Tento článek je druhým ze série o chybách, úskalích a osvědčených postupech T-SQL. Tentokrát se zaměřím na klasické chyby zahrnující poddotazy. Zejména se věnuji substitučním chybám a tříhodnotovým logickým problémům. Některá z témat, kterými se v seriálu zabývám, byla navržena kolegy MVP v diskusi, kterou jsme na toto téma vedli. Děkujeme Erlandu Sommarskogovi, Aaronovi Bertrandovi, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Miloš Radivojevič, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man a Paul White za vaše návrhy!
Chyba substituce
Abych demonstroval klasickou chybu substituce, použiji jednoduchý scénář zákazníci-objednávky. Spuštěním následujícího kódu vytvořte pomocnou funkci nazvanou GetNums a vytvořte a naplňte tabulky Zákazníci a Objednávky:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); V současnosti má tabulka Zákazníci 100 zákazníků s po sobě jdoucími ID zákazníků v rozsahu 1 až 100. 98 z těchto zákazníků má odpovídající objednávky v tabulce Objednávky. Zákazníci s ID 17 a 59 zatím nezadali žádné objednávky, a proto nejsou přítomni v tabulce Objednávky.
Jde vám pouze o zákazníky, kteří zadali objednávky, a pokoušíte se toho dosáhnout pomocí následujícího dotazu (nazývejte ho Dotaz 1):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Měli byste získat zpět 98 zákazníků, ale místo toho získáte všech 100 zákazníků, včetně těch s ID 17 a 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Dokážete přijít na to, co je špatně?
Chcete-li tento zmatek rozšířit, prozkoumejte plán pro Dotaz 1, jak je znázorněno na obrázku 1.
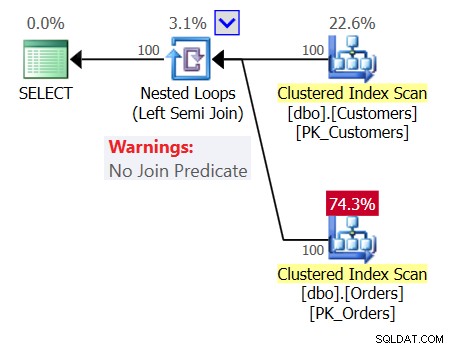 Obrázek 1:Plán pro dotaz 1
Obrázek 1:Plán pro dotaz 1
Plán ukazuje operátor Nested Loops (Left Semi Join) bez predikátu spojení, což znamená, že jedinou podmínkou pro vrácení zákazníka je mít neprázdnou tabulku Orders, jako by dotaz, který jste napsali, byl následující:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Pravděpodobně jste očekávali plán podobný tomu, který je znázorněn na obrázku 2.
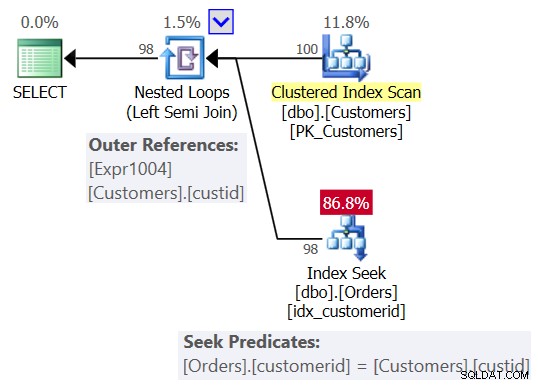 Obrázek 2:Očekávaný plán pro dotaz 1
Obrázek 2:Očekávaný plán pro dotaz 1
V tomto plánu vidíte operátor Nested Loops (Left Semi Join) se skenováním seskupeného indexu na Customers jako vnějším vstupem a hledáním v indexu ve sloupci customerid v Orders jako vnitřním vstupem. Vidíte také vnější odkaz (korelovaný parametr) založený na sloupci custid v Customers a predikát vyhledávání Orders.customerid =Customers.custid.
Proč tedy máte plán na obrázku 1 a ne ten na obrázku 2? Pokud jste na to ještě nepřišli, podívejte se pozorně na definice obou tabulek – konkrétně na názvy sloupců – a na názvy sloupců použité v dotazu. Všimněte si, že tabulka Zákazníci obsahuje ID zákazníků ve sloupci nazvaném custid a že tabulka Objednávky obsahuje ID zákazníků ve sloupci nazvaném customerid. Kód však používá custid ve vnějších i vnitřních dotazech. Protože odkaz na custid ve vnitřním dotazu není kvalifikovaný, musí SQL Server vyřešit, ze které tabulky sloupec pochází. Podle standardu SQL má SQL Server nejprve vyhledat sloupec v tabulce, který je dotazován ve stejném rozsahu, ale protože v objednávkách není žádný sloupec s názvem custid, měl by jej hledat v tabulce ve vnějším rozsah a tentokrát je tu shoda. Takže neúmyslně se odkaz na custid stane implicitně korelovaným odkazem, jako kdybyste napsali následující dotaz:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
Za předpokladu, že Objednávky nejsou prázdné a že vnější custid hodnota není NULL (v našem případě nemůže být, protože sloupec je definován jako NOT NULL), vždy dostanete shodu, protože porovnáváte hodnotu se sebou samým. . Dotaz 1 se tedy stává ekvivalentem:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Pokud by vnější tabulka podporovala hodnoty NULL ve sloupci custid, Dotaz 1 by byl ekvivalentní:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Nyní chápete, proč byl Dotaz 1 optimalizován s plánem na obrázku 1 a proč jste získali zpět všech 100 zákazníků.
Před časem jsem navštívil zákazníka, který měl podobnou chybu, ale bohužel s příkazem DELETE. Zamyslete se na chvíli, co to znamená. Všechny řádky tabulky byly vymazány a nejen ty, které původně zamýšleli smazat!
Pokud jde o osvědčené postupy, které vám mohou pomoci vyhnout se takovým chybám, existují dva hlavní. Za prvé, pokud to můžete ovládat, ujistěte se, že používáte konzistentní názvy sloupců napříč tabulkami pro atributy, které představují totéž. Zadruhé se ujistěte, že tabulky kvalifikujete odkazy na sloupce v poddotazech, včetně samostatných dotazů, kde to není běžná praxe. Samozřejmě můžete použít alias tabulky, pokud nechcete používat úplné názvy tabulek. Při použití tohoto postupu na náš dotaz předpokládejme, že váš první pokus použil následující kód:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Zde nepovolujete implicitní překlad názvů sloupců, a proto SQL Server generuje následující chybu:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Jdete a zkontrolujete metadata pro tabulku Objednávky, uvědomíte si, že jste použili nesprávný název sloupce, a opravte dotaz (nazvěte tento Dotaz 2), takto:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Tentokrát získáte správný výstup s 98 zákazníky, s výjimkou zákazníků s ID 17 a 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
Získáte také očekávaný plán zobrazený dříve na obrázku 2.
Kromě toho je jasné, proč je Customers.custid vnější reference (korelovaný parametr) v operátoru Nested Loops (Left Semi Join) na obrázku 2. Méně zřejmé je, proč se Expr1004 objevuje v plánu také jako vnější reference. Kolega SQL Server MVP Paul White teoretizuje, že by to mohlo souviset s používáním informací z vnějšího vstupního listu k naznačení enginu úložiště, aby se předešlo duplicitnímu úsilí mechanismů čtení napřed. Podrobnosti najdete zde.
Problém s logikou se třemi hodnotami
Běžná chyba zahrnující poddotazy souvisí s případy, kdy vnější dotaz používá predikát NOT IN a poddotaz může mezi svými hodnotami potenciálně vracet hodnoty NULL. Předpokládejme například, že potřebujete mít možnost ukládat objednávky v naší tabulce Objednávky s NULL jako ID zákazníka. Takový případ by představoval objednávku, která není spojena s žádným zákazníkem; například objednávka, která kompenzuje nesrovnalosti mezi skutečnými počty produktů a počty zaznamenanými v databázi.
Pomocí následujícího kódu znovu vytvořte tabulku Orders se sloupcem custid, který umožňuje hodnoty NULL, a nyní ji naplňte stejnými vzorovými daty jako dříve (s objednávkami podle ID zákazníka 1 až 100, kromě 17 a 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Všimněte si, že když už jsme u toho, řídil jsem se osvědčeným postupem uvedeným v předchozí části, abych použil konzistentní názvy sloupců napříč tabulkami pro stejné atributy, a pojmenoval jsem sloupec v tabulce Objednávky jako custid stejně jako v tabulce Zákazníci.
Předpokládejme, že potřebujete napsat dotaz, který vrátí zákazníky, kteří nezadali objednávky. Přijdete s následujícím zjednodušeným řešením pomocí predikátu NOT IN (nazývejte to Dotaz 3, první spuštění):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Tento dotaz vrací očekávaný výstup se zákazníky 17 a 59:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Ve skladu společnosti se provádí inventura a je zjištěna nekonzistence mezi skutečným množstvím nějakého produktu a množstvím zaznamenaným v databázi. Takže přidáte fiktivní kompenzační příkaz, abyste vysvětlili nekonzistenci. Vzhledem k tomu, že s objednávkou není spojen žádný skutečný zákazník, použijete jako ID zákazníka hodnotu NULL. Chcete-li přidat takové záhlaví objednávky, spusťte následující kód:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Spusťte dotaz 3 podruhé:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Tentokrát dostanete prázdný výsledek:
custid companyname ------- ------------ (0 rows affected)
Je jasné, že něco není v pořádku. Víte, že zákazníci 17 a 59 nezadali žádné objednávky a skutečně se objevují v tabulce Zákazníci, ale ne v tabulce Objednávky. Výsledek dotazu však tvrdí, že neexistuje žádný zákazník, který by nezadal žádné objednávky. Dokážete zjistit, kde je chyba a jak ji opravit?
Chyba samozřejmě souvisí s hodnotou NULL v tabulce Orders. Pro SQL je NULL značka pro chybějící hodnotu, která by mohla představovat příslušného zákazníka. SQL neví, že pro nás NULL představuje chybějícího a nepoužitelného (irelevantního) zákazníka. U všech zákazníků v tabulce Zákazníci, kteří jsou přítomni v tabulce Objednávky, najde predikát IN shodu s výsledkem TRUE a část NOT IN z něj udělá NEPRAVDA, proto je řádek zákazníka zahozen. Zatím je vše dobré. Ale pro zákazníky 17 a 59 má predikát IN hodnotu NEZNÁMÝ, protože všechna srovnání s hodnotami, které nejsou NULL, dávají hodnotu FALSE a porovnání s hodnotou NULL přináší NEZNÁMÝ. Pamatujte, že SQL předpokládá, že hodnota NULL může představovat libovolného použitelného zákazníka, takže logická hodnota UNKNOWN znamená, že není známo, zda se vnější ID zákazníka rovná vnitřnímu ID zákazníka NULL. FALSE OR FALSE … NEBO NEZNÁMÝ je NEZNÁMÝ. Pak část NOT IN aplikovaná na UNKNOWN stále dává UNKNOWN.
Jednodušeji řečeno, požádali jste o vrácení zákazníků, kteří nezadali objednávky. Dotaz tedy přirozeně vyřadí všechny zákazníky z tabulky Zákazníci, kteří jsou přítomni v tabulce Objednávky, protože je s jistotou známo, že zadali objednávky. Pokud jde o zbytek (v našem případě 17 a 59), dotaz je zahodí, protože do SQL, stejně jako není známo, zda zadali objednávky, stejně tak není známo, zda nezadali objednávky, a filtr potřebuje jistotu (PRAVDA) v příkaz vrátit řádek. Jaká okurka!
Jakmile se tedy do tabulky Orders dostane první NULL, od tohoto okamžiku vždy dostanete zpět prázdný výsledek z dotazu NOT IN. A co případy, kdy ve skutečnosti v datech nemáte hodnoty NULL, ale sloupec umožňuje hodnoty NULL? Jak jste viděli při prvním spuštění Dotazu 3, v takovém případě dostanete správný výsledek. Možná si myslíte, že aplikace nikdy nezavede do dat hodnoty NULL, takže se nemusíte ničeho obávat. To je špatná praxe z několika důvodů. Za prvé, pokud je sloupec definován jako povolující hodnoty NULL, je do značné míry jistota, že se tam hodnoty NULL nakonec dostanou, i když by neměly; je to jen otázka času. Může to být důsledek importu špatných dat, chyby v aplikaci a dalších důvodů. Za druhé, i když data neobsahují hodnoty NULL, pokud to sloupec umožňuje, musí optimalizátor počítat s možností, že při vytváření plánu dotazů budou přítomny hodnoty NULL, a v našem dotazu NOT IN to způsobí penalizaci výkonu. . Chcete-li to demonstrovat, zvažte plán prvního spuštění Dotazu 3 před přidáním řádku s hodnotou NULL, jak je znázorněno na obrázku 3.
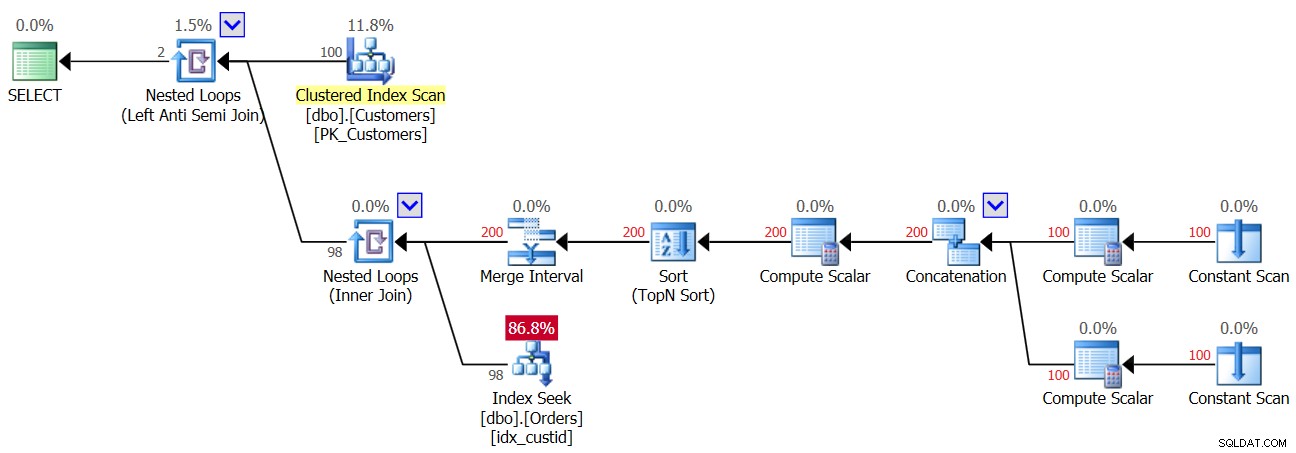 Obrázek 3:Plán prvního spuštění Dotazu 3
Obrázek 3:Plán prvního spuštění Dotazu 3
Horní operátor Nested Loops zpracovává logiku Left Anti Semi Join. Jde v podstatě o identifikaci neshod a zkratování vnitřní aktivity, jakmile je nalezena shoda. Vnější část smyčky vytáhne všech 100 zákazníků z tabulky Zákazníci, vnitřní část smyčky se tedy provede 100krát.
Vnitřní část horní smyčky provádí operátor Nested Loops (Inner Join). Vnější část spodní smyčky vytváří dva řádky na zákazníka – jeden pro případ NULL a druhý pro aktuální ID zákazníka v tomto pořadí. Nenechte se zmást operátorem Interval sloučení. Obvykle se používá ke sloučení překrývajících se intervalů, např. predikát jako col1 BETWEEN 20 AND 30 NEBO col1 BETWEEN 25 AND 35 se převede na col1 BETWEEN 20 AND 35. Tento nápad lze zobecnit a odstranit duplikáty v predikátu IN. V našem případě skutečně nemohou existovat žádné duplikáty. Zjednodušeně řečeno, jak již bylo zmíněno, představte si vnější část smyčky jako vytvoření dvou řádků na zákazníka – první pro případ NULL a druhý pro aktuální ID zákazníka. Poté vnitřní část smyčky nejprve vyhledá v indexu idx_custid na příkazech, aby hledala NULL. Pokud je nalezena hodnota NULL, neaktivuje druhé vyhledávání pro aktuální ID zákazníka (pamatujte na zkrat, který zvládla horní smyčka Anti Semi Join). V takovém případě je vnější zákazník vyřazen. Pokud však NULL není nalezena, spodní smyčka aktivuje druhé hledání k vyhledání aktuálního ID zákazníka v objednávkách. Pokud je nalezen, vnější zákazník je vyřazen. Pokud není nalezen, je vrácen vnější zákazník. To znamená, že když v objednávkách nejsou přítomny hodnoty NULL, tento plán provede dvě hledání na zákazníka! To lze v plánu pozorovat jako počet řad 200 ve vnějším vstupu spodní smyčky. Zde jsou tedy I/O statistiky, které jsou hlášeny pro první spuštění:
Table 'Orders'. Scan count 200, logical reads 603
Plán druhého provedení Dotazu 3 poté, co byl do tabulky Objednávky přidán řádek s NULL, je znázorněn na obrázku 4.
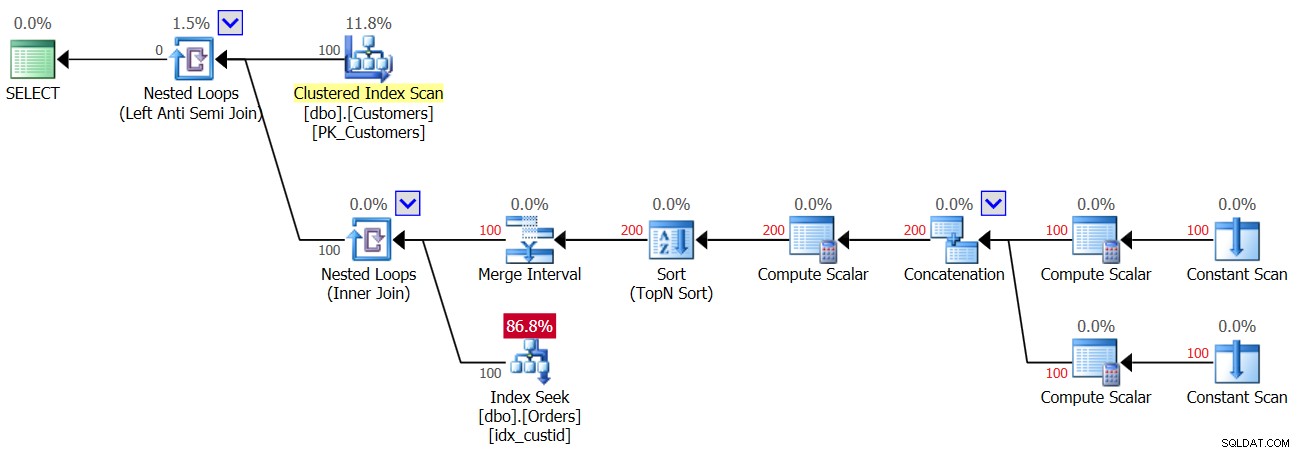 Obrázek 4:Plán druhého spuštění Dotazu 3
Obrázek 4:Plán druhého spuštění Dotazu 3
Vzhledem k tomu, že v tabulce je přítomna NULL, pro všechny zákazníky najde první spuštění operátora Index Seek shodu, a proto budou všichni zákazníci vyřazeni. Takže yay, provádíme pouze jedno hledání na zákazníka a ne dva, takže tentokrát dostanete 100 hledání a ne 200; zároveň to však znamená, že se vám vrací prázdný výsledek!
Zde jsou I/O statistiky, které jsou hlášeny pro druhé spuštění:
Table 'Orders'. Scan count 100, logical reads 300
Jedním řešením tohoto úkolu, když jsou mezi vrácenými hodnotami v poddotazu možné hodnoty NULL, je jednoduše je odfiltrovat, například (nazývejte to řešení 1/dotaz 4):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Tento kód generuje očekávaný výstup:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Nevýhodou tohoto řešení je, že musíte pamatovat na přidání filtru. Preferuji řešení využívající predikát NOT EXISTS, kde má poddotaz explicitní korelaci porovnávající zákaznické ID objednávky s zákaznickým ID zákazníka, podobně (nazývejte to řešení 2/dotaz 5):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Pamatujte, že porovnání mezi hodnotou NULL a čímkoli na základě rovnosti vede k NEZNÁMÉMU a NEZNÁMÉ je filtrem WHERE zahozeno. Pokud tedy v objednávkách existují hodnoty NULL, jsou eliminovány filtrem vnitřního dotazu, aniž byste museli přidat explicitní ošetření NULL, a proto se nemusíte starat o to, zda v datech existují nebo neexistují hodnoty NULL.
Tento dotaz generuje očekávaný výstup:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Plány pro obě řešení jsou znázorněny na obrázku 5.
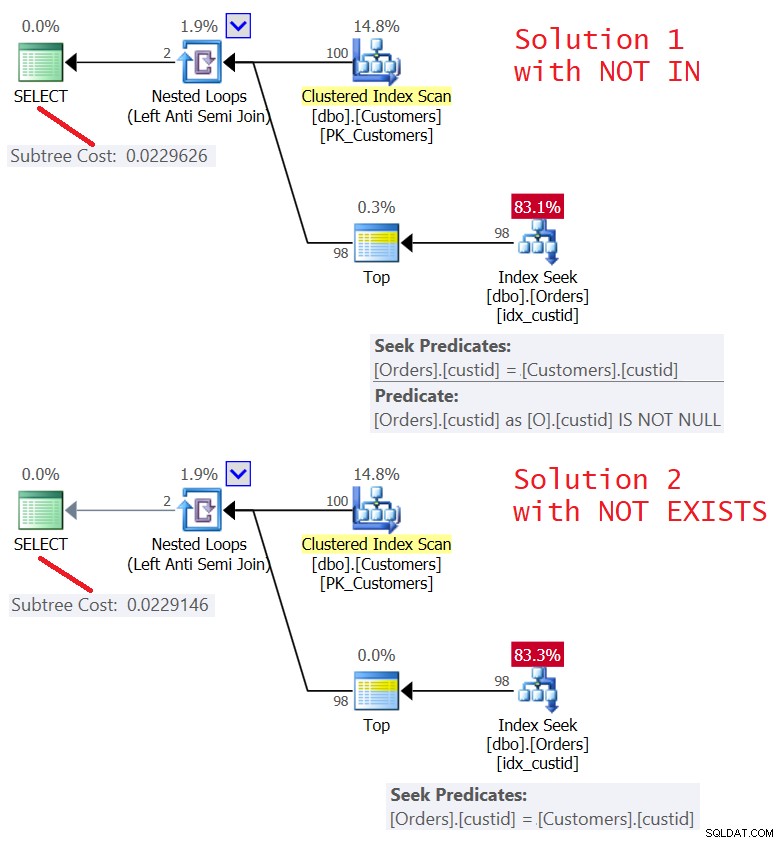 Obrázek 5:Plány pro Dotaz 4 (Řešení 1) a Dotaz 5 (Řešení 2 )
Obrázek 5:Plány pro Dotaz 4 (Řešení 1) a Dotaz 5 (Řešení 2 )
Jak vidíte, plány jsou téměř totožné. Jsou také docela efektivní, používají optimalizaci Left Semi Join se zkratem. Oba provedou pouze 100 hledání v indexu idx_custid na příkazech a pomocí operátoru Top aplikují zkrat po dotyku jednoho řádku v listu.
Statistiky I/O pro oba dotazy jsou stejné:
Table 'Orders'. Scan count 100, logical reads 348
Jedna věc, kterou je třeba zvážit, je, zda existuje nějaká šance, že vnější tabulka bude mít v korelovaném sloupci hodnoty NULL (v našem případě custid). Je velmi nepravděpodobné, že by to bylo relevantní ve scénáři, jako jsou objednávky zákazníků, ale mohlo by to být relevantní v jiných scénářích. Pokud tomu tak skutečně je, obě řešení zpracovávají vnější hodnotu NULL nesprávně.
Chcete-li to demonstrovat, zrušte a znovu vytvořte tabulku Zákazníci s NULL jako jedním z ID zákazníků spuštěním následujícího kódu:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); Řešení 1 nevrátí vnější hodnotu NULL bez ohledu na to, zda je přítomna vnitřní hodnota NULL či nikoli.
Řešení 2 vrátí vnější hodnotu NULL bez ohledu na to, zda je přítomna vnitřní hodnota NULL či nikoli.
Pokud si přejete zacházet s hodnotami NULL, jako byste zacházeli s hodnotami, které nejsou NULL, tj. vrátit hodnotu NULL, pokud je přítomna v Zákazníkech, ale ne v objednávkách, a nevracet ji, pokud je přítomna v obou, musíte změnit logiku řešení, abyste použili odlišnost. srovnání založené na rovnosti namísto srovnání založeného na rovnosti. Toho lze dosáhnout kombinací predikátu EXISTS a množinového operátoru EXCEPT, podobně (nazývejte to Řešení 3/Dotaz 6):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Protože v současné době existují hodnoty NULL v zákaznících i objednávkách, tento dotaz správně nevrací hodnotu NULL. Zde je výstup dotazu:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Spuštěním následujícího kódu odeberte řádek s hodnotou NULL z tabulky Objednávky a znovu spusťte řešení 3:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Tentokrát, protože NULL je přítomna v Customers, ale ne v objednávkách, výsledek obsahuje NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
Plán tohoto řešení je znázorněn na obrázku 6:
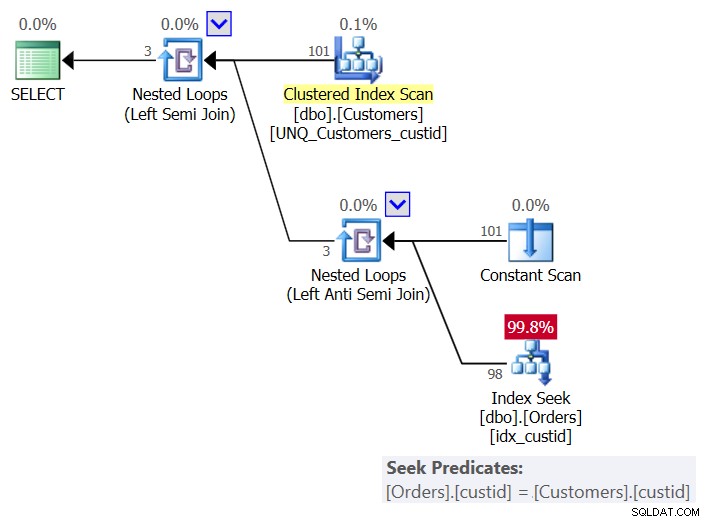 Obrázek 6:Plán pro dotaz 6 (řešení 3)
Obrázek 6:Plán pro dotaz 6 (řešení 3)
Plán pro každého zákazníka používá operátor Constant Scan k vytvoření řádku s aktuálním zákazníkem a aplikuje jediné hledání v indexu idx_custid na Objednávky, aby zkontroloval, zda zákazník v Objednávkách existuje. Skončíte s jedním hledáním na zákazníka. Protože aktuálně máme v tabulce 101 zákazníků, dostáváme 101 vyhledávání.
Zde jsou statistiky I/O pro tento dotaz:
Table 'Orders'. Scan count 101, logical reads 415
Závěr
Tento měsíc jsem se zabýval chybami, úskalími a doporučenými postupy souvisejícími s poddotazy. Zabýval jsem se substitučními chybami a tříhodnotovými logickými problémy. Nezapomeňte používat konzistentní názvy sloupců napříč tabulkami a vždy kvalifikovat sloupce v poddotazech, i když jsou samostatné. Nezapomeňte také vynutit omezení NOT NULL, když sloupec nemá povolovat hodnoty NULL, a vždy brát v úvahu hodnoty NULL, pokud jsou ve vašich datech možné. Ujistěte se, že jste do ukázkových dat zahrnuli hodnoty NULL, když jsou povoleny, abyste mohli snáze zachytit chyby v kódu při jeho testování. Při kombinaci s poddotazy buďte opatrní s predikátem NOT IN. Pokud jsou ve výsledku vnitřního dotazu možné hodnoty NULL, je obvykle preferovanou alternativou predikát NOT EXISTS.