Mnoho lidí používá statistiku čekání jako součást své celkové metodiky řešení problémů s výkonem, stejně jako já, takže otázka, kterou jsem chtěl v tomto příspěvku prozkoumat, se týká typů čekání spojených s režií pozorovatele. Režií pozorovatele mám na mysli dopad na propustnost zátěže SQL Server způsobený SQL Profilerem, trasováním na straně serveru nebo relacemi Extended Event. Více o tématu pozorovatele nad hlavou naleznete v následujících dvou příspěvcích od mého kolegy Jonathana Kehayiase :
- Měření „režie pozorovatele“ trasování SQL vs. rozšířené události
- Dopad události query_post_execution_showplan Extended v SQL Server 2012
Takže v tomto příspěvku bych rád prošel několika variacemi pozorovatele nad hlavou a zjistil, zda najdeme konzistentní typy čekání spojené s měřenou degradací. Existuje celá řada způsobů, jak uživatelé SQL Serveru implementují trasování ve svých produkčních prostředích, takže vaše výsledky se mohou lišit, ale chtěl jsem pokrýt několik širokých kategorií a podat zprávu o tom, co jsem našel:
- Využití relace SQL Profiler
- Využití trasování na straně serveru
- Využití trasování na straně serveru, zápis do pomalé I/O cesty
- Rozšířené použití událostí s cílem kruhové vyrovnávací paměti
- Použití rozšířených událostí s cílem souboru
- Využití rozšířených událostí s cílem souboru na pomalé cestě I/O
- Rozšířené použití událostí s cílem souboru na pomalé cestě I/O bez ztráty události
Pravděpodobně si můžete vymyslet další variace na toto téma a vyzývám vás, abyste se podělili o jakékoli zajímavé poznatky týkající se statistiky pozorovatele a čekání jako komentář v tomto příspěvku.
Základní čára
K testu jsem použil virtuální stroj VMware se čtyřmi vCPU a 4GB RAM. Můj host virtuálního stroje byl na OCZ Vertex SSD. Operačním systémem byl Windows Server 2008 R2 Enterprise a verze SQL Server je 2012, SP1 CU4.
Pokud jde o „pracovní zátěž“, používám dotaz pouze pro čtení ve smyčce proti vzorové databázi kreditů z roku 2008, nastavenou na GO 10 000 000krát.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 Tento dotaz také provádím prostřednictvím 16 souběžných relací. Konečným výsledkem na mém testovacím systému je 100% využití CPU napříč všemi vCPU na virtuálním hostovi a průměrně 14 492 dávkových požadavků za sekundu během 2 minut.
Pokud jde o sledování událostí, v každém testu jsem použil Showplan XML Statistics Profile pro SQL Profiler a trasovací testy na straně serveru – a query_post_execution_showplan pro relace Extended Event. Události plánu provádění jsou velmi drahé, a to je přesně důvod, proč jsem si je vybral, abych viděl, jestli za extrémních okolností dokážu odvodit témata typu čekání.
Pro testování akumulace typu čekání během testovacího období jsem použil následující dotaz. Nic převratného – stačí vymazat statistiky, počkat 2 minuty a poté shromáždit 10 nejlepších nahromadění čekání pro instanci SQL Server během období testu degradace:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Všimněte si, že nejsem odfiltrování typů čekání na pozadí, které jsou obvykle odfiltrovány, a to proto, že jsem nechtěl eliminovat něco, co je normálně neškodné – ale za těchto okolností ve skutečnosti ukazuje na skutečnou oblast, kterou je třeba dále prozkoumat.
Relace SQL Profiler
Následující tabulka ukazuje dávkové požadavky před a po za sekundu při povolení sledování trasování místního SQL Profiler Showplan XML Statistics Profile (běžící na stejném virtuálním počítači jako instance SQL Server):
| Výchozí dávkové požadavky za sekundu (průměr 2 minuty) | Hromadné požadavky relací SQL Profiler za sekundu (průměr 2 minuty) |
|---|---|
| 14 492 | 1 416 |
Můžete vidět, že trasování SQL Profiler způsobuje významný pokles propustnosti.
Pokud jde o kumulovanou dobu čekání za stejné období, nejčastější typy čekání byly následující (stejně jako u ostatních testů v tomto článku jsem provedl několik testovacích běhů a výstup byl obecně konzistentní):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| TRACEWRITE | 67 142 | 1 149 824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 313 | 180 449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120 086 |
| LAZYWRITER_SLEEP | 120 | 120 059 |
| DIRTY_PAGE_POLL | 1 198 | 120 038 |
| HADR_WORK_QUEUE | 12 | 120 015 |
| LOGMGR_QUEUE | 937 | 120 011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 006 |
Typ čekání, který mi naskočí, je TRACEWRITE – který je definován Books Online jako typ čekání, který „nastane, když poskytovatel trasování sady řádků SQL čeká na volnou vyrovnávací paměť nebo vyrovnávací paměť s událostmi ke zpracování“. Zbývající typy čekání vypadají jako standardní typy čekání na pozadí, které by se obvykle odfiltrovaly z vaší sady výsledků. A co víc, o podobném problému s nadměrným sledováním jsem mluvil v roce 2011 v článku nazvaném Observer overhead – nebezpečí přílišného sledování – takže jsem tento typ čekání někdy znal. správně ukazovat na problémy nad hlavou pozorovatele. V tomto konkrétním případě, o kterém jsem blogoval, to nebyl SQL Profiler, ale jiná aplikace využívající poskytovatele trasování sady řádků (neefektivně).
Trasování na straně serveru
To bylo pro SQL Profiler, ale co režie trasování na straně serveru? Následující tabulka ukazuje dávkové požadavky před a po za sekundu při povolení zápisu trasování do souboru na straně místního serveru:
| Výchozí dávkové požadavky za sekundu (průměr 2 minuty) | Dávkové požadavky SQL Profiler za sekundu (průměr 2 minuty) |
|---|---|
| 14 492 | 4 015 |
Nejčastější typy čekání byly následující (provedl jsem několik testovacích běhů a výstup byl konzistentní):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 015 |
| SLEEP_TASK | 253 | 180 871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 046 |
| HADR_WORK_QUEUE | 12 | 120 042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 021 |
| XE_DISPATCHER_WAIT | 3 | 120 006 |
| ČEKEJTE NA | 1 | 120 000 |
| LOGMGR_QUEUE | 931 | 119 993 |
| DIRTY_PAGE_POLL | 1 193 | 119 958 |
| XE_TIMER_EVENT | 55 | 119 954 |
Tentokrát nevidíme TRACEWRITE (nyní používáme poskytovatele souborů) a další typ čekání související se trasováním, nezdokumentovaný SQLTRACE_INCREMENTAL_FLUSH_SLEEP vyšplhal – ale ve srovnání s prvním testem má velmi podobnou kumulovanou dobu čekání (120 046 vs. 120 006) – a moje kolegyně Erin Stellato (@erinstellato) mluvila o tomto konkrétním typu čekání ve svém příspěvku Zjistit, kdy byly statistiky čekání naposledy vymazány . Když se tedy podíváme na ostatní typy čekání, žádný nevyskočí jako spolehlivý červený prapor.
Zápis trasování na straně serveru do pomalé I/O cesty
Co když umístíme trasovací soubor na straně serveru na pomalý disk? Následující tabulka ukazuje dávkové požadavky před a po za sekundu při povolení trasování na straně místního serveru, které zapisuje do souboru na USB klíčenku:
| Výchozí dávkové požadavky za sekundu (průměr 2 minuty) | Dávkové požadavky SQL Profiler za sekundu (průměr 2 minuty) |
|---|---|
| 14 492 | 260 |
Jak vidíme – výkon je výrazně snížen – dokonce i ve srovnání s předchozím testem.
Nejčastější typy čekání byly následující:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351 174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2 273 | 299 995 |
| SLEEP_TASK | 240 | 194 264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181 458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125 007 |
| LAZYWRITER_SLEEP | 63 | 124 437 |
| LOGMGR_QUEUE | 941 | 120 559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120 516 |
| ČEKEJTE NA | 1 | 120 515 |
| DIRTY_PAGE_POLL | 1 204 | 120 513 |
Jeden typ čekání, který pro tento test vyskočí, je nezdokumentovaný SQLTRACE_FILE_BUFFER . Na tomto není příliš zdokumentováno, ale na základě názvu můžeme kvalifikovaně odhadnout (zejména s ohledem na konfiguraci tohoto konkrétního testu).
Rozšířené události do cíle kruhové vyrovnávací paměti
Dále si projdeme zjištění pro ekvivalenty relací Extended Event. Použil jsem následující definici relace:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
Následující tabulka ukazuje dávkové požadavky před a po za sekundu při povolení relace XE s cílem kruhové vyrovnávací paměti (zachycující query_post_execution_showplan událost):
| Výchozí dávkové požadavky za sekundu (průměr 2 minuty) | Dávkové požadavky SQL Profiler za sekundu (průměr 2 minuty) |
|---|---|
| 14 492 | 4 737 |
Nejčastější typy čekání byly následující:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299 992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 006 |
| SLEEP_TASK | 240 | 181 739 |
| LAZYWRITER_SLEEP | 120 | 120 219 |
| HADR_WORK_QUEUE | 12 | 120 038 |
| DIRTY_PAGE_POLL | 1 198 | 120 035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 011 |
| LOGMGR_QUEUE | 936 | 120 008 |
| ČEKEJTE NA | 1 | 120 001 |
Nic nevyskočilo jako související s XE, pouze „hluk“ úlohy na pozadí.
Rozšířené události na cílový soubor
Co takhle změnit relaci tak, aby používala cíl souboru místo cíle kruhové vyrovnávací paměti? Následující tabulka ukazuje dávkové požadavky před a po za sekundu při povolení relace XE s cílem souboru namísto cíle kruhové vyrovnávací paměti:
| Výchozí dávkové požadavky za sekundu (průměr 2 minuty) | Dávkové požadavky SQL Profiler za sekundu (průměr 2 minuty) |
|---|---|
| 14 492 | 4 299 |
Nejčastější typy čekání byly následující:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2 103 | 299 996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 253 | 180 663 |
| LAZYWRITER_SLEEP | 120 | 120 187 |
| HADR_WORK_QUEUE | 12 | 120 029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 011 |
| ČEKEJTE NA | 1 | 120 001 |
| XE_TIMER_EVENT | 59 | 119 966 |
| LOGMGR_QUEUE | 935 | 119 957 |
Nic, s výjimkou XE_TIMER_EVENT , vyskočilo jako související s XE. Bob Ward’s Wait Type Repository to označuje za bezpečné ignorovat, pokud nebylo něco možného špatně – ale reálně byste si všimli tohoto obvykle neškodného typu čekání, pokud by byl na 9 místě ve vašem systému během snížení výkonu? A co když ho už odfiltrujete kvůli jeho normálně neškodné povaze?
Rozšířené události na cíl souboru s pomalou I/O cestou
Co když teď umístím soubor na pomalou I/O cestu? Následující tabulka ukazuje dávkové požadavky před a po za sekundu při povolení relace XE s cílem souboru na USB flash disku:
| Výchozí dávkové požadavky za sekundu (průměr 2 minuty) | Dávkové požadavky SQL Profiler za sekundu (průměr 2 minuty) |
|---|---|
| 14 492 | 4 386 |
Nejčastější typy čekání byly následující:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 046 |
| SLEEP_TASK | 253 | 180 719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120 427 |
| LAZYWRITER_SLEEP | 120 | 120 190 |
| HADR_WORK_QUEUE | 12 | 120 025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 011 |
| ČEKEJTE NA | 1 | 120 002 |
| DIRTY_PAGE_POLL | 1 197 | 119 977 |
| XE_TIMER_EVENT | 59 | 119 949 |
Opět zde není nic souvisejícího s XE, kromě XE_TIMER_EVENT .
Rozšířené události na cílový soubor s pomalou I/O cestou, bez ztráty události
Následující tabulka ukazuje dávkové požadavky před a po za sekundu při povolení relace XE s cílem souboru na USB klíčence, ale tentokrát bez povolení ztráty události (EVENT_RETENTION_MODE=NO_EVENT_LOSS) – což se nedoporučuje a uvidíte ve výsledcích, proč by to mohlo být:
| Výchozí dávkové požadavky za sekundu (průměr 2 minuty) | Dávkové požadavky SQL Profiler za sekundu (průměr 2 minuty) |
|---|---|
| 14 492 | 539 |
Nejčastější typy čekání byly následující:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8 773 | 1 707 845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 337 | 180 446 |
| LAZYWRITER_SLEEP | 120 | 120 032 |
| DIRTY_PAGE_POLL | 1 198 | 120 026 |
| HADR_WORK_QUEUE | 12 | 120 009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 006 |
| ČEKEJTE NA | 1 | 120 000 |
| XE_TIMER_EVENT | 59 | 119 944 |
S extrémním snížením propustnosti vidíme XE_BUFFERMGR_FREEBUF_EVENT skok na pozici číslo jedna v našich kumulovaných výsledcích čekací doby. Tento je dokumentováno v Books Online a Microsoft nám říká, že tato událost je spojena s relacemi XE nakonfigurovanými tak, aby nedocházelo ke ztrátě událostí a kde jsou všechny vyrovnávací paměti v relaci plné.
Vliv pozorovatele
Kromě typů čekání bylo zajímavé poznamenat, jaký dopad měla každá metoda pozorování na schopnost naší pracovní zátěže zpracovávat dávkové požadavky:
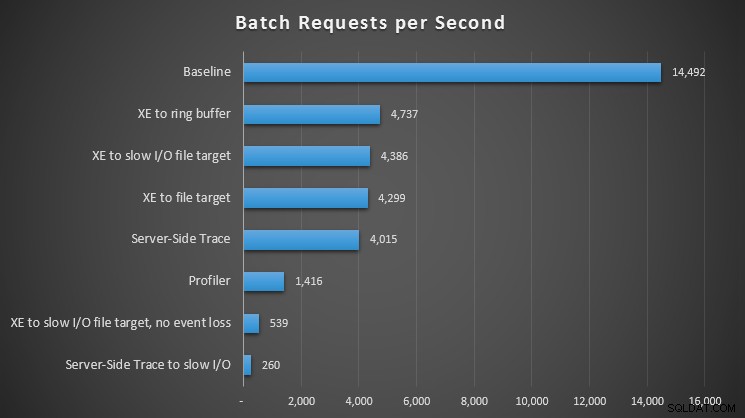
Vliv různých metod pozorování na dávkové požadavky za sekundu
U všech přístupů došlo k významnému – ale ne šokujícímu – zásahu ve srovnání s naší základní linií (žádné pozorování); nejvíce bolesti však bylo pociťováno při použití Profileru, při použití trasování na straně serveru k pomalé cestě I/O nebo rozšířených událostí k cíli souboru na pomalé cestě I/O – ale pouze při konfiguraci, aby nedošlo ke ztrátě události. Se ztrátou události se toto nastavení ve skutečnosti provádělo na stejné úrovni jako cíl souboru na rychlou cestu I/O, pravděpodobně proto, že dokázalo zahodit mnohem více událostí.
Shrnutí
Netestoval jsem všechny možné scénáře a určitě existují další zajímavé kombinace (nemluvě o různém chování na základě verze SQL Serveru), ale klíčový závěr, který si z tohoto průzkumu odnáším, je, že se nemůžete vždy spolehnout na zjevnou akumulaci typů čekání. ukazatel, když čelíte scénáři nad hlavou pozorovatele. Na základě testů v tomto příspěvku pouze tři ze sedmi scénářů vykazovaly konkrétní typ čekání, který by vám mohl pomoci nasměrovat správným směrem. Dokonce i tehdy – tyto testy probíhaly v řízeném systému – a často lidé filtrují výše uvedené typy čekání jako neškodné typy pozadí – takže je nemusíte vůbec vidět.
Vzhledem k tomu, co můžete dělat? Pro snížení výkonu bez jasných nebo zjevných příznaků doporučuji rozšířit rozsah, abyste se zeptali na trasování a relace XE (kromě toho doporučuji rozšířit rozsah, pokud je systém virtualizovaný nebo může mít nesprávné možnosti napájení). Například v rámci odstraňování problémů se systémem zkontrolujte sys.[traces] a sys.[dm_xe_sessions] abyste zjistili, zda v systému neběží něco neočekávaného. Je to další vrstva k tomu, o co se musíte starat, ale provedení několika rychlých ověření vám může ušetřit značné množství času.