Ahoj,
Index se v databázi SQL Server používá v prostředích, která vyžadují nejvyšší výkon, rychlost a úsporu paměti.
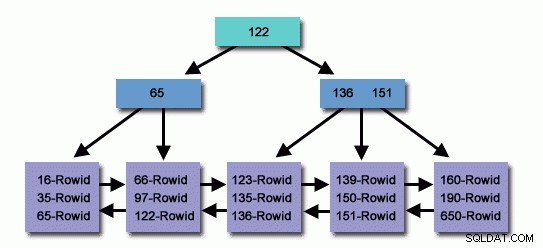
V tabulce s miliony nebo miliardami záznamů můžeme pomocí indexu číst méně záznamů a méně vyhledávat, abychom našli související záznam.
Přesně vytvořený index, miliony záznamů v databázi, které jsme prohledali ve velmi krátké době, abychom přinesli záznam pohodlí volajícího, a zároveň méně četl záznam dosažením cílového záznamu, efektivně využíváme prostředky operačního systému.
Měli byste vytvořit index pro většinou jen pro čtení dotazy na tabulku. Pokud jsou operace Delete,update více než dotazy pouze pro čtení, neměli byste vytvářet index této tabulky.
Na chybějící doporučení indexu SQL Serveru se můžete podívat pomocí následujícího skriptu. Můžete vytvořit chybějící index, ale měli byste tyto indexy sledovat. Pokud nejsou užitečné, měli byste je zahodit.
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;