 Tento článek je osmou částí série o tabulkových výrazech. Doposud jsem poskytoval pozadí tabulkových výrazů, pokrýval jak logické, tak optimalizační aspekty odvozených tabulek, logické aspekty CTE a některé optimalizační aspekty CTE. Tento měsíc pokračuji v pokrytí optimalizačních aspektů CTE, konkrétně se zabývám tím, jak se zachází s více referencemi CTE.
Tento článek je osmou částí série o tabulkových výrazech. Doposud jsem poskytoval pozadí tabulkových výrazů, pokrýval jak logické, tak optimalizační aspekty odvozených tabulek, logické aspekty CTE a některé optimalizační aspekty CTE. Tento měsíc pokračuji v pokrytí optimalizačních aspektů CTE, konkrétně se zabývám tím, jak se zachází s více referencemi CTE.
Ve svých příkladech budu nadále používat ukázkovou databázi TSQLV5. Skript, který vytváří a naplňuje TSQLV5, najdete zde a jeho ER diagram zde.
Vícenásobné odkazy a nedeterminismus
Minulý měsíc jsem vysvětlil a demonstroval, že CTE se oddělují, zatímco dočasné tabulky a proměnné tabulky ve skutečnosti uchovávají data. Poskytl jsem doporučení ohledně toho, kdy má smysl používat CTE a kdy má smysl používat dočasné objekty z hlediska výkonu dotazu. Ale je tu ještě jeden důležitý aspekt optimalizace CTE neboli fyzického zpracování, který je třeba vzít v úvahu nad rámec výkonu řešení – jak je zpracováno více odkazů na CTE z vnějšího dotazu. Je důležité si uvědomit, že pokud máte vnější dotaz s více odkazy na stejný CTE, každý z nich se zruší vnoření samostatně. Pokud máte ve vnitřním dotazu CTE nedeterministické výpočty, mohou mít tyto výpočty v různých odkazech různé výsledky.
Řekněme například, že vyvoláte funkci SYSDATETIME ve vnitřním dotazu CTE a vytvoříte výsledný sloupec nazvaný dt. Obecně platí, že za předpokladu, že se ve vstupech nezmění, je vestavěná funkce vyhodnocena jednou za dotaz a odkaz, bez ohledu na počet zahrnutých řádků. Pokud odkazujete na CTE pouze jednou z vnějšího dotazu, ale interagujete se sloupcem dt vícekrát, všechny odkazy mají představovat stejné vyhodnocení funkce a vracet stejné hodnoty. Pokud však ve vnějším dotazu odkazujete na CTE vícekrát, ať už jde o více poddotazů odkazujících na CTE nebo spojení mezi více instancemi stejného CTE (řekněme s aliasy C1 a C2), odkazy na C1.dt a C2.dt představuje různá hodnocení základního výrazu a může vést k různým hodnotám.
Chcete-li to demonstrovat, zvažte následující tři dávky:
-- Dávka 1 DECLARE @i JAKO INT =1; WHILE @@ROWCOUNT =1 SELECT @i +=1 WHERE SYSDATETIME() =SYSDATETIME(); PRINT @i;GO -- Dávka 2 DECLARE @i JAKO INT =1; WHILE @@ROWCOUNT =1 WITH C AS ( SELECT SYSDATETIME() AS dt ) SELECT @i +=1 FROM C WHERE dt =dt; PRINT @i;GO -- Dávka 3 DECLARE @i JAKO INT =1; WHILE @@ROWCOUNT =1 WITH C AS ( SELECT SYSDATETIME() AS dt ) SELECT @i +=1 WHERE (SELECT dt FROM C) =(SELECT dt FROM C); TISKNOUT @i;GO
Dokážete na základě toho, co jsem právě vysvětlil, určit, která z dávek má nekonečnou smyčku a která se v určitém okamžiku zastaví kvůli dvěma komparandům predikátu, které se vyhodnotí na různé hodnoty?
Pamatujte, že jsem řekl, že volání vestavěné nedeterministické funkce, jako je SYSDATETIME, je vyhodnoceno jednou za dotaz a odkaz. To znamená, že v Batch 1 máte dvě různá vyhodnocení a po dostatečném počtu iterací cyklu budou mít za následek různé hodnoty. Zkus to. Kolik iterací kód nahlásil?
Pokud jde o dávku 2, kód má dva odkazy na sloupec dt ze stejné instance CTE, což znamená, že oba představují stejné vyhodnocení funkce a měly by představovat stejnou hodnotu. V důsledku toho má dávka 2 nekonečnou smyčku. Spouštějte jej libovolně dlouho, ale nakonec budete muset spouštění kódu zastavit.
Pokud jde o dávku 3, vnější dotaz má dva různé poddotazy interagující s CTE C, z nichž každý představuje jinou instanci, která samostatně prochází procesem zrušení vnoření. Kód explicitně nepřiřazuje různé aliasy k různým instancím CTE, protože dva poddotazy se objevují v nezávislých rozsahech, ale pro snazší pochopení byste si mohli představit, že dva používají různé aliasy, jako je C1 v jednom poddotazu a C2 ve druhém. Je to tedy, jako by jeden poddotaz interagoval s C1.dt a druhý s C2.dt. Různé odkazy představují různá hodnocení základního výrazu, a proto mohou vést k různým hodnotám. Zkuste spustit kód a uvidíte, že se v určitém okamžiku zastaví. Kolik iterací trvalo, než se to zastavilo?
Je zajímavé pokusit se identifikovat případy, kdy máte v plánu provádění dotazu jedno nebo více vyhodnocení základního výrazu. Obrázek 1 obsahuje grafické plány provádění pro tři dávky (klikněte pro zvětšení).
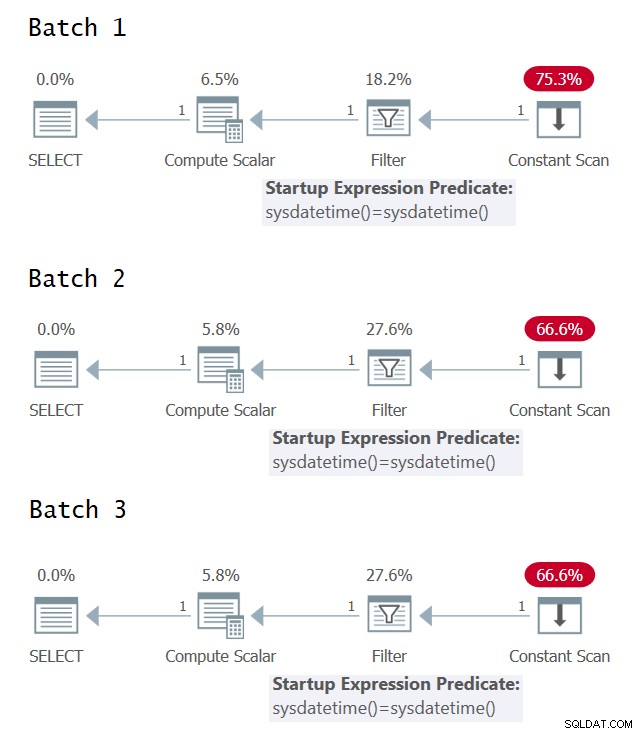 Obrázek 1:Grafické prováděcí plány pro dávku 1, dávku 2 a dávku 3
Obrázek 1:Grafické prováděcí plány pro dávku 1, dávku 2 a dávku 3
Bohužel žádná radost z grafických plánů provedení; všechny se zdají identické, i když sémanticky nemají tyto tři dávky stejný význam. Díky @CodeRecce a Forrestovi (@tsqladdict) se nám jako komunitě podařilo přijít na kloub pomocí jiných prostředků.
Jak zjistil @CodeRecce, plány XML obsahují odpověď. Zde jsou příslušné části XML pro tři dávky:
−− Dávka 1
…
…
−− Dávka 2
…
…
…
…
V plánu XML pro dávku 1 můžete jasně vidět, že predikát filtru porovnává výsledky dvou samostatných přímých vyvolání vnitřní funkce SYSDATETIME.
V plánu XML pro dávku 2 predikát filtru porovnává konstantní výraz ConstExpr1002 představující jedno vyvolání funkce SYSDATETIME se sebou samým.
V plánu XML pro dávku 3 predikát filtru porovnává dva různé konstantní výrazy nazvané ConstExpr1005 a ConstExpr1006, z nichž každý představuje samostatné vyvolání funkce SYSDATETIME.
Jako další možnost Forrest (@tsqladdict) navrhl použít příznak trasování 8605, který ukazuje počáteční reprezentaci stromu dotazů vytvořenou SQL Serverem, po povolení příznaku trasování 3604, který způsobí, že výstup TF 8605 bude směrován na klienta SSMS. K povolení obou příznaků trasování použijte následující kód:
Dále spustíte kód, pro který chcete získat strom dotazů. Zde jsou příslušné části výstupu, které jsem získal z TF 8605 pro tři dávky:
LogOp_Project COL:Expr1000
LogOp_Select
LogOp_ConstTableGet (1) [prázdné]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Nevlastněno,Value=1)
−− Dávka 2
LogOp_Project COL:Expr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [prázdné]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Expr1000
ScaOp_Identifier COL:Expr1000
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Nevlastněno,Value=1)
−− Dávka 3
LogOp_Project COL:Expr1004
LogOp_Select
LogOp_ConstTableGet (1) [prázdné]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Expr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [prázdné]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Identifier COL:Expr1000
ScaOp_Subquery COL:Expr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [prázdné]
AncOp_PrjList
AncOp_PrjEl COL:Expr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1003
ScaOp_Identifier COL:Expr1002
AncOp_PrjList
AncOp_PrjEl COL:Expr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Nevlastněno,Hodnota=1)
V dávce 1 můžete vidět srovnání mezi výsledky dvou samostatných vyhodnocení vnitřní funkce SYSDATETIME.
V Batch 2 vidíte jedno vyhodnocení funkce, jehož výsledkem je sloupec nazvaný Expr1000, a poté porovnání mezi tímto sloupcem a ním samotným.
V dávce 3 uvidíte dvě samostatná vyhodnocení funkce. Jeden ve sloupci nazvaném Expr1000 (později promítnutý sloupcem poddotazu s názvem Expr1001). Další ve sloupci s názvem Expr1002 (později promítnutý sloupcem poddotazu s názvem Expr1003). Pak máte srovnání mezi Expr1001 a Expr1003.
Takže s trochu větším překračováním toho, co odhaluje grafický plán provádění, můžete skutečně zjistit, kdy se základní výraz vyhodnotí pouze jednou nebo vícekrát. Nyní, když rozumíte různým případům, můžete vyvíjet svá řešení na základě požadovaného chování, o které usilujete.
Existuje další třída výpočtů, které vás mohou dostat do problémů při použití v řešeních s více odkazy na stejný CTE. To jsou funkce okna, které se spoléhají na nedeterministické řazení. Vezměte si jako příklad funkci okna ROW_NUMBER. Při použití s částečným objednáním (řazení podle prvků, které řádek jednoznačně neidentifikují), každé vyhodnocení základního dotazu může vést k jinému přiřazení čísel řádků, i když se podkladová data nezměnila. U více referencí CTE si pamatujte, že každá se oddělí samostatně a můžete získat různé sady výsledků. V závislosti na tom, co dělá vnější dotaz s každým odkazem, např. se kterými sloupci z každé reference interaguje a jak, může optimalizátor rozhodnout o přístupu k datům pro každou z instancí pomocí různých indexů s různými požadavky na řazení.
Zvažte následující kód jako příklad:
Může tento dotaz někdy vrátit neprázdnou sadu výsledků? Možná je vaše první reakce, že to nejde. Ale přemýšlejte o tom, co jsem právě vysvětlil, trochu pečlivěji a uvědomíte si, že alespoň teoreticky, díky dvěma samostatným procesům rozkládání CTE, které zde proběhnou – jeden z C1 a druhý z C2 – je to možné. Jedna věc je však teoretizovat, že se něco může stát, a druhá věc je demonstrovat to. Když jsem například spustil tento kód, aniž bych vytvořil nové indexy, stále jsem dostával prázdnou sadu výsledků:
Pro tento dotaz mám plán zobrazený na obrázku 23.
Zde je zajímavé poznamenat, že optimalizátor se rozhodl použít různé indexy ke zpracování různých referencí CTE, protože to považoval za optimální. Koneckonců, každý odkaz ve vnějším dotazu se týká jiné podmnožiny sloupců CTE. Jeden odkaz vedl k uspořádanému dopřednému skenování indexu idx_nc_orderedate a druhý k neuspořádanému skenování seskupeného indexu, po kterém následovala operace řazení vzestupně podle data objednávky. I když je index idx_nc_orderedate explicitně definován pouze ve sloupci orderdate jako klíč, v praxi je definován na (orderdate, orderid) jako jeho klíče, protože orderid je seskupený indexový klíč a je zahrnut jako poslední klíč ve všech neklastrovaných indexech. Uspořádané skenování indexu tedy ve skutečnosti vydává řádky seřazené podle orderdate, orderid. Pokud jde o neuspořádané skenování seskupeného indexu, na úrovni úložného jádra jsou data skenována v pořadí klíčů indexu (na základě orderid), aby byla splněna minimální očekávání konzistence výchozí úrovně izolace čtení potvrzené. Operátor Sort tedy zpracuje data seřazená podle orderid, seřadí řádky podle orderdate a v praxi to skončí tak, že vygeneruje řádky seřazené podle orderdate, orderid.
Teoreticky opět neexistuje žádná záruka, že tyto dva odkazy budou vždy představovat stejnou sadu výsledků, i když se základní data nezmění. Jednoduchým způsobem, jak to demonstrovat, je uspořádat dva různé optimální indexy pro dvě reference, ale jeden seřadit data podle orderdate ASC, orderid ASC a druhý seřadit data podle orderdate DESC, orderid ASC (nebo přesně naopak). První index již máme zaveden. Zde je kód pro jeho vytvoření:
Po vytvoření indexu spusťte kód podruhé:
Při spuštění tohoto kódu po vytvoření nového indexu jsem dostal následující výstup:
Jejda.
Prozkoumejte plán dotazů pro toto provedení, jak je znázorněno na obrázku 3:
Všimněte si, že horní větev plánu skenuje index idx_nc_orderdate uspořádaným dopředným způsobem, což způsobí, že operátor Sequence Project, který počítá čísla řádků, v praxi zpracovává data uspořádaná podle orderdate ASC, orderid ASC. Spodní větev plánu skenuje nový index idx_nc_odD_oid_I_sc seřazeným zpětně, což způsobí, že operátor sekvenčního projektu v praxi zpracovává data seřazená podle orderdate ASC, orderid DESC. To má za následek odlišné uspořádání čísel řádků pro dvě reference CTE, kdykoli existuje více než jeden výskyt stejné hodnoty orderdate. Následně dotaz vygeneruje neprázdnou sadu výsledků.
Chcete-li se takovým chybám vyhnout, jednou z možností je ponechat výsledek vnitřního dotazu v dočasném objektu, jako je dočasná tabulka nebo proměnná tabulky. Pokud se však nacházíte v situaci, kdy byste se raději drželi používání CTE, jednoduchým řešením je použití celkové objednávky ve funkci okna přidáním nerozhodného výsledku. Jinými slovy, ujistěte se, že objednáváte pomocí kombinace výrazů, které jednoznačně identifikují řádek. V našem případě můžete jednoduše přidat orderid explicitně jako nerozhodný výsledek, například takto:
Získáte prázdnou sadu výsledků podle očekávání:
Bez přidávání dalších indexů získáte plán zobrazený na obrázku 4:
Horní větev plánu je stejná jako u předchozího plánu znázorněného na obrázku 3. Spodní větev je však trochu jiná. Nový index vytvořený dříve není pro nový dotaz ve skutečnosti ideální v tom smyslu, že nemá data uspořádaná, jak potřebuje funkce ROW_NUMBER (orderdate, orderid). Je to stále nejužší krycí index, který mohl optimalizátor najít pro příslušnou referenci CTE, takže je vybrán; je však naskenován způsobem Ordered:False. Explicitní operátor Sort pak seřadí data podle data objednávky v pořadí podle potřeb výpočtu ROW_NUMBER. Samozřejmě můžete změnit definici indexu tak, aby datum objednávky i ID objednávky používaly stejný směr a tímto způsobem bude z plánu vyloučeno explicitní řazení. Hlavním bodem však je, že používáním úplného řazení se vyhnete problémům kvůli této specifické chybě.
Až budete hotovi, spusťte následující kód pro vyčištění:
Je důležité pochopit, že více odkazů na stejný CTE z vnějšího dotazu vede k samostatným vyhodnocením vnitřního dotazu CTE. Buďte obzvláště opatrní u nedeterministických výpočtů, protože různá vyhodnocení mohou vést k různým hodnotám.
Když používáte funkce okna, jako je ROW_NUMBER a agregace s rámcem, ujistěte se, že používáte celkové pořadí, abyste se vyhnuli získání různých výsledků pro stejný řádek v různých referencích CTE.
−− Dávka 3DBCC TRACEON(3604); -- přímý výstup na clientGO DBCC TRACEON(8605); -- zobrazit počáteční strom dotazuGO
*** Převedený strom:***
*** Převedený strom:***
*** Převedený strom:***Funkce okna s nedeterministickým pořadím
POUŽÍVEJTE TSQLV5; WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2. rownumWHERE C1.orderid <> C2.orderid;
orderid shipcountry orderid----------- --------------- -----------(0 dotčených řádků)
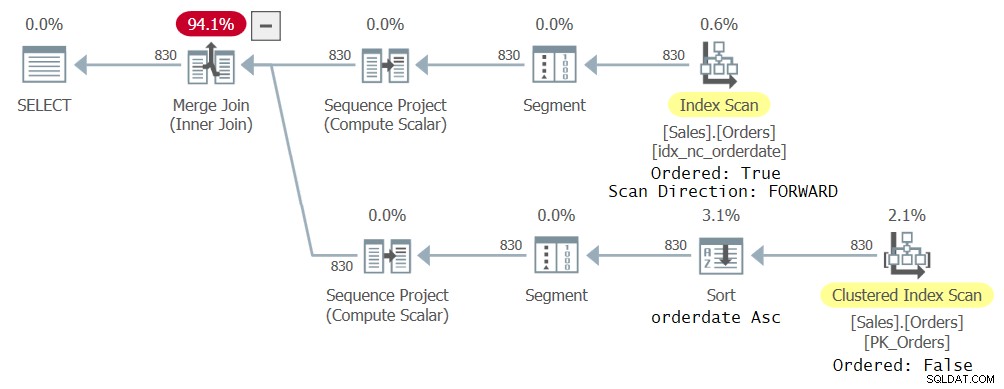 Obrázek 2:První plán dotazu se dvěma referencemi CTE
Obrázek 2:První plán dotazu se dvěma referencemi CTE CREATE INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);
WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2.rownumWHERE C1.orderid <> C2.orderid;
orderid shipcountry orderid----------- --------------- -----------10251 Francie 1025010250 Brazílie 1025110261 Brazílie 1026010260 Německo 1026110271 USA 10270...11070 Německo 1107311077 USA 1107411076 Francie 1107511075 Švýcarsko 1107611074 Dánsko 11077 (dotčených 546 řádků)
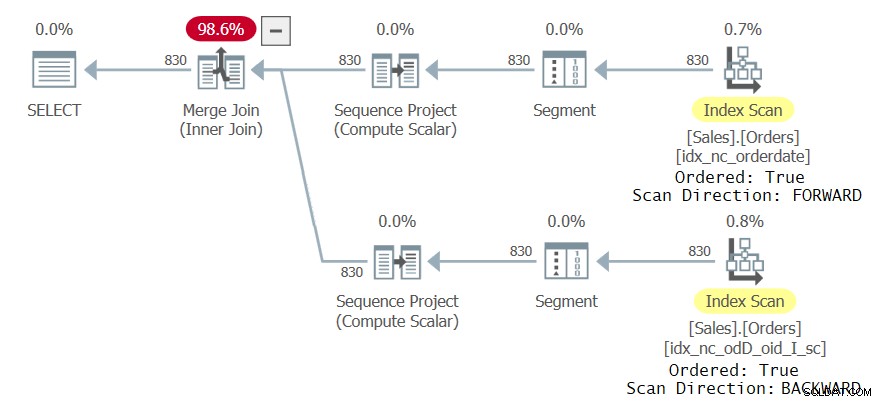 Obrázek 3:Druhý plán pro dotaz se dvěma referencemi CTE
Obrázek 3:Druhý plán pro dotaz se dvěma referencemi CTE WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1 .rownum =C2.rownumWHERE C1.orderid <> C2.orderid;
orderid shipcountry orderid----------- --------------- -----------(0 dotčených řádků)
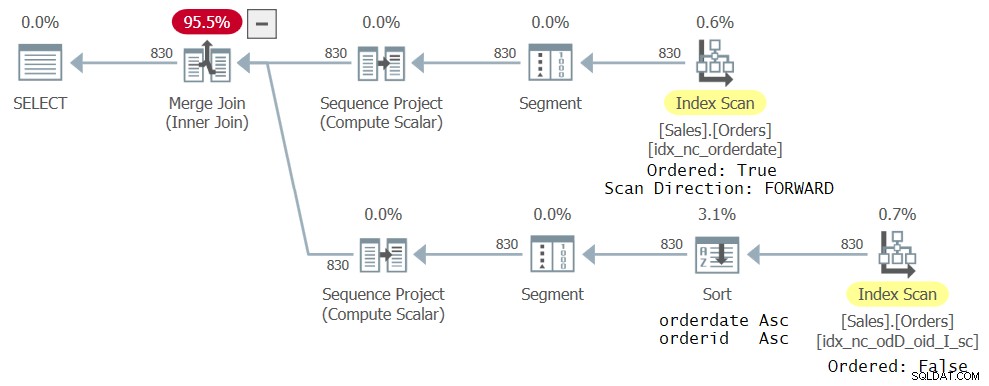 Obrázek 4:Třetí plán pro dotaz se dvěma referencemi CTE
Obrázek 4:Třetí plán pro dotaz se dvěma referencemi CTE PUSTIT INDEX, POKUD EXISTUJE idx_nc_odD_oid_I_sc ON Sales.Orders;
Závěr