Úvod
Dosažení minimálního protokolování pomocí INSERT...SELECT do prázdného cíl clusterovaného indexu není tak jednoduchý, jak je popsáno v Průvodci načítáním výkonu dat .
Tento příspěvek poskytuje nové podrobnosti o požadavcích na minimální protokolování když je cílem vložení prázdný tradiční seskupený index. (Slovo „tradiční“ nezahrnuje columnstore a optimalizováno z paměti ("Hekaton") seskupené tabulky). Podmínky, které platí, když je cílová tabulka halda, naleznete v předchozím článku této série.
Souhrn pro seskupené tabulky
Průvodce výkonem načítání dat obsahuje na vysoké úrovni souhrn podmínek požadovaných pro minimální protokolování do seskupených tabulek:
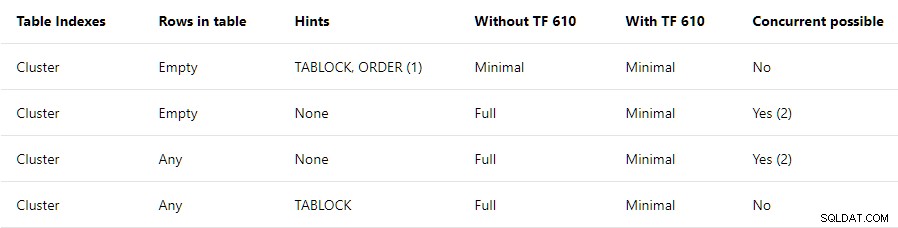
Tento příspěvek se týká pouze horního řádku . Uvádí, že TABLOCK a ORDER jsou vyžadovány rady s poznámkou:
Pokud používáte HROMADNÉ INSERT, musíte použít nápovědu k objednávce.
Vyprázdnit cíl se zámkem tabulky
Souhrnný horní řádek naznačuje, že vše vložení do prázdného seskupeného indexu bude minimálně protokolováno tak dlouho jako TABLOCK a ORDER jsou uvedeny rady. TABLOCK k povolení RowSetBulk je vyžadována nápověda zařízení, které se používá pro hromadné náklady haldového stolu. ORDER je vyžadována nápověda, aby se zajistilo, že řádky dorazí do vložení seskupeného indexu operátor plánu v pořadí klíčů cílového indexu . Bez této záruky může SQL Server přidat řádky indexu, které nejsou správně seřazeny, což by nebylo dobré.
Na rozdíl od jiných metod hromadného načítání to není možné zadejte požadovaný ORDER nápověda k INSERT...SELECT prohlášení. Tato nápověda není stejná jako pomocí ORDER BY klauzule na INSERT...SELECT prohlášení. ORDER BY klauzule na INSERT zaručuje pouze jakoukoli totožnost jsou přiřazeny hodnoty, nikoli pořadí vložení řádku.
Pro INSERT...SELECT , SQL Server dělá své vlastní rozhodnutí zda zajistit, aby se řádky zobrazovaly v vložení seskupeného indexu operátor v pořadí klíčů nebo ne. Výsledek tohoto hodnocení je viditelný v plánech provádění prostřednictvím DMLRequestSort vlastnost Vložit operátor. DMLRequestSort vlastnost musí být nastaven na true pro INSERT...SELECT do indexu, který má být minimálně protokolován . Když je nastaveno na false , minimální protokolování nemůže nastat.
S DMLRequestSort nastavte na pravda je jediná přijatelná záruka řazení vstupu vložení pro SQL Server. Dalo by se zkontrolovat plán provádění a předpovědět že řádky by měly/budou/musí dorazit v pořadí seskupeného indexu, ale bez konkrétních interních záruk poskytuje DMLRequestSort , toto hodnocení nemá cenu.
Když DMLRequestSort je pravda , SQL Server může zavést explicitní řazení operátora v prováděcím plánu. Pokud může interně zaručit objednání jinými způsoby, Řadit lze vynechat. Pokud jsou k dispozici alternativy řazení i netřídění, optimalizátor vytvoří nákladově založené výběr. Analýza nákladů nebere v úvahu minimální protokolování přímo; je řízeno očekávanými výhodami sekvenčního I/O a zamezením rozdělování stránek.
Podmínky DLRequestSort
Aby se SQL Server rozhodl nastavit DMLRequestSort, musí projít oba následující testy pravda při vkládání do prázdného seskupeného indexu s určeným uzamčením tabulky:
- Odhad více než 250 řádků na vstupní straně Clustered Index Insert operátor; a
- Odhad velikost dat více než 2 stránky . Odhadovaná velikost dat není celé číslo, takže tuto podmínku splňuje výsledek 2 001 stránek.
(To vám může připomenout podmínky pro minimální protokolování haldy , ale požadovaný odhad velikost dat je zde dvě stránky místo osmi.)
Výpočet velikosti dat
Odhadovaná velikost dat výpočet zde podléhá stejným zvláštnostem popsaným v předchozím článku pro hromady, kromě toho, že 8bajtový RID není přítomen.
Pro SQL Server 2012 a starší to znamená 5 bajtů navíc na řádek jsou zahrnuty do výpočtu velikosti dat:Jeden bajt pro interní bit příznak a čtyři bajty pro uniquifier (používá se ve výpočtu i pro jedinečné indexy, které neukládají unikifikátor ).
Pro SQL Server 2014 a novější, uniquifier je správně vynecháno pro jedinečné indexy, ale jeden bajt navíc pro interní bit příznak je zachován.
Ukázka
Následující skript by měl být spuštěn na vývojové instanci SQL Server v nové testovací databázi nastavte na použití SIMPLE nebo BULK_LOGGED model obnovy.
Demo načte 268 řádků do zcela nové seskupené tabulky pomocí INSERT...SELECT pomocí TABLOCK a sestavy o vygenerovaných záznamech protokolu transakcí.
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
(Pokud skript spouštíte na SQL Server 2012 nebo starším, změňte TOP klauzule ve skriptu od 268 do 252, z důvodů, které budou vysvětleny za chvíli.)
Výstup ukazuje, že všechny vložené řádky byly plně protokolovány navzdory prázdnému cílová seskupená tabulka a TABLOCK nápověda:
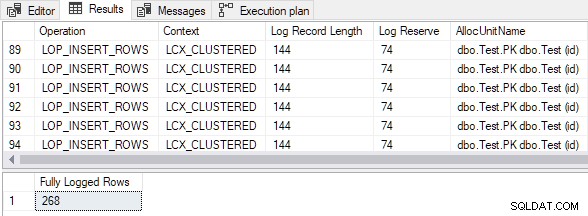
Vypočítaná velikost vložených dat
Vlastnosti plánu provádění Vložení seskupeného indexu operátor ukazuje, že DMLRequestSort je nastaveno na false . Důvodem je, že ačkoli je odhadovaný počet řádků k vložení více než 250 (splňuje první požadavek), vypočtené velikost dat není přesáhnout dvě stránky o velikosti 8 kB.
Podrobnosti výpočtu (pro SQL Server 2014 a novější) jsou následující:
- Celková pevná délka velikost sloupce =54 bajtů :
- ID typu 104
bit=1 bajt (interní). - Zadejte ID 56
integer=4 bajty (idsloupec). - Zadejte ID 56
integer=4 bajty (c1sloupec). - ID typu 175
char(45)=45 bajtů (paddingsloupec).
- ID typu 104
- Nová bitmapa =3 bajty .
- Záhlaví řádku režie =4 bajty .
- Vypočítaná velikost řádku =54 + 3 + 4 =61 bajtů .
- Vypočítaná velikost dat =61 bajtů * 268 řádků =16 348 bajtů .
- Stránky s vypočtenými daty =16 384 / 8 192 =1,99560546875 .
Vypočítaná velikost řádku (61 bajtů) se liší od skutečné velikosti úložiště řádku (60 bajtů) o jeden bajt interních metadat navíc přítomných ve vloženém proudu. Výpočet také nezohledňuje 96 bajtů použitých na každé stránce záhlavím stránky nebo jiné věci, jako je režie verzování řádků. Stejný výpočet na SQL Server 2012 přidá další 4 bajty na řádek pro uniquifier (který není přítomen v jedinečných indexech, jak bylo zmíněno výše). Bajty navíc znamenají, že se na každou stránku vejde méně řádků:
- Vypočítaná velikost řádku =61 + 4 =65 bajtů .
- Vypočítaná velikost dat =65 bajtů * 252 řádků =16 380 bajtů
- Stránky s vypočtenými daty =16 380 / 8 192 =1,99951171875 .
Změna TOP klauzule z 268 řádků na 269 (nebo z 252 na 253 pro rok 2012) činí výpočet očekávané velikosti dat správným tip přes minimální hranici 2 stránek:
- SQL Server 2014
- 61 bajtů * 269 řádků =16 409 bajtů.
- 16 409 / 8192 =2,0030517578125 stránky.
- SQL Server 2012
- 65 bajtů * 253 řádků =16 445 bajtů.
- 16 445 / 8192 =2,0074462890625 stránky.
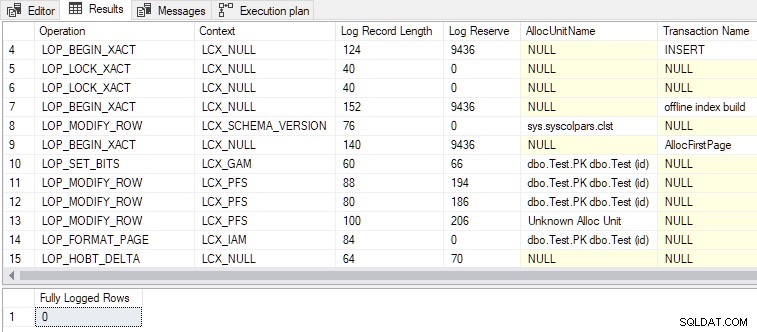
Nyní je splněna i druhá podmínka, DMLRequestSort je nastaveno na true a minimální protokolování je dosaženo, jak ukazuje výstup níže:
Některé další zajímavosti:
- Celkem je vygenerováno 79 záznamů protokolu ve srovnání s 328 u plně protokolované verze. Očekávaným výsledkem minimálního protokolování je méně záznamů protokolu.
LOP_BEGIN_XACTzáznamy v minimálně protokolovaných záznamy si rezervují poměrně velké množství logovacího prostoru (každý 9436 bajtů).- Jeden z názvů transakcí uvedených v záznamech protokolu je „offline index build“ . I když jsme nežádali o vytvoření indexu jako takového, hromadné načítání řádků do prázdného indexu je v podstatě stejná operace.
- úplně přihlášeni insert používá exkluzivní zámek na úrovni tabulky (
Tab-X), zatímco minimálně protokolované insert převezme úpravu schématu (Sch-M) stejně jako „skutečné“ offline sestavení indexu. - Hromadné načítání prázdné seskupené tabulky pomocí
INSERT...SELECTpomocíTABLOCKaDMRequestSortnastavte na pravda používáRowsetBulkmechanismus, stejně jako minimálně protokolované haldy zatížení v předchozím článku.
Odhady mohutnosti
Dejte si pozor na nízké odhady mohutnosti v Vložení seskupeného rejstříku operátor. Pokud je k nastavení DMLRequestSort vyžadována některá z prahových hodnot pravda není dosaženo kvůli nepřesnému odhadu mohutnosti, vložka bude plně přihlášena , bez ohledu na skutečný počet řádků a celkovou velikost dat zjištěnou v době provádění.
Například změna TOP klauzule v demo skriptu k použití proměnné vede k pevné mohutnosti hádejte 100 řádků, což je méně než minimum 251 řádků:
-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Plánovat ukládání do mezipaměti
DMLRequestSort vlastnost je uložena jako součást plánu uloženého v mezipaměti. Když je plán uložený v mezipaměti znovu použit , hodnota DMLRequestSort není přepočítán v době provádění, pokud nedojde k rekompilaci. Všimněte si, že pro TRIVIAL nedochází k rekompilacím plány založené na změnách statistik nebo mohutnosti tabulky.
Jedním ze způsobů, jak se vyhnout jakémukoli neočekávanému chování způsobenému ukládáním do mezipaměti, je použít OPTION (RECOMPILE) náznak. Tím zajistíte správné nastavení pro DMLRequestSort je přepočítán za cenu kompilace při každém spuštění.
Příznak sledování
Je možné vynutit DMLRequestSort být nastaven na pravda nastavením nedokumentované a nepodporované trasovací příznak 2332, jak jsem psal v Optimalizace T-SQL dotazů, které mění data. Bohužel to není ovlivnit minimální protokolování způsobilost pro prázdné seskupené tabulky — příloha musí být stále odhadována na více než 250 řádků a 2 stránky. Tento příznak trasování ovlivňuje ostatní minimální protokolování scénáře, které jsou popsány v závěrečné části této série.
Přehled
Hromadné načítání prázdného seskupený index pomocí INSERT...SELECT znovu používá RowsetBulk mechanismus používaný k hromadnému nakládání haldových tabulek. To vyžaduje zamykání tabulky (běžně se to dosahuje pomocí TABLOCK nápověda) a ORDER náznak. Neexistuje žádný způsob, jak přidat ORDER nápověda k INSERT...SELECT prohlášení. V důsledku toho je dosaženo minimálního protokolování do prázdné seskupené tabulky vyžaduje DMLRequestSort vlastnost Clustered Index Insert operátor je nastaven na true . To zaručuje na SQL Server, které se řádky zobrazí Insert operátor dorazí v pořadí cílového indexového klíče. Efekt je stejný jako při použití ORDER nápověda dostupná pro jiné metody hromadného vkládání, jako je BULK INSERT a bcp .
Za účelem DMLRequestSort nastavte na pravda , musí tam být:
- Více než 250 řádků odhadem vložit; a
- Odhad vložte velikost dat větší než dvě stránky .
Odhad vložit výpočet velikosti dat není shodují se s výsledkem vynásobení prováděcího plánu odhadovaným počtem řádků a odhadovaná velikost řádku vlastnosti na vstupu do Vložit operátor. Interní výpočet (nesprávně) zahrnuje jeden nebo více interních sloupců ve vloženém proudu, které nejsou trvalé v konečném indexu. Interní výpočet také nezohledňuje záhlaví stránek nebo jiné režie, jako je verzování řádků.
Při testování nebo ladění minimální protokolování problémů, dejte si pozor na nízké odhady mohutnosti a nezapomeňte, že nastavení DMLRequestSort je ukládán do mezipaměti jako součást prováděcího plánu.
Poslední část této série podrobně popisuje podmínky potřebné k dosažení minimálního protokolování bez použití RowsetBulk mechanismus. Ty přímo odpovídají novým zařízením přidaným pod příznakem trasování 610 na SQL Server 2008, poté změněno tak, aby byly ve výchozím nastavení zapnuté od SQL Server 2016 a dále.