Minulý týden jsem zveřejnil příspěvek s názvem #BackToBasics :DATEFROMPARTS() , kde jsem ukázal, jak používat tuto funkci pro rok 2012+ pro čistší, proměnlivé dotazy na časové období. Použil jsem to k demonstraci toho, že pokud používáte predikát data s otevřeným koncem a máte index v příslušném sloupci data/času, můžete skončit s mnohem lepším využitím indexu a nižším I/O (nebo v nejhorším případě , totéž, pokud nelze z nějakého důvodu hledání použít nebo pokud neexistuje vhodný index):
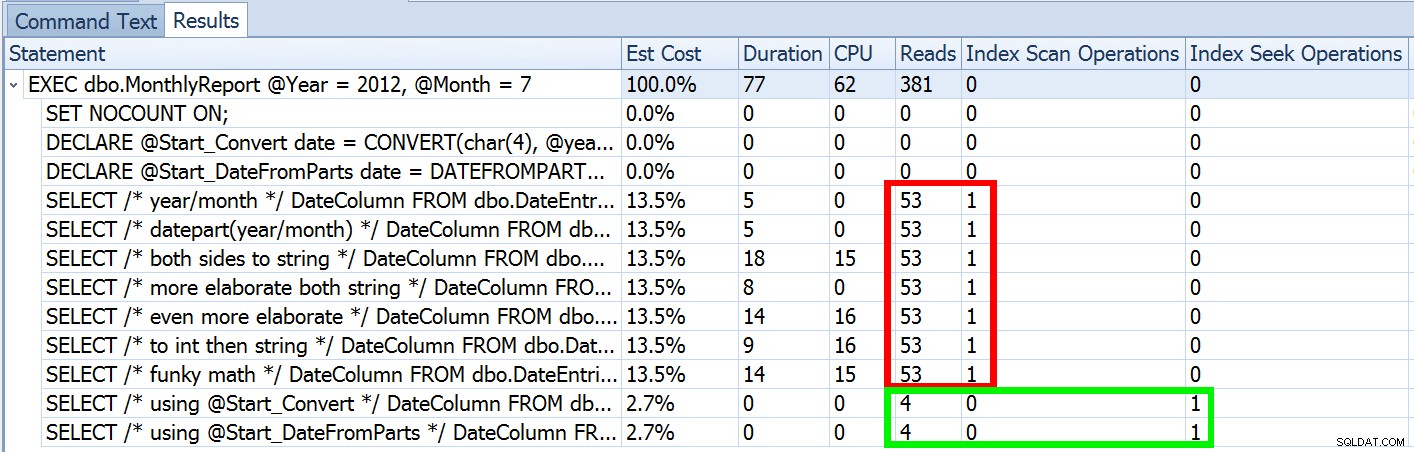
Ale to je jen část příběhu (a aby bylo jasno, DATEFROMPARTS() není technicky vyžadováno pro získání vyhledávání, v tomto případě je pouze čistší). Pokud trochu oddálíme, všimneme si, že naše odhady nejsou ani zdaleka přesné, což je složitost, kterou jsem v předchozím příspěvku nechtěl představovat:
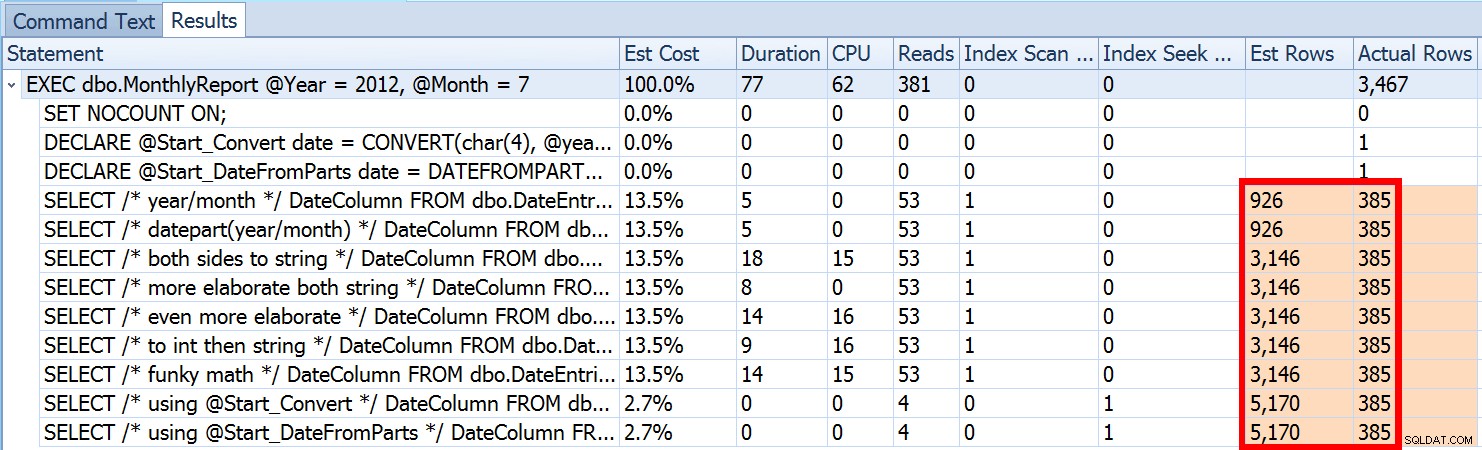
To není neobvyklé jak pro predikáty nerovnosti, tak pro vynucené skenování. A samozřejmě, nepřinesla by metoda, kterou jsem navrhl, ty nejnepřesnější statistiky? Zde je základní přístup (schéma tabulky, indexy a ukázková data můžete získat z mého předchozího příspěvku):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Nepřesné odhady nebudou vždy problémem, ale mohou způsobit problémy s neefektivními volbami plánu ve dvou extrémech. Jeden plán nemusí být optimální, když zvolený rozsah poskytne velmi malé nebo velmi velké procento tabulky nebo indexu, a to může být pro SQL Server velmi obtížné předvídat, kdy je distribuce dat nerovnoměrná. Joseph Sack nastínil typičtější věci, které mohou špatné odhady ovlivnit ve svém příspěvku „Deset běžných hrozeb pro kvalitu plánu provádění:“
„[…] odhady špatných řádků mohou ovlivnit řadu rozhodnutí včetně výběru indexu, operací vyhledávání vs. skenování, paralelního a sériového provádění, výběru algoritmu spojení, výběru vnitřního vs. vnějšího fyzického spojení (např. sestavení vs. sonda), generování zařazování, vyhledávání záložek vs. úplný klastrový nebo haldový přístup k tabulce, výběr streamu nebo hash agregace a zda modifikace dat používá široký nebo úzký plán."
Existují také další, jako jsou paměťové granty, které jsou příliš velké nebo příliš malé. Dále popisuje některé z častějších příčin špatných odhadů, ale primární příčina v tomto případě v jeho seznamu chybí:odhady. Protože ke změně příchozího int používáme lokální proměnnou parametry na jediné místní date proměnnou, SQL Server neví, jaká bude hodnota, takže dělá standardizované odhady mohutnosti na základě celé tabulky.
Výše jsme viděli, že odhad pro můj navrhovaný přístup byl 5 170 řádků. Nyní víme, že s predikátem nerovnosti a se serverem SQL, který nezná hodnoty parametrů, uhodne 30 % tabulky. 31,645 * 0.3 není 5 170. Není ani 31,465 * 0.3 * 0.3 , když si pamatujeme, že ve skutečnosti existují dva predikáty pracující proti stejnému sloupci. Odkud tedy pochází tato hodnota 5 170?
Jak popisuje Paul White ve svém příspěvku „Odhad mohutnosti pro více predikátů“, nový odhad mohutnosti v SQL Server 2014 používá exponenciální úbytek, takže násobí počet řádků tabulky (31 465) selektivitou prvního predikátu (0,3). a pak to vynásobí druhou odmocninou selektivity druhého predikátu (~0,547723).
31 645 * (0,3) * SQRT (0,3) ~=5 170,227Nyní tedy vidíme, kde SQL Server přišel se svým odhadem; jaké jsou některé metody, které můžeme použít, abychom s tím něco udělali?
- Předejte parametry data. Pokud je to možné, můžete aplikaci změnit tak, aby předávala správné parametry data namísto samostatných celočíselných parametrů.
- Použijte postup obálky. Variantou metody č. 1 – například pokud nemůžete změnit aplikaci – by bylo vytvoření druhé uložené procedury, která akceptuje vytvořené parametry data z první.
- Použijte
OPTION (RECOMPILE). Při nepatrných nákladech na kompilaci při každém spuštění dotazu to nutí SQL Server k optimalizaci na základě hodnot prezentovaných pokaždé, namísto optimalizace jednoho plánu pro neznámé, první nebo průměrné hodnoty parametrů. (Pro důkladné zpracování tohoto tématu viz Paul White "Parameter Sniffing, Embedding, and the RECOMPILE Options."
- Používejte dynamické SQL. Dynamické SQL přijme vytvořené
dateproměnná si vynutí správnou parametrizaci (stejně jako kdybyste volali uloženou proceduru sdateparametr), ale je trochu ošklivý a hůře se udržuje.
- Nepořádejte si s radami a příznaky trasování. Paul White o některých z nich hovoří ve výše uvedeném příspěvku.
Nebudu naznačovat, že se jedná o vyčerpávající seznam, a nebudu opakovat Paulovy rady ohledně nápověd nebo příznaků sledování, takže se zaměřím pouze na ukázku toho, jak mohou první čtyři přístupy zmírnit problém se špatnými odhady. .
1. Parametry data
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Postup balení
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. OPTION (REKOMPILOVAT)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. Dynamický SQL
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Testy
Se čtyřmi sadami procedur bylo snadné vytvořit testy, které by mi ukázaly plány a odhady odvozené SQL Serverem. Protože některé měsíce jsou rušnější než jiné, vybral jsem tři různé měsíce a všechny jsem je provedl několikrát.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
Výsledek? Každý jednotlivý plán přináší stejné hledání indexu, ale odhady jsou správné pouze ve všech třech obdobích v OPTION (RECOMPILE) verze. Zbytek nadále používá odhady odvozené z první sady parametrů (červenec 2012), takže zatímco pro první získají lepší odhady provedení, tento odhad nebude nutně o nic lepší pro následné provádění s použitím různých parametrů (klasický učebnicový případ sniffování parametrů):
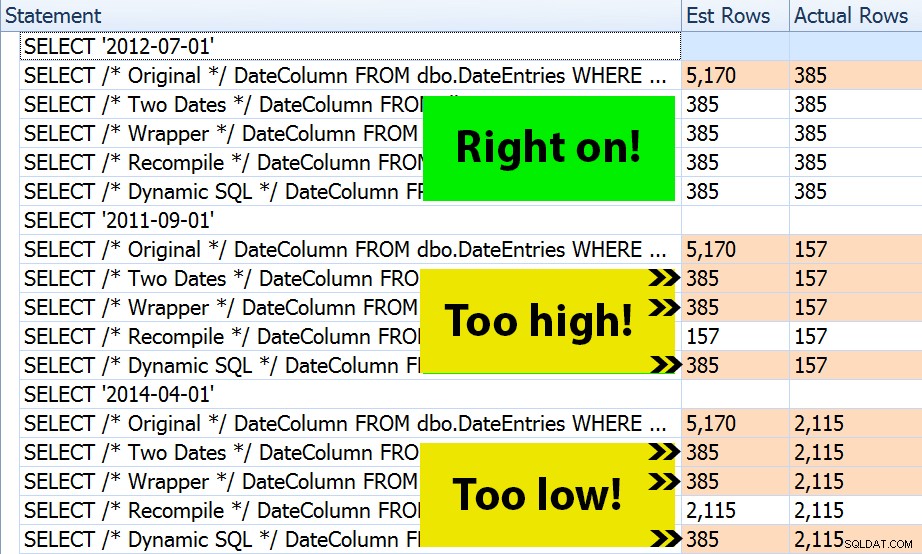
Všimněte si, že výše uvedené není *přesný* výstup z SQL Sentry Plan Explorer – například jsem odstranil řádky stromu příkazů, které ukazovaly vnější volání uložených procedur a deklarace parametrů.
Bude na vás, abyste určili, zda je pro vás nejlepší taktika sestavování pokaždé, nebo zda potřebujete v první řadě něco „opravit“. Zde jsme skončili se stejnými plány a bez znatelných rozdílů v metrikách výkonu za běhu. Ale na větších tabulkách, s více zkresleným rozložením dat a většími rozdíly v predikátových hodnotách (např. zvažte zprávu, která může pokrýt týden, rok a cokoli mezi tím), může stát za průzkum. A všimněte si, že zde můžete kombinovat metody – například můžete přepnout na správné parametry data *a* přidat OPTION (RECOMPILE) , pokud byste chtěli.
Závěr
V tomto konkrétním případě, což je záměrné zjednodušení, se snaha získat správné odhady opravdu nevyplatila – nezískali jsme jiný plán a výkon za běhu byl ekvivalentní. Určitě však existují i jiné případy, kdy to bude mít vliv, a je důležité rozpoznat rozdíl v odhadech a určit, zda by se to mohlo stát problémem s růstem vašich dat a/nebo zkreslením distribuce. Bohužel neexistuje žádná černobílá odpověď, protože mnoho proměnných ovlivní, zda je režie kompilace oprávněná – jako u mnoha scénářů IT DEPENDS™ …