Odoo (dříve známý jako OpenERP) je sada open-source podnikových aplikací. Dodává se ve dvou verzích – komunitní a podniková. Některé z nejoblíbenějších aplikací (a zdarma!) integrovaných do této platformy jsou Diskuse, CRM, Zásoby, Webové stránky, Zaměstnanec, Dovolená, Nábor, Výdaje, Účetnictví, Fakturace, Prodejní místo a mnoho dalších.
V tomto blogovém příspěvku se podíváme na to, jak clusterovat Odoo, abyste dosáhli vysoké dostupnosti a škálovatelnosti. Tento příspěvek je podobný našim předchozím příspěvkům o škálování Drupal, WordPress, Magento. Používané software jsou Odoo 12, HAProxy 1.8.8, Keepalived 1.3.9, PostgreSQL 11 a OCFS2 (Oracle Cluster File System).
Naše nastavení se skládá ze 6 serverů:
- lb1 (HAProxy) + keepalived + ClusterControl – 192.168.55.101
- lb2 (HAProxy) + keepalived + sdílené úložiště – 192.168.55.102
- odoo1 – 192.168.55.111
- odoo2 – 192.168.55.112
- postgresql1 (master) – 192.168.55.121
- postgresql2 (otrok) – 192.168.55.122
Všechny uzly běží na Ubuntu 18.04.2 LTS (Bionic). ClusterControl budeme používat k nasazení a správě PostgreSQL, Keepalived a HAProxy, protože nám to ušetří spoustu práce. ClusterControl bude umístěn společně s HAProxy na lb1, zatímco k lb2 přidáme další disk, který bude použit jako poskytovatel sdíleného úložiště. Tento disk bude připojen pomocí klastrového systému souborů s názvem OCFS2 jako sdílený adresář. Virtuální IP adresa 192.168.55.100 funguje jako jediný koncový bod pro naši databázovou službu.
Následující diagram znázorňuje naši celkovou architekturu systému:
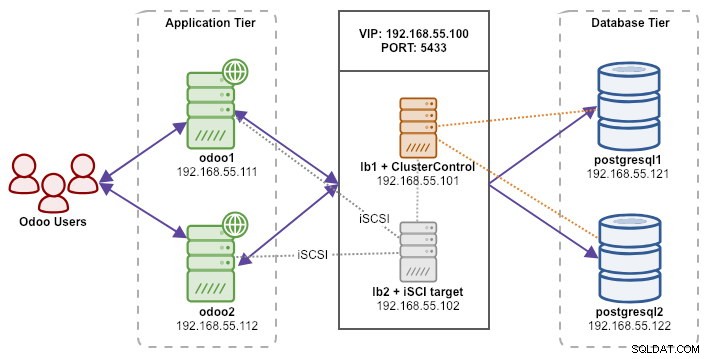
Níže je uveden obsah /etc/hosts na všech uzlech:
192.168.55.101 lb1.local lb1 cc.local cc
192.168.55.102 lb2.local lb2 storage.local storage
192.168.55.111 odoo1.local odoo1
192.168.55.112 odoo2.local odoo2
192.168.55.121 postgresql1.local postgresql1
192.168.55.122 postgresql2.local postgresql2Nasazení replikace streamování PostgreSQL
Začneme instalací ClusterControl na lb1:
$ wget severalnines.com/downloads/cmon/install-cc
$ chmod 755 ./install-cc
$ sudo ./install-ccPostupujte podle průvodce instalací, během procesu budete muset odpovědět na některé otázky.
Nastavte SSH bez hesla z uzlu ClusterControl (lb1) do všech uzlů, které budou spravovány pomocí ClusterControl, což je lb1 (sám o sobě), lb2, postresql1 a postgresql2. Nejprve však vygenerujte klíč SSH:
$ whoami
ubuntu
$ ssh-keygen -t rsa # press Enter on all promptsPoté zkopírujte klíč do všech cílových uzlů pomocí nástroje ssh-copy-id:
$ whoami
ubuntu
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.comOtevřete uživatelské rozhraní ClusterControl na adrese https://192.168.55.101/clustercontrol a vytvořte uživatele superadmin s heslem. Budete přesměrováni na řídicí panel uživatelského rozhraní ClusterControl. Poté nasaďte nový cluster PostgreSQL kliknutím na tlačítko "Deploy" v horní nabídce. Zobrazí se následující dialogové okno nasazení:
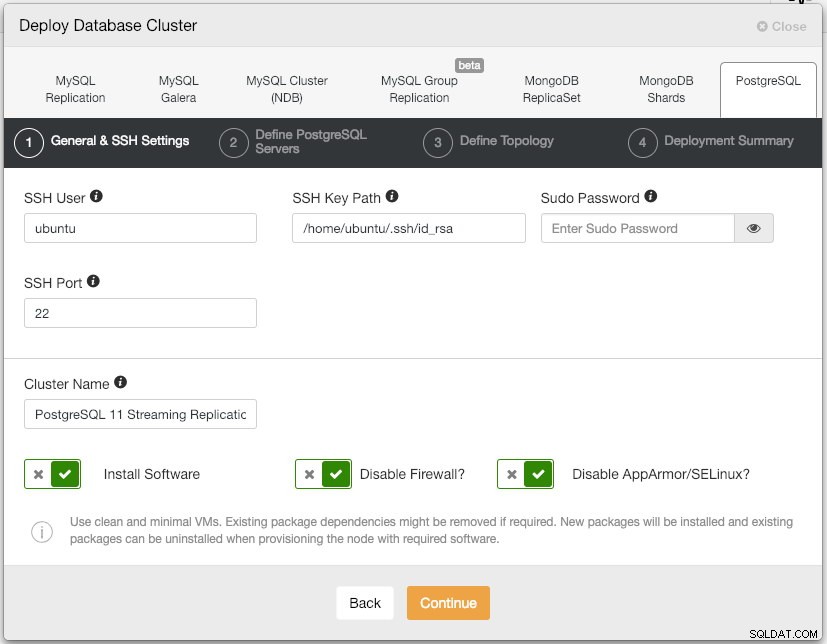
Zde je to, co jsme napsali v dalším dialogu, "Define PostgreSQL Servers":
- Port serveru:5432
- Uživatel:postgres
- Heslo:s3cr3t
- Verze:11
- Datadir:
- Úložiště:Používejte úložiště dodavatelů
V části "Definovat topologii" zadejte IP adresu postgresql1 a postgresql2 podle toho:
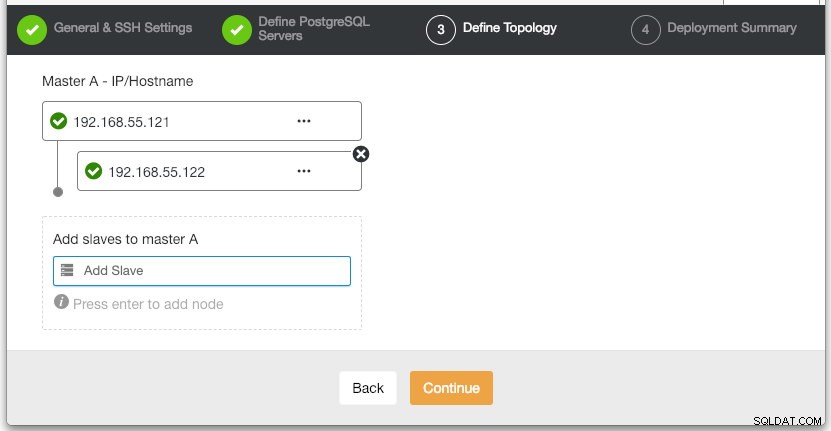
V poslední části "Shrnutí nasazení" máte možnost povolit synchronní replikaci. Protože budeme slave používat pouze pro účely převzetí služeb při selhání (slave nebude obsluhovat žádné operace čtení), ponecháme výchozí hodnotu tak, jak je. Poté stisknutím tlačítka "Deploy" spusťte nasazení clusteru databáze. Průběh nasazení můžete sledovat v Aktivita> Úlohy> Vytvořit klastr :
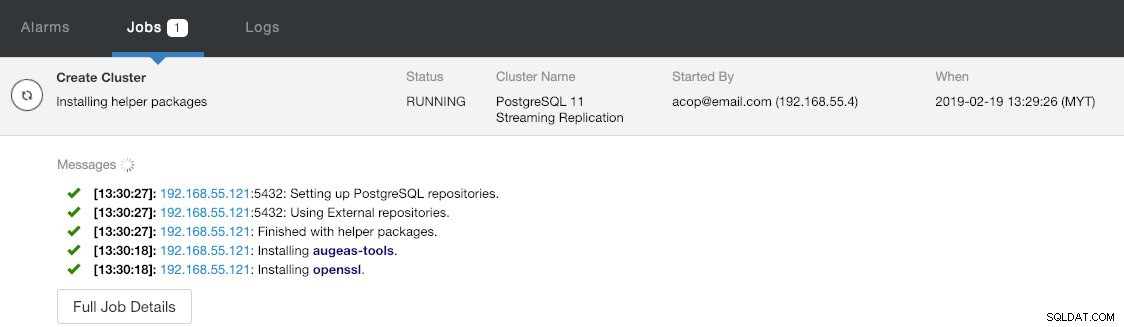
Mezitím si dejte kávu a nasazení clusteru by mělo být dokončeno během 10–15 minut.
Nasazení Load Balancerů a virtuální IP adresy pro PostgreSQL servery
V tuto chvíli již máme dvouuzlový replikační cluster PostgreSQL spuštěný v nastavení master-slave:

Dalším krokem je nasazení vrstvy nástroje pro vyrovnávání zatížení pro naši databázi, což nám umožňuje propojit ji s virtuální IP adresou a poskytnout aplikaci jeden koncový bod. Nakonfigurujeme možnosti nasazení HAProxy takto:
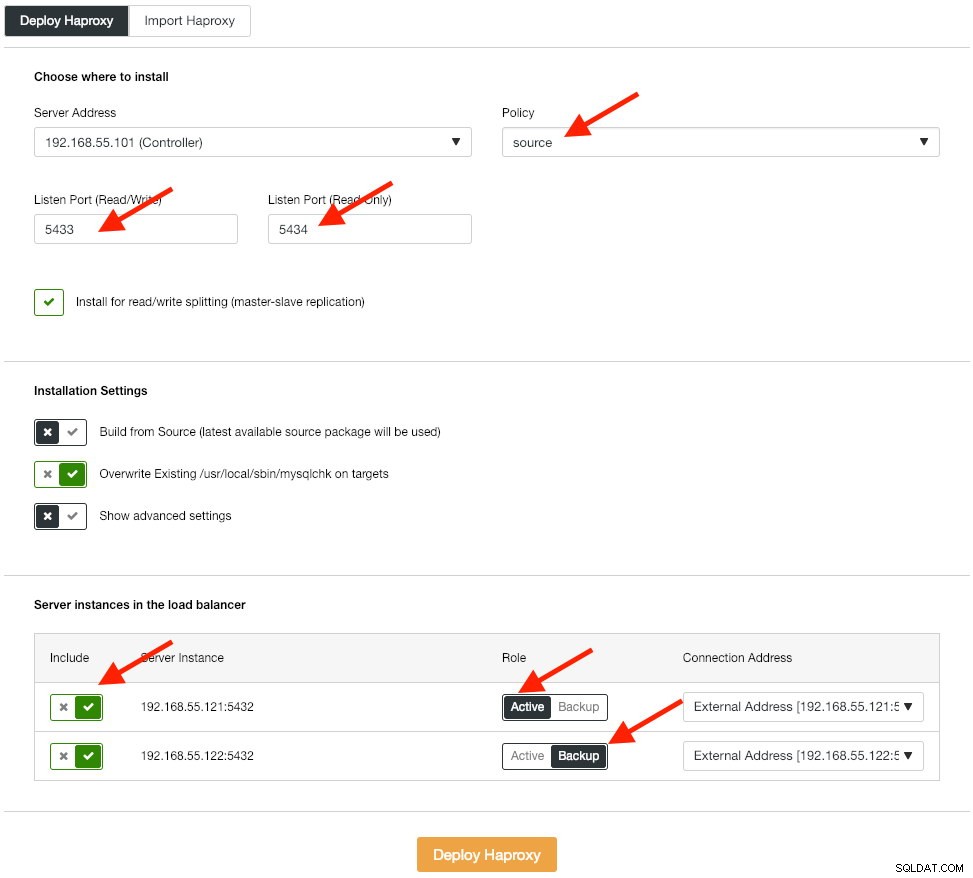
Aplikace nativně nepodporuje dělení čtení a zápisu, takže k dosažení vysoké dostupnosti použijeme aktivní-pasivní metodu. Nejlepším algoritmem pro vyrovnávání zátěže je zásada "zdroje", protože v jednu chvíli používáme pouze jeden uzel PostgreSQL.
Opakujte stejný krok pro další vyvažovač zátěže, lb2. Místo toho změňte "Adresu serveru" na 192.168.55.102. Zde je, jak to vypadá po dokončení nasazení, pokud přejdete na stránku Nodes:
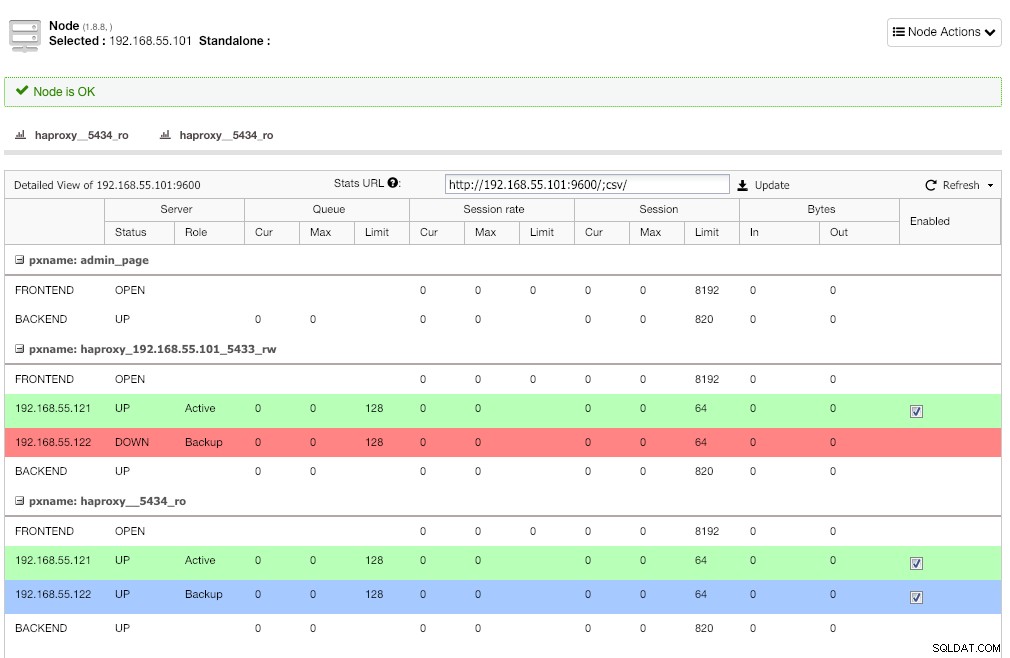
Červená čára na prvním posluchači se očekává tam, kde HAProxy ukazuje, že postgresql2 (192.168.55.122) je nefunkční, protože skript kontroly stavu vrací uzel je aktivní, ale není hlavní. Druhý posluchač s modrou čarou (haproxy_5434_ro) ukazuje, že uzel je UP, ale ve stavu "záloha". Tento posluchač však může být ignorován, protože aplikace nepodporuje rozdělení čtení a zápisu.
Dále nasadíme instance Keepalived na tyto nástroje pro vyrovnávání zatížení, abychom je spojili s jedinou virtuální IP adresou. Přejděte na Spravovat -> Load Balancer -> Keepalived -> Nasadit Keepalived a zadejte první a druhou instanci HAProxy, poté virtuální IP adresu a síťové rozhraní, které chcete poslouchat:
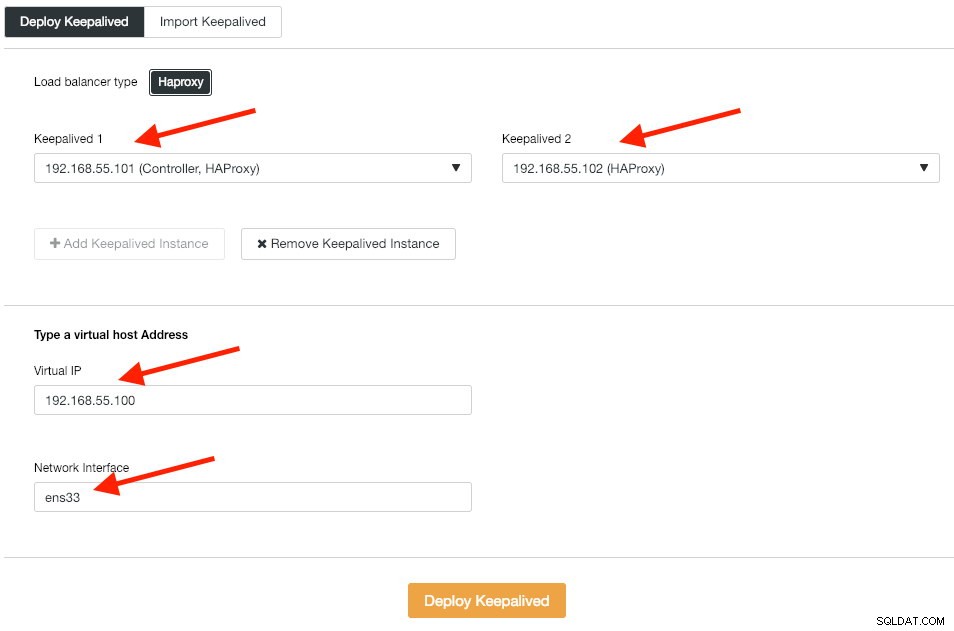
Kliknutím na „Deploy Keepalived“ zahájíte nasazení. Služba připojení PostgreSQL je nyní vyrovnána zatížením pro oba databázové uzly a je přístupná přes 192.168.55.100 port 5433.
Konfigurace iSCSI
Úložný server (lb2) potřebuje exportovat disk přes iSCSI, aby jej bylo možné připojit na oba aplikační servery Odoo (odoo1 a odoo2). iSCSI v podstatě říká vašemu jádru, že máte disk SCSI, a přenáší tento přístup přes IP. „Server“ se nazývá „cíl“ a „klient“, který toto zařízení iSCSI používá, je „iniciátor“.
Nejprve nainstalujte cíl iSCSI v lb2:
$ sudo apt install -y tgtPovolit tgt při spouštění:
$ systemctl enable tgtJe preferováno mít samostatný disk pro shlukování systému souborů. Proto použijeme další disk připojený v lb2 (/dev/sdb), který bude sdílen mezi aplikačními servery (odoo1 a odoo2). Nejprve vytvořte cíl iSCSI pomocí nástroje tgtadm:
$ sudo tgtadm --lld iscsi --op new --mode target --tid 1 -T iqn.2019-02.lb2:odcfs2Poté přiřaďte blokové zařízení /dev/sdb k číslu logické jednotky (LUN) 1 spolu s cílovým ID 1:
$ sudo tgtadm --lld iscsi --op new --mode logicalunit --tid 1 --lun 1 -b /dev/sdbPoté povolte iniciačním uzlům ve stejné síti přístup k tomuto cíli:
$ sudo tgtadm --lld iscsi --op bind --mode target --tid 1 --initiator-address 192.168.55.0/24Pomocí nástroje tgt-admin vypište konfigurační řádky iSCSI a uložte je jako konfigurační soubor, aby byl trvalý i po restartu:
$ sudo tgt-admin --dump > /etc/tgt/conf.d/shareddisk.confNakonec restartujte cílovou službu iSCSI:
$ sudo systemctl restart tgt** Následující kroky by měly být provedeny na odeo1 a odoo2.
Nainstalujte iniciátor iSCSI na příslušné hostitele:
$ sudo apt-get install -y open-iscsiNastavte iniciátor iSCSI na automatické spouštění:
$ sudo systemctl enable open-iscsiObjevte cíle iSCSI, které jsme nastavili dříve:
$ sudo iscsiadm -m discovery -t sendtargets -p lb2
192.168.55.102:3260,1 iqn.2019-02.lb2:odcfs2Pokud uvidíte podobný výsledek jako výše, znamená to, že vidíme a můžeme se připojit k cíli iSCSI. Pro připojení k cíli iSCSI na lb2 použijte následující příkaz:
$ sudo iscsiadm -m node --targetname iqn.2019-02.lb2:odcfs2 -p lb2 -l
Logging in to [iface: default, target: iqn.2019-02.lb2:odcfs2, portal: 192.168.55.102,3260] (multiple)
Login to [iface: default, target: iqn.2019-02.lb2:odcfs2, portal: 192.168.55.102,3260] successful.Ujistěte se, že vidíte nový pevný disk (/dev/sdb) uvedený v adresáři /dev:
$ sudo ls -1 /dev/sd*
/dev/sda
/dev/sda1
/dev/sda2
/dev/sda3
/dev/sdbNáš sdílený disk je nyní připojen na oba aplikační servery (odoo1 a odoo2).
Konfigurace OCFS2 pro Odoo
** Následující kroky by měly být provedeny na odoo1, pokud není uvedeno jinak.
OCFS2 umožňuje připojení souborového systému na více než jedno místo. Nainstalujte nástroje OCFS2 na servery odoo1 i odoo2:
$ sudo apt install -y ocfs2-toolsVytvořte tabulku rozdělení disku pro jednotku pevného disku /dev/sdb:
$ sudo cfdisk /dev/sdbVytvořte oddíl pomocí následujících sekvencí v průvodci cfdisk:Nový> Primární> přijmout velikost> Zapsat> ano> Ukončit .
Vytvořte souborový systém OCFS2 na /dev/sdb1:
$ sudo mkfs.ocfs2 -b 4K -C 128K -L "Odoo_Cluster" /dev/sdb1
mkfs.ocfs2 1.8.5
Cluster stack: classic o2cb
Label: Odoo_Cluster
Features: sparse extended-slotmap backup-super unwritten inline-data strict-journal-super xattr indexed-dirs refcount discontig-bg append-dio
Block size: 4096 (12 bits)
Cluster size: 131072 (17 bits)
Volume size: 21473656832 (163831 clusters) (5242592 blocks)
Cluster groups: 6 (tail covers 2551 clusters, rest cover 32256 clusters)
Extent allocator size: 4194304 (1 groups)
Journal size: 134217728
Node slots: 8
Creating bitmaps: done
Initializing superblock: done
Writing system files: done
Writing superblock: done
Writing backup superblock: 3 block(s)
Formatting Journals: done
Growing extent allocator: done
Formatting slot map: done
Formatting quota files: done
Writing lost+found: done
mkfs.ocfs2 successfulVytvořte konfigurační soubor clusteru v /etc/ocfs2/cluster.conf a definujte direktivy node a cluster, jak je uvedeno níže:
# /etc/ocfs2/cluster.conf
cluster:
node_count = 2
name = ocfs2
node:
ip_port = 7777
ip_address = 192.168.55.111
number = 1
name = odoo1
cluster = ocfs2
node:
ip_port = 7777
ip_address = 192.168.55.112
number = 2
name = odoo2
cluster = ocfs2Všimněte si, že atributy pod klauzulí uzlu nebo clusteru musí být za tabulátorem.
** Následující kroky by měly být provedeny na odeo1 a odoo2, pokud není uvedeno jinak.
Vytvořte stejný konfigurační soubor (/etc/ocfs2/cluster.conf) na odoo2. Tento soubor by měl být stejný ve všech uzlech v klastru a změny provedené v tomto souboru musí být přeneseny do ostatních uzlů v klastru.
Restartujte službu o2cb, abyste použili změny, které jsme provedli v /etc/ocfs2/cluster.conf:
$ sudo systemctl restart o2cbVytvořte adresář souborů Odoo pod /var/lib/odoo:
$ sudo mkdir -p /var/lib/odooZískejte ID bloku pro zařízení /dev/sdb1. UUID se doporučuje ve fstab, pokud používáte zařízení iSCSI:
$ sudo blkid /dev/sdb1 | awk {'print $3'}
UUID="93a2b6c4-d800-4532-9a9b-2d2f2f1a726b"Při přidávání následujícího řádku do /etc/fstab použijte hodnotu UUID:
UUID=93a2b6c4-d800-4532-9a9b-2d2f2f1a726b /var/lib/odoo ocfs2 defaults,_netdev 0 0Zaregistrujte cluster ocfs2 a připojte souborový systém z fstab:
$ sudo o2cb register-cluster ocfs2
$ sudo mount -a
Ověřte pomocí:
$ mount | grep odoo
/dev/sdb1 on /var/lib/odoo type ocfs2 (rw,relatime,_netdev,heartbeat=local,nointr,data=ordered,errors=remount-ro,atime_quantum=60,coherency=full,user_xattr,acl,_netdev)Pokud vidíte výše uvedený řádek na všech aplikačních serverech, je dobré nainstalovat Odoo.
Instalace a konfigurace Odoo 12
** Následující kroky by měly být provedeny na odeo1 a odoo2, pokud není uvedeno jinak.
Nainstalujte Odoo 12 přes úložiště balíčků:
$ wget -O - https://nightly.odoo.com/odoo.key | sudo apt-key add -
$ echo "deb https://nightly.odoo.com/12.0/nightly/deb/ ./" | sudo tee -a /etc/apt/sources.list.d/odoo.list
$ sudo apt update && sudo apt install odooVe výchozím nastavení výše uvedený příkaz automaticky nainstaluje server PostgreSQL na stejného hostitele jako součást závislostí Odoo. Pravděpodobně to chceme zastavit, protože stejně nebudeme používat místní server:
$ sudo systemctl stop postgresql
$ sudo systemctl disable postgresqlNa postgresql1 vytvořte uživatele databáze s názvem "odoo":
$ sudo -i
$ su - postgres
$ createuser --createrole --createdb --pwprompt odooVe výzvě zadejte heslo. Poté na postgresql1 i postgresql2 přidejte do pg_hba.conf následující řádek, aby se aplikace a uzly vyrovnávání zatížení mohly připojit. Stejně jako v našem případě se nachází na /etc/postgresql/11/main/pg_hba.conf:
host all all 192.168.55.0/24 md5Poté znovu načtěte server PostgreSQL, aby se načetly změny:
$ su - postgres
$ /usr/lib/postgresql/11/bin/pg_ctl reload -D /var/lib/postgresql/11/main/Upravte konfigurační soubor Odoo na /etc/odoo/odoo.conf a podle toho nakonfigurujte parametry admin_passwd, db_host a db_password:
[options]
; This is the password that allows database operations:
admin_passwd = admins3cr3t
db_host = 192.168.55.100
db_port = 5433
db_user = odoo
db_password = odoopassword
;addons_path = /usr/lib/python3/dist-packages/odoo/addonsRestartujte Odoo na obou serverech, aby se načetly nové změny:
$ sudo systemctl restart odooOtevřete Odoo na jednom z aplikačních serverů prostřednictvím webového prohlížeče. V tomto příkladu jsme se připojili k odoo1, takže adresa URL je https://192.168.55.111:8069/ a měli byste vidět následující úvodní stránku:
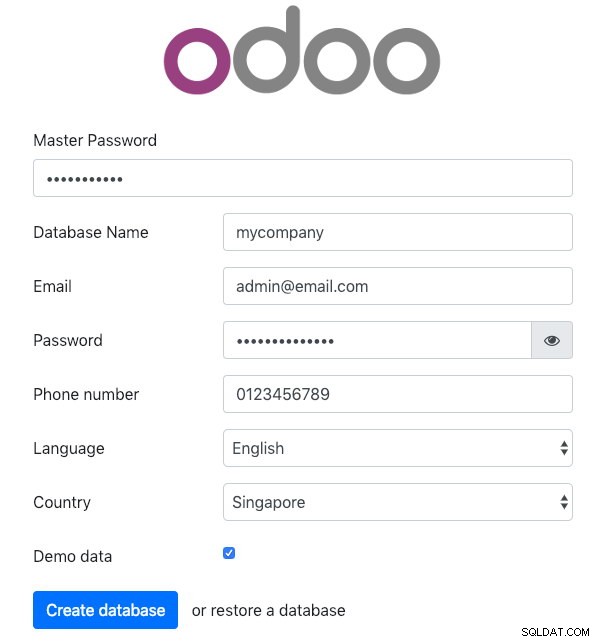
Zadejte „Hlavní heslo“ shodné s hodnotou admin_passwd definovanou v konfiguračním souboru Odoo. Poté vyplňte všechny požadované informace pro novou společnost, která bude tuto platformu používat.
Po dokončení chvíli počkejte, než se inicializace dokončí. Budete přesměrováni na administrační panel Odoo:

V tomto okamžiku je instalace Odoo dokončena a můžete začít konfigurovat obchodní aplikace pro tuto společnost. Všechny změny souborů provedené tímto aplikačním serverem budou uloženy v clusterovém souborovém systému umístěném na "/var/lib/odoo/.local" (který je také připojen k jinému aplikačnímu serveru, odoo2), zatímco změny v databázi budou probíhat. na hlavním uzlu PostgreSQL.
Navzdory tomu, že běží na dvou různých hostitelích, mějte na paměti, že samotná aplikace Odoo není v tomto psaní vyvážená. Můžete použít instance HAProxy nasazené pro databázový cluster k dosažení lepší dostupnosti, stejně jako databázová služba. Navíc je systém souborů sdíleného disku (OCFS2) používaný oběma aplikačními servery stále vystaven jedinému selhání, protože všechny používají stejné zařízení iSCSI na lb2 (představte si, že lb2 je nepřístupný).
Operace při selhání databáze
Možná se ptáte, co by se stalo, kdyby hlavní server PostgreSQL selhal. Pokud k tomu dojde, ClusterControl automaticky povýší běžícího slave na master, jak je znázorněno na obrázku níže:
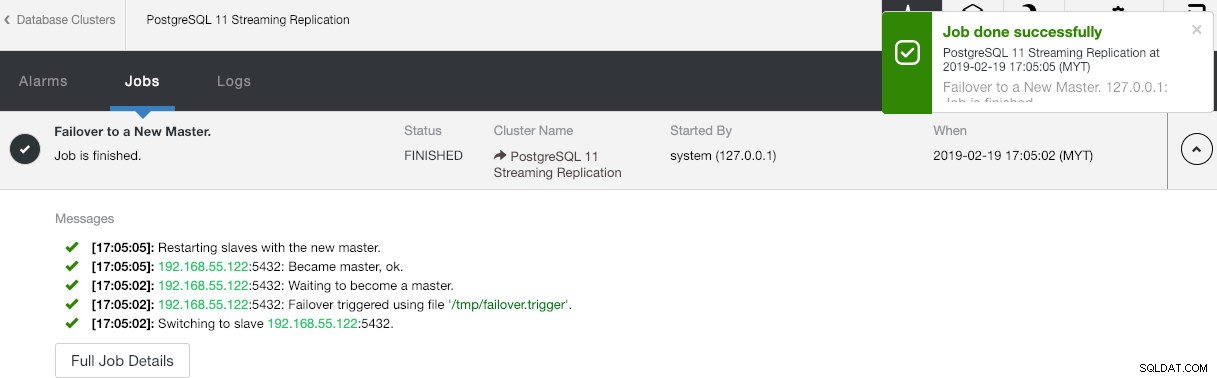
Koncový uživatel nemusí nic dělat, protože převzetí služeb při selhání se provádí automaticky (po 30sekundové dodatečné lhůtě). Po dokončení převzetí služeb při selhání bude nová topologie hlášena ClusterControl jako:
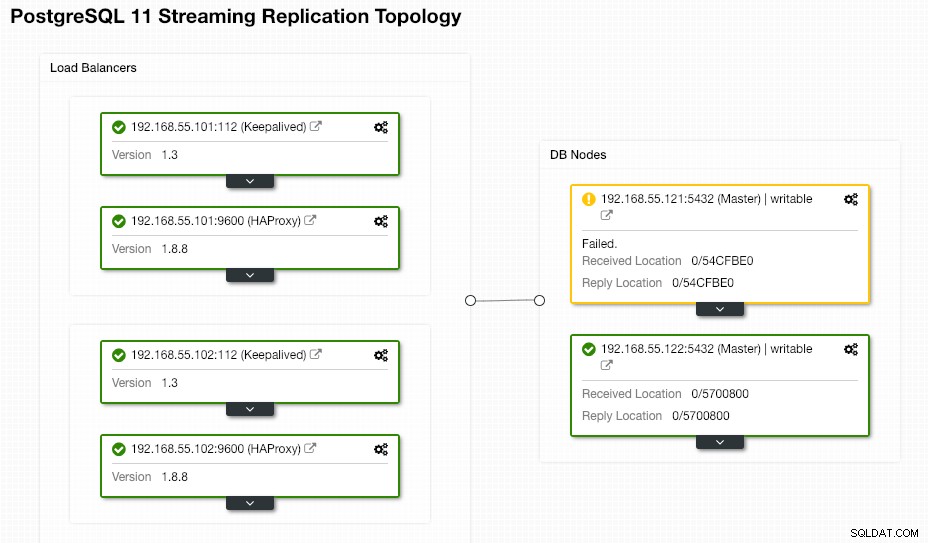
Pokud se starý hlavní server vrátí, služba PostgreSQL se automaticky vypne a další věc, kterou musí uživatel udělat, je znovu synchronizovat starý hlavní server zpět z nového hlavního serveru tím, že přejde na Akce uzlů> Znovu vytvořit replikační slave zařízení :
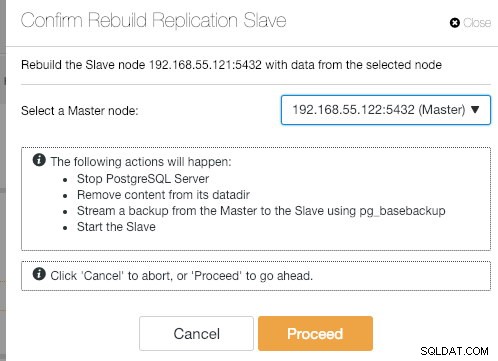
Po dokončení operace synchronizace se starý hlavní server stane otrokem nového hlavního serveru:
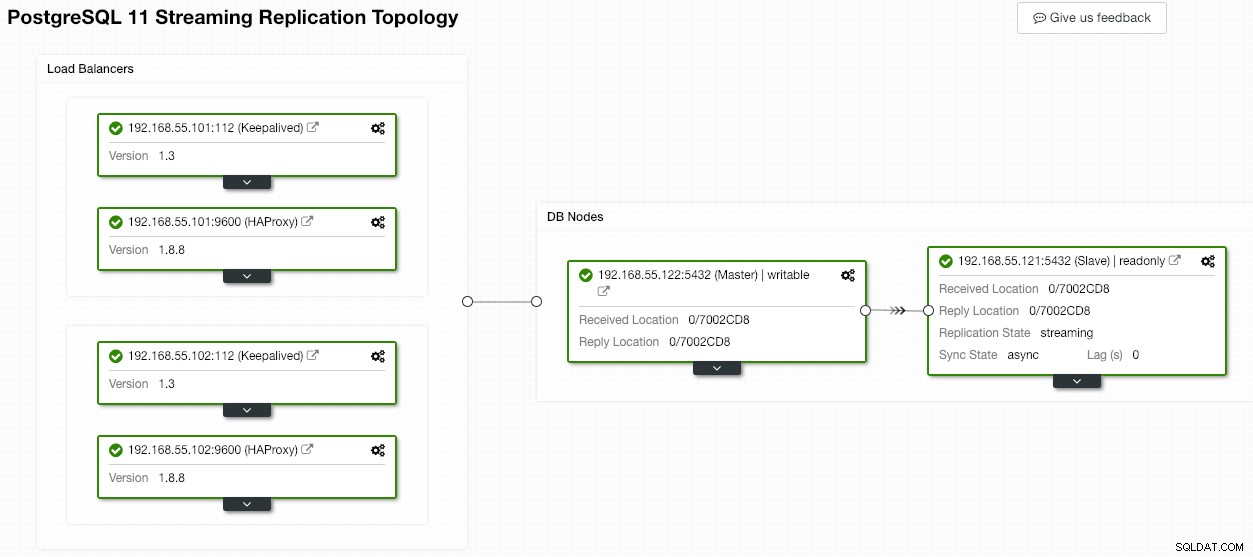
ClusterControl jistě zlepšuje dostupnost databáze pomocí funkce automatického obnovení a opětovná synchronizace špatného databázového uzlu je vzdálena pouze dvě kliknutí. Jak jednoduché je to po katastrofické poruše?
To je zatím vše lidi. Šťastné shlukování!