V plánu obnovy po havárii je cíl bodu obnovy (RPO) klíčovým parametrem obnovy, který určuje, kolik dat si můžete dovolit ztratit. RPO se uvádí v čase, od sekund po dny. RPO je ve skutečnosti přímo závislé na vašem zálohovacím systému. Označuje stáří vašich zálohovaných dat, která musíte obnovit, abyste mohli obnovit normální operace.
Pokud provedete noční zálohu ve 22 hodin. a váš databázový systém neopravitelně havaruje v 15:00. následující den ztratíte vše, co bylo změněno od poslední zálohy. Vaše RPO je v tomto konkrétním kontextu záloha z předchozího dne, což znamená, že si můžete dovolit přijít o změny za jeden den.
Níže uvedený diagram z naší Whitepaper on Disaster Recovery tento koncept ilustruje.
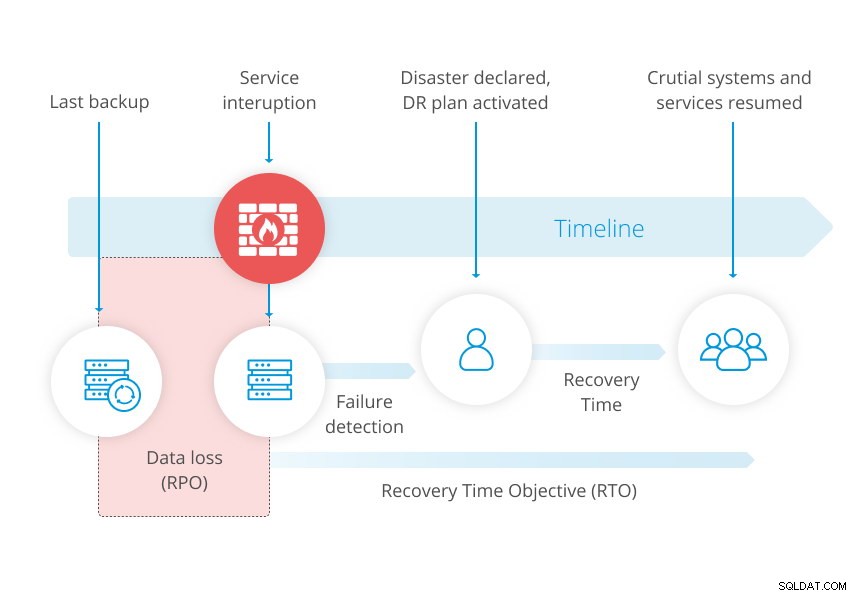
Pro přísnější RPO však záloha nemusí stačit. Při zálohování databáze vlastně pořizujete snímek dat v daném okamžiku. Takže když obnovujete zálohu, zmeškáte změny, ke kterým došlo mezi poslední zálohou a selháním.
Zde přichází na řadu koncept Point In Time Recovery (PITR).
Co je PITR?
Point In Time Recovery (PITR), jak název napovídá, zahrnuje obnovu databáze v jakémkoli daném okamžiku v minulosti. Abychom to mohli udělat, budeme muset obnovit zálohu a poté použít všechny změny, ke kterým došlo po zálohování až do doby těsně před selháním.
Pro PostgreSQL jsou změny uloženy v protokolech WAL (další podrobnosti o WAL a datech, která ukládají, se můžete podívat na tento blog).
Jsou tedy dvě věci, které musíme zajistit, abychom mohli provádět PITR:Zálohy a WAL (musíme pro ně nastavit průběžnou archivaci).
Pro provedení PITR budeme muset obnovit zálohu a poté použít WAL.
Kdy by to mohlo být užitečné?
Tuto strategii můžete použít vždy, když provádíte obnovu z problému, který způsobil poškození dat. Musíte mít na paměti, že se snažíte minimalizovat ztrátu dat, ale existují určité problémy, které mohou způsobit, že data poté již nebudou užitečná.
Některé příklady mohou být neplánované úpravy dat (DML nebo DDL), selhání médií nebo údržba databáze (např. upgrady), které vedou k poškození dat. Nebudete moci obnovit změny dat, ke kterým došlo po problému.
Předpokládejme, že uživatel nesprávně provedl DML, takže data celé tabulky budou nesprávně změněna nebo odstraněna. Můžete provést PITR databáze na samostatném místě a poté exportovat obsah tabulky. Potom můžete tuto tabulku obnovit do existující databáze a efektivně se vrátit zpět ke kopii toho, jak tabulka byla před tím, než k problému došlo.
Samozřejmě není vždy možné tímto způsobem obnovit pouze část databáze, takže v takovém případě budete muset obnovit celou databázi do daného bodu a dojde k minimální, ale nevyhnutelné ztrátě dat (přijdete o jakékoli změny, ke kterým došlo poté, co k problému došlo).
Jak jej používat s ClusterControl?
V předchozím blogu jsme mohli vidět, jak implementovat PITR ručně, nyní se podívejme, jak k provedení tohoto úkolu použít ClusterControl.
Povolení bodové obnovy
Pro aktivaci funkce PITR musíme mít povolenou archivaci WAL. Za tímto účelem můžeme přejít do ClusterControl -> Vybrat PostgreSQL Cluster -> Akce uzlů -> Povolit archivaci WAL, nebo jednoduše přejít do ClusterControl -> Vybrat PostgreSQL Cluster -> Zálohování -> Nastavení a povolit možnost „Povolit obnovu v bodě v čase (WAL Archiving)“, jak uvidíme na následujícím obrázku.
Musíme mít na paměti, že abychom povolili archivaci WAL, musíme restartovat naši databázi. ClusterControl to může udělat i za nás.
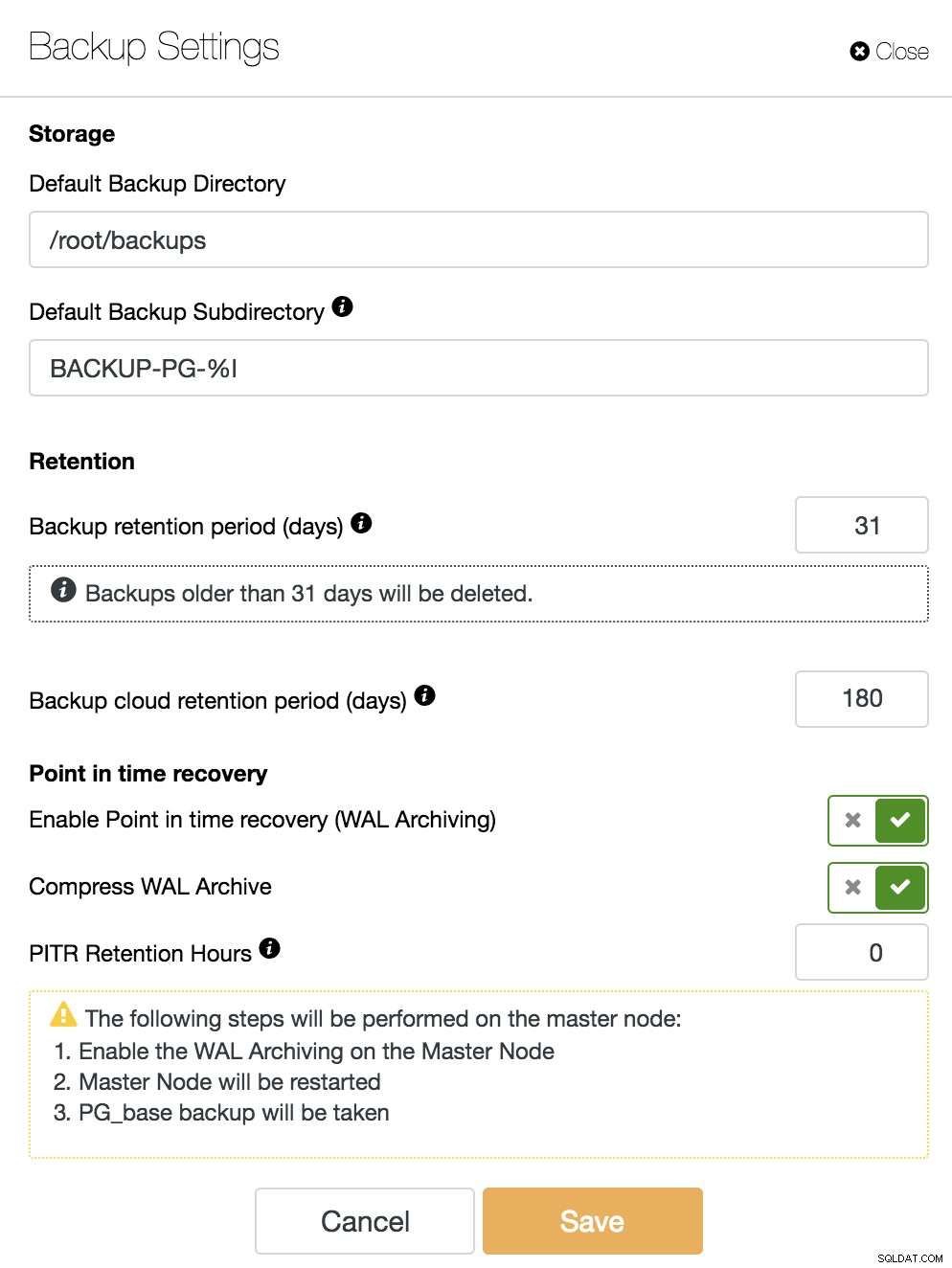
Kromě možností společných pro všechny zálohy, jako je „Adresář záloh“ a „Doba uchování zálohy“, zde můžeme také zadat dobu uchování WAL. Ve výchozím nastavení je 0, což znamená navždy.
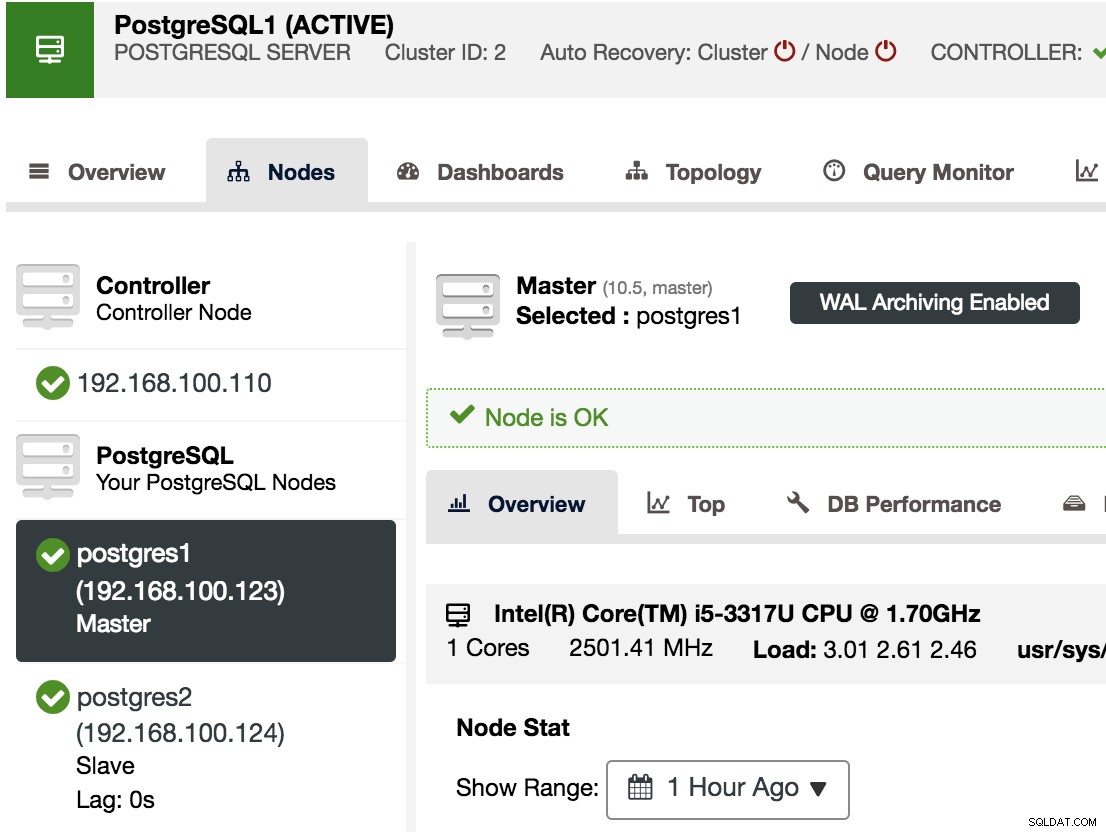
Abychom potvrdili, že máme povolenou archivaci WAL, můžeme vybrat náš hlavní uzel v ClusterControl -> Select PostgreSQL Cluster -> Nodes a měli bychom vidět zprávu WAL Archiving Enabled, jak můžeme vidět na následujícím obrázku.
Vytvoření zálohy kompatibilní s Point In Time Recovery
Po aktivaci archivace WAL, jak jsme viděli v předchozím kroku, můžeme vytvořit naši zálohu kompatibilní s PITR. Chcete-li to provést, přejděte na ClusterControl -> Vyberte klastr PostgreSQL -> Záloha -> Vytvořit zálohu.
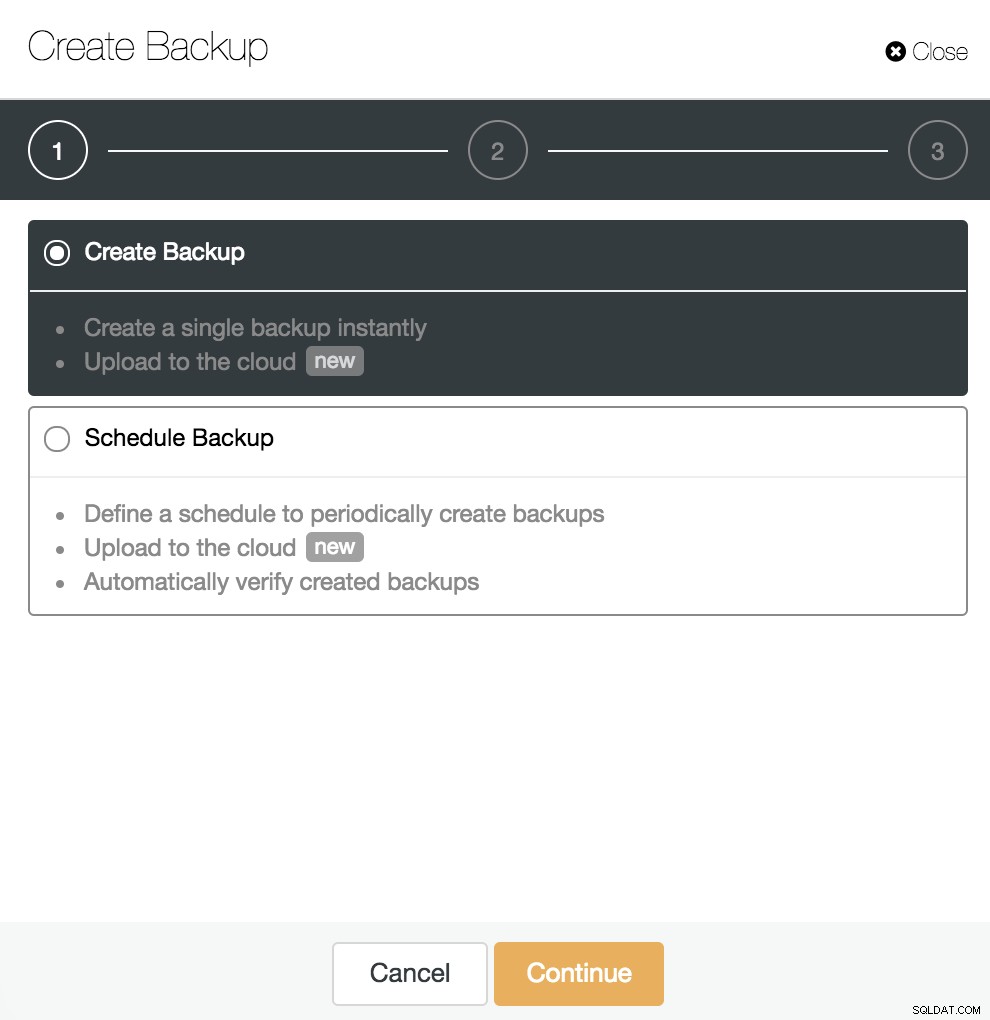
Můžeme vytvořit novou zálohu nebo nakonfigurovat plánovanou. V našem příkladu okamžitě vytvoříme jedinou zálohu.
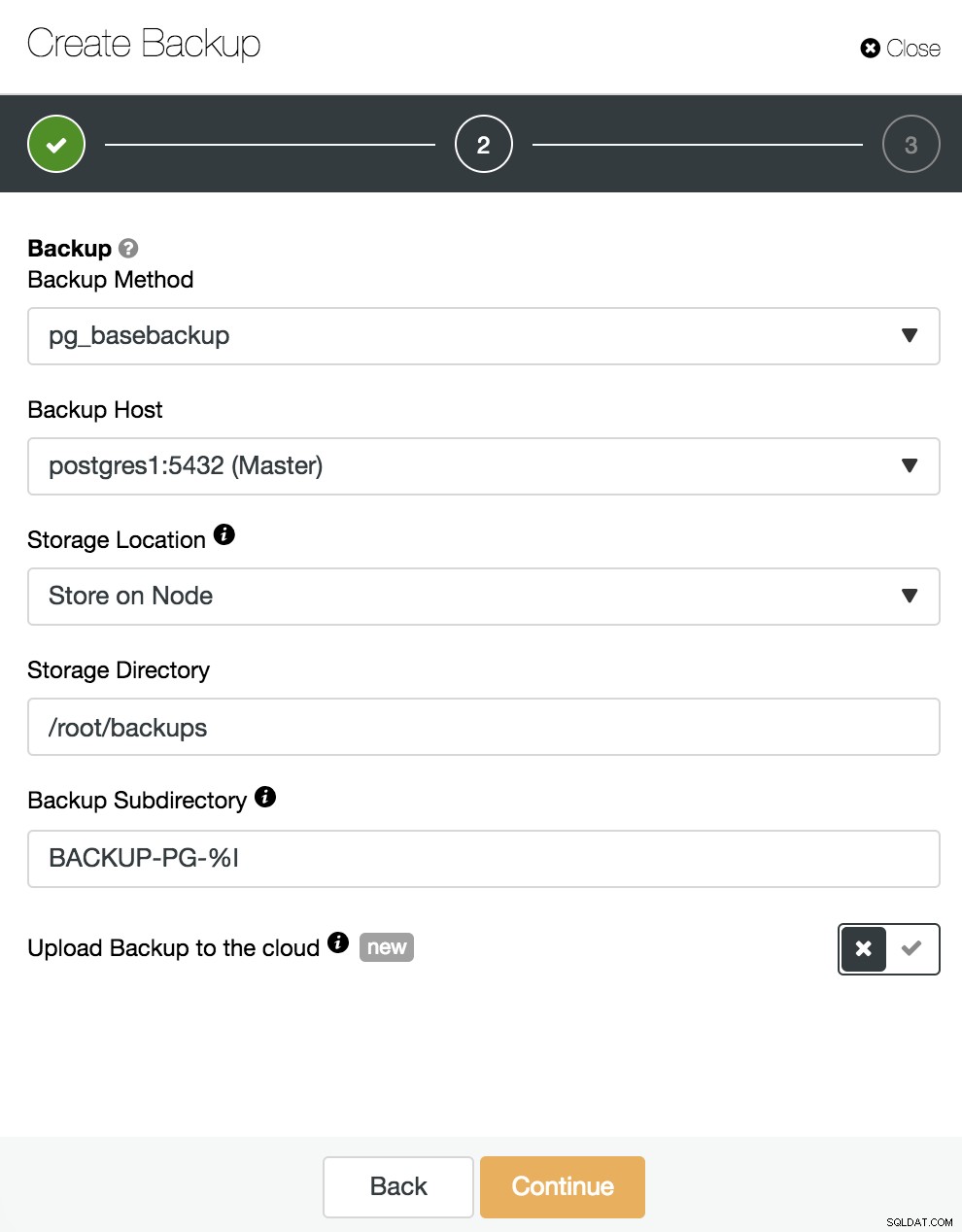
Zde musíme zvolit metodu „pg_basebackup“, kompatibilní s PITR, server, ze kterého se bude záloha brát (aby byla kompatibilní s PITR, musí to být master) a kam chceme zálohu uložit. Můžeme také nahrát naši zálohu do cloudu (AWS, Google nebo Azure) povolením odpovídajícího tlačítka.
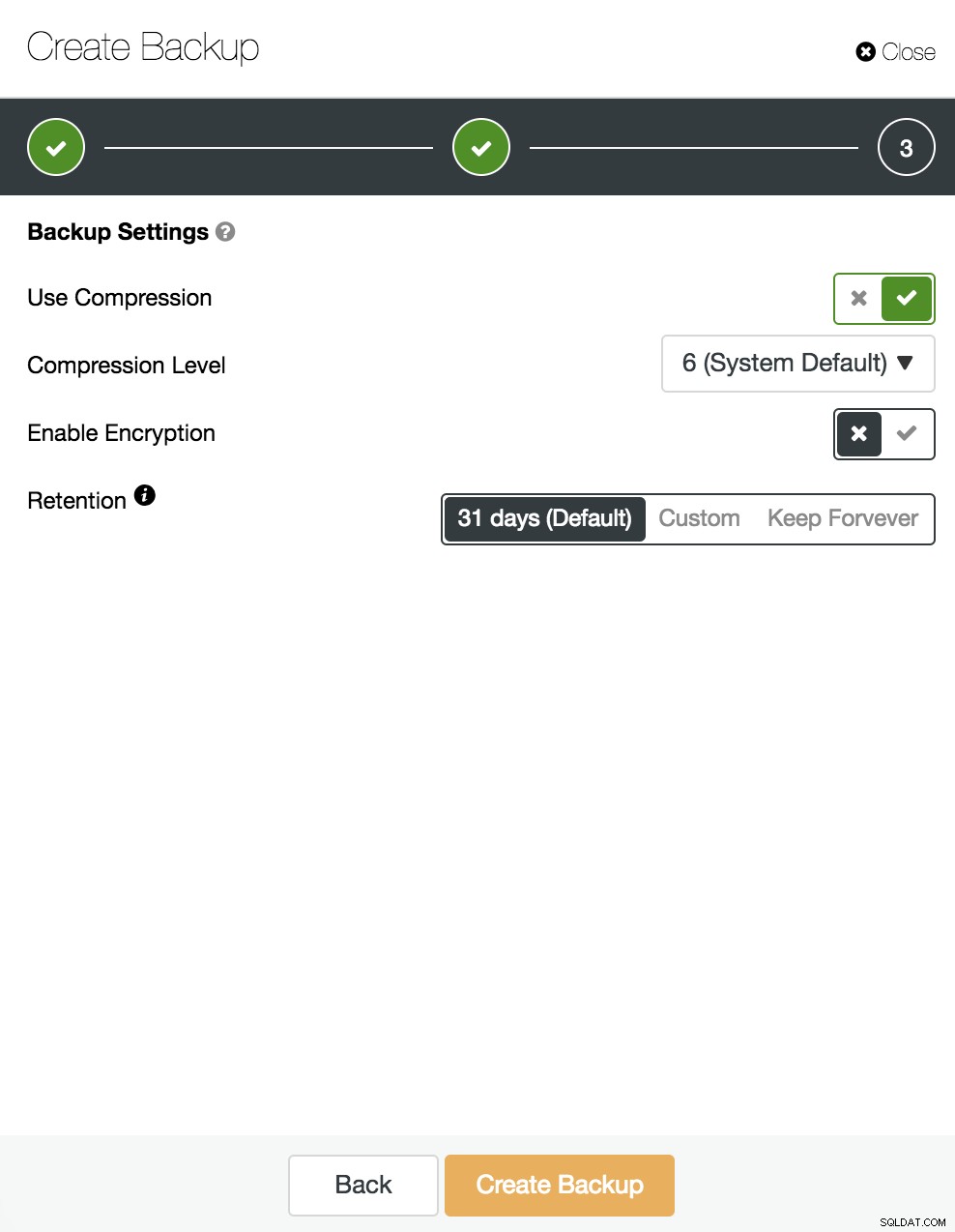
Poté určíme použití komprese, šifrování a uchování naší zálohy.
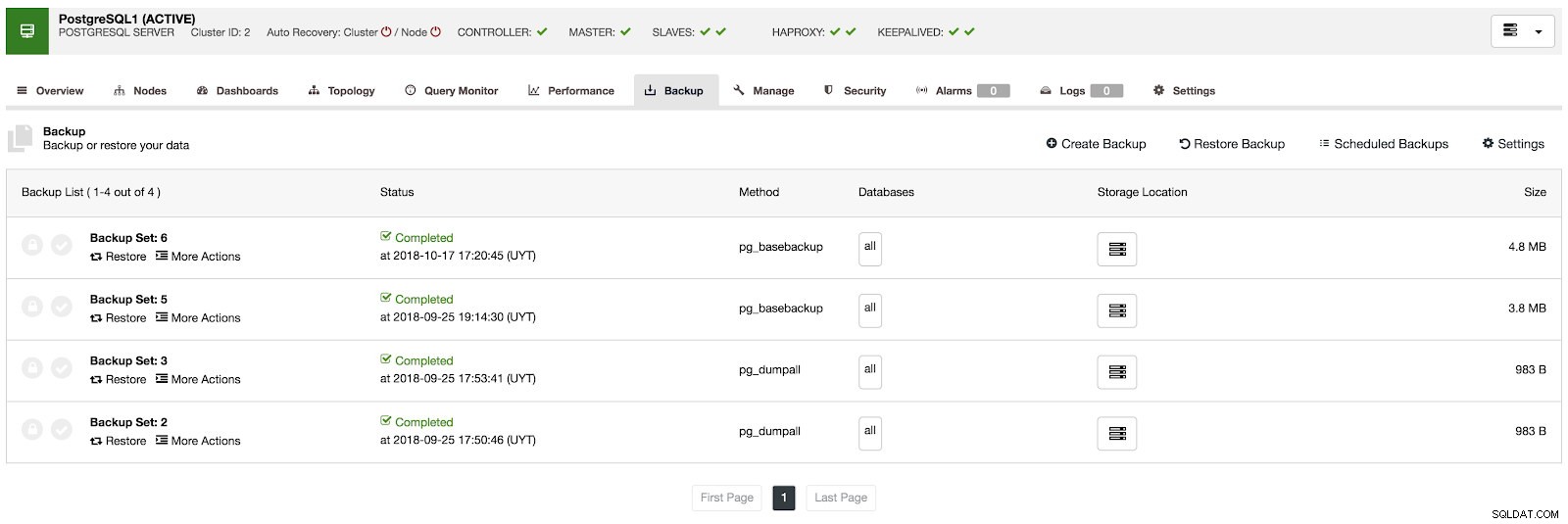
V sekci zálohování můžeme vidět průběh zálohování a informace, jako je metoda, velikost, umístění a další.
Point In Time Recovery ze zálohy
Jakmile je záloha dokončena, můžeme ji obnovit pomocí funkce ClusterControl PITR. K tomu můžeme v naší sekci zálohování (ClusterControl -> Select PostgreSQL Cluster -> Backup) vybrat "Restore Backup" nebo přímo "Restore" na záloze, kterou chceme obnovit.
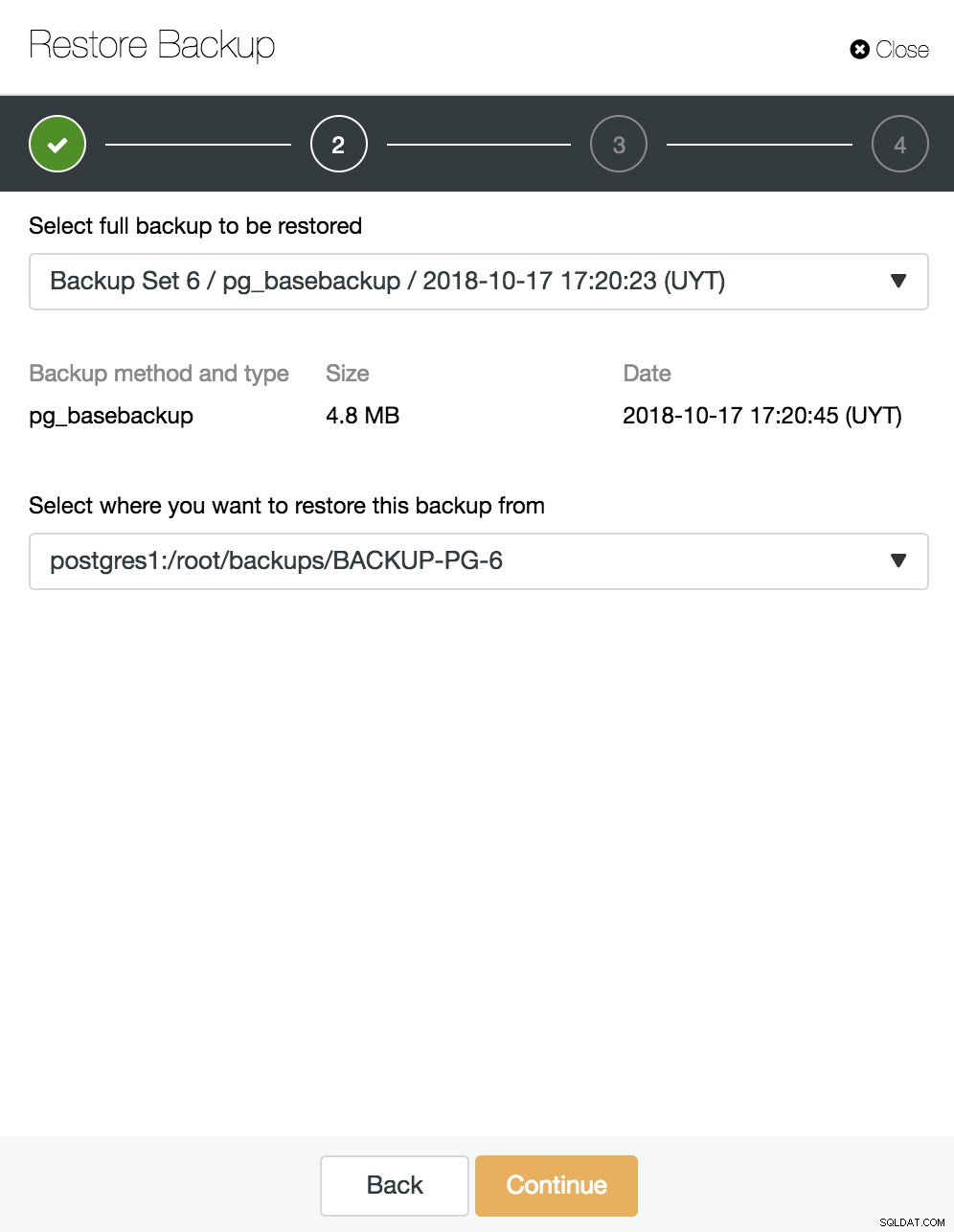
Zde si vybereme, kterou zálohu chceme obnovit a z jakého adresáře.
Necháme vybranou možnost „Obnovit v uzlu“ a pokračujeme.
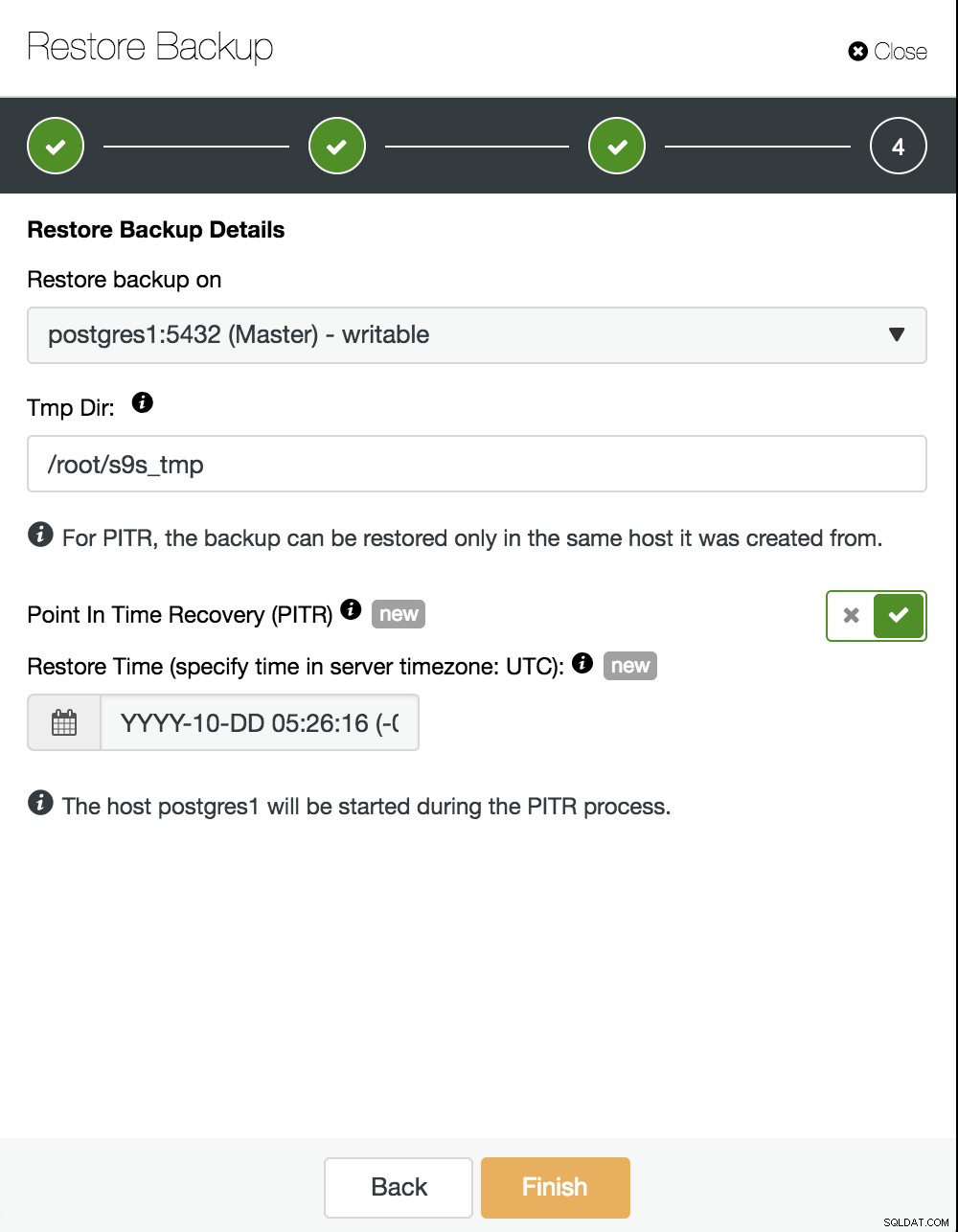
Nyní musíme vybrat, kam obnovit naši zálohu, a povolit možnost PITR. Zadáním času to bude čas, do kdy se zotavíme. Vezměte v úvahu, že se používá časové pásmo UTC a že naše služba PostgreSQL v hlavním serveru bude restartována.
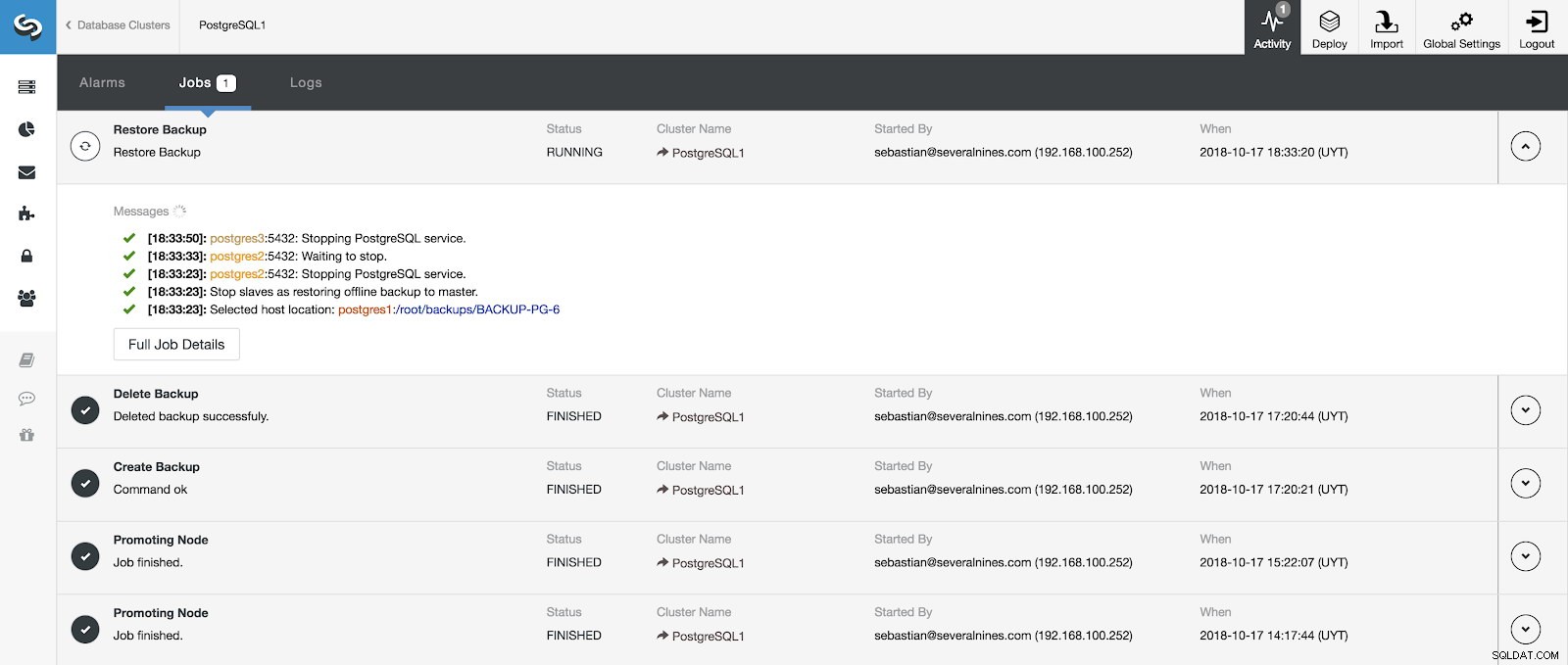
Průběh obnovy můžeme sledovat v sekci Aktivita v našem ClusterControl.
Závěr
PITR je potřebná funkce pro splnění přísného RPO. Musíme jej správně nastavit, abychom zajistili správný plán obnovy po havárii. ClusterControl poskytuje snadno použitelné rozhraní, které vám pomůže implementovat PITR pro vaše databáze PostgreSQL.