Správa provozu do databáze může být stále obtížnější, protože její objem se zvyšuje a databáze je ve skutečnosti distribuována na více serverech. Klienti PostgreSQL obvykle mluví s jedním koncovým bodem. Když primární uzel selže, databázoví klienti budou opakovat stejnou IP adresu. V případě, že jste přešli na sekundární uzel, je třeba aplikaci aktualizovat pomocí nového koncového bodu. Zde byste chtěli umístit nástroj pro vyrovnávání zatížení mezi aplikace a instance databáze. Může nasměrovat aplikace na dostupné/zdravé databázové uzly a v případě potřeby přepnout na selhání. Další výhodou by bylo zvýšení výkonu čtení efektivním používáním replik. Je možné vytvořit port pouze pro čtení, který vyrovnává čtení napříč replikami. V tomto blogu se budeme zabývat HAProxy. Uvidíme, co to je, jak to funguje a jak to nasadit pro PostgreSQL.
Co je HAProxy?
HAProxy je proxy server s otevřeným zdrojovým kódem, který lze použít k implementaci vysoké dostupnosti, vyvažování zátěže a proxy pro aplikace založené na TCP a HTTP.
Jako nástroj pro vyrovnávání zatížení HAProxy distribuuje provoz z jednoho zdroje do jednoho nebo více cílů a může pro tento úkol definovat specifická pravidla a/nebo protokoly. Pokud některý z cílů přestane reagovat, je označen jako offline a provoz je odeslán do zbývajících dostupných cílů.
Jak ručně nainstalovat a nakonfigurovat HAProxy
K instalaci HAProxy na Linux můžete použít následující příkazy:
V OS Ubuntu/Debian:
$ apt-get install haproxy -yNa CentOS/RedHat OS:
$ yum install haproxy -yA pak musíme upravit následující konfigurační soubor, abychom mohli spravovat naši konfiguraci HAProxy:
$ /etc/haproxy/haproxy.cfgKonfigurace našeho HAProxy není složitá, ale musíme vědět, co děláme. Máme několik parametrů, které musíme nakonfigurovat, podle toho, jak chceme, aby HAProxy fungovala. Pro více informací se můžeme řídit dokumentací o konfiguraci HAProxy.
Podívejme se na příklad základní konfigurace. Předpokládejme, že máte následující topologii databáze:
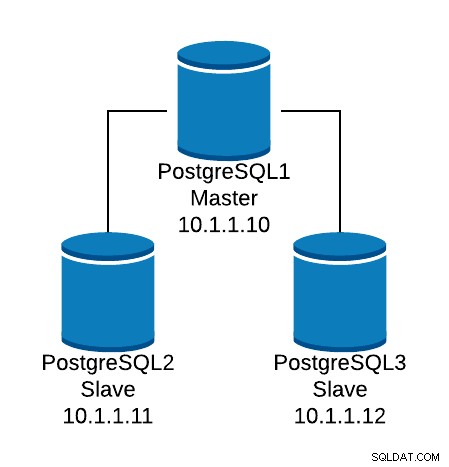 Příklad topologie databáze
Příklad topologie databáze Chceme vytvořit posluchač HAProxy, abychom vyvážili čtecí provoz mezi třemi uzly.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkJak jsme zmínili dříve, je zde několik parametrů, které je třeba nakonfigurovat, a tato konfigurace závisí na tom, co chceme dělat. Například:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkJak HAProxy funguje na ClusterControl
Pro PostgreSQL je HAProxy konfigurováno ClusterControl se dvěma různými porty ve výchozím nastavení, jedním pro čtení-zápis a jedním pouze pro čtení.
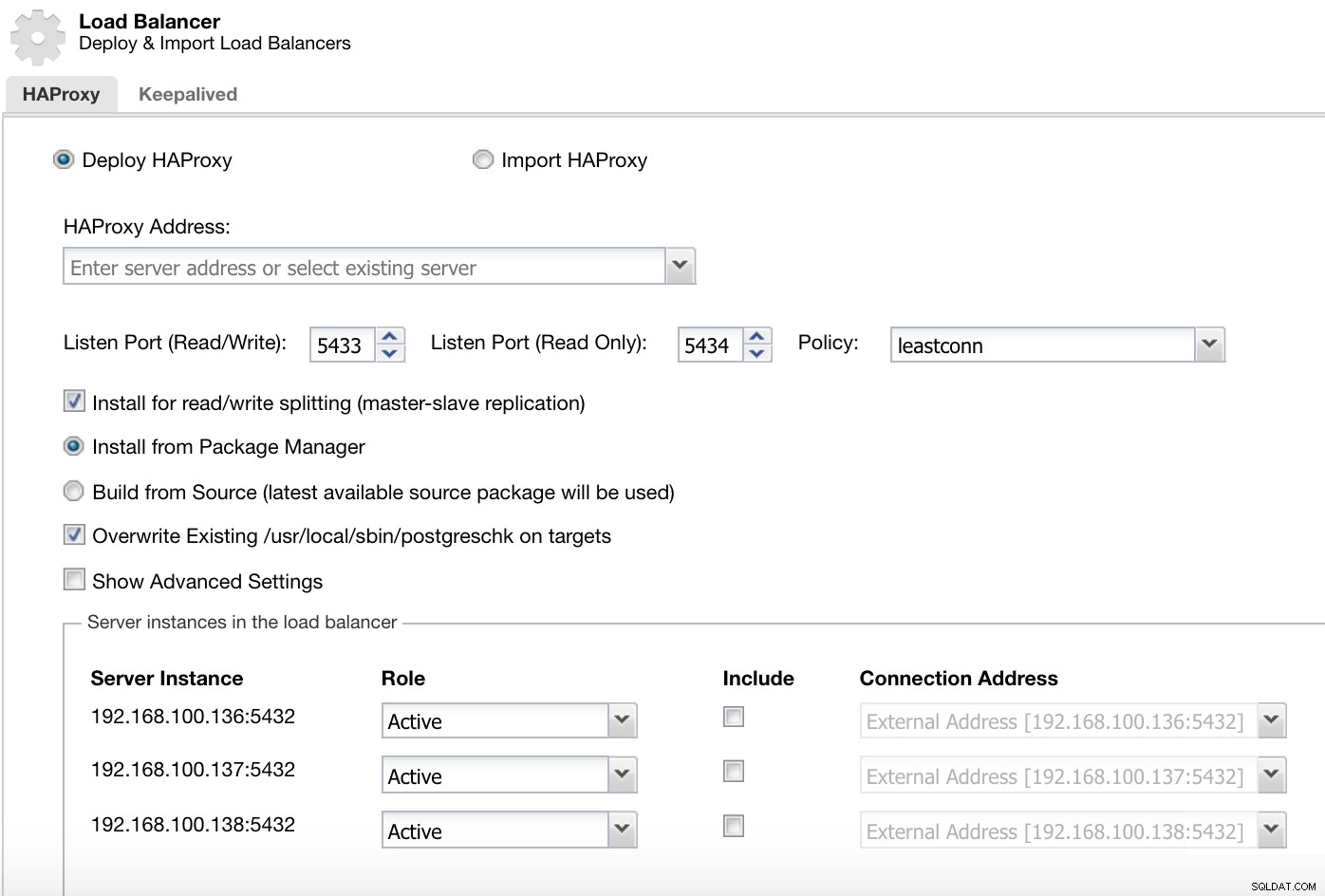 Informace o nasazení nástroje ClusterControl Load Balancer 1
Informace o nasazení nástroje ClusterControl Load Balancer 1 V našem portu pro čtení a zápis máme náš hlavní server jako online a zbytek našich uzlů jako offline a na portu pouze pro čtení máme hlavní i podřízené online.
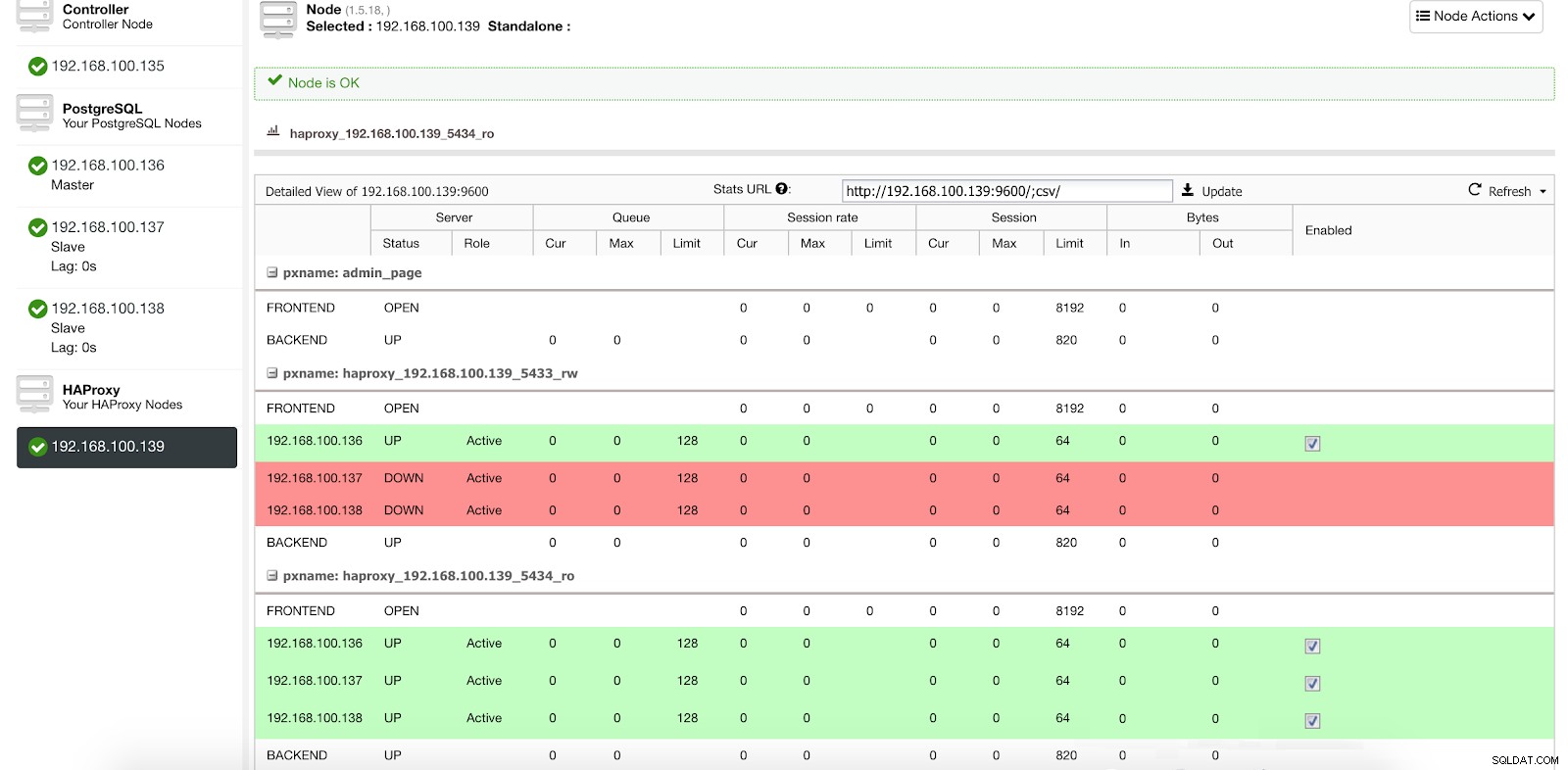 ClusterControl Load Balancer Stats 1
ClusterControl Load Balancer Stats 1 Když HAProxy zjistí, že některý z našich uzlů, ať už master nebo slave, není přístupný, automaticky ho označí jako offline a nebere ho v úvahu při odesílání provozu. Detekce se provádí pomocí skriptů Healthcheck, které jsou konfigurovány ClusterControl v době nasazení. Tyto kontrolují, zda jsou instance aktivní, zda procházejí obnovením nebo jsou pouze pro čtení.
Když ClusterControl povýší slave na master, naše HAProxy označí starý master jako offline (pro oba porty) a uvede povýšený uzel online (do portu pro čtení a zápis).
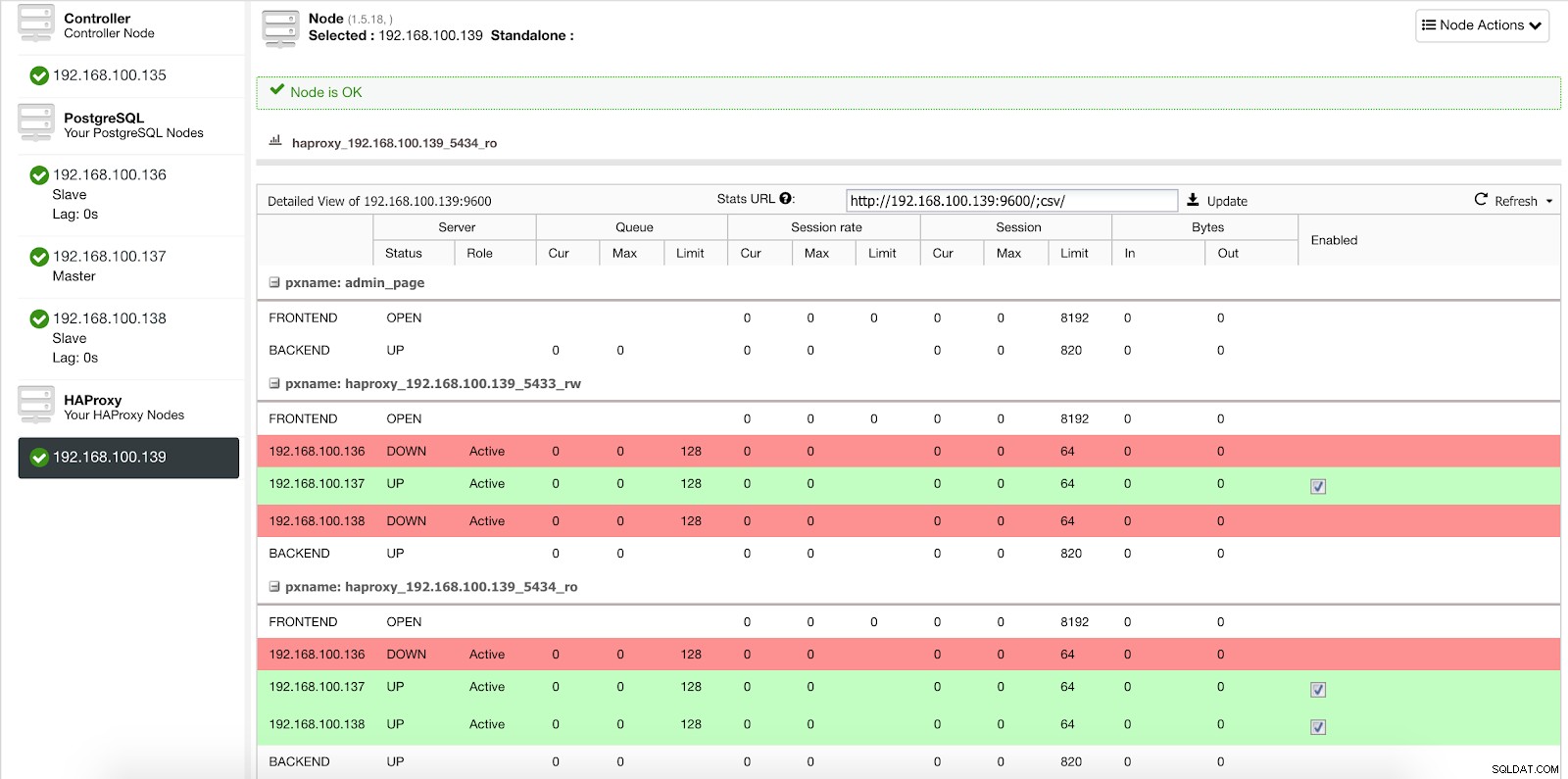 ClusterControl Load Balancer Stats 2
ClusterControl Load Balancer Stats 2 Tímto způsobem naše systémy nadále fungují normálně a bez našeho zásahu.
Jak nasadit HAProxy s ClusterControl
V našem příkladu jsme vytvořili prostředí s 1 hlavním a 2 podřízenými – viz snímek obrazovky Topology View v ClusterControl. Nyní přidáme náš HAProxy load balancer.
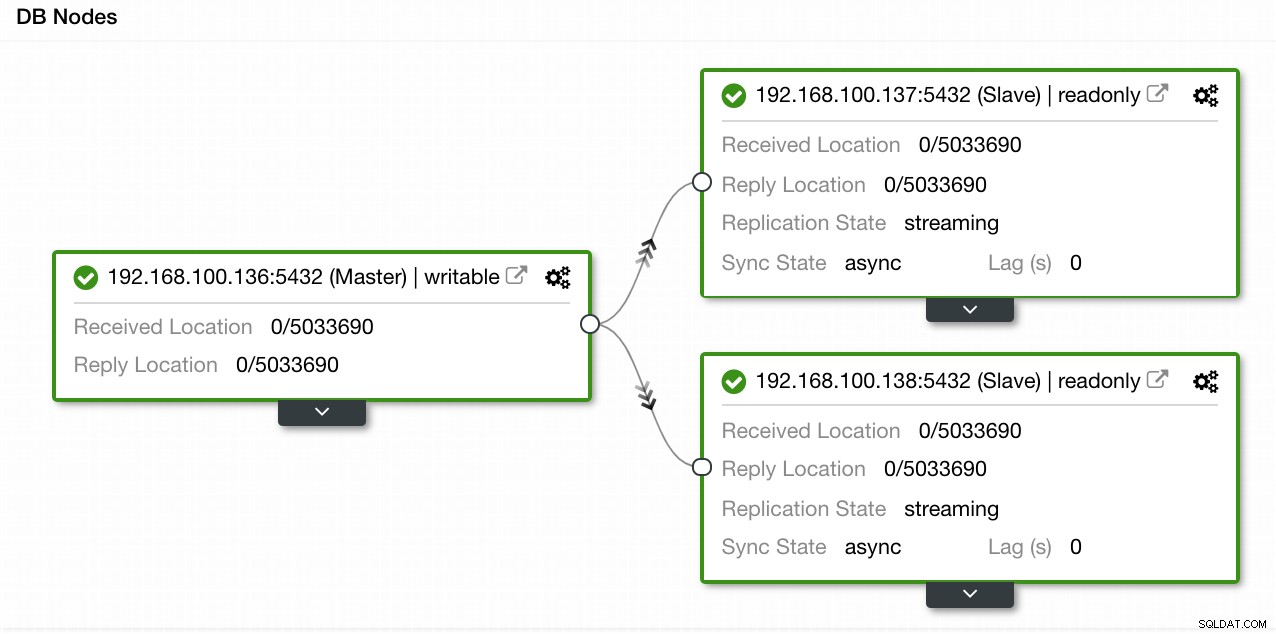 Zobrazení topologie ClusterControl 1
Zobrazení topologie ClusterControl 1 Pro tento úkol musíme přejít do ClusterControl -> Akce clusteru PostgreSQL -> Přidat Load Balancer
 Nabídka akcí clusteru ClusterControl
Nabídka akcí clusteru ClusterControl Zde musíme přidat informace, které ClusterControl použije k instalaci a konfiguraci našeho HAProxy load balanceru.
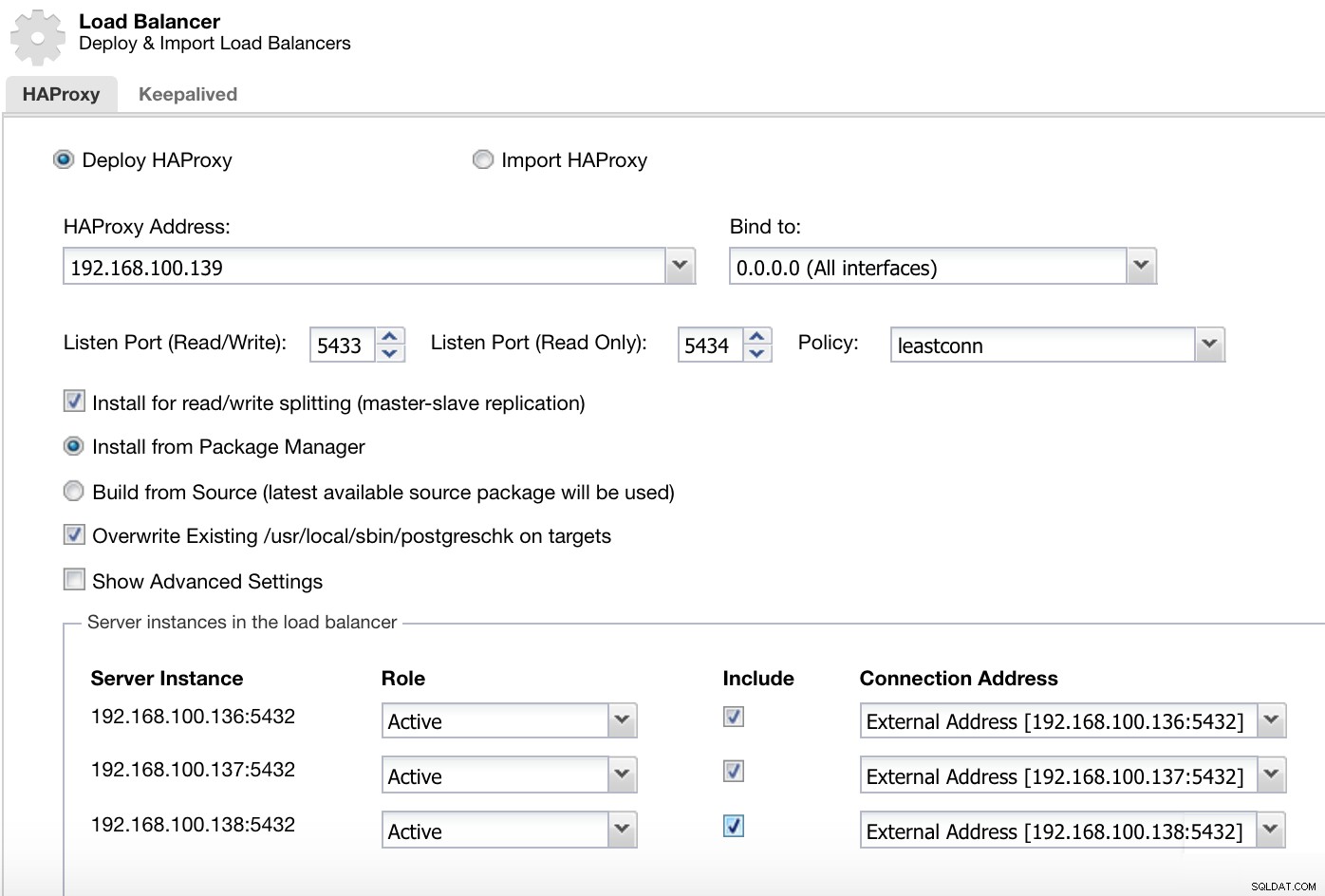 Informace o nasazení nástroje ClusterControl Load Balancer 2
Informace o nasazení nástroje ClusterControl Load Balancer 2 Informace, které musíme představit, jsou:
Akce:Nasazení nebo import.
HAProxy Address:IP adresa našeho HAProxy serveru.
Bind to:Interface nebo IP Address, kde bude HAProxy naslouchat.
Listen Port (Read/Write):Port pro režim čtení/zápis.
Listen Port (pouze pro čtení):Port pro režim pouze pro čtení.
Zásady:Může to být:
- leastconn:Server s nejnižším počtem připojení přijme připojení.
- roundrobin:Každý server se používá v tazích podle své váhy.
- zdroj:Zdrojová IP adresa je hašována a vydělena celkovou váhou běžících serverů, aby se určilo, který server obdrží požadavek.
Instalovat pro rozdělení čtení/zápisu:Pro replikaci master-slave.
Zdroj:Můžeme zvolit Instalovat ze správce balíčků nebo sestavit ze zdroje.
Přepište existující postgreschk na cílech.
A musíme vybrat, které servery chcete přidat do konfigurace HAProxy, a nějaké další informace, jako:
Role:Může být aktivní nebo záložní.
Zahrnout:Ano nebo Ne.
Informace o adrese připojení.
Můžeme také nakonfigurovat pokročilá nastavení, jako je uživatel správce, název backendu, časové limity a další.
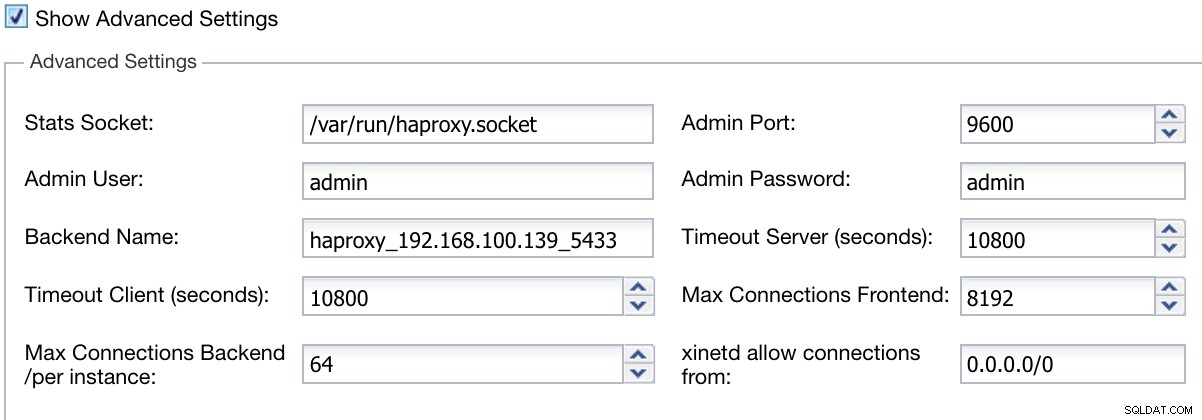 Pokročilé informace o nasazení nástroje ClusterControl Load Balancer
Pokročilé informace o nasazení nástroje ClusterControl Load Balancer Když dokončíte konfiguraci a potvrdíte nasazení, můžeme sledovat průběh v sekci Aktivita v uživatelském rozhraní ClusterControl.
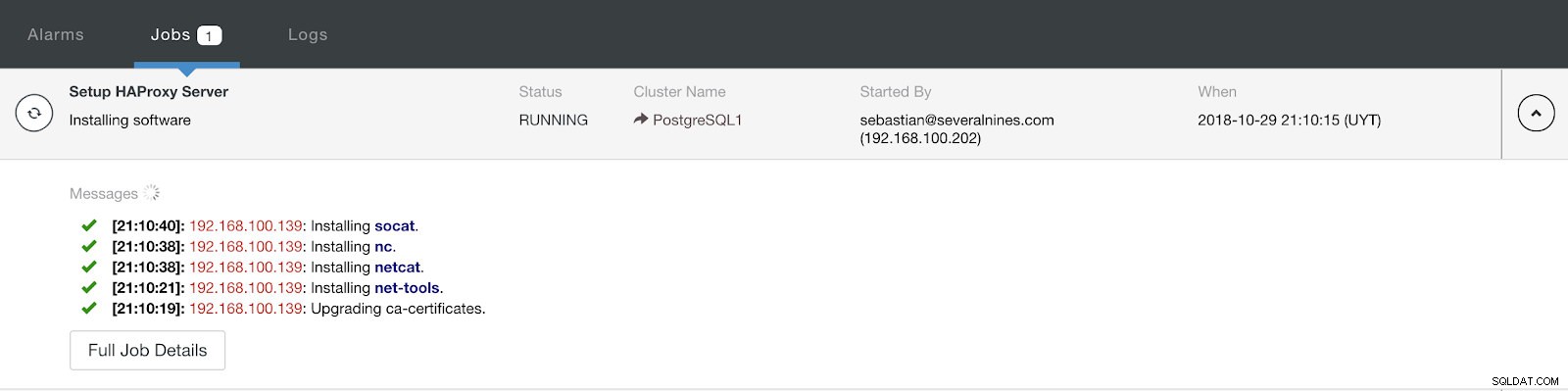 Činnost ClusterControl
Činnost ClusterControl Po dokončení bychom měli mít následující topologii:
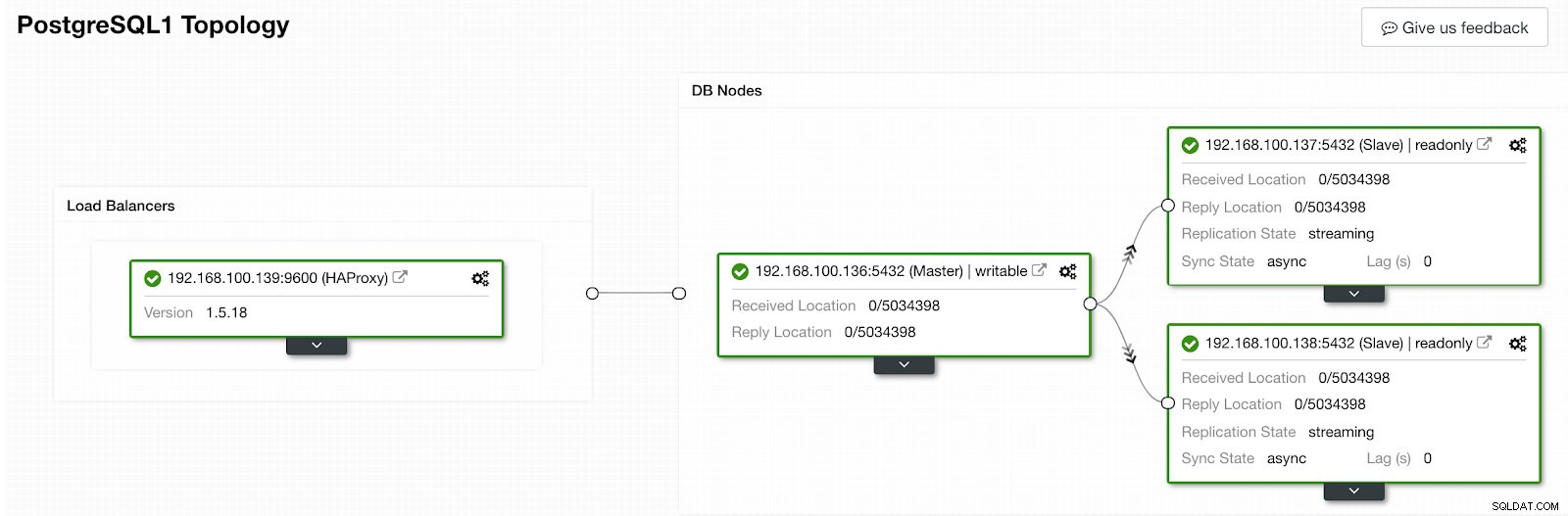 Zobrazení topologie ClusterControl 2
Zobrazení topologie ClusterControl 2 Můžeme vylepšit náš návrh HA přidáním nového uzlu HAProxy a konfigurací služby Keepalived mezi nimi. To vše dokáže ClusterControl. Pro více informací se můžete podívat na náš předchozí blog o PostgreSQL a HA.
Použití ClusterControl CLI k přidání HAProxy Load Balancer
Tento volitelný balíček známý také jako s9s-tools byl představen ve verzi ClusterControl 1.4.1, která obsahuje binární soubor nazvaný s9s. Jedná se o nástroj příkazového řádku pro interakci, řízení a správu vaší databázové infrastruktury pomocí ClusterControl. Projekt příkazového řádku s9s je open source a lze jej nalézt na GitHubu.
Počínaje verzí 1.4.1 instalační skript automaticky nainstaluje balíček (s9s-tools) do uzlu ClusterControl.
ClusterControl CLI otevírá nové dveře pro automatizaci clusteru, kde ji můžete snadno integrovat se stávajícími nástroji pro automatizaci nasazení, jako je Ansible, Puppet, Chef nebo Salt.
Podívejme se na příklad, jak vytvořit HAProxy load balancer s IP adresou 192.168.100.142 na clusteru ID 1:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.A pak můžeme zkontrolovat všechny naše uzly z příkazového řádku:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5Další informace o s9 a jejich používání najdete v oficiální dokumentaci nebo v tomto blogu na toto téma.
Závěr
V tomto blogu jsme se zabývali tím, jak nám HAProxy může pomoci řídit provoz přicházející z aplikace do naší databáze PostgreSQL. Zkontrolovali jsme, jak jej lze ručně nasadit a nakonfigurovat, a poté jsme viděli, jak jej lze automatizovat pomocí ClusterControl. Abyste se vyhnuli tomu, že se HAProxy stane jediným bodem selhání (SPOF), ujistěte se, že nasadíte alespoň dvě instance HAProxy a nad nimi implementujete něco jako Keepalived a Virtual IP.