Delayed Durability je nejnovější, ale zajímavá funkce v SQL Server 2014; výška výtahu na vysoké úrovni této funkce je jednoduše:
- „Obchodní trvanlivost za výkon.“
Nejprve nějaké pozadí. Ve výchozím nastavení používá SQL Server protokol pro zápis napřed (WAL), což znamená, že změny jsou zapsány do protokolu dříve, než je povoleno jejich potvrzení. V systémech, kde se zápisy do protokolu transakcí stávají úzkým hrdlem a kde existuje střední tolerance ke ztrátě dat , nyní máte možnost dočasně pozastavit požadavek na čekání na vyprázdnění a potvrzení protokolu. Stává se to doslova a doslova vyjme D z ACID, alespoň pro malou část dat (více o tom později).
Tuhle oběť už jsi tak trochu učinil. V režimu plné obnovy vždy existuje určité riziko ztráty dat, jen se měří spíše z hlediska času než velikosti. Pokud například zálohujete protokol transakcí každých pět minut, můžete ztratit až 5 minut dat, pokud se stane něco katastrofického. Nemluvím zde o jednoduchém převzetí služeb při selhání, ale řekněme, že server doslova vzplane nebo někdo zakopne o napájecí kabel – databáze může být velmi dobře neobnovitelná a možná se budete muset vrátit do bodu v čase poslední zálohy protokolu . A to za předpokladu, že své zálohy dokonce testujete tím, že je někde obnovujete – v případě kritického selhání možná nemáte bod obnovy, který si myslíte, že máte. O tomto scénáři samozřejmě nepřemýšlíme, protože nikdy neočekáváme špatné věci™ aby se stalo.
Jak to funguje
Zpožděná trvanlivost umožňuje, aby transakce zápisu pokračovaly v běhu, jako by byl protokol vyprázdněn na disk; ve skutečnosti byly zápisy na disk seskupeny a odloženy, aby byly zpracovávány na pozadí. Transakce je optimistická; předpokládá, že vyprázdnění logu bude stát se. Systém používá 60KB blok vyrovnávací paměti protokolu a pokusí se vyprázdnit protokol na disk, když je tento 60KB blok plný (nejpozději – může a často se to stane i předtím). Tuto možnost můžete nastavit na úrovni databáze, na úrovni jednotlivých transakcí nebo – v případě nativně kompilovaných procedur v In-Memory OLTP – na úrovni procedury. V případě konfliktu vítězí nastavení databáze; pokud je například databáze nastavena na vypnuto, pokus o potvrzení transakce pomocí možnosti zpoždění bude jednoduše ignorován bez chybové zprávy. Některé transakce jsou také vždy plně trvalé, bez ohledu na nastavení databáze nebo nastavení potvrzení; například systémové transakce, transakce napříč databázemi a operace zahrnující FileTable, sledování změn, sběr dat změn a replikaci.
Na úrovni databáze můžete použít:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Pokud jej nastavíte na ALLOWED , to znamená, že každá jednotlivá transakce může použít zpožděnou trvanlivost; FORCED znamená, že všechny transakce, které mohou používat Delayed Durability, budou (výjimky výše jsou v tomto případě stále relevantní). Pravděpodobně budete chtít použít ALLOWED spíše než FORCED – ale to druhé může být užitečné v případě existující aplikace, kde chcete tuto možnost používat po celou dobu a také minimalizovat množství kódu, který je třeba osahat. Důležitá věc k poznámce o ALLOWED spočívá v tom, že plně trvanlivé transakce mohou čekat déle, protože si nejprve vynutí spláchnutí všech zpožděných trvanlivých transakcí.
Na úrovni transakce můžete říci:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
A v nativně zkompilované proceduře In-Memory OLTP můžete do BEGIN ATOMIC přidat následující možnost blokovat:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Častou otázkou je, co se stane se sémantikou zamykání a izolace. Nic se nemění, opravdu. K zamykání a blokování stále dochází a transakce se zavazují stejným způsobem a se stejnými pravidly. Jediný rozdíl je v tom, že tím, že umožníte provedení odevzdání bez čekání na vyprázdnění protokolu na disk, budou všechny související zámky uvolněny mnohem dříve.
Kdy byste jej měli použít
Kromě výhody, kterou získáte, když umožníte pokračování transakcí bez čekání na zápis do protokolu, získáte také méně zápisů větších velikostí. To může fungovat velmi dobře, pokud má váš systém vysoký podíl transakcí, které jsou ve skutečnosti menší než 60 kB, a zvláště když je logovací disk pomalý (ačkoli jsem našel podobné výhody na SSD a tradičním HDD). Nefunguje to tak dobře, pokud jsou vaše transakce z větší části větší než 60 kB, pokud jsou obvykle dlouhotrvající nebo pokud máte vysokou propustnost a vysokou souběžnost. Zde se může stát, že můžete zaplnit celou vyrovnávací paměť protokolu před dokončením vyprázdnění, což znamená pouze převedení čekání na jiný zdroj a v konečném důsledku to nezlepší výkon vnímaný uživateli aplikace.
Jinými slovy, pokud váš protokol transakcí aktuálně není úzkým hrdlem, nezapínejte tuto funkci. Jak můžete zjistit, zda je váš protokol transakcí aktuálně úzkým hrdlem? První indikátor by byl vysoký WRITELOG čeká, zvláště když je spojen s PAGEIOLATCH_** . Paul Randal (@PaulRandal) má skvělou čtyřdílnou sérii o identifikaci problémů s protokoly transakcí a také o konfiguraci pro optimální výkon:
- Oříznutí tuku v protokolu transakcí
- Oříznutí více tuku v protokolu transakcí
- Problémy s konfigurací protokolu transakcí
- Monitorování protokolu transakcí
Podívejte se také na tento blogový příspěvek od Kimberly Tripp (@KimberlyLTripp), 8 kroků k lepší propustnosti protokolu transakcí a blogový příspěvek týmu SQL CAT Diagnosing Transaction Log Performance Issues and Limits of the Log Manager.
Toto šetření vás může vést k závěru, že zpožděná trvanlivost stojí za prozkoumání; nemusí. Testování vaší pracovní zátěže bude nejspolehlivější způsob, jak to s jistotou zjistit. Stejně jako mnoho dalších doplňků v posledních verzích SQL Server (*kašel* Hekaton ), tato funkce NENÍ navržena tak, aby zlepšila každou jednotlivou pracovní zátěž – a jak je uvedeno výše, ve skutečnosti může některé úlohy zhoršit. Podívejte se na tento blogový příspěvek od Simona Harveyho, kde najdete některé další otázky, které byste si měli položit o svém pracovním vytížení, abyste zjistili, zda je možné obětovat určitou odolnost pro dosažení lepšího výkonu.
Možnost ztráty dat
Zmíním se o tom několikrát a pokaždé, když to udělám, přidám důraz:Musíte být tolerantní ke ztrátě dat . U dobře fungujícího disku je maximum, o které byste měli očekávat ztrátu při katastrofě – nebo dokonce plánovaném a elegantním vypnutí – až jeden celý blok (60 kB). V případě, že váš I/O subsystém nemůže držet krok, je možné, že ztratíte až celou vyrovnávací paměť protokolu (~7 MB).
Abych to upřesnil, z dokumentace (důraz):
Kvůli zpožděné trvanlivosti není žádný rozdíl mezi neočekávaným vypnutím a očekávaným vypnutím/restartem SQL Server . Stejně jako při katastrofických událostech byste měli plánovat ztrátu dat . Při plánovaném vypnutí/restartu mohou být některé transakce, které nebyly zapsány na disk, nejprve uloženy na disk, ale neměli byste to plánovat. Plánujte, jako by vypnutí/restart, ať už plánované nebo neplánované, ztratilo data stejně jako katastrofická událost.Je tedy velmi důležité, abyste zvážili riziko ztráty dat s potřebou zmírnit problémy s výkonem protokolu transakcí. Pokud provozujete banku nebo cokoli, co se zabývá penězi, může být pro vás mnohem bezpečnější a vhodnější přesunout deník na rychlejší disk, než házet kostkou pomocí této funkce. Pokud se snažíte zlepšit dobu odezvy ve své aplikaci Web Gamerz Chat Room, možná je riziko méně závažné.
Toto chování můžete do určité míry ovládat, abyste minimalizovali riziko ztráty dat. Všechny zpožděné trvalé transakce můžete vynutit vyprázdnění na disk jedním ze dvou způsobů:
- Proveďte jakoukoli plně trvanlivou transakci.
- Zavolejte na
sys.sp_flush_logručně.
To vám umožní vrátit se k řízení ztráty dat z hlediska času, nikoli velikosti; můžete naplánovat splachování například každých 5 sekund. Ale budete chtít najít svou sladkou tečku zde; Příliš časté splachování může v první řadě kompenzovat přínos zpožděné životnosti. V každém případě budete muset být stále tolerantní ke ztrátě dat , i když má hodnotu pouhých
Mysleli byste si, že CHECKPOINT zde může pomoci, ale tato operace ve skutečnosti technicky nezaručuje vyprázdnění protokolu na disk.
Interakce s HA/DR
Možná vás zajímá, jak funguje zpožděná trvanlivost s funkcemi HA/DR, jako je odesílání protokolu, replikace a skupiny dostupnosti. U většiny z nich to funguje beze změny. Odeslání a replikace protokolu přehraje záznamy protokolu, které byly zpevněny, takže existuje stejná možnost ztráty dat. S AG v asynchronním režimu stejně nečekáme na sekundární potvrzení, takže se bude chovat stejně jako dnes. U synchronního však nemůžeme provést potvrzení na primární, dokud není transakce potvrzena a zpevněna do vzdáleného protokolu. I v tomto scénáři můžeme mít určitou výhodu lokálně, protože nebudeme muset čekat na zápis do místního protokolu, ale stále musíme čekat na vzdálenou aktivitu. Takže v tomto scénáři je přínos menší a potenciálně žádný; snad s výjimkou ojedinělého scénáře, kdy je primární logovací disk opravdu pomalý a sekundární logovací disk je opravdu rychlý. Mám podezření, že stejné podmínky platí pro synchronizaci/asynchronní zrcadlení, ale nedostanete ode mě žádný oficiální závazek ohledně toho, jak nová funkce funguje s jednou zastaralou. :-)
Pozorování výkonu
Nebylo by to nic moc, kdybych neukázal nějaké skutečné postřehy z výkonu. Nastavil jsem 8 databází, abych otestoval účinky dvou různých vzorů pracovní zátěže s následujícími atributy:
- Model obnovy:jednoduchý vs. úplný
- Umístění protokolu:SSD vs. HDD
- Odolnost:zpožděná vs. plně odolná
Jsem opravdu, opravdu, opravdu líný efektivní v této věci. Protože se chci vyhnout opakování stejných operací v každé databázi, vytvořil jsem následující tabulku dočasně v model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Pak jsem sestavil sadu dynamických příkazů SQL pro sestavení těchto 8 databází, spíše než abych databáze vytvářel jednotlivě a pak se šukal s nastavením:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Neváhejte a spusťte tento kód sami (pomocí EXEC stále komentováno), abyste viděli, že by to vytvořilo 4 databáze s vypnutou Delayed Durability (dvě v PLNÉ obnově, dvě v JEDNODUCHÉ, každá s přihlášením na pomalém disku a jedna s přihlášením na SSD). Opakujte tento vzorec pro 4 databáze s vynucenou zpožděnou trvanlivostí – udělal jsem to proto, abych zjednodušil kód v testu, spíše než abych odrážel, co bych dělal v reálném životě (kde bych pravděpodobně chtěl považovat některé transakce za kritické a některé za jako, no, méně než kritické).
Pro kontrolu zdravého rozumu jsem spustil následující dotaz, abych se ujistil, že databáze mají správnou matici atributů:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Výsledky:
| name | recovery_model | delayed_durability | log_disk |
|---|---|---|---|
| dd1 | PLNÉ | VNUCENO | SSD |
| dd2 | JEDNODUCHÉ | VNUCENO | SSD |
| dd3 | PLNÉ | VNUCENO | HDD |
| dd4 | JEDNODUCHÉ | VNUCENO | HDD |
| dd5 | PLNÉ | ZAKÁZÁNO | SSD |
| dd6 | JEDNODUCHÉ | ZAKÁZÁNO | SSD |
| dd7 | PLNÉ | ZAKÁZÁNO | HDD |
| dd8 | JEDNODUCHÉ | ZAKÁZÁNO | HDD |
Příslušná konfigurace 8 testovacích databází
Test jsem také provedl čistě několikrát, abych se ujistil, že datový soubor o velikosti 1 GB a soubor protokolu o velikosti 1 GB bude stačit ke spuštění celé sady pracovních zátěží, aniž by do rovnice byly zaváděny jakékoli události automatického růstu. Jako osvědčený postup se běžně snažím zajistit, aby systémy zákazníků měly dostatek přiděleného prostoru (a vestavěná správná upozornění), aby v neočekávanou dobu nikdy nenastala žádná událost růstu. Vím, že ve skutečném světě se to nestává vždy, ale je to ideální.
Nastavil jsem systém tak, aby byl monitorován pomocí SQL Sentry – to by mi umožnilo snadno zobrazit většinu metrik výkonu, které jsem chtěl zdůraznit. Ale také jsem vytvořil dočasnou tabulku pro ukládání dávkových metrik včetně trvání a velmi specifického výstupu ze sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; To by mi umožnilo zaznamenat čas začátku a konce každé jednotlivé dávky a měřit delty v DMV mezi časem zahájení a časem ukončení (pouze spolehlivé v tomto případě, protože vím, že jsem jediný uživatel v systému).
Spousta malých transakcí
První test, který jsem chtěl provést, byla spousta malých transakcí. Pro každou databázi jsem chtěl skončit s 500 000 samostatnými dávkami jedné přílohy:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Pamatujte, že se snažím být líný efektivní v této věci. Abych vygeneroval kód pro všech 8 databází, spustil jsem toto:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Provedl jsem tento test a pak jsem se podíval na #Metrics tabulka s následujícím dotazem:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; To přineslo následující výsledky (a prostřednictvím několika testů jsem potvrdil, že výsledky byly konzistentní):
| databáze | píše | bajtů | bajtů/zápis | io_stall_ms | start_time | end_time | trvání (v sekundách) |
|---|---|---|---|---|---|---|---|
| dd1 | 8 068 | 261 894 656 | 32 460,91 | 6 232 | 2014-04-26 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8 072 | 261 682 688 | 32 418,56 | 2 740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8 246 | 262 254 592 | 31 803,85 | 3 996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8 055 | 261 688 320 | 32 487,68 | 4 231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500 012 | 526 448 640 | 1 052,87 | 35 593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500 014 | 525 870 080 | 1 051,71 | 35 435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500 015 | 526 120 448 | 1 052,20 | 50 857 | 2014-04-26 17:28:31 | 2014-04-26 17:30:45 | 134 |
| dd8 | 500 017 | 525 886 976 | 1 051,73 | 49 680 | 133 |
Malé transakce:Trvání a výsledky ze sys.dm_io_virtual_file_stats
Zde jsou určitě zajímavé postřehy:
- Počet jednotlivých operací zápisu byl u databází zpožděné trvanlivosti velmi malý (~60X u tradičních).
- Celkový počet zapsaných bajtů byl snížen na polovinu pomocí Delayed Durability (předpokládám, že všechny zápisy v tradičním případě obsahovaly spoustu plýtvaného místa).
- Počet bajtů na zápis byl u zpožděné trvanlivosti mnohem vyšší. To nebylo příliš překvapivé, protože hlavním účelem této funkce je sdružovat zápisy do větších dávek.
- Celkové trvání I/O blokování bylo nestálé, ale zhruba o řád nižší pro zpožděnou trvanlivost. Stánky pod plně odolnými transakcemi byly mnohem citlivější na typ disku.
- Pokud vás něco dosud nepřesvědčilo, sloupec trvání je velmi výmluvný. Plně odolné dávky, které zaberou dvě minuty nebo více, se zkrátí téměř na polovinu.
Sloupce s časem zahájení/ukončení mi umožnily zaměřit se na řídicí panel Performance Advisor na přesné období, kdy se tyto transakce odehrávaly, kde můžeme čerpat spoustu dalších vizuálních indikátorů:
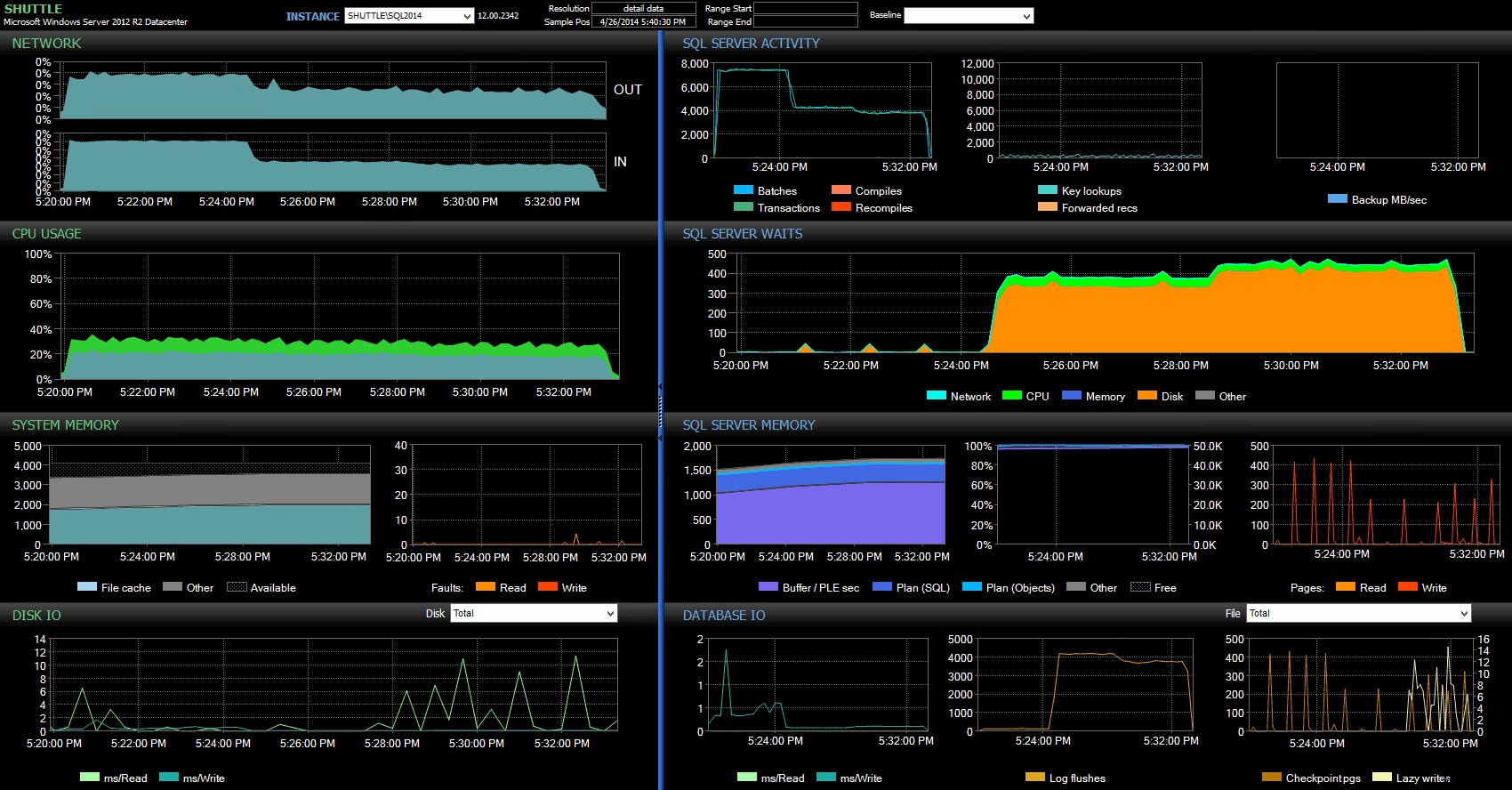
Hlavní panel SQL Sentry – kliknutím zvětšíte
Další postřehy zde:
- Na několika grafech můžete jasně vidět, kdy přesně převzala část dávky nezpožděnou trvanlivost (~17:24:32).
- Při použití zpožděné výdrže není žádný pozorovatelný dopad na CPU nebo paměť.
- V prvním grafu v části Aktivita serveru SQL můžete vidět obrovský dopad na dávky/transakce za sekundu.
- Čekání serveru SQL Server projde až po zahájení plně odolných transakcí. Ty se skládaly téměř výhradně z
WRITELOGčeká s malým počtemPAGEIOLOATCH_EXaPAGEIOLATCH_UPčeká na dobrou míru. - Celkový počet log flushů během operací zpožděné trvanlivosti byl poměrně malý (nízký 100 s/s), zatímco u tradičního chování vyskočil na více než 4 000/s (a mírně nižší po dobu trvání testu HDD).
Méně větších transakcí
V dalším testu jsem chtěl vidět, co by se stalo, kdybychom provedli méně operací, ale zajistil jsem, aby každý příkaz ovlivnil větší množství dat. Chtěl jsem, aby tato dávka běžela proti každé databázi:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Znovu jsem tedy použil línou metodu k vytvoření 8 kopií tohoto skriptu, jednu na databázi:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Spustil jsem tuto dávku a poté změnil dotaz proti #Metrics výše, abyste se podívali na druhý test místo prvního. Výsledky:
| databáze | píše | bajtů | bajtů/zápis | io_stall_ms | start_time | end_time | trvání (v sekundách) |
|---|---|---|---|---|---|---|---|
| dd1 | 20 970 | 1 271 911 936 | 60 653,88 | 12 577 | 2014-04-26 17:41:21 | 2014-04-26 17:43:46 | 145 |
| dd2 | 20 997 | 1 272 145 408 | 60 587,00 | 14 698 | 2014-04-26 17:43:46 | 2014-04-26 17:46:11 | 145 |
| dd3 | 20 973 | 1 272 982 016 | 60 696,22 | 12 085 | 2014-04-26 17:46:11 | 2014-04-26 17:48:33 | 142 |
| dd4 | 20 958 | 1 272 064 512 | 60 695,89 | 11 795 | 143 | ||
| dd5 | 30 138 | 1 282 231 808 | 42 545,35 | 7 402 | 2014-04-26 17:50:56 | 2014-04-26 17:53:23 | 147 |
| dd6 | 30 138 | 1 282 260 992 | 42 546,31 | 7 806 | 2014-04-26 17:53:23 | 2014-04-26 17:55:53 | 150 |
| dd7 | 30 129 | 1 281 575 424 | 42 536,27 | 9 888 | 2014-04-26 17:55:53 | 2014-04-26 17:58:25 | 152 |
| dd8 | 30 130 | 1 281 449 472 | 42 530,68 | 11 452 | 2014-04-26 17:58:25 | 2014-04-26 18:00:55 | 150 |
Větší transakce:Trvání a výsledky ze sys.dm_io_virtual_file_stats
Tentokrát je dopad Delayed Durability mnohem méně patrný. Vidíme o něco menší počet operací zápisu při mírně větším počtu bajtů na zápis, přičemž celkový počet zapsaných bajtů je téměř identický. V tomto případě skutečně vidíme, že I/O bloky jsou vyšší pro Delayed Durability, a to pravděpodobně vysvětluje skutečnost, že doby trvání byly také téměř totožné.
Z řídicího panelu Performance Advisor vidíme některé podobnosti s předchozím testem a také některé výrazné rozdíly:
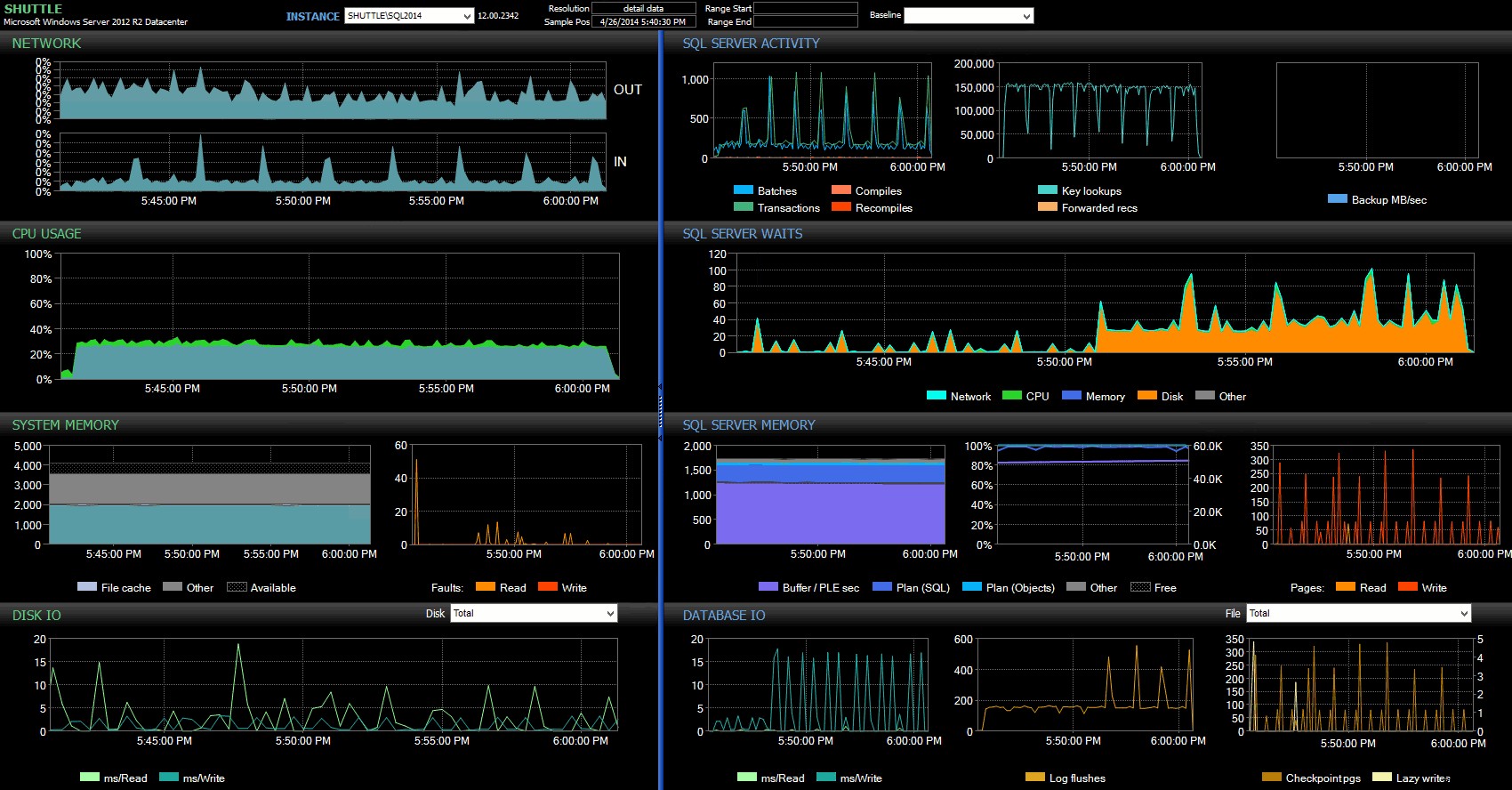
Hlavní panel SQL Sentry – kliknutím zvětšíte
Jedním z velkých rozdílů, na které je třeba zde poukázat, je, že rozdíl ve statistikách čekání není tak výrazný jako u předchozího testu – stále je zde mnohem vyšší frekvence WRITELOG čeká na plně trvanlivé šarže, ale zdaleka se neblíží úrovním, které lze vidět u menších transakcí. Další věc, kterou si můžete všimnout okamžitě, je, že dříve pozorovaný dopad na dávky a transakce za sekundu již není přítomen. A konečně, zatímco u plně trvanlivých transakcí dochází k většímu vyprázdnění protokolu než při zpoždění, tento rozdíl je mnohem méně výrazný než u menších transakcí.
Závěr
Mělo by být jasné, že existují určité typy zátěže, které mohou výrazně těžit ze zpožděné trvanlivosti – samozřejmě za předpokladu, že máte toleranci ke ztrátě dat . Tato funkce není omezena na In-Memory OLTP, je dostupná ve všech edicích SQL Server 2014 a lze ji implementovat s malými nebo žádnými změnami kódu. Určitě to může být výkonná technika, pokud ji vaše pracovní vytížení podporuje. Ale znovu, budete muset otestovat svou pracovní zátěž, abyste si byli jisti, že bude mít z této funkce prospěch, a také důkladně zvážit, zda to nezvýší vaše vystavení riziku ztráty dat.
Kromě toho se to může davu SQL Serveru zdát jako nový nápad, ale ve skutečnosti to Oracle představil jako „Asynchronous Commit“ v roce 2006 (viz COMMIT WRITE ... NOWAIT jak je zde zdokumentováno a blogováno v roce 2007). A samotná myšlenka existuje již téměř 3 desetiletí; viz stručná kronika Hala Berensona o jeho historii.
Příště
Jednou z myšlenek, které jsem měl na mysli, je pokusit se zlepšit výkon tempdb tím, že tam vnucujeme Delayed Durability. Jedna speciální vlastnost tempdb díky tomu je tak lákavým kandidátem, protože je svou povahou přechodný – cokoliv v tempdb je výslovně navržen tak, aby jej bylo možné přehodit v důsledku široké škály systémových událostí. Říkám to nyní, aniž bych měl tušení, zda existuje forma pracovní zátěže, kde to bude dobře fungovat; ale plánuji to vyzkoušet, a pokud najdu něco zajímavého, můžete si být jisti, že o tom zde napíšu.