V SQL Server 2012 a SQL Server 2014 došlo k chybě regrese, kdy pokud paralelně znovu sestavíte index online a také dojde k závažné chybě, jako je časový limit zámku, můžete zaznamenat ztráta nebo poškození dat . To by měl být relativně vzácný scénář (Phil Brammer má jednoduché opakování v Connect #795134), ale ztráta dat je ztráta dat a já nejsem připraven hazardovat. Oprava je popsána v KB #2969896:OPRAVA:Ke ztrátě dat v clusterovém indexu dochází při spuštění indexu sestavení online na serveru SQL Server 2012.
Ne každý se musí tímto problémem zabývat. Pokud nepoužíváte Enterprise (nebo ekvivalentní) edici, nemůžete v první řadě provádět paralelní nebo online přestavby (a pravděpodobně jsou někteří lidé na Enterprise, kteří nepřestavují nebo nepřestavují online). Pokud máte celou instanci MAXDOP nastavena na 1, nemohou jít paralelně, pokud to nepřepíšete na úrovni příkazu. Pokud však používáte rok 2012 nebo 2014, používáte odpovídající edici a vaše online přestavby mohou probíhat souběžně, jste tímto problémem zranitelní.
Jak jsem uvedl výše, tento problém se mohl projevit v SQL Server 2012 RTM, Service Pack 1 a dokonce i Service Pack 2, který byl vydán 10. června. Chyba byla opravena až dlouho poté, co byl kód SP2 zmrazen, takže SP2 ano. nezahrnují tuto opravu ani žádnou z oprav z SP1 CU #10 nebo #11. Blogoval jsem o tom zde. Pobočka RTM je oficiálně mimo podporu, takže tam neuvidíte opravu. K problému může dojít také v SQL Server 2014.
Nyní jsou k dispozici kumulativní aktualizace pro SQL Server 2012 Service Pack 1 a 2 a také pro SQL Server 2014. Rychlé shrnutí možností, které doporučuji:
Pokud je vaše pobočka / @@VERSION…
| …měli byste… | ||||
|---|---|---|---|---|---|
| |||||
| |||||
| Nedělat nic; již máte opravu. | |||||
| |||||
| Nedělat nic; již máte opravu. | |||||
| SQL Server 2014 RTM |
| ||||
| Nedělat nic; již máte opravu. | |||||
| * Pokud nainstalujete opravu hotfix SP1 nebo kumulativní aktualizaci #11 a poté nainstalujete aktualizaci SP2, vrátíte tyto změny zpět, včetně tato oprava. | |||||
Řešení pro opravu hotfix/odvrácenou CU
Vzhledem k tomu, že všechny dotčené pobočky (s výjimkou RTM 2012) mají na vyžádání hotfix a/nebo kumulativní aktualizaci, která problém řeší, je snadná odpověď pouze nainstalovat příslušnou aktualizaci. Můžete se však ocitnout ve scénáři, kdy vám zásady vaší společnosti nebo testovací cykly brání v rychlém nasazení těchto aktualizací, nebo možná vůbec. Jaké další možnosti tedy máte?
- Můžete přestat provádět přestavby, dokud nebude pro vaši pobočku k dispozici nový service pack (možná stačí zůstat u
REORGANIZEpro teď). Bohužel, pokud jste ve společnosti „pouze service pack“, vaše možnosti jsou velmi omezené:můžete tvrději bojovat za změnu této zásady, nebo můžete počkat na SQL Server 2012 Service Pack 3 (což může být dlouhá doba nebo může prostě nikdy nepřijď – viz FAQ č. 21 zde) nebo SQL Server 2014 Service Pack 1 (kterého se pravděpodobně nedočkáme dříve než v roce 2015). - Můžete nastavit
max degree of parallelismpro celou instanci na 1, nicméně to může mít negativní vliv na zbytek vaší pracovní zátěže – přemýšlejte o věcech, jako je vícevláknové DBCC, paralelní dotazy proti nebo mezi rozdělenými tabulkami a další operace, kde možná budete chtít omezit paralelismus, ale ne ho úplně odstranit. Toto nastavení také neovlivní online přestavbu s, řekněme, explicitnímMAXDOP = 8pevně zakódované do příkazu, protože to přepíšesp_configurenastavení.
- Můžete přidat
WITH (MAXDOP = 1)možnost ručně na všechny vaše příkazy pro obnovu. (Poznámka:nemusíte to dělat pro indexy XML, protože ze své podstaty běží jednovláknové, ale pouze bych to použil na všechna přestavění kvůli konzistenci a aby se zabránilo zbytečné podmíněné logice.)
- Můžete nastavit, aby se úlohy údržby indexu spouštěly jako konkrétní přihlášení, a poté pomocí nástroje Resource Governor vytvořit skupinu pracovní zátěže, která omezuje
MAX_DOPdaného přihlášení. na 1, bez ohledu na to, co dělají. Mám takový příklad v bílé knize z roku 2008, kterou jsem napsal s Borisem Baryshnikovem, Using the Resource Governor, v sekci nazvané "Omezení paralelismu pro intenzivní pracovní místa na pozadí."
- Pokud používáte řešení pro údržbu indexu Ola Hallengren, můžete přidat
@MaxDopparametr k vašim volánímdbo.IndexOptimize:
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - Pokud používáte SQL Sentry Fragmentation Manager, můžete diktovat úroveň
MAXDOPpoužít v části Nastavení – a můžete to provést v rámci celého podniku, na instanci, na databázi nebo dokonce na jednotlivý index (v tomto případě byste to pravděpodobně chtěli nastavit pro každou instanci, pro všechny instance bez dostupné opravy):
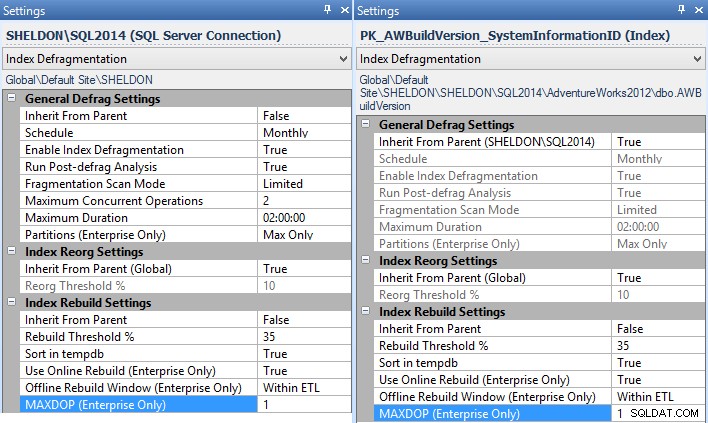
Nastavení správce fragmentace pro instanci (vlevo) a individuální index (vpravo). - Pokud pro přestavby indexu používáte plány údržby, budete je muset změnit, abyste mohli používat příkazy Execute T-SQL Statement Tasks, a zapsat
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);příkazy ručně (takže může také přejít na automatizované řešení). Podívejte se, úloha Rebuild Rebuild nemá vystavenou vlastnost proMAXDOP, i když o to bylo požádáno několikrát (naposledy v roce 2012 Alberto Morillo a až v roce 2006 Linchi Shea). A stačí se podívat na všechny tyto další užitečné vlastnosti, které odhalují, jako jeAdvSortInTempdb,ObjectTypeSelectionaTaskAllowesDatbaseSelection[sic!]:
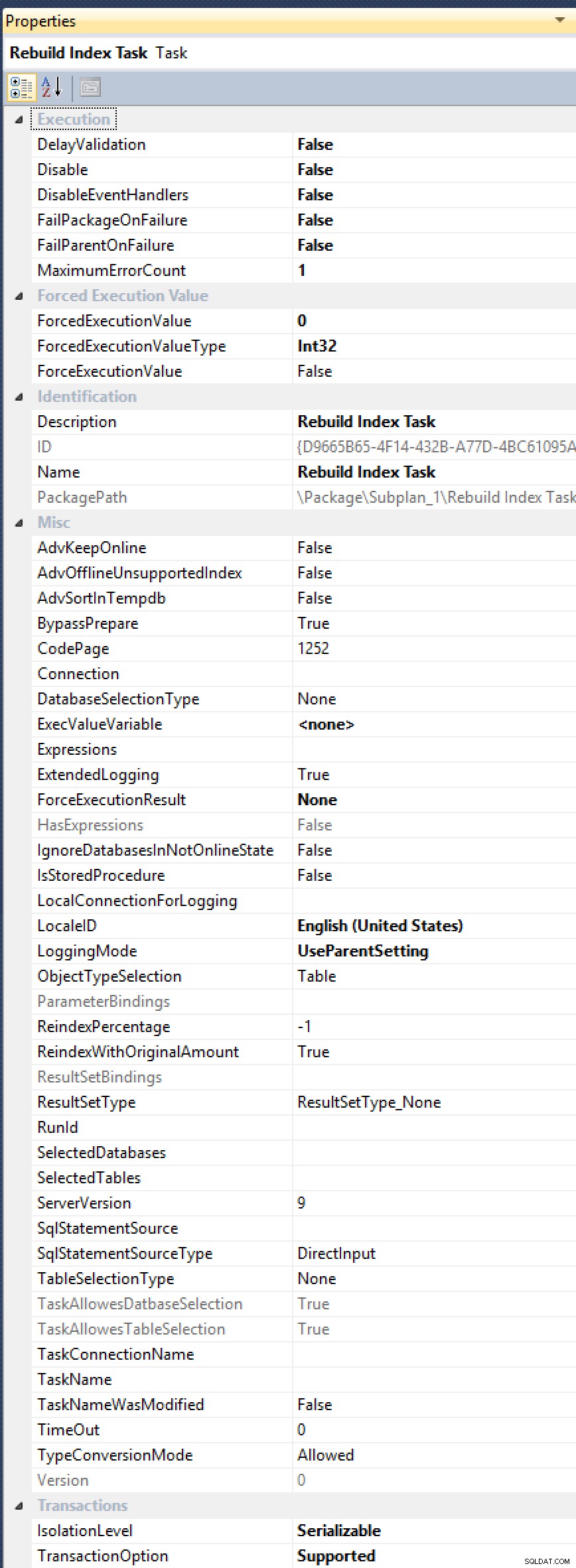
Všechny tyto možnosti, ale stále žádný lék na MAXDOP.