V části 2 této série jste přidali možnost ukládat změny provedené prostřednictvím REST API do databáze pomocí SQLAlchemy a naučili jste se serializovat tato data pro REST API pomocí Marshmallow. Připojení REST API k databázi, aby aplikace mohla provádět změny stávajících dat a vytvářet nová data, je skvělé a dělá aplikaci mnohem užitečnější a robustnější.
To je však jen část výkonu, který databáze nabízí. Ještě výkonnější funkcí je R součástí RDBMS systémy:vztahy . V databázi je vztahem schopnost spojit dvě nebo více tabulek smysluplným způsobem. V tomto článku se dozvíte, jak implementovat vztahy a změnit svou Person databáze do webové aplikace pro miniblogování.
V tomto článku se dozvíte:
- Proč je více než jedna tabulka v databázi užitečná a důležitá
- Jak spolu tabulky souvisí
- Jak vám SQLAlchemy může pomoci řídit vztahy
- Jak vám vztahy pomohou vytvořit miniblogovací aplikaci
Pro koho je tento článek určen
Část 1 této série vás provedla vytvářením rozhraní REST API a část 2 vám ukázala, jak toto rozhraní REST API připojit k databázi.
Tento článek dále rozšiřuje váš opasek s programovacími nástroji. Dozvíte se, jak vytvořit hierarchické datové struktury reprezentované jako vztahy jedna k mnoha pomocí SQLAlchemy. Kromě toho rozšíříte rozhraní REST API, které jste již vytvořili, aby poskytovalo podporu CRUD (vytváření, čtení, aktualizace a odstraňování) pro prvky v této hierarchické struktuře.
Webová aplikace představená v části 2 bude mít své soubory HTML a JavaScript výrazně upraveny tak, aby vytvořila plně funkční miniblogovací aplikaci. Konečnou verzi kódu z části 2 si můžete prohlédnout v úložišti GitHub pro daný článek.
Počkejte, až začnete vytvářet vztahy a svou miniblogovací aplikaci!
Další závislosti
Neexistují žádné nové závislosti na Pythonu nad rámec toho, co bylo požadováno pro článek 2. Ve webové aplikaci však budete používat dva nové moduly JavaScriptu, aby byly věci jednodušší a konzistentnější. Tyto dva moduly jsou následující:
- Handlebars.js je šablonovací modul pro JavaScript, podobně jako Jinja2 pro Flask.
- Moment.js je modul pro analýzu a formátování data a času, který usnadňuje zobrazování časových razítek UTC.
Nemusíte stahovat ani jeden z nich, protože webová aplikace je získá přímo z Cloudflare CDN (Content Delivery Network), jak to již děláte pro modul jQuery.
Údaje o lidech rozšířené pro blogování
V části 2 People data existovala jako slovník v build_database.py Python kód. To je to, co jste použili k naplnění databáze některými počátečními daty. Chystáte se upravit People datová struktura, která každé osobě poskytne seznam poznámek, které jsou s ní spojeny. Nové People datová struktura bude vypadat takto:
# Data to initialize database with
PEOPLE = [
{
"fname": "Doug",
"lname": "Farrell",
"notes": [
("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
("This could be useful", "2019-01-08 22:17:54"),
("Well, sort of useful", "2019-03-06 22:17:54"),
],
},
{
"fname": "Kent",
"lname": "Brockman",
"notes": [
(
"I'm going to make really profound observations",
"2019-01-07 22:17:54",
),
(
"Maybe they'll be more obvious than I thought",
"2019-02-06 22:17:54",
),
],
},
{
"fname": "Bunny",
"lname": "Easter",
"notes": [
("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
("I'm really late delivering these!", "2019-04-06 22:17:54"),
],
},
]
Každá osoba v People slovník nyní obsahuje klíč nazvaný notes , který je spojen se seznamem obsahujícím n-tice dat. Každá n-tice v notes seznam představuje jednu poznámku obsahující obsah a časové razítko. Časová razítka jsou inicializována (spíše než dynamicky vytvářena), aby se později v REST API demonstrovalo řazení.
Každá jednotlivá osoba je spojena s více poznámkami a každá jednotlivá poznámka je spojena pouze s jednou osobou. Tato hierarchie dat je známá jako vztah jedna k mnoha, kde jeden nadřazený objekt souvisí s mnoha podřízenými objekty. Uvidíte, jak je tento vztah typu one-to-many spravován v databázi pomocí SQLAlchemy.
Přístup hrubou silou
Databáze, kterou jste vytvořili, uložila data do tabulky a tabulka je dvourozměrné pole řádků a sloupců. Mohou People bude slovník výše zastoupen v jediné tabulce řádků a sloupců? Může to být následujícím způsobem ve vaší person databázová tabulka. Bohužel, když do příkladu zahrnete všechna skutečná data, vytvoří se pro tabulku posuvník, jak uvidíte níže:
person_id | lname | fname | timestamp | content | note_timestamp |
|---|---|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01 | Super, mini aplikace pro blogování! | 2019-01-06 22:17:54 |
| 2 | Farrell | Doug | 2018-08-08 21:16:01 | To by mohlo být užitečné | 2019-01-08 22:17:54 |
| 3 | Farrell | Doug | 2018-08-08 21:16:01 | No, docela užitečné | 2019-03-06 22:17:54 |
| 4 | Brockman | Kent | 2018-08-08 21:16:01 | Provedu opravdu důkladná pozorování | 2019-01-07 22:17:54 |
| 5 | Brockman | Kent | 2018-08-08 21:16:01 | Možná budou jasnější, než jsem si myslel | 2019-02-06 22:17:54 |
| 6 | Velikonoce | Zajíček | 2018-08-08 21:16:01 | Viděl někdo moje velikonoční vajíčka? | 2019-01-07 22:47:54 |
| 7 | Velikonoce | Zajíček | 2018-08-08 21:16:01 | Doručuji je opravdu pozdě! | 2019-04-06 22:17:54 |
Výše uvedená tabulka by skutečně fungovala. Všechna data jsou reprezentována a jedna osoba je spojena se sbírkou různých poznámek.
Výhody
Koncepčně má výše uvedená struktura tabulky výhodu v tom, že je relativně jednoduchá na pochopení. Můžete dokonce udělat případ, že by data mohla být uložena do plochého souboru místo do databáze.
Díky dvourozměrné struktuře tabulky můžete tato data ukládat a používat v tabulkovém procesoru. Tabulkové kalkulátory se jako úložiště dat používaly docela dost.
Nevýhody
I když by výše uvedená struktura tabulky fungovala, má některé skutečné nevýhody.
Aby byla reprezentována sbírka poznámek, všechna data pro každou osobu se opakují pro každou jedinečnou poznámku, takže osobní data jsou nadbytečná. Pro vaše osobní údaje to není tak velký problém, protože zde není tolik sloupců. Ale představte si, že by měl člověk mnohem více sloupců. I u velkých diskových jednotek to může být problém s úložištěm, pokud pracujete s miliony řádků dat.
Mít nadbytečná data, jako je tato, může časem vést k problémům s údržbou. Co kdyby se například velikonoční zajíček rozhodl změnit jméno jako dobrý nápad. Aby to bylo možné, každý záznam obsahující jméno velikonočního zajíčka by musel být aktualizován, aby byla data konzistentní. Tento druh práce s databází může vést k nekonzistenci dat, zejména pokud práci provádí osoba, která ručně spouští SQL dotaz.
Pojmenování sloupců se stává nepohodlným. V tabulce výše je timestamp sloupec používaný ke sledování času vytvoření a aktualizace osoby v tabulce. Chcete mít podobnou funkcionalitu pro vytvoření a aktualizaci času pro poznámku, ale protože timestamp je již použit, vymyšlený název note_timestamp se používá.
Co kdybyste chtěli přidat další vztahy one-to-many k person stůl? Například zahrnout děti nebo telefonní čísla osoby. Každá osoba může mít více dětí a více telefonních čísel. To by se dalo relativně snadno udělat pro Python People slovník výše přidáním children a phone_numbers klíče s novými seznamy obsahujícími data.
Představení těchto nových vztahů typu one-to-many ve vaší person výše uvedená databázová tabulka se výrazně ztíží. Každý nový vztah typu one-to-many dramaticky zvyšuje počet řádků nezbytných k jeho reprezentaci pro každý jednotlivý záznam v podřízených datech. Kromě toho se problémy spojené s redundancí dat zvětšují a je obtížnější je zvládnout.
A konečně, data, která byste získali zpět z výše uvedené struktury tabulky, by nebyla příliš Pythonic:byl by to jen velký seznam seznamů. SQLAlchemy by vám moc nepomohla, protože vztah neexistuje.
Přístup relační databáze
Na základě toho, co jste viděli výše, je jasné, že pokus o reprezentaci i středně složité datové sady v jedné tabulce se rychle stane neovladatelným. Vzhledem k tomu, jakou alternativu databáze nabízí? Toto je místo R součástí RDBMS do hry vstupují databáze. Reprezentace vztahů odstraňuje výše nastíněné nevýhody.
Namísto snahy reprezentovat hierarchická data v jediné tabulce jsou data rozdělena do více tabulek s mechanismem, který je vzájemně propojuje. Tabulky jsou rozděleny podle sběrných čar, takže pro vaše People slovník výše, to znamená, že tam bude tabulka představující osoby a další představující poznámky. Tím se vrátí vaše původní person tabulka, která vypadá takto:
person_id | lname | fname | timestamp |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Velikonoce | Zajíček | 2018-08-08 21:16:01.886834 |
Chcete-li reprezentovat informace o nové poznámce, vytvoříte novou tabulku s názvem note . (Nezapomeňte na naši singulární konvenci pojmenování tabulek.) Tabulka vypadá takto:
note_id | person_id | content | timestamp |
|---|---|---|---|
| 1 | 1 | Super, mini aplikace pro blogování! | 2019-01-06 22:17:54 |
| 2 | 1 | To by mohlo být užitečné | 2019-01-08 22:17:54 |
| 3 | 1 | No, docela užitečné | 2019-03-06 22:17:54 |
| 4 | 2 | Provedu opravdu důkladná pozorování | 2019-01-07 22:17:54 |
| 5 | 2 | Možná budou jasnější, než jsem si myslel | 2019-02-06 22:17:54 |
| 6 | 3 | Viděl někdo moje velikonoční vajíčka? | 2019-01-07 22:47:54 |
| 7 | 3 | Doručuji je opravdu pozdě! | 2019-04-06 22:17:54 |
Všimněte si, že jako person tabulka, note tabulka má jedinečný identifikátor s názvem note_id , což je primární klíč pro note stůl. Jedna věc, která není zřejmá, je zahrnutí person_id hodnotu v tabulce. K čemu se to používá? To je to, co vytváří vztah k person stůl. Zatímco note_id je primární klíč pro tabulku, person_id je to, co je známé jako cizí klíč.
Cizí klíč poskytuje každý záznam v note tabulka primární klíč person záznam, se kterým je spojen. Pomocí tohoto může SQLAlchemy shromáždit všechny poznámky spojené s každou osobou připojením person.person_id primární klíč k note.person_id cizí klíč, vytvoření vztahu.
Výhody
Rozdělením datové sady do dvou tabulek a zavedením konceptu cizího klíče jste udělali data trochu složitější na přemýšlení a vyřešili jste nevýhody reprezentace jedné tabulky. SQLAlchemy vám pomůže zakódovat zvýšenou složitost poměrně snadno.
Data již nejsou v databázi nadbytečná. Pro každou osobu, kterou chcete uložit do databáze, existuje pouze jedna osoba. Okamžitě se tak vyřeší problémy se skladováním a výrazně se zjednoduší údržba.
Pokud by velikonoční zajíček přesto chtěl změnit jména, museli byste změnit pouze jeden řádek v person tabulka a vše ostatní související s tímto řádkem (jako note tabulka) okamžitě využije změny.
Pojmenování sloupců je konzistentnější a smysluplnější. Protože údaje o osobě a poznámce existují v samostatných tabulkách, lze časové razítko vytvoření a aktualizace pojmenovat konzistentně v obou tabulkách, protože v tabulkách nedochází ke konfliktu jmen.
Navíc již nebudete muset vytvářet permutace každého řádku pro nové vztahy typu one-to-many, které byste mohli chtít reprezentovat. Vezměte naše children a phone_numbers příklad z dřívějška. Implementace by vyžadovala child a phone_number tabulky. Každá tabulka by obsahovala cizí klíč person_id přiřadit jej zpět k person tabulka.
Pomocí SQLAlchemy by byla data, která byste získali zpět z výše uvedených tabulek, bezprostředně užitečnější, protože to, co byste získali, je objekt pro každý řádek osoby. Tento objekt má pojmenované atributy ekvivalentní sloupcům v tabulce. Jedním z těchto atributů je seznam Python obsahující související objekty poznámek.
Nevýhody
Tam, kde byl přístup hrubou silou srozumitelnější, koncept cizích klíčů a vztahů činí uvažování o datech poněkud abstraktnějším. Na tuto abstrakci je třeba myslet u každého vztahu, který mezi tabulkami vytvoříte.
Využití vztahů znamená zavázat se používat databázový systém. Toto je další nástroj k instalaci, učení a údržbě nad rámec aplikace, která skutečně používá data.
Modely SQLAlchemy
Chcete-li použít dvě výše uvedené tabulky a vztah mezi nimi, budete muset vytvořit modely SQLAlchemy, které budou znát obě tabulky a vztah mezi nimi. Zde je SQLAlchemy Person model z části 2, aktualizovaný tak, aby zahrnoval vztah ke sbírce notes :
1class Person(db.Model):
2 __tablename__ = 'person'
3 person_id = db.Column(db.Integer, primary_key=True)
4 lname = db.Column(db.String(32))
5 fname = db.Column(db.String(32))
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
9 notes = db.relationship(
10 'Note',
11 backref='person',
12 cascade='all, delete, delete-orphan',
13 single_parent=True,
14 order_by='desc(Note.timestamp)'
15 )
Řádky 1 až 8 výše uvedené třídy Python vypadají přesně jako to, co jste vytvořili dříve v části 2. Řádky 9 až 16 vytvářejí nový atribut v Person třída s názvem notes . Tyto nové notes atributy jsou definovány v následujících řádcích kódu:
-
Řádek 9: Stejně jako ostatní atributy třídy vytváří tento řádek nový atribut s názvem
notesa nastaví ji na stejnou instanci objektu s názvemdb.relationship. Tento objekt vytváří vztah, který přidáváte kPersonclass a je vytvořen se všemi parametry definovanými v následujících řádcích. -
Řádek 10: Řetězcový parametr
'Note'definuje třídu SQLAlchemy, kterou jePersontřída bude souviset.Notetřída ještě není definována, proto je zde uveden řetězec. Toto je dopředný odkaz a pomáhá řešit problémy, které by pořadí definic mohlo způsobit, když je potřeba něco, co není definováno až později v kódu.'Note'řetězec umožňujePersontřídy a najděteNoteclass za běhu, což je po obouPersonaNotebyly definovány. -
Řádek 11:
backref='person'parametr je složitější. Vytváří to, co je vNoteznámé jako zpětná reference objektů. Každá instanceNoteobjekt bude obsahovat atribut nazvanýperson.personatribut odkazuje na nadřazený objekt, na který se vztahuje konkrétníNoteinstance je spojena s. Mít odkaz na nadřazený objekt (personv tomto případě) v potomkovi může být velmi užitečné, pokud váš kód iteruje přes poznámky a musí obsahovat informace o nadřazeném prvku. To se v kódu vykreslování displeje stává překvapivě často. -
Řádek 12:
cascade='all, delete, delete-orphan'Parametr určuje, jak zacházet s instancemi objektu poznámky, když jsou provedeny změny v nadřazenéPersoninstance. Například kdyžPersonPokud je objekt odstraněn, SQLAlchemy vytvoří SQL potřebné k odstraněníPersonz databáze. Tento parametr mu navíc říká, že má také odstranit všechnyNoteinstance s tím spojené. Více o těchto možnostech si můžete přečíst v dokumentaci SQLAlchemy. -
Řádek 13:
single_parent=Trueparametr je povinný, pokuddelete-orphanje součástí předchozícascadeparametr. To říká SQLAlchemy, aby nepovolila osamocenouNoteinstance (Notebez nadřazenéPersonobjekt) existovat, protože každáNotemá jednoho rodiče. -
Řádek 14:
order_by='desc(Note.timestamp)'parametr říká SQLAlchemy, jak tříditNoteinstance spojené sPerson. KdyžPersonobjekt se načte, ve výchozím nastavenínotesseznam atributů bude obsahovatNotepředměty v neznámém pořadí. SQLAlchemydesc(...)funkce seřadí poznámky v sestupném pořadí od nejnovější po nejstarší. Pokud by tento řádek byl místo tohoorder_by='Note.timestamp', SQLAlchemy by ve výchozím nastavení používalaasc(...)a seřadit noty ve vzestupném pořadí, od nejstarší po nejnovější.
Nyní vaše Person model má nové notes a to představuje vztah jedna k mnoha k Note objektů, budete muset definovat model SQLAlchemy pro Note :
1class Note(db.Model):
2 __tablename__ = 'note'
3 note_id = db.Column(db.Integer, primary_key=True)
4 person_id = db.Column(db.Integer, db.ForeignKey('person.person_id'))
5 content = db.Column(db.String, nullable=False)
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
Note class definuje atributy tvořící poznámku, jak je vidět v našem ukázkovém note databázová tabulka shora. Atributy jsou definovány zde:
-
Řádek 1 vytvoří
Notetřídy, dědící zdb.Model, přesně jako jste to udělali předtím při vytvářeníPersontřída. -
Řádek 2 říká třídě, jakou databázovou tabulku má použít k uložení
Noteobjektů. -
Řádek 3 vytvoří
note_idatribut, který jej definuje jako celočíselnou hodnotu a jako primární klíč proNoteobjekt. -
Řádek 4 vytvoří
person_ida definuje jej jako cizí klíč, který souvisí sNotetřídy naPersontřídy pomocíperson.person_idprimární klíč. Toto aPerson.notesatribut, jak SQLAlchemy ví, co dělat při interakci sPersonaNoteobjektů. -
Řádek 5 vytvoří
contentatribut, který obsahuje skutečný text poznámky. Hodnotanullable=FalseParametr označuje, že je v pořádku vytvářet nové poznámky, které nemají žádný obsah. -
Řádek 6 vytvoří
timestampatribut a přesně jakoPersontřída, obsahuje čas vytvoření nebo aktualizace pro kteroukoli konkrétníNoteinstance.
Inicializovat databázi
Nyní, když jste aktualizovali Person a vytvořil Note modely, použijete je k přebudování testovací databáze people.db . Uděláte to aktualizací souboru build_database.py kód z části 2. Takto bude kód vypadat:
1import os
2from datetime import datetime
3from config import db
4from models import Person, Note
5
6# Data to initialize database with
7PEOPLE = [
8 {
9 "fname": "Doug",
10 "lname": "Farrell",
11 "notes": [
12 ("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
13 ("This could be useful", "2019-01-08 22:17:54"),
14 ("Well, sort of useful", "2019-03-06 22:17:54"),
15 ],
16 },
17 {
18 "fname": "Kent",
19 "lname": "Brockman",
20 "notes": [
21 (
22 "I'm going to make really profound observations",
23 "2019-01-07 22:17:54",
24 ),
25 (
26 "Maybe they'll be more obvious than I thought",
27 "2019-02-06 22:17:54",
28 ),
29 ],
30 },
31 {
32 "fname": "Bunny",
33 "lname": "Easter",
34 "notes": [
35 ("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
36 ("I'm really late delivering these!", "2019-04-06 22:17:54"),
37 ],
38 },
39]
40
41# Delete database file if it exists currently
42if os.path.exists("people.db"):
43 os.remove("people.db")
44
45# Create the database
46db.create_all()
47
48# Iterate over the PEOPLE structure and populate the database
49for person in PEOPLE:
50 p = Person(lname=person.get("lname"), fname=person.get("fname"))
51
52 # Add the notes for the person
53 for note in person.get("notes"):
54 content, timestamp = note
55 p.notes.append(
56 Note(
57 content=content,
58 timestamp=datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S"),
59 )
60 )
61 db.session.add(p)
62
63db.session.commit()
Výše uvedený kód pochází z části 2 s několika změnami, které vytvořily vztah jedna k mnoha mezi Person a Note . Zde jsou aktualizované nebo nové řádky přidané do kódu:
-
Řádek 4 byl aktualizován tak, aby importoval
Notedříve definovaná třída. -
Řádky 7 až 39 obsahovat aktualizované
PEOPLEslovník obsahující naše osobní údaje spolu se seznamem poznámek spojených s každou osobou. Tato data budou vložena do databáze. -
Řádky 49 až 61 iterujte přes
PEOPLEslovník, získává každouPersona pomocí toho vytvořitPersonobjekt. -
Řádek 53 iteruje přes
person.notesseznam, získání každénotespostupně. -
Řádek 54 rozbalí
contentatimestampz každénotesn-tice. -
Řádek 55 až 60 vytvoří
Noteobjekt a připojí jej ke kolekci osobních poznámek pomocíp.notes.append(). -
Řádek 61 přidá
Personobjektpk relaci databáze. -
Řádek 63 odevzdá veškerou aktivitu v relaci do databáze. V tomto okamžiku jsou všechna data zapsána
personanotetabulky vpeople.dbdatabázový soubor.
Můžete vidět, že pracujete s notes kolekce v Person instance objektu p je stejně jako práce s jakýmkoli jiným seznamem v Pythonu. SQLAlchemy se stará o základní informace o vztahu jedna k mnoha, když db.session.commit() hovor je uskutečněn.
Například stejně jako Person instance má pole primárního klíče person_id inicializován SQLAlchemy, když je vázán na databázi, instance Note budou mít inicializována pole primárního klíče. Kromě toho Note cizí klíč person_id bude také inicializován s hodnotou primárního klíče Person instance, se kterou je spojen.
Zde je příklad instance Person objekt před db.session.commit() v jakémsi pseudokódu:
Person (
person_id = None
lname = 'Farrell'
fname = 'Doug'
timestamp = None
notes = [
Note (
note_id = None
person_id = None
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Zde je příklad Person objekt za db.session.commit() :
Person (
person_id = 1
lname = 'Farrell'
fname = 'Doug'
timestamp = '2019-02-02 21:27:10.336'
notes = [
Note (
note_id = 1
person_id = 1
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = 2
person_id = 1
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = 3
person_id = 1
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Důležitý rozdíl mezi těmito dvěma je, že primární klíč person a Note objekty byly inicializovány. Databázový stroj se o to postaral, protože objekty byly vytvořeny díky funkci automatického inkrementování primárních klíčů probírané v části 2.
Navíc person_id cizí klíč ve všech Note instance byly inicializovány tak, aby odkazovaly na svého rodiče. To se děje kvůli pořadí, ve kterém Person a Note objekty jsou vytvořeny v databázi.
SQLAlchemy si je vědoma vztahu mezi Person a Note objektů. Když Person objekt je odevzdán person databázovou tabulku, SQLAlchemy získá person_id hodnotu primárního klíče. Tato hodnota se používá k inicializaci hodnoty cizího klíče person_id v Note objekt předtím, než je odevzdán do databáze.
SQLAlchemy se stará o tuto práci v databázi kvůli informacím, které jste předali při Person.notes atribut byl inicializován pomocí db.relationship(...) objekt.
Kromě toho Person.timestamp atribut byl inicializován s aktuálním časovým razítkem.
Spuštění build_database.py program z příkazového řádku (ve virtuálním prostředí znovu vytvoří databázi s novými přírůstky a připraví ji pro použití s webovou aplikací. Tento příkazový řádek znovu sestaví databázi:
$ python build_database.py
Soubor build_database.py obslužný program nevydává žádné zprávy, pokud běží úspěšně. Pokud vyvolá výjimku, vypíše se na obrazovku chyba.
Aktualizovat REST API
Aktualizovali jste modely SQLAlchemy a použili je k aktualizaci people.db databáze. Nyní je čas aktualizovat rozhraní REST API, abyste získali přístup k novým informacím o poznámkách. Zde je REST API, které jste vytvořili v části 2:
| Akce | Slovo HTTP | Cesta adresy URL | Popis |
|---|---|---|---|
| Vytvořit | POST | /api/people | Adresa URL pro vytvoření nové osoby |
| Přečíst | GET | /api/people | Adresa URL pro čtení skupiny lidí |
| Přečíst | GET | /api/people/{person_id} | Adresa URL pro čtení jedné osoby podle person_id |
| Aktualizovat | PUT | /api/people/{person_id} | Adresa URL pro aktualizaci existující osoby pomocí person_id |
| Smazat | DELETE | /api/people/{person_id} | Adresa URL pro smazání existující osoby podle person_id |
Výše uvedené REST API poskytuje HTTP URL cesty ke sbírkám věcí a k věcem samotným. Můžete získat seznam lidí nebo komunikovat s jednou osobou z tohoto seznamu lidí. Tento styl cesty zpřesňuje to, co je vráceno, zleva doprava a postupně se stává podrobnějším.
Budete pokračovat v tomto vzoru zleva doprava, abyste získali podrobnější informace a získali přístup ke sbírkám poznámek. Zde je rozšířené rozhraní REST API, které vytvoříte za účelem poskytování poznámek webové aplikaci miniblogu:
| Akce | Slovo HTTP | Cesta adresy URL | Popis |
|---|---|---|---|
| Vytvořit | POST | /api/people/{person_id}/notes | Adresa URL pro vytvoření nové poznámky |
| Přečíst | GET | /api/people/{person_id}/notes/{note_id} | Adresa URL pro přečtení poznámky jedné osoby |
| Aktualizovat | PUT | api/people/{person_id}/notes/{note_id} | Adresa URL pro aktualizaci samostatné poznámky jedné osoby |
| Smazat | DELETE | api/people/{person_id}/notes/{note_id} | Adresa URL pro smazání jedné poznámky jedné osoby |
| Přečíst | GET | /api/notes | Adresa URL pro získání všech poznámek všech lidí seřazených podle note.timestamp |
notes mají dvě varianty součástí REST API ve srovnání s konvencí používanou v people sekce:
-
Není definována žádná URL pro získání všech
notesspojené s osobou, pouze URL pro získání jedné poznámky. Tím by bylo REST API svým způsobem kompletní, ale webová aplikace, kterou vytvoříte později, tuto funkci nepotřebuje. Therefore, it’s been left out. -
There is the inclusion of the last URL
/api/notes. This is a convenience method created for the web application. It will be used in the mini-blog on the home page to show all the notes in the system. There isn’t a way to get this information readily using the REST API pathing style as designed, so this shortcut has been added.
As in Part 2, the REST API is configured in the swagger.yml file.
Poznámka:
The idea of designing a REST API with a path that gets more and more granular as you move from left to right is very useful. Thinking this way can help clarify the relationships between different parts of a database. Just be aware that there are realistic limits to how far down a hierarchical structure this kind of design should be taken.
For example, what if the Note object had a collection of its own, something like comments on the notes. Using the current design ideas, this would lead to a URL that went something like this:/api/people/{person_id}/notes/{note_id}/comments/{comment_id}
There is no practical limit to this kind of design, but there is one for usefulness. In actual use in real applications, a long, multilevel URL like that one is hardly ever needed. A more common pattern is to get a list of intervening objects (like notes) and then use a separate API entry point to get a single comment for an application use case.
Implement the API
With the updated REST API defined in the swagger.yml file, you’ll need to update the implementation provided by the Python modules. This means updating existing module files, like models.py and people.py , and creating a new module file called notes.py to implement support for Notes in the extended REST API.
Update Response JSON
The purpose of the REST API is to get useful JSON data out of the database. Now that you’ve updated the SQLAlchemy Person and created the Note models, you’ll need to update the Marshmallow schema models as well. As you may recall from Part 2, Marshmallow is the module that translates the SQLAlchemy objects into Python objects suitable for creating JSON strings.
The updated and newly created Marshmallow schemas are in the models.py module, which are explained below, and look like this:
1class PersonSchema(ma.ModelSchema):
2 class Meta:
3 model = Person
4 sqla_session = db.session
5 notes = fields.Nested('PersonNoteSchema', default=[], many=True)
6
7class PersonNoteSchema(ma.ModelSchema):
8 """
9 This class exists to get around a recursion issue
10 """
11 note_id = fields.Int()
12 person_id = fields.Int()
13 content = fields.Str()
14 timestamp = fields.Str()
15
16class NoteSchema(ma.ModelSchema):
17 class Meta:
18 model = Note
19 sqla_session = db.session
20 person = fields.Nested('NotePersonSchema', default=None)
21
22class NotePersonSchema(ma.ModelSchema):
23 """
24 This class exists to get around a recursion issue
25 """
26 person_id = fields.Int()
27 lname = fields.Str()
28 fname = fields.Str()
29 timestamp = fields.Str()
There are some interesting things going on in the above definitions. The PersonSchema class has one new entry:the notes attribute defined in line 5. This defines it as a nested relationship to the PersonNoteSchema . It will default to an empty list if nothing is present in the SQLAlchemy notes relationship. The many=True parameter indicates that this is a one-to-many relationship, so Marshmallow will serialize all the related notes .
The PersonNoteSchema class defines what a Note object looks like as Marshmallow serializes the notes seznam. The NoteSchema defines what a SQLAlchemy Note object looks like in terms of Marshmallow. Notice that it has a person attribute. This attribute comes from the SQLAlchemy db.relationship(...) definition parameter backref='person' . The person Marshmallow definition is nested, but because it doesn’t have the many=True parameter, there is only a single person connected.
The NotePersonSchema class defines what is nested in the NoteSchema.person attribute.
Poznámka:
You might be wondering why the PersonSchema class has its own unique PersonNoteSchema class to define the notes collection attribute. By the same token, the NoteSchema class has its own unique NotePersonSchema class to define the person attribute. You may be wondering whether the PersonSchema class could be defined this way:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
notes = fields.Nested('NoteSchema', default=[], many=True)
Additionally, couldn’t the NoteSchema class be defined using the PersonSchema to define the person attribute? A class definition like this would each refer to the other, and this causes a recursion error in Marshmallow as it will cycle from PersonSchema to NoteSchema until it runs out of stack space. Using the unique schema references breaks the recursion and allows this kind of nesting to work.
People
Now that you’ve got the schemas in place to work with the one-to-many relationship between Person and Note , you need to update the person.py and create the note.py modules in order to implement a working REST API.
The people.py module needs two changes. The first is to import the Note class, along with the Person class at the top of the module. Then only read_one(person_id) needs to change in order to handle the relationship. That function will look like this:
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: Id of person to find
7 :return: person matching id
8 """
9 # Build the initial query
10 person = (
11 Person.query.filter(Person.person_id == person_id)
12 .outerjoin(Note)
13 .one_or_none()
14 )
15
16 # Did we find a person?
17 if person is not None:
18
19 # Serialize the data for the response
20 person_schema = PersonSchema()
21 data = person_schema.dump(person).data
22 return data
23
24 # Otherwise, nope, didn't find that person
25 else:
26 abort(404, f"Person not found for Id: {person_id}")
The only difference is line 12:.outerjoin(Note) . An outer join (left outer join in SQL terms) is necessary for the case where a user of the application has created a new person object, which has no notes related to it. The outer join ensures that the SQL query will return a person object, even if there are no note rows to join with.
At the start of this article, you saw how person and note data could be represented in a single, flat table, and all of the disadvantages of that approach. You also saw the advantages of breaking that data up into two tables, person and note , with a relationship between them.
Until now, we’ve been working with the data as two distinct, but related, items in the database. But now that you’re actually going to use the data, what we essentially want is for the data to be joined back together. This is what a database join does. It combines data from two tables together using the primary key to foreign key relationship.
A join is kind of a boolean and operation because it only returns data if there is data in both tables to combine. If, for example, a person row exists but has no related note row, then there is nothing to join, so nothing is returned. This isn’t what you want for read_one(person_id) .
This is where the outer join comes in handy. It’s a kind of boolean or operation. It returns person data even if there is no associated note data to combine with. This is the behavior you want for read_one(person_id) to handle the case of a newly created Person object that has no notes yet.
You can see the complete people.py in the article repository.
Notes
You’ll create a notes.py module to implement all the Python code associated with the new note related REST API definitions. In many ways, it works like the people.py module, except it must handle both a person_id and a note_id as defined in the swagger.yml configuration file. As an example, here is read_one(person_id, note_id) :
1def read_one(person_id, note_id):
2 """
3 This function responds to a request for
4 /api/people/{person_id}/notes/{note_id}
5 with one matching note for the associated person
6
7 :param person_id: Id of person the note is related to
8 :param note_id: Id of the note
9 :return: json string of note contents
10 """
11 # Query the database for the note
12 note = (
13 Note.query.join(Person, Person.person_id == Note.person_id)
14 .filter(Person.person_id == person_id)
15 .filter(Note.note_id == note_id)
16 .one_or_none()
17 )
18
19 # Was a note found?
20 if note is not None:
21 note_schema = NoteSchema()
22 data = note_schema.dump(note).data
23 return data
24
25 # Otherwise, nope, didn't find that note
26 else:
27 abort(404, f"Note not found for Id: {note_id}")
The interesting parts of the above code are lines 12 to 17:
- Line 13 begins a query against the
NoteSQLAlchemy objects and joins to the relatedPersonSQLAlchemy object comparingperson_idfrom bothPersonandNote. - Line 14 filters the result down to the
Noteobjects that has aPerson.person_idequal to the passed inperson_idparameter. - Line 15 filters the result further to the
Noteobject that has aNote.note_idequal to the passed innote_idparameter. - Line 16 returns the
Noteobject if found, orNoneif nothing matching the parameters is found.
You can check out the complete notes.py .
Updated Swagger UI
The Swagger UI has been updated by the action of updating the swagger.yml file and creating the URL endpoint implementations. Below is a screenshot of the updated UI showing the Notes section with the GET /api/people/{person_id}/notes/{note_id} expanded:
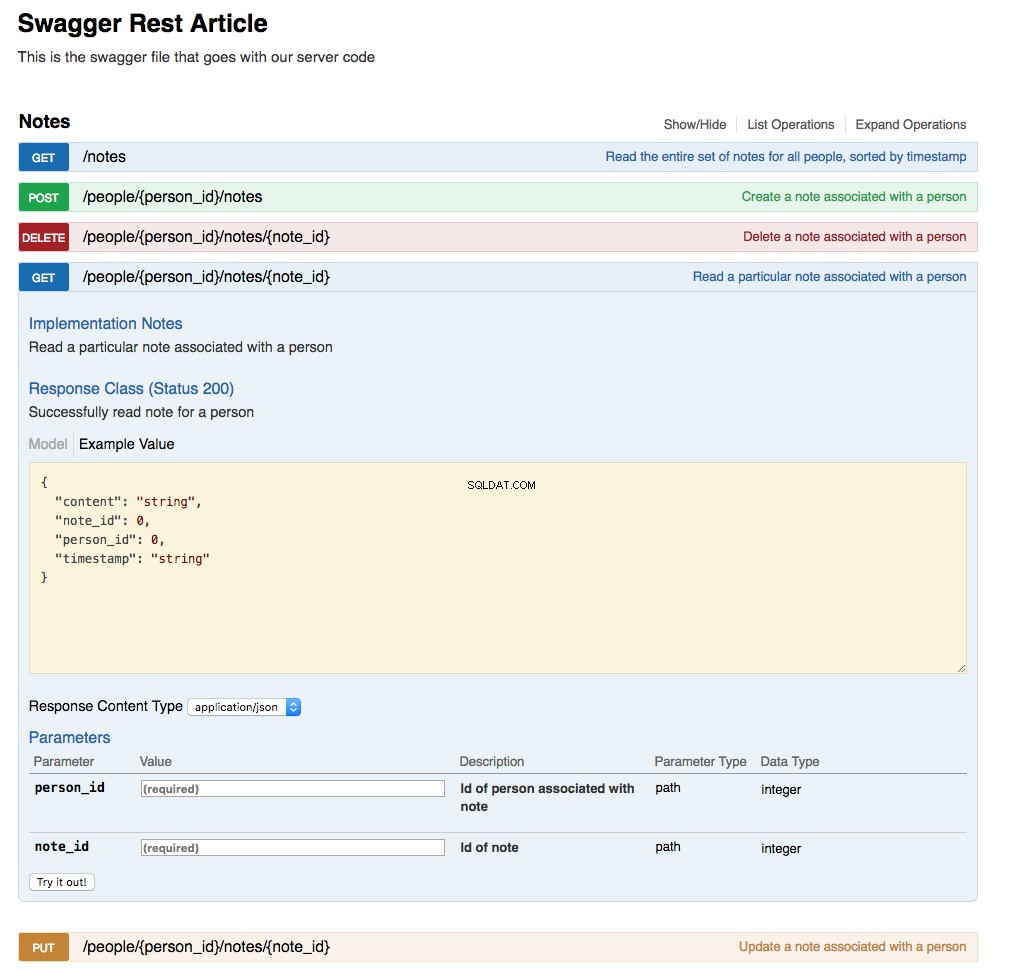
Mini-Blogging Web Application
The web application has been substantially changed to show its new purpose as a mini-blogging application. It has three pages:
-
The home page (
localhost:5000/) , which shows all of the blog messages (notes) sorted from newest to oldest -
The people page (
localhost:5000/people) , which shows all the people in the system, sorted by last name, and also allows the user to create a new person and update or delete an existing one -
The notes page (
localhost:5000/people/{person_id}/notes) , which shows all the notes associated with a person, sorted from newest to oldest, and also allows the user to create a new note and update or delete an existing one
Navigation
There are two buttons on every page of the application:
- The Home button will navigate to the home screen.
- The People button navigates to the
/peoplescreen, showing all people in the database.
These two buttons are present on every screen in the application as a way to get back to a starting point.
Home Page
Below is a screenshot of the home page showing the initialized database contents:
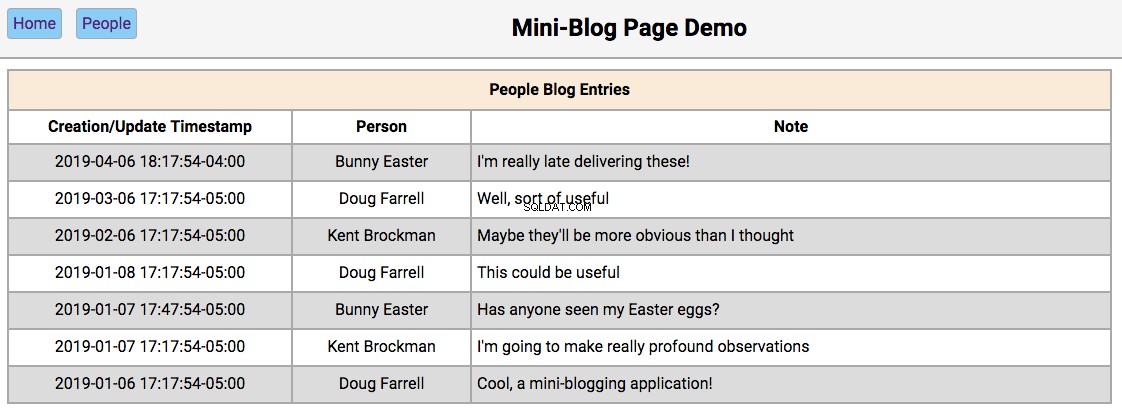
The functionality of this page works like this:
-
Double-clicking on a person’s name will take the user to the
/people/{person_id}page, with the editor section filled in with the person’s first and last names and the update and reset buttons enabled. -
Double-clicking on a person’s note will take the user to the
/people/{person_id}/notes/{note_id}page, with the editor section filled in with the note’s contents and the Update and Reset buttons enabled.
People Page
Below is a screenshot of the people page showing the people in the initialized database:
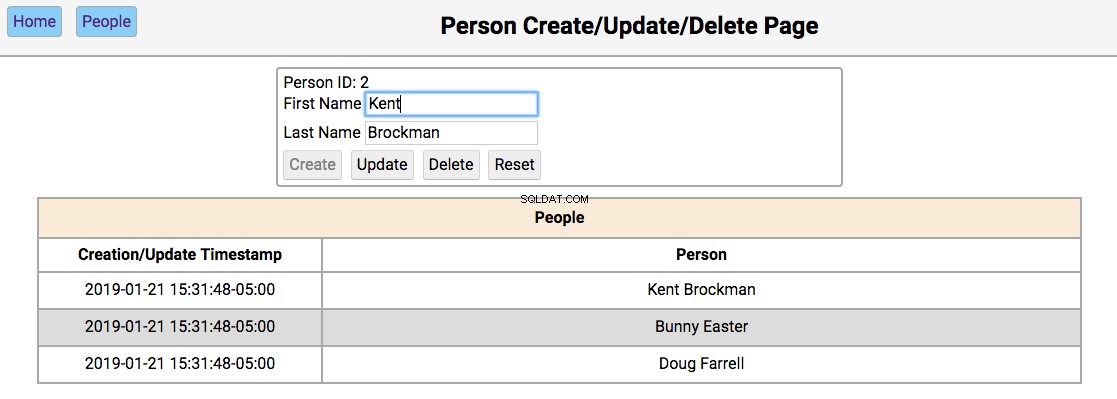
The functionality of this page works like this:
-
Single-clicking on a person’s name will populate the editor section of the page with the person’s first and last name, disabling the Create button, and enabling the Update and Delete buttons.
-
Double clicking on a person’s name will navigate to the notes pages for that person.
The functionality of the editor works like this:
-
If the first and last name fields are empty, the Create and Reset buttons are enabled. Entering a new name in the fields and clicking Create will create a new person and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the first and last name fields have data, the user navigated here by double-clicking the person’s name from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the first or last name and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the person from the database and re-render the table.
Notes Page
Below is a screenshot of the notes page showing the notes for a person in the initialized database:
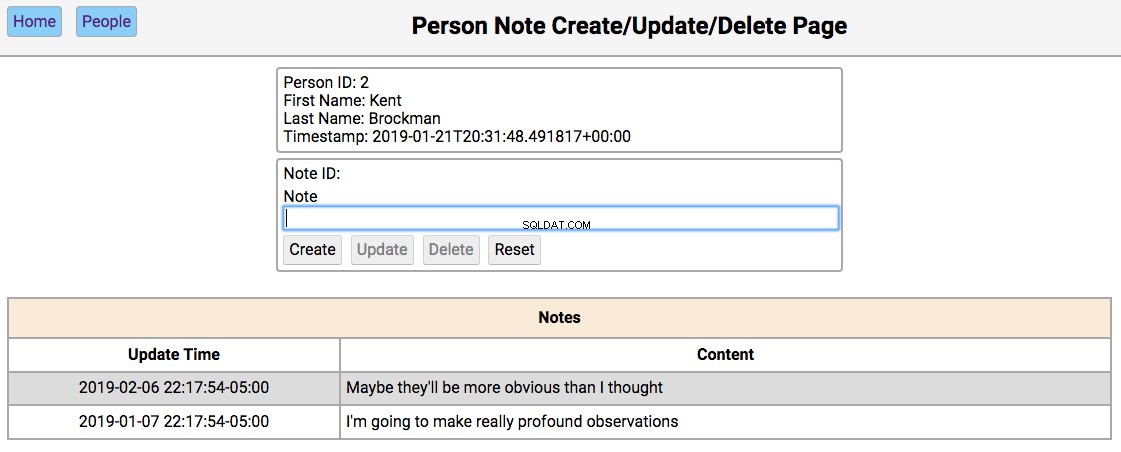
The functionality of this page works like this:
-
Single-clicking on a note will populate the editor section of the page with the notes content, disabling the Create button, and enabling the Update and Delete buttons.
-
All other functionality of this page is in the editor section.
The functionality of the editor works like this:
-
If the note content field is empty, then the Create and Reset buttons are enabled. Entering a new note in the field and clicking Create will create a new note and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the note field has data, the user navigated here by double-clicking the person’s note from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the note and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the note from the database and re-render the table.
Web Application
This article is primarily focused on how to use SQLAlchemy to create relationships in the database, and how to extend the REST API to take advantage of those relationships. As such, the code for the web application didn’t get much attention. When you look at the web application code, keep an eye out for the following features:
-
Each page of the application is a fully formed single page web application.
-
Each page of the application is driven by JavaScript following an MVC (Model/View/Controller) style of responsibility delegation.
-
The HTML that creates the pages takes advantage of the Jinja2 inheritance functionality.
-
The hardcoded JavaScript table creation has been replaced by using the Handlebars.js templating engine.
-
The timestamp formating in all of the tables is provided by Moment.js.
You can find the following code in the repository for this article:
- The HTML for the web application
- The CSS for the web application
- The JavaScript for the web application
All of the example code for this article is available in the GitHub repository for this article. This contains all of the code related to this article, including all of the web application code.
Conclusion
Congratulations are in order for what you’ve learned in this article! Knowing how to build and use database relationships gives you a powerful tool to solve many difficult problems. There are other relationship besides the one-to-many example from this article. Other common ones are one-to-one, many-to-many, and many-to-one. All of them have a place in your toolbelt, and SQLAlchemy can help you tackle them all!
For more information about databases, you can check out these tutorials. You can also set up Flask to use SQLAlchemy. You can check out Model-View-Controller (MVC) more information about the pattern used in the web application JavaScript code.
In Part 4 of this series, you’ll focus on the HTML, CSS, and JavaScript files used to create the web application.
« Part 2:Database PersistencePart 3:Database RelationshipsPart 4:Simple Web Applications »