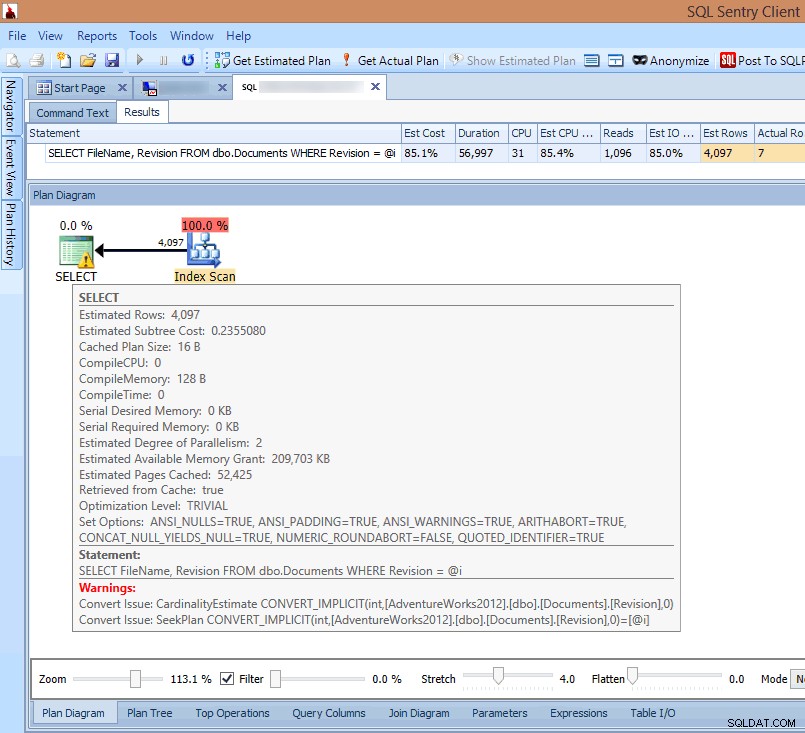
Zobrazení implicitních upozornění na konverze v plánu dotazů
Příčina toho všeho je zvýrazněna ve varování na SELECT operátor:Je to implicitní konverze!
Implicitní převody jsou zákeřným problémem způsobeným neshodou mezi datovým typem predikátu vyhledávání a datovým typem prohledaného sloupce nebo výpočtem prováděným na sloupci tabulky namísto predikátu vyhledávání. V obou případech nemůže SQL Server použít hledání indexu ve sloupci tabulky a musí místo toho použít skenování.
To se může objevit ve zdánlivě nevinném kódu a běžným příkladem je použití výpočtu data. Pokud máte tabulku, která ukládá věk zákazníků, a chcete provést výpočet, abyste zjistili, kolik je dnes starších 21 let, můžete napsat kód takto:
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
S tímto kódem je výpočet ve sloupci tabulky, takže nelze použít hledání indexu, což má za následek nevyhledatelný výraz (technicky známý jako výraz bez SARGable) a prohledávání tabulky/shlukovaného indexu. To lze vyřešit přesunem výpočtu na druhou stranu operátoru:
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
Pokud jde o to, kdy srovnání základních sloupců vyžaduje konverzi datových typů, která může způsobit implicitní konverzi, můj kolega Jonathan Kehayias napsal vynikající blogový příspěvek, který porovnává každou kombinaci datových typů a uvádí, kdy bude vyžadována implicitní konverze.
Shrnutí
Nenechte se chytit do pasti myšlenek, že přehnané PAGEIOLATCH_XX čekání je způsobeno I/O subsystémem. Podle mých zkušeností jsou obvykle způsobeny něčím, co souvisí s SQL Serverem, a tam bych začal s odstraňováním problémů.
Pokud jde o obecné statistiky čekání, více informací o jejich použití pro odstraňování problémů s výkonem naleznete v:
- Moje série příspěvků na blogu SQLskills, počínaje statistikou čekání, nebo mi prosím řekněte, kde to bolí
- Moje knihovna typů čekání a tříd Latch zde
- Můj online školicí kurz Pluralsight SQL Server:Odstraňování problémů s výkonem pomocí statistiky čekání
- Sledování SQL
V dalším článku ze série proberu další typ čekání, který je častou příčinou trhavých reakcí. Do té doby přejeme hodně štěstí při odstraňování problémů!