Úvod
Vývojářům se často říká, aby používali uložené procedury, aby se vyhnuli takzvaným ad hoc dotazům což může mít za následek zbytečné nabobtnání mezipaměti plánu. Vidíte, když je opakující se kód SQL napsán nekonzistentně nebo když existuje kód, který generuje dynamické SQL za běhu, SQL Server má tendenci vytvořit plán provádění pro každé jednotlivé spuštění. To může snížit celkový výkon o:
Vyžadování fáze kompilace pro každé spuštění kódu.
Naplnění mezipaměti plánu příliš mnoha úchyty plánu, které nelze znovu použít.
Optimalizace pro zátěže Ad Hoc
Jedním ze způsobů, jak byl tento problém řešen v minulosti, je optimalizace instance pro Ad Hoc zátěž. To může být užitečné pouze v případě, že většina databází nebo nejvýznamnějších databází v instanci spouští převážně Ad Hoc SQL.
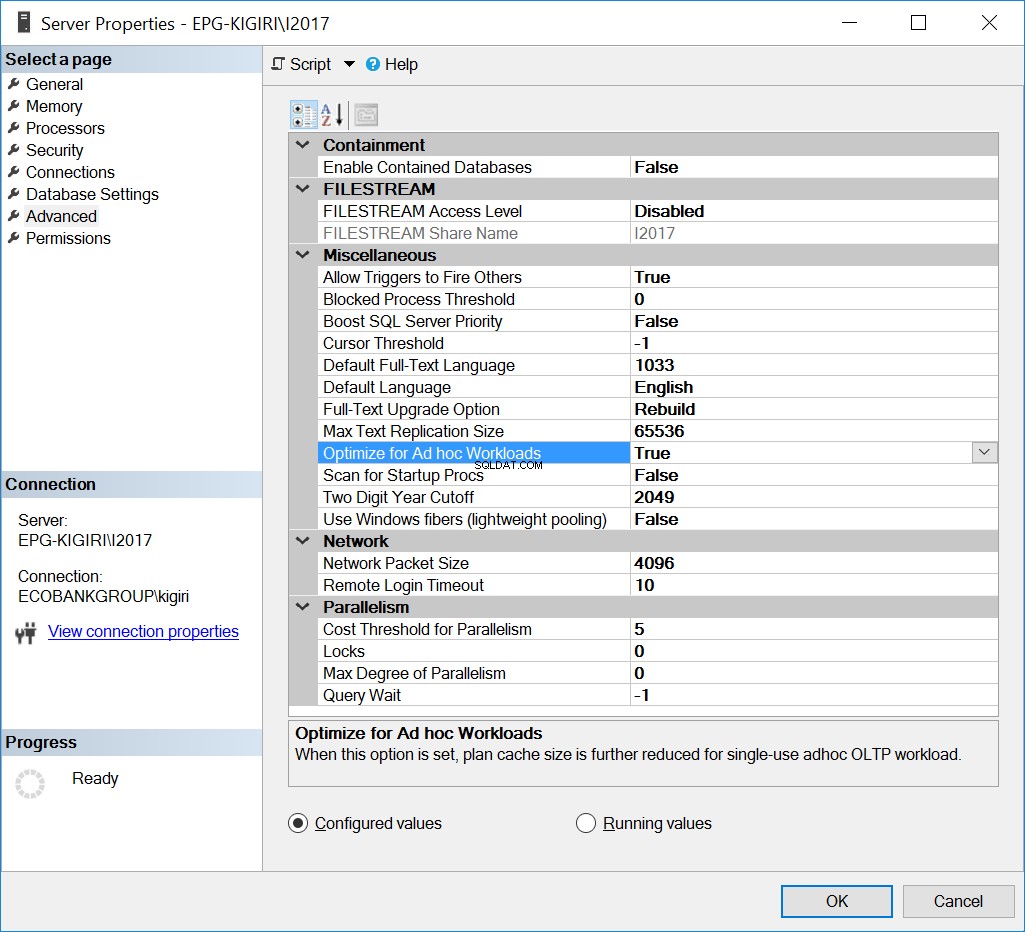
Obr. 1 Optimalizace pro zátěže Ad Hoc
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
Tato možnost v podstatě říká serveru SQL Server, aby uložil částečnou verzi plánu známou jako kompilovaný útržek plánu. Pahýl zabírá mnohem méně místa než celý plán.
Jako alternativu k této metodě někteří lidé přistupují k problému poměrně brutálně a čas od času vyprázdní mezipaměť plánu. Nebo opatrněji vyprázdněte „plány na jedno použití“ pomocí DBCC FREESYSTEMCACHE. Vypláchnutí celé mezipaměti plánu má své stinné stránky, jak už možná víte.
Použití uložených procedur a parametrů
Použitím uložených procedur lze prakticky eliminovat problém způsobený Ad Hoc SQL. Uložená procedura se zkompiluje pouze jednou a stejný plán se znovu použije pro následné provádění stejných nebo podobných dotazů SQL. Když se uložené procedury používají k implementaci obchodní logiky, hlavní rozdíl v dotazech SQL, které budou nakonec provedeny serverem SQL Server, spočívá v parametrech předávaných v době provádění. Protože plán je již zaveden a připraven k použití, SQL Server použije stejný plán bez ohledu na to, jaký parametr bude předán.
Zkreslená data
V určitých scénářích nejsou data, se kterými se zabýváme, distribuována rovnoměrně. Můžeme to demonstrovat – nejprve budeme muset vytvořit tabulku:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Naše tabulka obsahuje údaje o členech klubu z různých zemí. Velký počet členů klubu pochází z Ghany, zatímco dva další národy mají deset a dva členy. Abych se soustředil na agendu a pro jednoduchost, použil jsem pouze tři země a stejné jméno pro členy pocházející ze stejné země. Také jsem přidal seskupený index do sloupce ID a neshlukovaný index do sloupce Kód země, abych demonstroval účinek různých plánů provádění pro různé hodnoty.
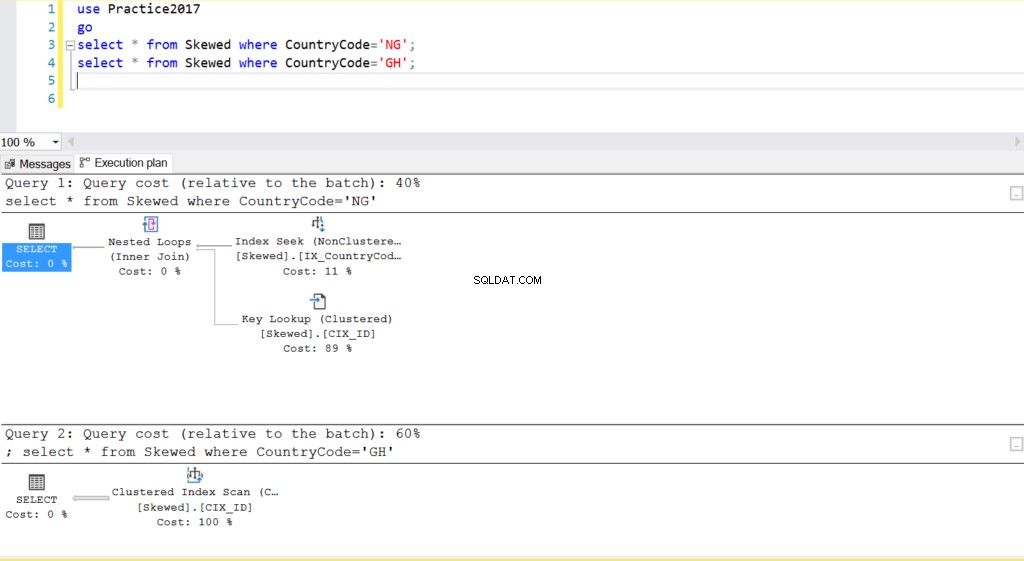
Obr. 2 Plány provedení pro dva dotazy
Když se dotazujeme v tabulce na záznamy, kde CountryCode je NG a GH, zjistíme, že SQL Server v těchto případech používá dva různé plány provádění. K tomu dochází, protože očekávaný počet řádků pro CountryCode=’NG’ je 10, zatímco pro CountryCode=’GH’ je 10 000. SQL Server určuje preferovaný plán provádění na základě statistik tabulky. Pokud je očekávaný počet řádků vysoký ve srovnání s celkovým počtem řádků v tabulce, SQL Server se rozhodne, že je lepší jednoduše provést úplné prohledání tabulky než odkazovat na index. S mnohem menším odhadovaným počtem řádků se index stává užitečným.
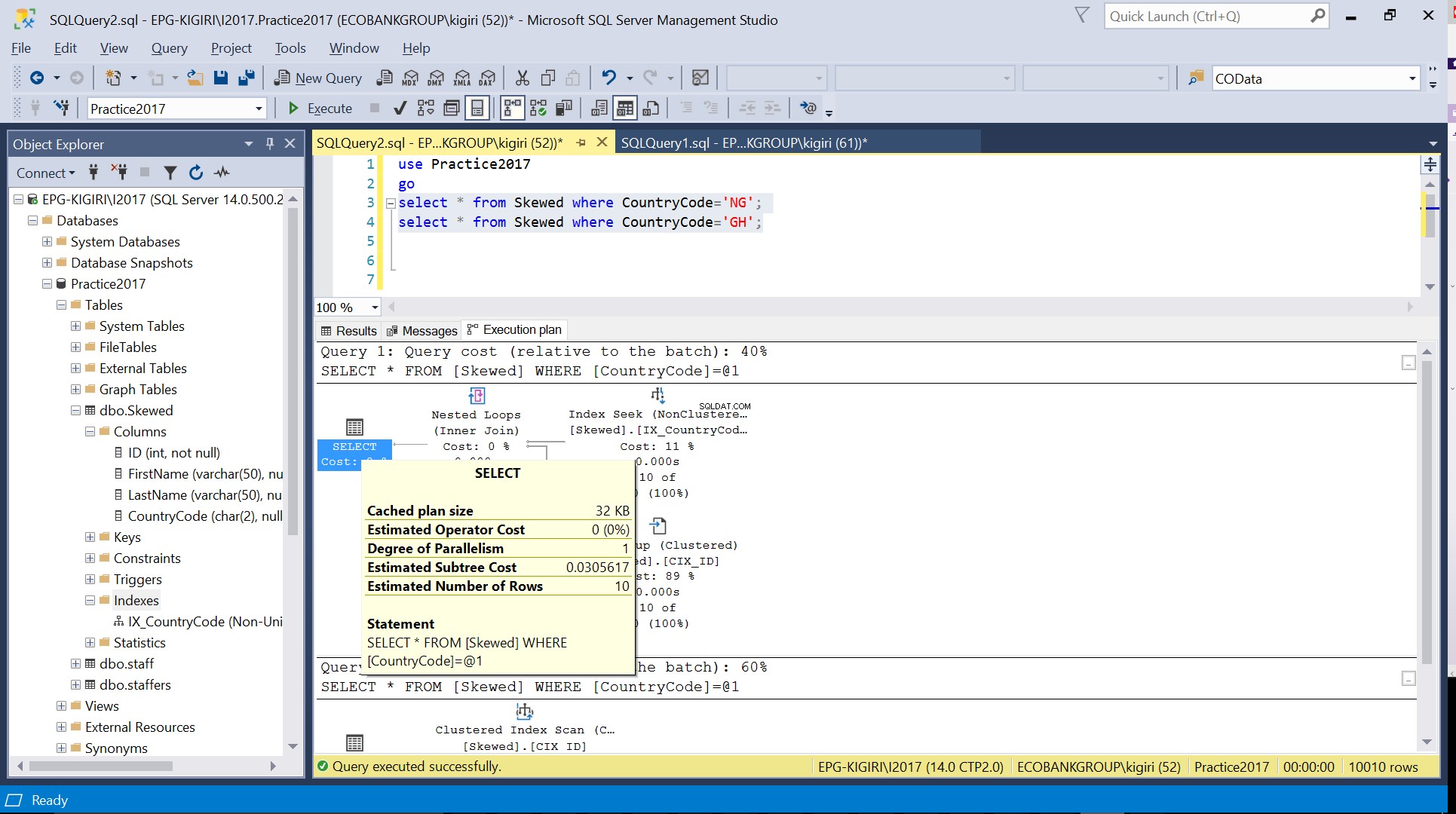
Obr. 3 Odhadovaný počet řádků pro CountryCode=’NG’
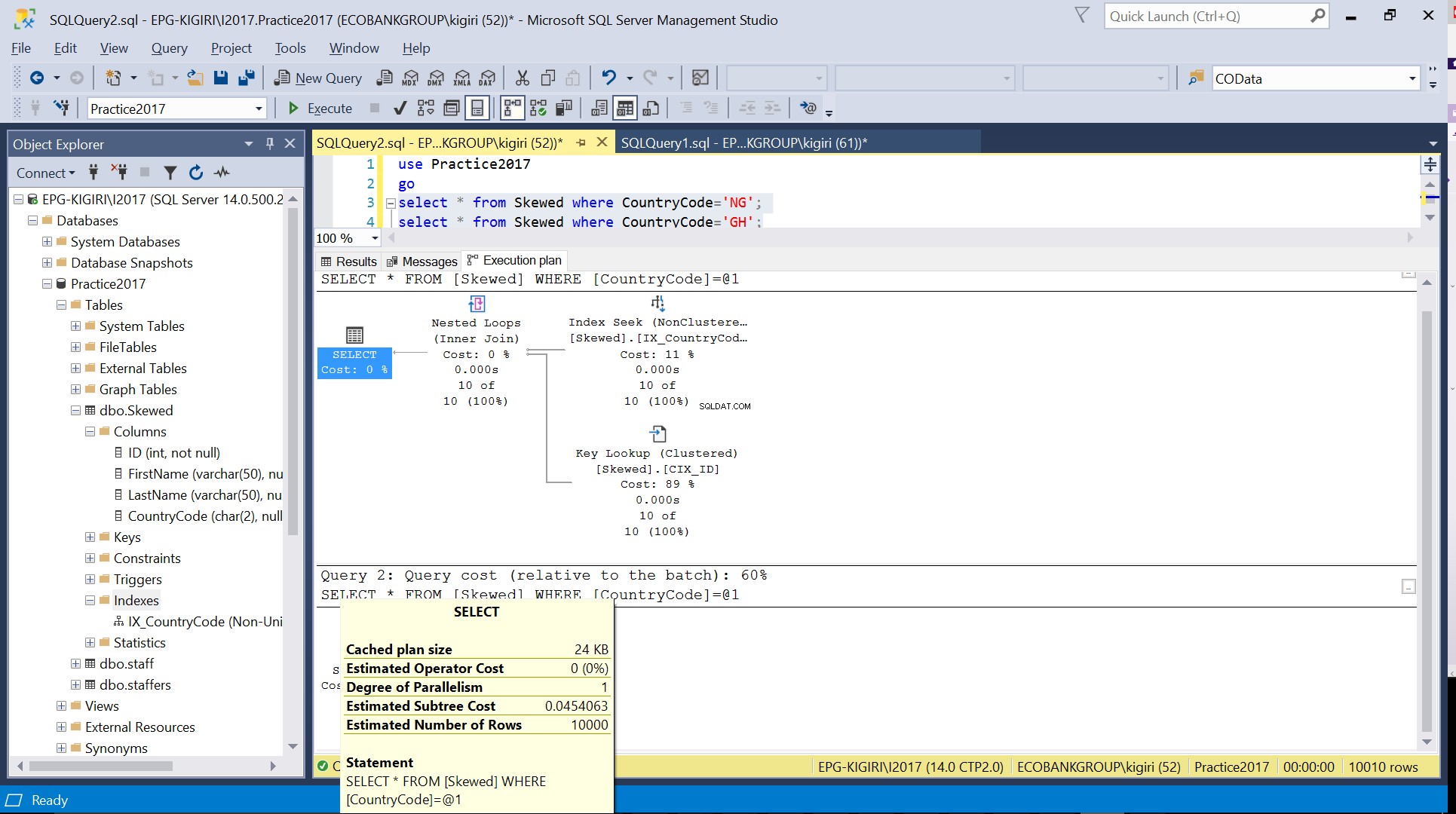
Obr. 4 Odhadovaný počet řádků pro CountryCode=’GH’
Zadejte uložené procedury
Můžeme vytvořit uloženou proceduru pro načtení požadovaných záznamů pomocí stejného dotazu. Jediný rozdíl je tentokrát v tom, že jako parametr předáváme CountryCode (viz Výpis 3). Když to uděláme, zjistíme, že plán provádění je stejný bez ohledu na to, jaký parametr předáme. Plán provádění, který bude použit, je určen plánem provádění vráceným při prvním vyvolání uložené procedury. Pokud například nejprve spustíme proceduru s CountryCode=’GH’, bude od tohoto okamžiku používat úplné prohledání tabulky. Pokud poté vymažeme mezipaměť procedur a spustíme proceduru nejprve s CountryCode=’NG’, bude v budoucnu používat skenování založené na indexu.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
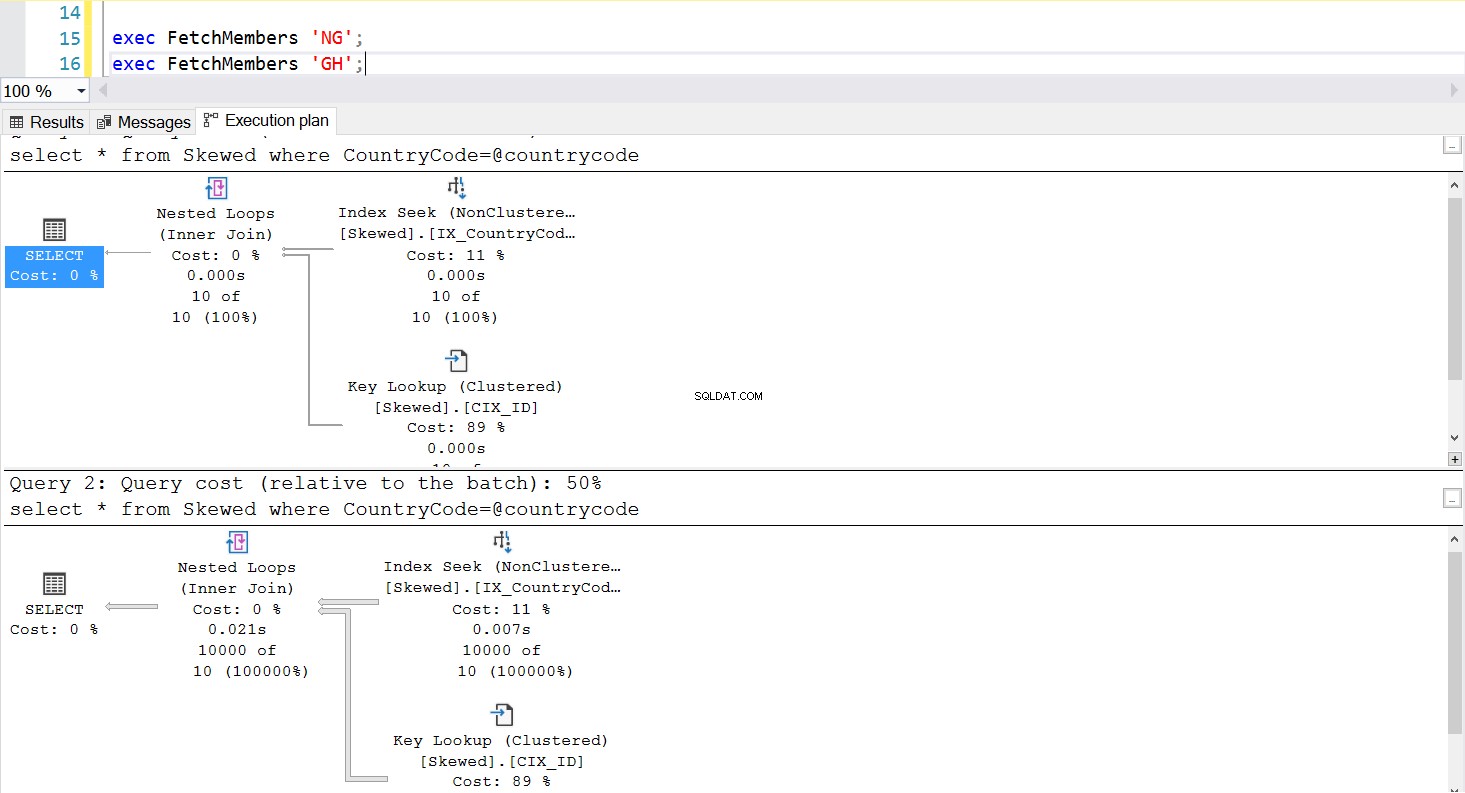
Obr. 5 Plán provádění hledání indexu, když se jako první použije ‚NG‘
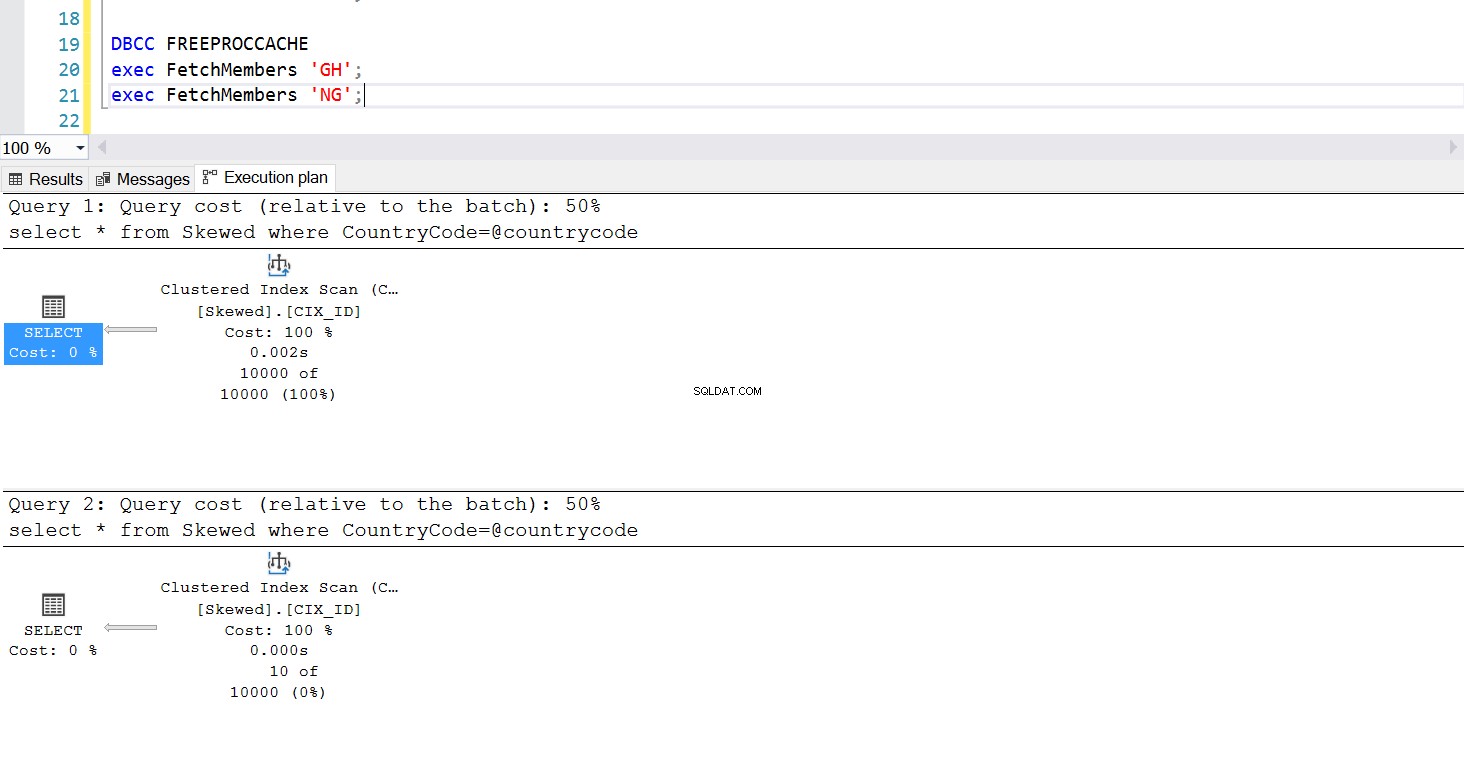
Obr. 6 Plán provádění skenování seskupených indexů, když se jako první použije „GH“
Provádění uložené procedury se chová tak, jak bylo navrženo – požadovaný plán provádění se používá konzistentně. To však může být problém, protože jeden plán provádění není vhodný pro všechny dotazy, pokud jsou data zkreslená. Použití indexu k načtení kolekce řádků téměř stejně velkých jako celá tabulka není efektivní – ani použití úplného skenování k načtení pouze malého počtu řádků. Toto je problém Parameter Sniffing.
Možná řešení
Jedním běžným způsobem, jak vyřešit problém s vyhledáváním parametrů, je záměrně vyvolat rekompilaci při každém spuštění uložené procedury. To je mnohem lepší než vyprázdnění mezipaměti plánu – kromě případů, kdy chcete vyprázdnit mezipaměť tohoto konkrétního dotazu SQL, což je zcela možné. Podívejte se na aktualizovanou verzi uložené procedury. Tentokrát k řešení problému používá OPTION (REKOMPILOVAT). Obr.6 nám ukazuje, že kdykoli je spuštěna nová uložená procedura, používá plán vhodný pro parametr, který předáváme.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
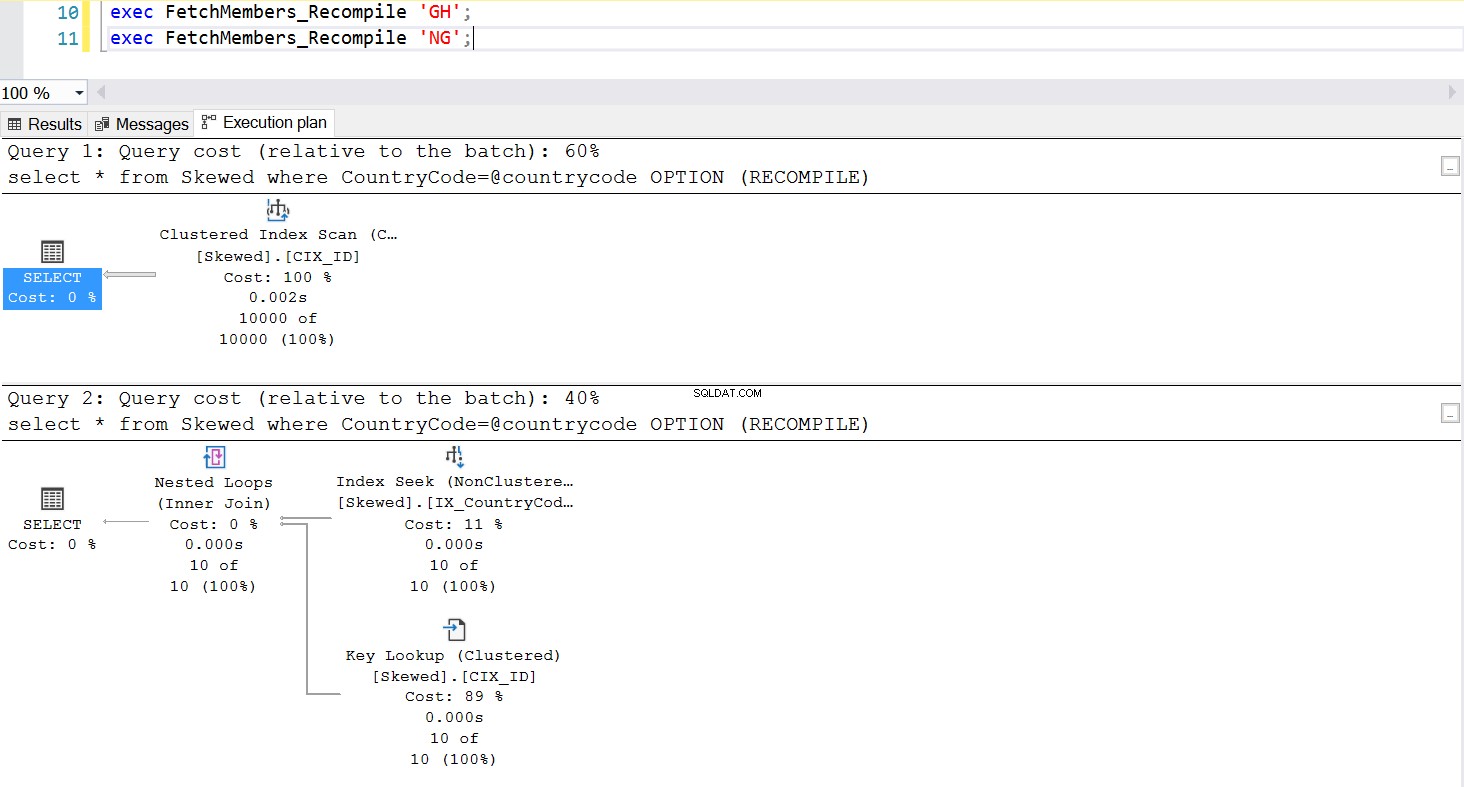
Obr. 7 Chování uložené procedury s OPTION (RECOMPILE)
Závěr
V tomto článku jsme se podívali na to, jak se mohou konzistentní plány provádění pro uložené procedury stát problémem, když jsou data, se kterými se zabýváme, zkreslená. To jsme si také předvedli v praxi a dozvěděli se o společném řešení problému. Troufám si říci, že tyto znalosti jsou neocenitelné pro vývojáře, kteří používají SQL Server. Existuje řada dalších řešení tohoto problému – Brent Ozar šel do tématu hlouběji a na SQLDay Poland 2017 zdůraznil některé hlubší podrobnosti a řešení. Odpovídající odkaz jsem uvedl v sekci reference.
Odkazy
Plánování mezipaměti a optimalizace pro adhoc zátěže
Identifikace a oprava problémů se sniffováním parametrů