Sniffování parametrů
Parametrizace dotazu podporuje opětovné použití plánů provádění uložených v mezipaměti, čímž se vyhne zbytečným kompilacím a sníží počet ad-hoc dotazů v mezipaměti plánu.
To jsou všechno dobré věci, za předpokladu parametrizovaný dotaz by měl skutečně používat stejný plán provádění v mezipaměti pro různé hodnoty parametrů. Plán provádění, který je účinný pro jednu hodnotu parametru, nemusí ne být dobrou volbou pro další možné hodnoty parametrů.
Když je sniffování parametrů povoleno (výchozí nastavení), SQL Server zvolí plán provádění na základě konkrétních hodnot parametrů, které existují v době kompilace. Implicitním předpokladem je, že parametrizované příkazy jsou nejčastěji prováděny s nejběžnějšími hodnotami parametrů. To zní dostatečně rozumně (dokonce zjevně) a skutečně to často funguje dobře.
Problém může nastat, když dojde k automatické rekompilaci plánu uloženého v mezipaměti. Rekompilace může být spuštěna z nejrůznějších důvodů, například proto, že index používaný plánem uloženým v mezipaměti byl zrušen (správnost rekompilace) nebo protože se statistické informace změnily (optimalita). překompilovat).
Bez ohledu na přesnou příčinu při rekompilaci plánu existuje možnost, že atypické hodnota je předávána jako parametr v době generování nového plánu. To může mít za následek nový plán uložený v mezipaměti (založený na sniffované atypické hodnotě parametru), který není vhodný pro většinu provádění, pro která bude znovu použit.
Není snadné předvídat, kdy dojde k rekompilaci konkrétního prováděcího plánu (například proto, že se dostatečně změnily statistiky), což má za následek situaci, kdy může být kvalitní opakovaně použitelný plán náhle nahrazen zcela jiným plánem optimalizovaným pro atypické hodnoty parametrů.
Jeden takový scénář nastane, když je atypická hodnota vysoce selektivní, což vede k plánu optimalizovanému pro malý počet řádků. Takové plány budou často používat provádění s jedním vláknem, spojení vnořených smyček a vyhledávání. Pokud je tento plán znovu použit pro různé hodnoty parametrů, které generují mnohem větší počet řádků, mohou nastat vážné problémy s výkonem.
Deaktivace sledování parametrů
Sniffování parametrů lze zakázat pomocí dokumentovaného příznaku trasování 4136. Příznak trasování je podporován také pro na dotaz použít prostřednictvím QUERYTRACEON nápověda k dotazu. Obě platí od SQL Server 2005 Service Pack 4 a dále (a o něco dříve, pokud použijete kumulativní aktualizace Service Pack 3).
Počínaje SQL Serverem 2016 lze sniffování parametrů také zakázat na úrovni databáze pomocí PARAMETER_SNIFFING argument pro ALTER DATABASE SCOPED CONFIGURATION .
Když je sniffování parametrů zakázáno, SQL Server používá průměrnou distribuci statistiky pro výběr plánu provádění.
To také zní jako rozumný přístup (a může pomoci vyhnout se situaci, kdy je plán optimalizován pro neobvykle selektivní hodnotu parametru), ale ani to není dokonalá strategie:Plán optimalizovaný pro „průměrnou“ hodnotu by mohl skončit jako vážně suboptimální pro běžně používané hodnoty parametrů.
Zvažte plán provádění, který obsahuje operátory náročné na paměť, jako jsou sorty a hash. Protože paměť je rezervována před zahájením provádění dotazu, parametrizovaný plán založený na průměrných distribučních hodnotách se může přenést do tempdb pro běžné hodnoty parametrů, které produkují více dat, než optimalizátor očekával.
Rezervace paměti se během provádění dotazu obvykle nemohou zvětšit, bez ohledu na to, kolik volné paměti může mít server. Určité aplikace těží z vypnutí sniffování parametrů (příklad viz tento archivní příspěvek týmu Dynamics AX Performance Team).
U většiny úloh je úplné zakázání sniffování parametrů špatným řešením a může to být i katastrofa. Sniffování parametrů je heuristická optimalizace:Na většině systémů většinou funguje lépe než použití průměrných hodnot.
Nápovědy k dotazu
SQL Server poskytuje řadu tipů pro dotazy a další možnosti pro vyladění chování sniffování parametrů:
- Položka
OPTIMIZE FOR (@parameter = value)query hint vytvoří znovu použitelný plán na základě konkrétní hodnoty. OPTIMIZE FOR (@parameter UNKNOWN)používá statistiky průměrné distribuce pro konkrétní parametr.OPTIMIZE FOR UNKNOWNpoužívá průměrné rozdělení pro všechny parametry (stejný účinek jako příznak trasování 4136).- Položka
WITH RECOMPILEuložená procedura zkompiluje nový plán procedur pro každé provedení. - Položka
OPTION (RECOMPILE)query hint sestaví nový plán pro individuální výpis.
Stará technika „skrývání parametrů“ (přiřazení parametrů procedury lokálním proměnným a místo toho odkazování na proměnné) má stejný účinek jako zadání OPTIMIZE FOR UNKNOWN . Může být užitečné v instancích starších než SQL Server 2008 (OPTIMIZE FOR hint byl nový pro rok 2008).
Dalo by se namítnout, že každý parametrizovaný příkaz by měl být zkontrolován z hlediska citlivosti na hodnoty parametrů a buď ponechán samostatně (pokud výchozí chování funguje dobře), nebo explicitně naznačen pomocí jedné z výše uvedených možností.
To se v praxi provádí jen zřídka, částečně proto, že provádění komplexní analýzy pro všechny možné hodnoty parametrů může být časově náročné a vyžaduje poměrně pokročilé dovednosti.
Většinou se žádná taková analýza neprovádí a problémy s citlivostí parametrů se řeší jako a když se vyskytují ve výrobě.
Tento nedostatek předchozí analýzy je pravděpodobně jedním z hlavních důvodů, proč má sniffování parametrů špatnou pověst. Vyplatí se uvědomit si potenciální problémy a provést alespoň rychlou analýzu příkazů, které pravděpodobně způsobí problémy s výkonem při rekompilaci s atypickou hodnotou parametru.
Co je to parametr?
Někdo by řekl, že SELECT příkaz odkazující na lokální proměnnou je „parametrizovaný příkaz“ druhu, ale to není definice, kterou SQL Server používá.
Přiměřený náznak toho, že příkaz používá parametry, lze nalézt ve vlastnostech plánu (viz Parametry v Průzkumníku Sentry One Plan. Nebo klikněte na kořenový uzel plánu dotazů v SSMS a otevřete Vlastnosti a rozbalte Seznam parametrů uzel):
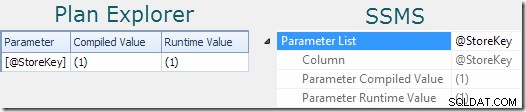
„Zkompilovaná hodnota“ zobrazuje hodnotu parametru použitého ke kompilaci plánu uloženého v mezipaměti. „Hodnota za běhu“ zobrazuje hodnotu parametru pro konkrétní provedení zachycené v plánu.
Každá z těchto vlastností může být za různých okolností prázdná nebo chybí. Pokud dotaz není parametrizován, budou jednoduše všechny vlastnosti chybět.
Protože na serveru SQL Server není nikdy nic jednoduché, existují situace, kdy lze seznam parametrů naplnit, ale příkaz stále není parametrizován. K tomu může dojít, když se SQL Server pokusí o jednoduchou parametrizaci (probráno později), ale rozhodne, že tento pokus je „nebezpečný“. V takovém případě budou přítomny značky parametrů, ale plán provádění není ve skutečnosti parametrizován.
Sniffing není jen pro uložené procedury
Sniffování parametrů také nastane, když je dávka explicitně parametrizována pro opětovné použití pomocí sp_executesql .
Například:
EXECUTE sys.sp_executesql
N'
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
',
N'@NameLike nvarchar(50)',
@NameLike = N'K%';
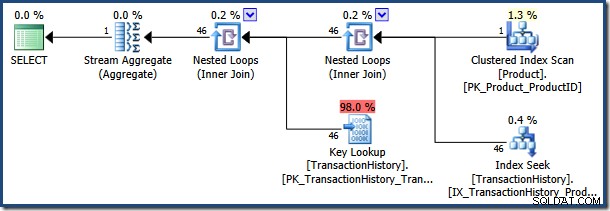
Optimalizátor vybere plán provádění na základě načtené hodnoty @NameLike parametr. Odhaduje se, že hodnota parametru „K%“ odpovídá velmi malému počtu řádků v Product tak optimalizátor zvolí vnořené smyčky spojení a strategii vyhledávání klíčů:

Opětovné provedení příkazu s hodnotou parametru „[H-R] %“ (která bude odpovídat mnoha dalším řádkům) znovu použije parametrizovaný plán uložený v mezipaměti:
EXECUTE sys.sp_executesql
N'
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
',
N'@NameLike nvarchar(50)',
@NameLike = N'[H-R]%';
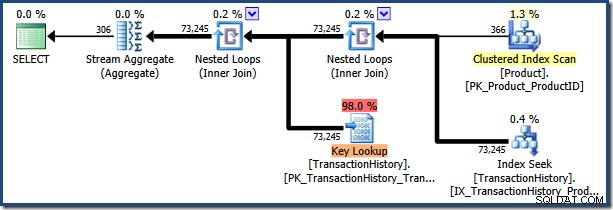

AdventureWorks ukázková databáze je příliš malá na to, aby z toho byla výkonová katastrofa, ale tento plán rozhodně není optimální pro hodnotu druhého parametru.
Plán, který by optimalizátor zvolil, můžeme vidět vymazáním mezipaměti plánu a opětovným provedením druhého dotazu:
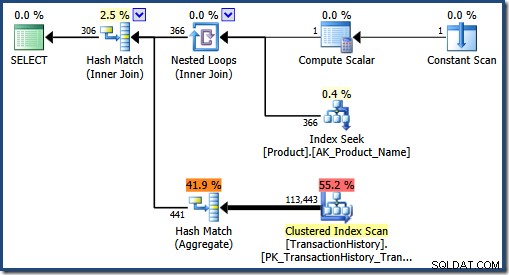

Při očekávaném větším počtu shod optimalizátor určí, že spojení hash a agregace hash jsou lepší strategie.
Funkce T-SQL
Sniffování parametrů se vyskytuje i u funkcí T-SQL, i když způsob, jakým jsou generovány prováděcí plány, to může ztížit.
Existují dobré důvody, proč se obecně vyhýbat skalárním a vícepříkazovým funkcím T-SQL, takže pouze pro vzdělávací účely uvádíme verzi našeho testovacího dotazu s vícepříkazovými funkcemi T-SQL s tabulkovou hodnotou:
CREATE FUNCTION dbo.F
(@NameLike nvarchar(50))
RETURNS @Result TABLE
(
ProductID integer NOT NULL PRIMARY KEY,
Name nvarchar(50) NOT NULL,
TotalQty integer NOT NULL
)
WITH SCHEMABINDING
AS
BEGIN
INSERT @Result
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
RETURN;
END; Následující dotaz používá funkci k zobrazení informací pro názvy produktů začínající na ‚K‘:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'K%') AS Result; Zobrazení parametru sniffing pomocí vestavěné funkce je obtížnější, protože SQL Server nevrací samostatný plán dotazů po spuštění (skutečný) pro každé vyvolání funkce. Funkce by mohla být volána mnohokrát v rámci jednoho příkazu a uživatelé by nebyli ohromeni, kdyby se SSMS pokusilo zobrazit milion plánů volání funkcí pro jeden dotaz.
V důsledku tohoto rozhodnutí o návrhu není skutečný plán vrácený serverem SQL Server pro náš testovací dotaz příliš užitečný:
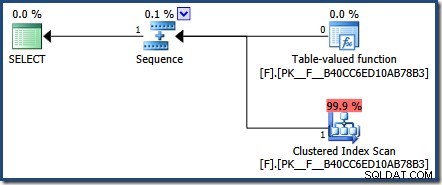
Přesto existují způsoby, jak vidět sniffování parametrů v akci s vestavěnými funkcemi. Metodou, kterou jsem se zde rozhodl použít, je kontrola mezipaměti plánu:
SELECT
DEQS.plan_generation_num,
DEQS.execution_count,
DEQS.last_logical_reads,
DEQS.last_elapsed_time,
DEQS.last_rows,
DEQP.query_plan
FROM sys.dm_exec_query_stats AS DEQS
CROSS APPLY sys.dm_exec_sql_text(DEQS.plan_handle) AS DEST
CROSS APPLY sys.dm_exec_query_plan(DEQS.plan_handle) AS DEQP
WHERE
DEST.objectid = OBJECT_ID(N'dbo.F', N'TF');
Tento výsledek ukazuje, že plán funkcí byl proveden jednou, za cenu 201 logických čtení s uplynulým časem 2891 mikrosekund, a poslední provedení vrátilo jeden řádek. Vrácená reprezentace plánu XML ukazuje, že hodnota parametru byla přičichl:
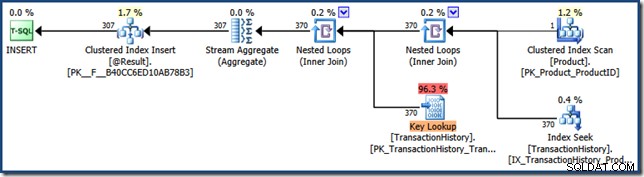

Nyní spusťte příkaz znovu s jiným parametrem:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'[H-R]%') AS Result; Plán po spuštění ukazuje, že funkce vrátila 306 řádků:
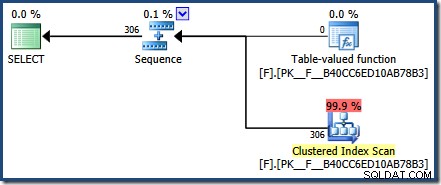
Dotaz mezipaměti plánu ukazuje, že plán provádění funkce v mezipaměti byl znovu použit (execution_count =2):

Ukazuje také mnohem vyšší počet logických čtení a delší uplynulý čas ve srovnání s předchozím spuštěním. To je v souladu s opětovným použitím vnořených smyček a plánu vyhledávání, ale pro úplnou jistotu lze plán funkcí po spuštění zachytit pomocí Extended Events nebo SQL Server Profiler nástroj:
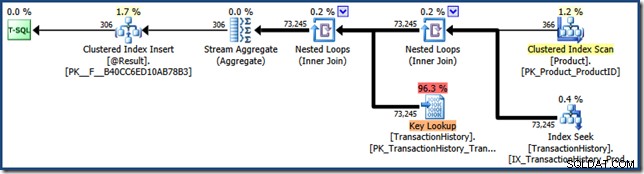

Protože funkce sniffování parametrů platí, mohou tyto moduly trpět stejnými neočekávanými změnami výkonu, které jsou běžně spojeny s uloženými procedurami.
Například při prvním odkazu na funkci může být plán uložen do mezipaměti, který nepoužívá paralelismus. Následná spuštění s hodnotami parametrů, kterým by prospěl paralelismus (ale znovu použily sériový plán uložený v mezipaměti), budou vykazovat neočekávaně slabý výkon.
Tento problém může být obtížné identifikovat, protože SQL Server nevrací samostatné plány po spuštění pro volání funkcí, jak jsme viděli. Pomocí Rozšířených událostí nebo Profiler rutinní zachycení plánů po provedení může být extrémně náročné na zdroje, takže často dává smysl používat tuto techniku velmi cíleným způsobem. Problémy s laděním problémů s citlivostí parametrů funkce znamenají, že je ještě užitečnější provést analýzu (a defenzivní kódování) předtím, než se funkce dostane do produkce.
Sniffování parametrů funguje přesně stejným způsobem se skalárními uživatelem definovanými funkcemi T-SQL (pokud není in-line, na SQL Server 2019 a novější). Funkce s hodnotou tabulky v řádcích negenerují samostatný plán provádění pro každé vyvolání, protože (jak název říká) jsou vloženy do volajícího dotazu před kompilací.
Pozor na vyčmuchané hodnoty NULL
Vymažte mezipaměť plánu a požádejte o odhad (před spuštěním) plán pro testovací dotaz:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'K%') AS Result; Uvidíte dva plány provádění, z nichž druhý je pro volání funkce:
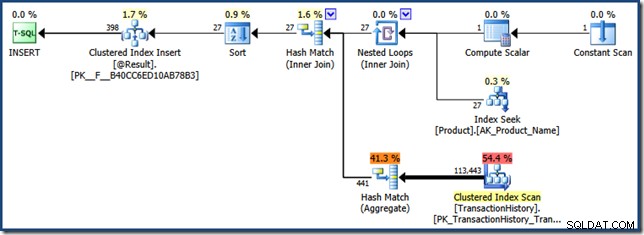
Omezení sniffování parametrů pomocí zabudovaných funkcí v odhadovaných plánech znamená, že hodnota parametru je sniffována jako NULLs (nikoli „K %“):

Ve verzích SQL Server před rokem 2012 tento plán (optimalizovaný pro NULLs parametr) je uložen do mezipaměti pro opětovné použití . To je nešťastné, protože NULLs je nepravděpodobné, že by to byla reprezentativní hodnota parametru a rozhodně to nebyla hodnota uvedená v dotazu.
SQL Server 2012 (a novější) neukládá do mezipaměti plány vyplývající z požadavku „odhadovaného plánu“, i když stále zobrazuje funkční plán optimalizovaný pro NULLs hodnotu parametru v době kompilace.
Jednoduchá a vynucená parametrizace
Příkaz T-SQL ad-hoc obsahující konstantní doslovné hodnoty může být parametrizován SQL Serverem, buď proto, že se dotaz kvalifikuje pro jednoduchou parametrizaci, nebo protože je povolena možnost databáze pro vynucenou parametrizaci (nebo je se stejným účinkem použit průvodce plánem).
Takto parametrizovaný příkaz také podléhá sniffování parametrů. Následující dotaz splňuje podmínky pro jednoduchou parametrizaci:
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Heidestieg Straße 8664'; Odhadovaný plán provádění zobrazuje odhad 2,5 řádků na základě načtené hodnoty parametru:
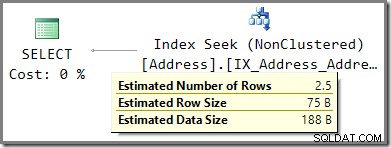
Dotaz ve skutečnosti vrátí 7 řádků (odhad mohutnosti není dokonalý, a to ani v případě, že jsou hodnoty nasnímány):
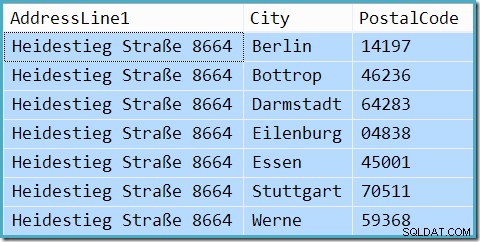
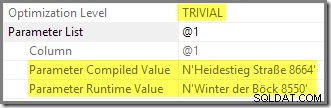
V tuto chvíli se možná ptáte, kde je důkaz, že tento dotaz byl parametrizován a výsledná hodnota parametru byla přičichnuta. Spusťte dotaz podruhé s jinou hodnotou:
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Winter der Böck 8550'; Dotaz vrátí jeden řádek:

Prováděcí plán ukazuje druhé provedení znovu použitého parametrizovaného plánu, který byl zkompilován pomocí sniffované hodnoty:
Parametrizace a čichání jsou samostatné činnosti
Příkaz ad-hoc může být parametrizován SQL Serverem bez hodnoty parametrů jsou sniffovány.
Abychom demonstrovali, můžeme použít příznak trasování 4136 k zakázání sledování parametrů pro dávku, která bude parametrizována serverem:
DBCC FREEPROCCACHE;
DBCC TRACEON (4136);
GO
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Heidestieg Straße 8664';
GO
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Winter der Böck 8550';
GO
DBCC TRACEOFF (4136); Výsledkem skriptu jsou příkazy, které jsou parametrizované, ale hodnota parametru není sniffována pro účely odhadu mohutnosti. Abychom to viděli, můžeme zkontrolovat mezipaměť plánu:
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
DECP.cacheobjtype,
DECP.objtype,
DECP.usecounts,
DECP.plan_handle,
parameterized_plan_handle =
DEQP.query_plan.value
(
'(//StmtSimple)[1]/@ParameterizedPlanHandle',
'NVARCHAR(100)'
)
FROM sys.dm_exec_cached_plans AS DECP
CROSS APPLY sys.dm_exec_sql_text(DECP.plan_handle) AS DEST
CROSS APPLY sys.dm_exec_query_plan(DECP.plan_handle) AS DEQP
WHERE
DEST.[text] LIKE N'%AddressLine1%'
AND DEST.[text] NOT LIKE N'%XMLNAMESPACES%'; Výsledky ukazují dva záznamy mezipaměti pro ad-hoc dotazy spojené s parametrizovaným (připraveným) plánem dotazů pomocí parametrizovaného popisovače plánu.
Parametrizovaný plán se používá dvakrát:

Plán provádění ukazuje jiný odhad mohutnosti nyní, když je deaktivováno sledování parametrů:
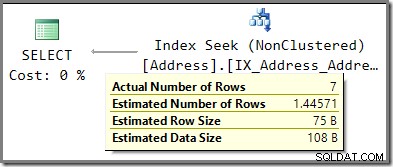
Porovnejte odhad 1,44571 řádků s odhadem 2,5 řádku použitým, když bylo aktivováno sledování parametrů.
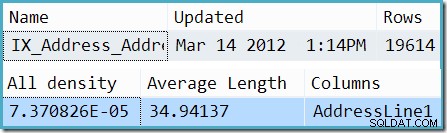
Je-li deaktivováno čichání, odhad pochází z informací o průměrné frekvenci o AddressLine1 sloupec. Výňatek z DBCC SHOW_STATISTICS výstup pro dotyčný index ukazuje, jak bylo toto číslo vypočítáno:Vynásobením počtu řádků v tabulce (19 614) hustotou (7,370826e-5) dostaneme odhad 1,44571.
Poznámka: Obecně se má za to, že pro jednoduchou parametrizaci se mohou kvalifikovat pouze celočíselná srovnání pomocí jedinečného indexu. Tento příklad jsem záměrně vybral (porovnání řetězců pomocí nejedinečného indexu), abych to vyvrátil.
S RECOMPILE a OPTION (RECOMPILE)
Když narazíte na problém s citlivostí parametrů, běžnou radou na fórech a stránkách Q&A je „použít rekompilaci“ (za předpokladu, že jiné možnosti ladění uvedené výše nejsou vhodné). Bohužel je tato rada často mylně interpretována tak, že znamená přidání WITH RECOMPILE možnost k uložené proceduře.
Pomocí WITH RECOMPILE efektivně nás vrací k chování SQL Server 2000, kde je celá uložená procedura je rekompilován při každém spuštění.
Lepší alternativa , na SQL Server 2005 a novějších, je použít OPTION (RECOMPILE) nápověda k dotazu pouze na příkaz který trpí problémem s čicháním parametrů. Výsledkem této nápovědy k dotazu je rekompilace problematického příkazu pouze. Plány provádění pro další příkazy v rámci uložené procedury jsou uloženy v mezipaměti a znovu použity jako obvykle.
Pomocí WITH RECOMPILE také znamená, že kompilovaný plán pro uloženou proceduru není uložen do mezipaměti. V důsledku toho nejsou v DMV udržovány žádné informace o výkonu, jako je sys.dm_exec_query_stats .
Použití nápovědy k dotazu místo toho znamená, že zkompilovaný plán lze uložit do mezipaměti a informace o výkonu jsou k dispozici v DMV (ačkoli jsou omezeny na nejnovější spuštění, pouze pro dotčený příkaz).
Pro instance, na kterých běží alespoň SQL Server 2008 sestavení 2746 (Service Pack 1 s kumulativní aktualizací 5), pomocí OPTION (RECOMPILE) má další podstatnou výhodu přes WITH RECOMPILE :Pouze OPTION (RECOMPILE) aktivuje Optimalizaci vkládání parametrů .
Optimalizace vkládání parametrů
Sniffing hodnot parametrů umožňuje optimalizátoru použít hodnotu parametru k odvození odhadů mohutnosti. Oba WITH RECOMPILE a OPTION (RECOMPILE) výsledkem jsou plány dotazů s odhady vypočítanými ze skutečných hodnot parametrů při každém spuštění.
Optimalizace vkládání parametrů posouvá tento proces o krok dále. Parametry dotazu jsou nahrazeny s doslovnými konstantními hodnotami během analýzy dotazu.
Analyzátor je schopen překvapivě složitých zjednodušení a následná optimalizace dotazů může věci ještě více vylepšit. Zvažte následující uloženou proceduru, která obsahuje WITH RECOMPILE možnost:
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
WITH RECOMPILE
AS
BEGIN
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC;
END; Procedura se provede dvakrát s následujícími hodnotami parametrů:
EXECUTE dbo.P @NameLike = N'K%', @Sort = 1; GO EXECUTE dbo.P @NameLike = N'[H-R]%', @Sort = 4;
Protože WITH RECOMPILE Pokud se použije, je postup při každém spuštění plně překompilován. Hodnoty parametrů jsou sniffed pokaždé a používá je optimalizátor k výpočtu odhadů mohutnosti.
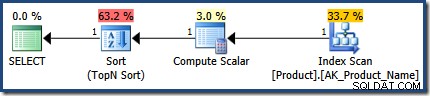
Plán pro provedení prvního postupu je přesně správný, odhaduje 1 řádek:
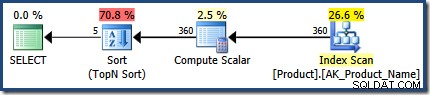
Druhé provedení odhaduje 360 řádků, což je velmi blízko počtu 366 zaznamenaných za běhu:
Oba plány používají stejnou obecnou strategii provádění:Prohledejte všechny řádky v indexu pomocí WHERE větný predikát jako reziduum; vypočítejte CASE výraz použitý v ORDER BY doložka; a proveďte Nejvyšší řazení na výsledek CASE výraz.
OPTION (REKOMPILOVAT)
Nyní znovu vytvořte uloženou proceduru pomocí OPTION (RECOMPILE) dotaz místo WITH RECOMPILE :
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
AS
BEGIN
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC
OPTION (RECOMPILE);
END; Dvojité provedení uložené procedury se stejnými hodnotami parametrů jako předtím způsobí dramaticky odlišné prováděcí plány.
Toto je první plán provádění (s parametry vyžadujícími názvy začínající na „K“, seřazené podle ProductID vzestupně):
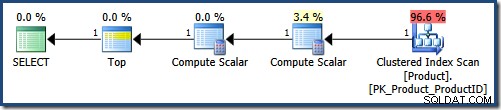
Analyzátor vloží hodnoty parametrů v textu dotazu, což vede k následujícímu přechodnému tvaru:
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
'K%' IS NULL
OR Name LIKE 'K%'
ORDER BY
CASE WHEN 1 = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN 1 = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN 1 = 3 THEN Name ELSE NULL END ASC,
CASE WHEN 1 = 4 THEN Name ELSE NULL END DESC;
Analyzátor pak jde dále, odstraňuje rozpory a plně vyhodnocuje CASE výrazy. Výsledkem je:
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
Name LIKE 'K%'
ORDER BY
ProductID ASC,
NULL DESC,
NULL ASC,
NULL DESC; Pokud se pokusíte odeslat dotaz přímo na SQL Server, zobrazí se chybová zpráva, protože řazení podle konstantní hodnoty není povoleno. Nicméně je to forma vytvořená analyzátorem. Je povoleno interně, protože vzniklo v důsledku použití optimalizace vkládání parametrů . Zjednodušený dotaz výrazně usnadňuje život optimalizátoru dotazů:
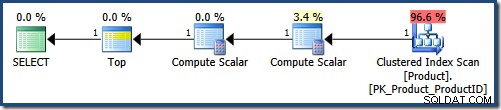
Skenování seskupeného indexu použije LIKE predikát jako reziduum. Výpočetní skalár poskytuje konstantu NULLs hodnoty. Nahoře vrátí prvních 5 řádků v pořadí uvedeném v Clustered Index (vyhýbání se řazení). V dokonalém světě by optimalizátor dotazů také odstranil Výpočetní skalár který definuje NULLs , protože se nepoužívají při provádění dotazu.
Druhé provedení následuje přesně stejný proces, jehož výsledkem je plán dotazů (pro názvy začínající písmeny „H“ až „R“, seřazené podle Name sestupně) takto:

Tento plán obsahuje Neclustered Index Seek který pokrývá LIKE rozsah, zbytkový LIKE predikát, konstanta NULLs jako dříve a horní (5). Optimalizátor dotazů se rozhodne provést BACKWARD rozsah skenování v Hledání indexu abyste se znovu vyhnuli řazení.
Porovnejte výše uvedený plán s plánem vytvořeným pomocí WITH RECOMPILE , která nemůže používat optimalizaci vkládání parametrů :
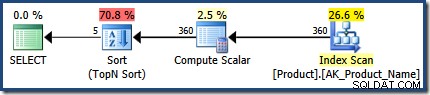
Tento ukázkový příklad by mohl být lépe implementován jako série IF příkazy v proceduře (jeden pro každou kombinaci hodnot parametrů). To by mohlo poskytnout podobné výhody plánu dotazů, aniž by bylo nutné pokaždé sestavovat příkazy. Ve složitějších scénářích rekompilace na úrovni příkazů s vložením parametrů poskytnutým OPTION (RECOMPILE) může být mimořádně užitečnou optimalizační technikou.
Omezení vkládání
Existuje jeden scénář, kde se používá OPTION (RECOMPILE) nebude mít za následek použití optimalizace vkládání parametrů. Pokud je příkaz přiřazen k proměnné, hodnoty parametrů nejsou vloženy:
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
AS
BEGIN
DECLARE
@ProductID integer,
@Name nvarchar(50);
SELECT TOP (1)
@ProductID = ProductID,
@Name = Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC
OPTION (RECOMPILE);
END;
Protože SELECT příkaz nyní přiřadí proměnné, vytvořené plány dotazů jsou stejné jako při WITH RECOMPILE byl použit. Hodnoty parametrů jsou stále sniffovány a používány optimalizátorem dotazů pro odhad mohutnosti a OPTION (RECOMPILE) stále pouze kompiluje jeden příkaz, pouze výhoda vkládání parametrů je ztraceno.