V poslední době jsem měl spoustu konverzací o typech pracovních zátěží – konkrétně o pochopení toho, zda je zátěž parametrizovaná, adhoc nebo smíšená. Je to jedna z věcí, na kterou se díváme během zdravotního auditu, a Kimberly má skvělý dotaz ze své mezipaměti plánu a optimalizace pro adhoc pracovní zátěže, která je součástí naší sady nástrojů. Zkopíroval jsem níže uvedený dotaz a pokud jste jej nikdy předtím nespouštěli v žádném ze svých produkčních prostředí, rozhodně si na to najděte čas.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Pokud spustím tento dotaz proti produkčnímu prostředí, můžeme získat výstup jako následující:
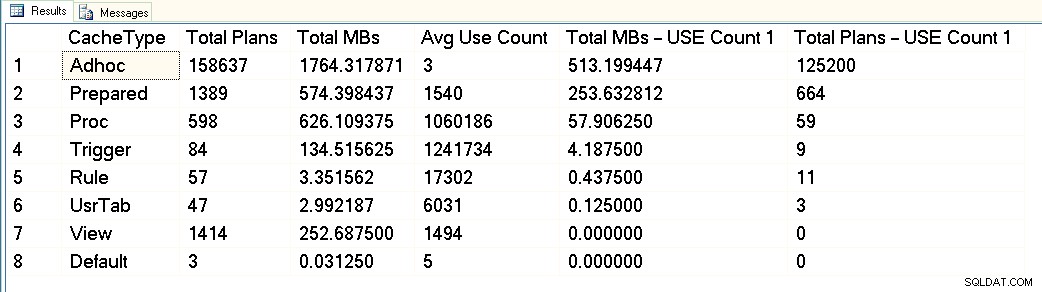
Z tohoto snímku obrazovky můžete vidět, že máme celkem asi 3 GB vyhrazené pro mezipaměť plánu a z toho 1,7 GB je pro plány s více než 158 000 adhoc dotazy. Z těchto 1,7 GB je přibližně 500 MB využito pro 125 000 plánů, které spouštějí JEDEN pouze čas. Přibližně 1 GB mezipaměti plánu je určeno pro připravené plány a plány postupů a zabírají pouze asi 300 MB místa. Ale všimněte si průměrného počtu použití – hodně přes 1 milion pro procedury. Při pohledu na tento výstup bych toto pracovní zatížení kategorizoval jako smíšené – některé parametrizované dotazy, některé adhoc.
Příspěvek na blogu Kimberly pojednává o možnostech správy mezipaměti plánu naplněné spoustou adhoc dotazů. Plán nafouknutí mezipaměti je jen jeden problém, se kterým se musíte potýkat, když máte adhoc zátěž, a v tomto příspěvku chci prozkoumat, jaký vliv může mít na CPU v důsledku všech kompilací, ke kterým musí dojít. Když se dotaz spustí na serveru SQL Server, prochází kompilací a optimalizací a s tímto procesem je spojena režie, která se často projevuje jako náklady na CPU. Jakmile je plán dotazů v mezipaměti, lze jej znovu použít. Parametrizované dotazy mohou skončit opětovným použitím plánu, který je již v mezipaměti, protože text dotazu je úplně stejný. Když se provede adhoc dotaz, znovu použije plán v mezipaměti pouze v případě, že má přesné stejný text a vstupní hodnoty .
Nastavení
Pro naše testování vygenerujeme náhodný řetězec v TSQL a zřetězíme ho do dotazu, takže každé provedení má jinou doslovnou hodnotu. Zabalil jsem to do uložené procedury, která volá dotaz pomocí Dynamic String Execution (EXEC @QueryString), takže se chová jako příkaz adhoc. Volání z uložené procedury znamená, že ji můžeme spustit známým počtem opakování.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
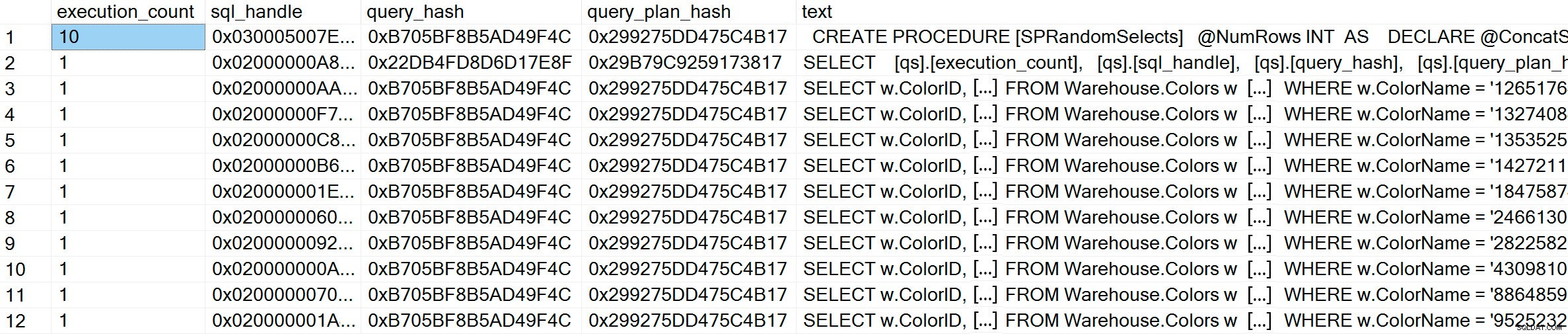
GO Pokud po provedení zkontrolujeme mezipaměť plánu, můžeme vidět, že máme 10 jedinečných záznamů, každý s počtem provádění 1 (přibližte si obrázek, pokud je potřeba, abyste viděli jedinečné hodnoty predikátu):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Nyní vytvoříme téměř identickou uloženou proceduru, která provede stejný dotaz, ale parametrizovaný:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO V mezipaměti plánu kromě 10 adhoc dotazů vidíme jednu položku pro parametrizovaný dotaz, který byl proveden 10krát. Protože je vstup parametrizován, i když jsou do parametru předány zcela odlišné řetězce, je text dotazu naprosto stejný:
Testování
Nyní, když rozumíme tomu, co se děje v mezipaměti plánu, pojďme vytvořit další zatížení. Použijeme soubor příkazového řádku, který volá stejný soubor .sql v 10 různých vláknech, přičemž každý soubor volá uloženou proceduru 10 000krát. Než začneme, vymažeme mezipaměť plánu a zaznamenáme celkové % CPU a kompilace SQL/s pomocí PerfMon, zatímco se skripty spouštějí.
Obsah souboru Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Obsah souboru Parameterized.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Příklad souboru příkazu (zobrazený v programu Poznámkový blok), který volá soubor .sql:
Ukázkový soubor příkazu (zobrazený v programu Poznámkový blok), který vytváří 10 vláken, z nichž každé volá soubor Run_Adhoc.cmd:
Po spuštění každé sady dotazů celkem 100 000krát, když se podíváme na mezipaměť plánu, uvidíme následující:

V mezipaměti plánů je více než 10 000 adhoc plánů. Možná se divíte, proč neexistuje plán pro všech 100 000 adhoc dotazů, které byly provedeny, a souvisí to s tím, jak funguje mezipaměť plánu (její velikost je založena na dostupné paměti, když nepoužívané plány zastarají atd.). Důležité je, že tak existuje mnoho adhoc plánů ve srovnání s tím, co vidíme u ostatních typů mezipaměti.
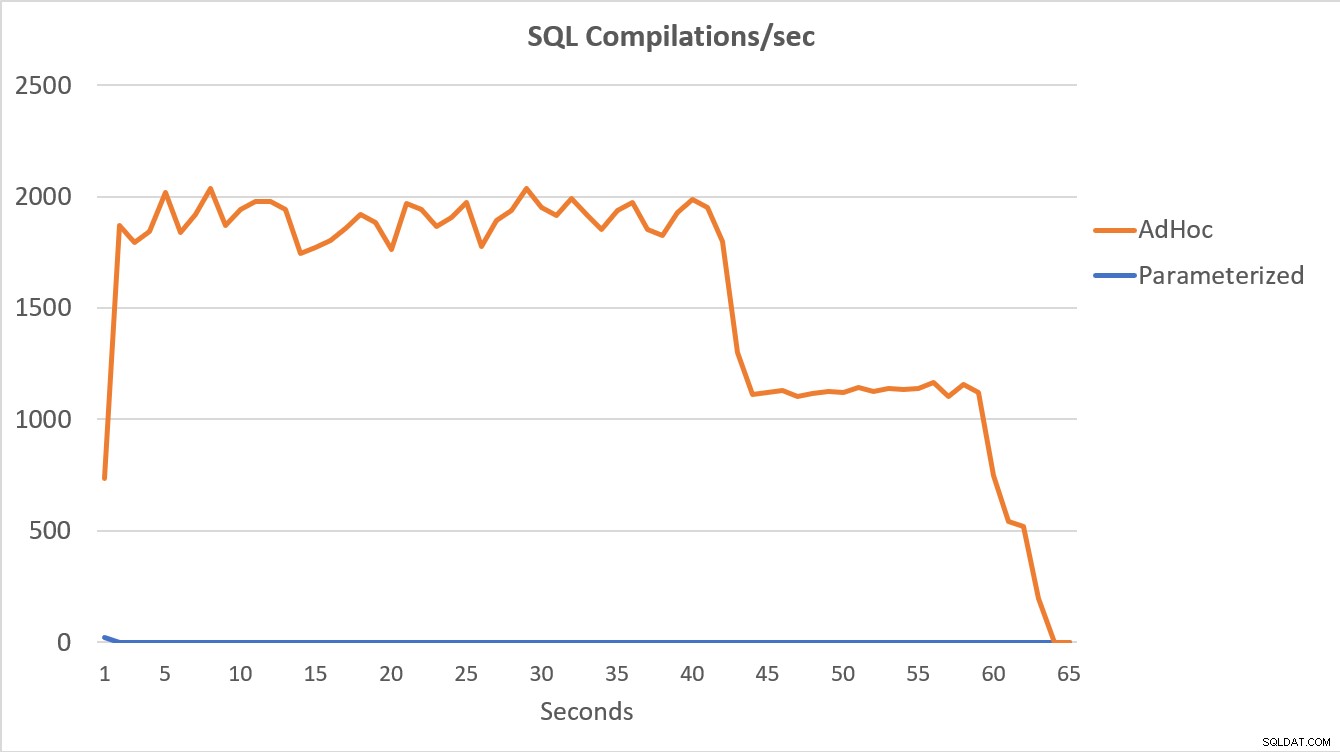
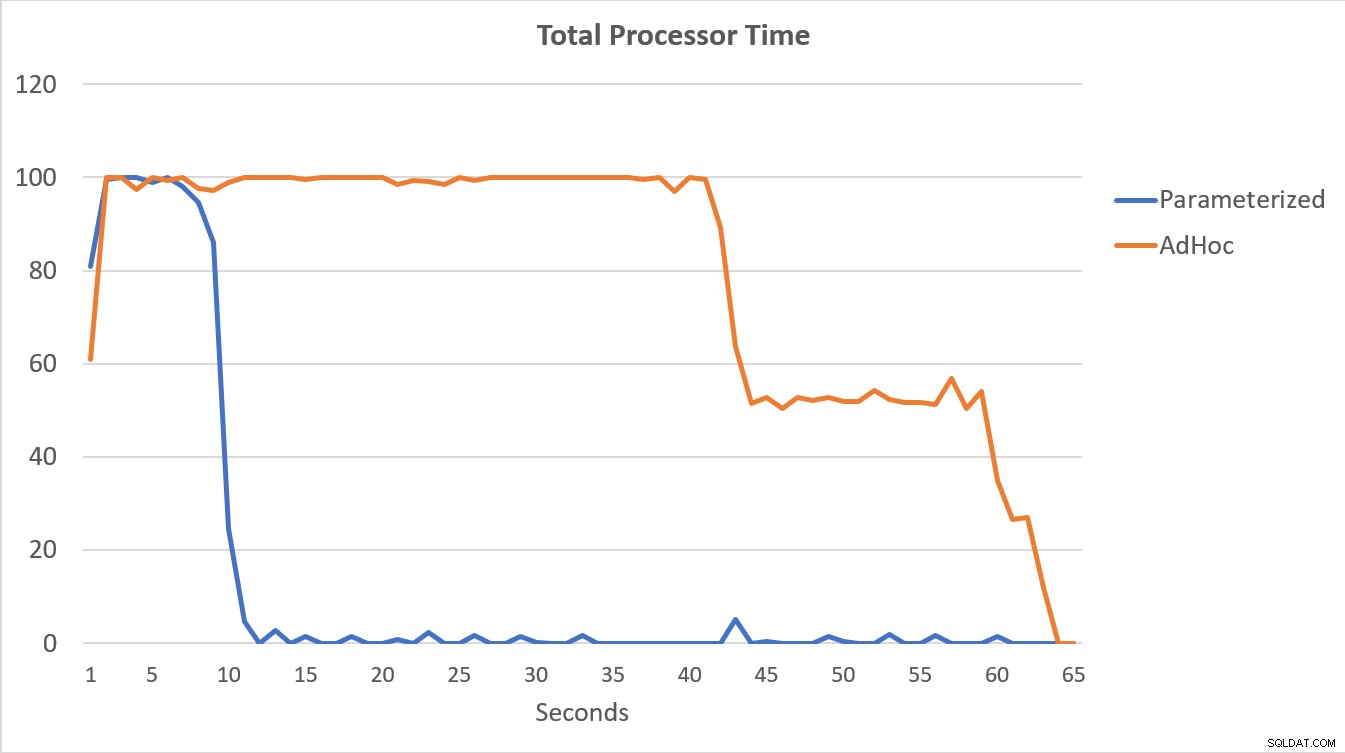
Nejvýmluvnější jsou data PerfMon uvedená v grafu níže. Provedení 100 000 parametrizovaných dotazů bylo dokončeno za méně než 15 sekund a na začátku došlo k malému nárůstu kompilací/s, což je na grafu sotva patrné. Dokončení stejného počtu adhoc spuštění trvalo něco málo přes 60 sekund, přičemž kompilace/s vyskočily blízko 2000, než klesly blíže k 1000 kolem 45 sekund, s CPU blízko nebo na 100 % po většinu času.
Shrnutí
Náš test byl extrémně jednoduchý v tom, že jsme odeslali pouze varianty pro jednu adhoc dotaz, zatímco v produkčním prostředí bychom mohli mít stovky nebo tisíce různých variant pro stovky nebo tisíce různých adhoc dotazů. Dopad na výkon těchto adhoc dotazů není jen nafouknutí mezipaměti plánu, ke kterému dochází, i když pohled na mezipaměť plánu je skvělým místem, kde začít, pokud nejste obeznámeni s typem zátěže, kterou máte. Velké množství adhoc dotazů může řídit kompilace a tím i CPU, což lze někdy maskovat přidáním dalšího hardwaru, ale může zcela jistě dojít k bodu, kdy se CPU stane úzkým hrdlem. Pokud si myslíte, že by to mohl být problém nebo potenciální problém ve vašem prostředí, podívejte se, jaké dotazy adhoc se spouštějí nejčastěji, a zjistěte, jaké máte možnosti pro jejich parametrizaci. Nechápejte mě špatně – u parametrizovaných dotazů existují potenciální problémy (např. stabilita plánu kvůli zkreslení dat), a to je další problém, který možná budete muset vyřešit. Bez ohledu na vaše pracovní vytížení je důležité pochopit, že jen zřídka existuje metoda „nastav a zapomeň“ pro kódování, konfiguraci, údržbu atd. Řešení SQL Server jsou živé, dýchající entity, které se neustále mění a neustále se o ně starají. fungovat spolehlivě. Jedním z úkolů DBA je udržet si nad touto změnou přehled a řídit výkon co nejlépe – ať už se týká adhoc nebo parametrizovaných výzev výkonu.