Čas od času si můžete všimnout, že jedno nebo více spojení v prováděcím plánu je označeno StarJoinInfo struktura. Oficiální schéma showplanu má k tomuto prvku plánu následující informace (kliknutím zvětšíte):
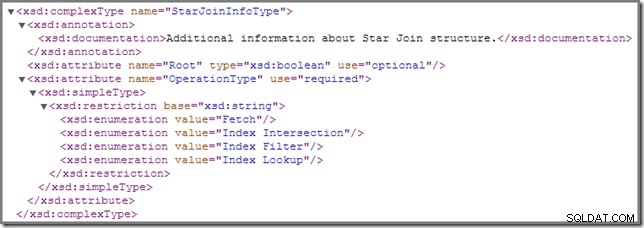
Zde zobrazená přímá dokumentace („další informace o struktuře Star Join ") není tak poučné, i když ostatní detaily jsou docela zajímavé – podíváme se na ně podrobně.
Pokud se podíváte na svůj oblíbený vyhledávač pro více informací pomocí výrazů jako „SQL Server hvězdicová optimalizace spojení“, pravděpodobně uvidíte výsledky popisující optimalizované bitmapové filtry. Toto je samostatná funkce pouze pro podniky představená v SQL Server 2008 a nesouvisí s StarJoinInfo struktura vůbec.
Optimalizace pro selektivní hvězdné dotazy
Přítomnost StarJoinInfo označuje, že SQL Server použil jednu ze sady optimalizací zaměřených na selektivní dotazy hvězdného schématu. Tyto optimalizace jsou dostupné ze serveru SQL Server 2005 ve všech edicích (nejen Enterprise). Všimněte si, že selektivní zde odkazuje na počet řádků načtených z tabulky faktů. Kombinace dimenzionálních predikátů v dotazu může být stále selektivní, i když její jednotlivé predikáty kvalifikují velký počet řádků.
Křižovatka běžného indexu
Optimalizátor dotazů může zvážit zkombinování více neklastrovaných indexů tam, kde vhodný jediný index neexistuje, jak ukazuje následující dotaz AdventureWorks:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
Optimalizátor určí, že zkombinováním dvou neklastrovaných indexů (jeden na SalesPersonID a druhý na CustomerID ) je nejlevnější způsob, jak splnit tento dotaz (v obou sloupcích není žádný index):
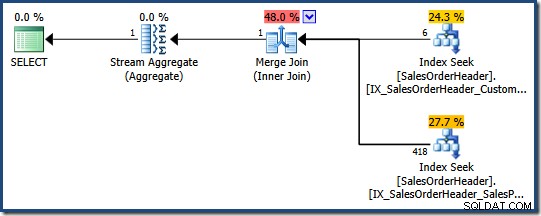
Každé hledání indexu vrací klíč seskupeného indexu pro řádky, které předávají predikát. Spojení odpovídá vráceným klíčům, aby bylo zajištěno, že pouze řádky, které odpovídají oběma predikáty jsou předávány dál.
Pokud by tabulka byla halda, každé hledání by vrátilo identifikátory řádku haldy (RID) namísto seskupených indexových klíčů, ale celková strategie je stejná:najít identifikátory řádků pro každý predikát a poté je porovnat.
Ruční křížení indexu spojení hvězd
Stejný nápad lze rozšířit na dotazy, které vybírají řádky z tabulky faktů pomocí predikátů aplikovaných na tabulky dimenzí. Chcete-li zjistit, jak to funguje, zvažte následující dotaz (pomocí vzorové databáze Contoso BI), abyste zjistili celkovou částku prodeje za MP3 přehrávače prodávané v obchodech Contoso s přesně 50 zaměstnanci:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Pro srovnání s pozdějšími snahami tento (velmi selektivní) dotaz vytváří plán dotazů, jako je tento (kliknutím rozbalíte):
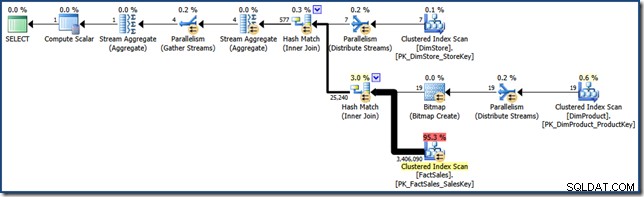
Tento plán realizace má odhadované náklady něco málo přes 15,6 jednotek . Vyznačuje se paralelním prováděním s úplným skenováním tabulky faktů (i když s aplikovaným bitmapovým filtrem).
Tabulky faktů v této ukázkové databázi ve výchozím nastavení nezahrnují indexy bez klastrů na cizích klíčích tabulky faktů, takže musíme přidat několik:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
S těmito indexy na místě můžeme začít vidět, jak lze použít průnik indexů ke zlepšení efektivity. Prvním krokem je najít identifikátory řádku tabulky faktů pro každý samostatný predikát. Následující dotazy aplikují jeden predikát dimenze, poté se připojí zpět k tabulce faktů a najdou identifikátory řádků (klíče indexu seskupených v tabulce faktů):
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; Plány dotazů zobrazují skenování tabulky malých dimenzí, po kterém následuje vyhledávání pomocí neclusterovaného indexu tabulky faktů k nalezení identifikátorů řádků (nezapomeňte, že neclusterové indexy vždy obsahují klíč klastrování základní tabulky nebo RID haldy):
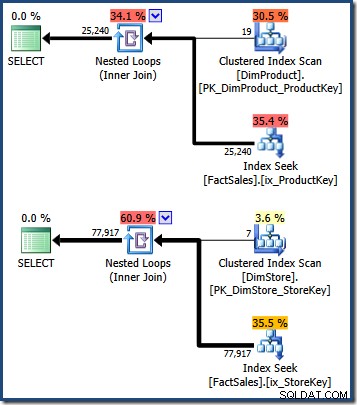
Průnik těchto dvou sad indexových klíčů seskupených tabulek faktů identifikuje řádky, které by měly být vráceny původním dotazem. Jakmile máme tyto identifikátory řádků, stačí vyhledat částku prodeje v každém řádku tabulky faktů a vypočítat součet.
Ruční indexový průsečík
Když to vše shrneme do dotazu, získáme následující:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
FORCESEEK nápověda je tam, aby zajistila, že získáme body vyhledávání v tabulce faktů. Bez toho se optimalizátor rozhodne prohledat tabulku faktů, což je přesně to, čemu se chceme vyhnout. MAXDOP 1 nápověda jen pomáhá udržet finální plán v poměrně rozumné velikosti pro účely zobrazení (kliknutím zobrazíte plnou velikost):
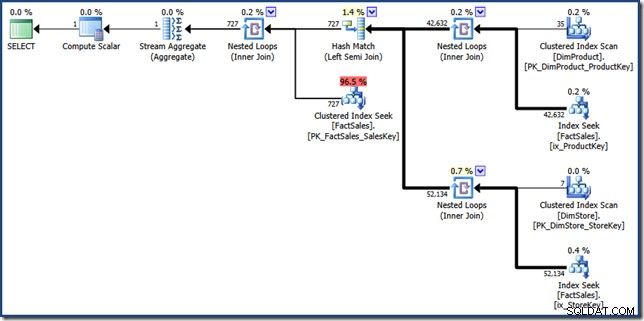
Součásti plánu křižovatky ručního indexu lze poměrně snadno identifikovat. Dva neshlukované indexové vyhledávání v tabulce faktů na pravé straně vytváří dvě sady identifikátorů řádků tabulky faktů. Hašovací spojení najde průnik těchto dvou množin. Vyhledávání seskupeného indexu do tabulky faktů najde částky prodeje pro tyto identifikátory řádků. Nakonec Stream Aggregate vypočítá celkovou částku.
Tento plán dotazů provádí relativně málo vyhledávání v neklastrovaných a seskupených indexech tabulky faktů. Pokud je dotaz dostatečně selektivní, může to být levnější strategie provádění než úplné skenování tabulky faktů. Ukázková databáze Contoso BI je relativně malá, s pouze 3,4 miliony řádků v tabulce prodejních skutečností. U větších tabulek faktů může být rozdíl mezi úplným skenováním a několika stovkami vyhledávání velmi významný. Ruční přepis bohužel přináší některé závažné chyby mohutnosti, což vede k plánu s odhadovanou cenou 46,5 jednotek .
Automatické protnutí indexu hvězdicového spojení s vyhledáváním
Naštěstí se nemusíme rozhodovat, zda je dotaz, který píšeme, dostatečně selektivní, aby ospravedlnil toto přepsání manuálu. Optimalizace hvězdicového spojení pro selektivní dotazy znamená, že optimalizátor dotazů může tuto možnost prozkoumat za nás pomocí uživatelsky přívětivější původní syntaxe dotazu:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Optimalizátor vytvoří následující plán provádění s odhadovanými náklady 1,64 jednotky (kliknutím zvětšíte):
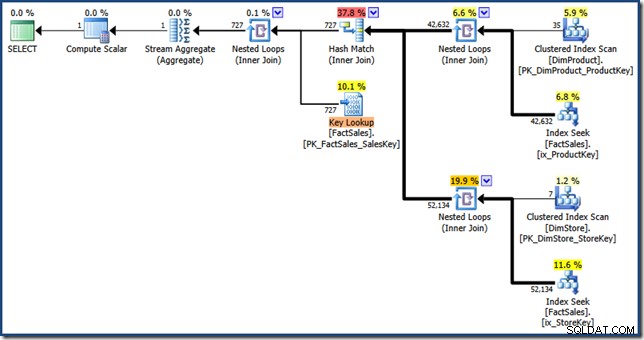
Rozdíly mezi tímto plánem a manuální verzí jsou:průsečík indexu je vnitřní spojení namísto polovičního spojení; a vyhledávání seskupeného indexu je zobrazeno jako vyhledávání klíčů namísto vyhledávání seskupeného indexu. Pokud by byla tabulka faktů hromadou, riskovalo by to pracné řešení, pokud by tabulka faktů byla hromadou, vyhledávání klíčů by bylo vyhledáváním RID.
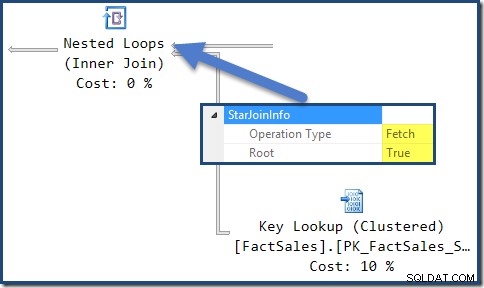
Vlastnosti StarJoinInfo
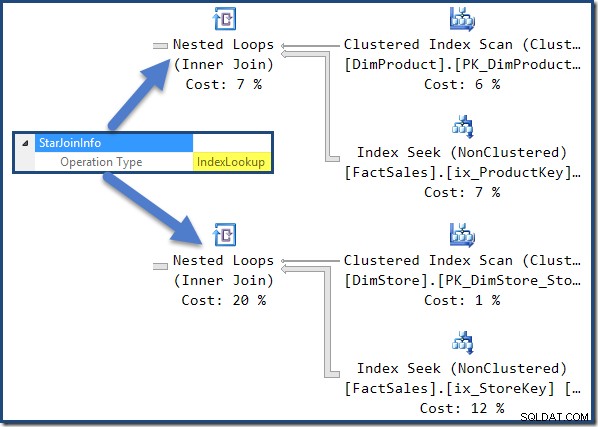
Všechna spojení v tomto plánu mají StarJoinInfo struktura. Chcete-li jej zobrazit, klikněte na iterátor spojení a podívejte se do okna Vlastnosti SSMS. Klikněte na šipku nalevo od StarJoinInfo prvek pro rozšíření uzlu.
Spojení neshlukované tabulky faktů napravo od plánu jsou vyhledávání indexů vytvořená optimalizátorem:
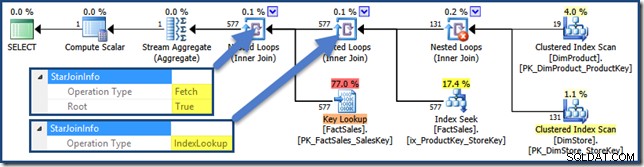
Hašovací spojení má StarJoinInfo struktura ukazující, že provádí protínání indexu (opět vytvořeno optimalizátorem):
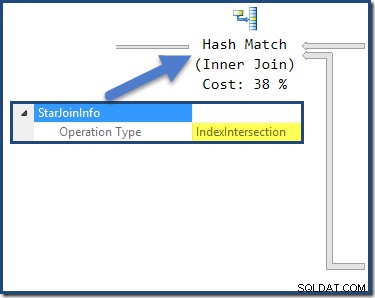
StarJoinInfo pro spojení Nested Loops nejvíce vlevo ukazuje, že byl vygenerován pro načtení řádků tabulky faktů podle identifikátoru řádku. Nachází se v kořenu podstromu hvězdicového spojení generovaného optimalizátorem:
Kartézské produkty a vyhledávání vícesloupcového indexu
Plány průsečíků indexů, které jsou považovány za součást optimalizací hvězdicového spojení, jsou užitečné pro selektivní dotazy na tabulku faktů, kde na cizích klíčích tabulky faktů existují jednosloupcové neshlukované indexy (běžná návrhová praxe).
Někdy také dává smysl vytvářet vícesloupcové indexy na cizích klíčích tabulky faktů pro často dotazované kombinace. Vestavěné selektivní optimalizace hvězdicových dotazů obsahují přepis i pro tento scénář. Chcete-li zjistit, jak to funguje, přidejte do tabulky faktů následující vícesloupcový index:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Zkompilujte testovací dotaz znovu:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Plán dotazů již neobsahuje průnik indexu (kliknutím zvětšíte):
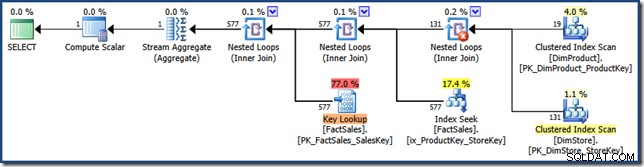
Zde zvolená strategie je aplikovat každý predikát na tabulky dimenzí, vzít kartézský součin výsledků a použít jej k vyhledání obou klíčů vícesloupcového indexu. Plán dotazů pak provede vyhledání klíčů v tabulce faktů pomocí identifikátorů řádků přesně tak, jak bylo vidět dříve.
Plán dotazů je obzvláště zajímavý, protože kombinuje tři funkce, které jsou často považovány za špatné věci (úplné skenování, kartézské produkty a vyhledávání klíčů) v optimalizaci výkonu. . Toto je platná strategie, když se očekává, že součin těchto dvou dimenzí bude velmi malý.
Neexistuje žádné StarJoinInfo pro kartézský součin, ale ostatní spojení mají informace (kliknutím zvětšíte):
Indexový filtr
Pokud se vrátíme ke schématu showplanu, existuje ještě jedno StarJoinInfo operace, kterou musíme pokrýt:
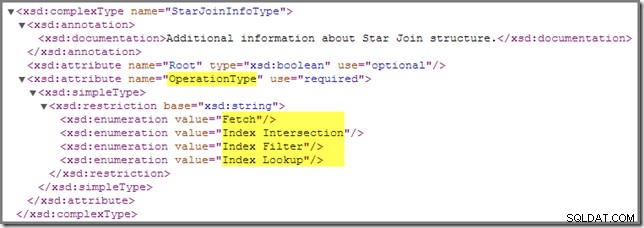
Index Filter hodnota je vidět u spojení, která jsou považována za dostatečně selektivní, aby se vyplatilo provést před načtením tabulky faktů. Spojení, která nejsou dostatečně selektivní, budou provedena po načtení a nebudou mít StarJoinInfo struktura.
Abychom viděli filtr indexu pomocí našeho testovacího dotazu, musíme do mixu přidat třetí tabulku spojení, odstranit dosud vytvořené indexy neshlukovaných tabulek faktů a přidat novou:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; Plán dotazů je nyní (kliknutím zvětšíte):
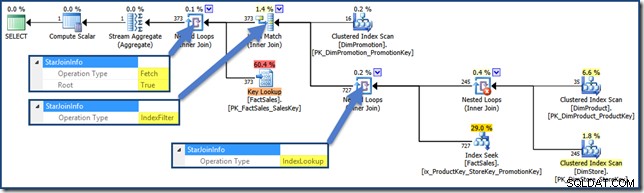
Plán dotazu na průnik indexu haldy
Pro úplnost je zde skript pro vytvoření kopie tabulky faktů se dvěma neshlukovanými indexy potřebnými k přepsání optimalizátoru průniku indexu:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; Plán provádění tohoto dotazu má stejné funkce jako dříve, ale protínání indexu se provádí pomocí RID namísto indexových klíčů seskupených v tabulce faktů a konečným načtením je vyhledávání RID (kliknutím rozbalíte):
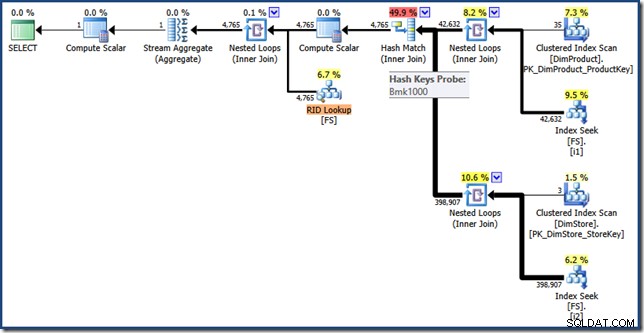
Poslední myšlenky
Zde zobrazené přepisy optimalizátoru jsou zaměřeny na dotazy, které vracejí relativně malý počet řádků z velkého tabulka faktů. Tyto přepisy jsou k dispozici ve všech edicích SQL Server od roku 2005.
Přestože je záměrem urychlit selektivní dotazy na schémata hvězd (a sněhových vloček) v datových skladech, může optimalizátor tyto techniky použít všude tam, kde zjistí vhodnou sadu tabulek a spojení. Heuristika používaná k detekci hvězdicových dotazů je poměrně široká, takže se můžete setkat s tvary plánů s StarJoinInfo struktur v téměř jakémkoli typu databáze. Jakákoli tabulka přiměřené velikosti (řekněme 100 stránek nebo více) s odkazy na menší (rozměrově podobné) tabulky je potenciálním kandidátem na tyto optimalizace (všimněte si, že explicitní cizí klíče nejsou vyžadováno).
Pro ty z vás, kteří mají rádi takové věci, se pravidlo optimalizátoru zodpovědné za generování selektivních vzorů spojení hvězd z logického spojení n-tabulek nazývá StarJoinToIdxStrategy (strategie hvězdicového spojení s indexem).