Monitorování PostgreSQL může být občas jako snažit se rvát dobytek v bouřce. Aplikace se připojují a zadávají dotazy tak rychle, že je těžké vidět, co se děje, nebo dokonce získat dobrý přehled o výkonu systému, kromě typických požadavků vývojáře, kteří si stěžují „věci jsou pomalé, pomozte!“.
V předchozích článcích jsme diskutovali o tom, jak se dostat ke zdroji, když se PostgreSQL chová pomalu, ale když je zdrojem konkrétně dotazy, základní monitorování nemusí stačit k posouzení toho, co se děje v aktivním živém prostředí.
Zadejte pg_top, program specifický pro PostgreSQL pro monitorování aktivity v databázi v reálném čase a pro zobrazení základních informací o samotném hostiteli databáze. Podobně jako u linuxového příkazu „top“, jeho spuštění přináší uživateli živé interaktivní zobrazení databázové aktivity na hostiteli, které se automaticky obnovuje v intervalech.
Instalace
Instalaci pg_top lze provést obecně očekávanými způsoby:správci balíčků a instalací zdroje. Nejnovější verze tohoto článku je 3.7.0.
Správci balíčků
Na základě distribuce příslušného linuxu vyhledejte ve správci balíčků pgtop nebo pg_top, pravděpodobně je v určitém ohledu k dispozici pro nainstalovanou verzi PostgreSQL v systému.
Distrace založené na Red Hat:
# sudo yum install pg_topDistrace založené na Gentoo:
# sudo apt-get install pgtopZdroj
V případě potřeby lze pg_top nainstalovat ze zdroje z git úložiště PostgreSQL. To poskytne jakoukoli požadovanou verzi, dokonce i novější sestavení, která ještě nejsou v oficiálních verzích.
Funkce
Po instalaci funguje pg_top jako velmi přesný náhled do databáze, kterou monitoruje, v reálném čase a pomocí příkazového řádku ke spuštění „pg_top“ spustíte interaktivní monitorovací nástroj PostgreSQL.
Samotný nástroj může pomoci osvětlit všechny procesy aktuálně připojené k databázi.
Spuštění pg_top
Spuštění pg_top je stejné jako samotný příkaz „top“ ve stylu unix / linux spolu s informacemi o připojení k databázi.
Chcete-li spustit pg_top na hostiteli místní databáze:
pg_top -h localhost -p 5432 -d severalnines -U postgresPro spuštění pg_top na vzdáleném hostiteli je vyžadován příznak -r nebo --remote-mode a na samotném hostiteli je nainstalováno rozšíření pg_proctab:
pg_top -r -h 192.168.1.20 -p 5432 -d severalnines -U postgresCo je na obrazovce
Při spuštění pg_top vidíme displej s poměrně velkým množstvím informací.
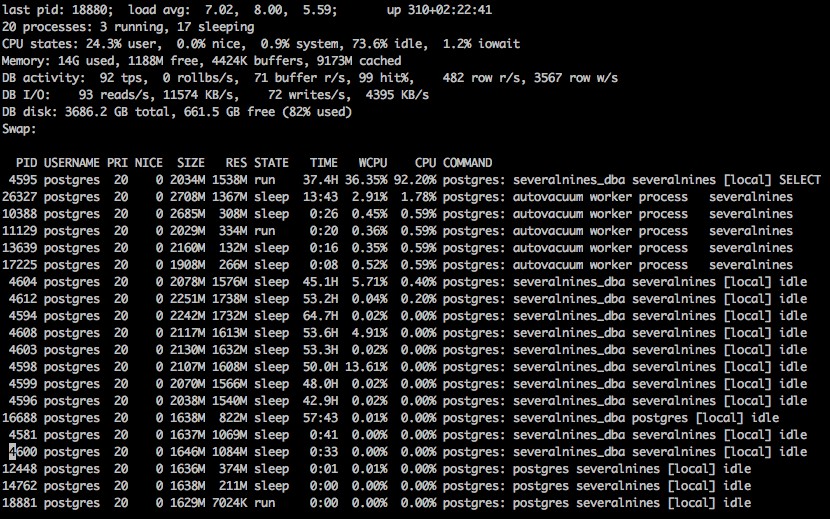 Standardní výstup z pg_top na linuxu
Standardní výstup z pg_top na linuxu
Load Average:
Stejně jako u standardního příkazu top je toto zatížení průměrné pro 1, 5 a 15 minutové intervaly.
Uptime:
Celková doba, po kterou byl systém online od posledního restartu.
Procesy:
Celkový počet připojených databázových procesů s počtem, kolik běží a kolik spí.
Statistiky CPU:
Statistiky CPU, ukazující procentuální zatížení pro uživatele, systém a nečinnost, pěkné informace a také procenta iowait.
Paměť:
Celkové množství použité paměti, volné, ve vyrovnávací paměti a v mezipaměti.
Činnost databáze:
Statistiky aktivity databáze, jako jsou transakce za sekundu, počet návratů za sekundu, vyrovnávací paměti přečtené za sekundu, přístup do vyrovnávací paměti za sekundu, počet přečtených řádků za sekundu a zapsaných řádků za sekundu.
DB I/O Activity:
Činnost pro Input Output v systému, která ukazuje počet čtení a zápisů za sekundu a také množství čtení a zápisu za sekundu.
DB Disk Stats:
Celková velikost databázového disku a také množství volného místa.
Swap:
Informace o použitém odkládacím prostoru, pokud existuje.
Procesy:
Seznam procesů připojených k databázi, včetně všech typů interních procesů autovakuování. Seznam obsahuje pid, prioritu, velikost nice, použitou rezidentní paměť, stav připojení, počet použitých sekund procesoru, procento procesoru a aktuální příkaz, kterým proces běží.
Užitečné interaktivní funkce
V pg_top je několik interaktivních funkcí, ke kterým lze přistupovat, když je spuštěn. Úplný seznam lze nalézt zadáním ?, což vyvolá obrazovku nápovědy se všemi různými dostupnými možnostmi.
Informace o plánovači
E – Plán provádění
Zadání E poskytne výzvu k ID procesu, pro který se má zobrazit plán vysvětlení. To je ekvivalentní spuštění „EXPLAIN
A - EXPLAIN ANALYZE (UPDATE/DELETE safe)
Zadáním A se zobrazí výzva k zadání ID procesu, pro který se má zobrazit plán EXPLAIN ANALYZE. To je ekvivalentní spuštění „EXPLAIN ANALYZE
Informace o procesu
Q – Zobrazit aktuální dotaz procesu
Zadáním Q se zobrazí výzva k zadání ID procesu, pro které se má zobrazit celý dotaz.
I – Zobrazuje statistiky I/O pro každý proces (pouze Linux)
Zadáním I přepnete seznam procesů na zobrazení I/O, kde se každý proces čte, zapisuje atd. na disk.
L – Zobrazuje zámky držené procesem
Zadáním L se zobrazí výzva k zadání ID procesu, pro které se mají zobrazit držené zámky. To bude zahrnovat databázi, tabulku, typ zámku a to, zda byl nebo nebyl zámek udělen. Užitečné při zkoumání dlouho běžících nebo čekajících procesů.
Informace o vztazích
R – Zobrazit statistiky uživatelských tabulek.
Zadáním R zobrazíte statistiky tabulky včetně sekvenčního prohledávání, indexového prohledávání, INSERT, AKTUALIZACE a DELETE, všechny relevantní pro nedávnou aktivitu.
X – Zobrazit statistiky indexu uživatelů
Zadáním X zobrazíte statistiky indexu včetně prohledávání indexu, čtení indexu a načítání indexu, vše relevantní pro nedávnou aktivitu.
Řazení
Řazení zobrazení lze provést pomocí libovolného z následujících znaků.
M - Seřadit podle využití paměti
N - Seřadit podle pid
P - Seřadit podle využití CPU
T - Seřadit podle čas
Následují položky zadané po stisknutí o, které umožňují řazení stránek indexu, tabulky a i/o statu.
o - Zadejte pořadí řazení (cpu, velikost, rozlišení, čas, příkaz)
statistiky indexu (idx_scan, idx_tup_fetch, idx_tup_read)
statistiky tabulky (seq_scan, seq_tup_read, idx_scan, idx_tup_fetch, n_tup_ins, wc, n_tup_ins, n_tup_ins, n_tup_upd, wc, n_tup_upd, ids , idr / syschar /ids , idr / n_t , píše, cwrites, příkaz)
Připojení / manipulace s dotazem
k - zadané zabíjení procesů
Zadáním k se zobrazí výzva k zadání procesu nebo seznamu databázových procesů, které se mají zabít.
r - renice a proces (pouze lokální databáze, pouze root)
Zadáním r se zobrazí výzva k zadání hodnoty nice, po níž následuje seznam procesů, které mají být nastaveny na tuto novou hodnotu nice. Tím se změní priorita důležitých procesů v systému.
Příklad:„renice 1 7004“
Různá použití pg_top
Reaktivní využití pg_top
Obecné použití pro pg_top je interaktivní režim, který nám umožňuje vidět, jaké dotazy běží na systému, který má problémy s pomalostí, spouštět plány vysvětlení na tyto dotazy, přepisovat důležité dotazy, aby byly dokončeny rychleji, nebo zabíjet jakékoli dotazy způsobující velká zpomalení. . Obecně umožňuje správci databáze dělat mnoho ze stejných věcí, které lze v systému provádět ručně, ale rychleji a vše v jedné možnosti.
Proaktivní používání pg_top
I když to není příliš běžné, pg_top lze spustit v „dávkovém režimu“, který zobrazí hlavní diskutované informace na standardní výstup a poté se ukončí. To lze naskriptovat tak, aby se spouštělo v určitých intervalech, a poté odeslat do libovolného požadovaného vlastního procesu, analyzovat a generovat výstrahy na základě toho, na co může chtít být správce upozorněn. Pokud se například zatížení systému příliš zvýší, pokud je hodnota transakcí za sekundu vyšší, než se očekávalo, může kreativní program zjistit cokoli.
Obecně existují další nástroje pro shromažďování a podávání zpráv o těchto informacích, ale mít více možností je vždy dobrá věc a s více dostupnými nástroji lze najít ty nejlepší.
Historické použití pg_top
Podobně jako u předchozího použití, proaktivního použití, můžeme skriptovat pg_top v dávkovém režimu a zaznamenávat snímky toho, jak databáze vypadá v průběhu času. To může být stejně jednoduché jako zápis do textového souboru s časovým razítkem nebo jeho analýza a uložení data do relační databáze za účelem generování sestav. To by umožnilo najít více informací po velkém incidentu, jako je pád databáze ve 4:00. Čím více údajů je k dispozici, tím pravděpodobnější jsou problémy.
Další informace
Dokumentace k projektu je poměrně omezená a většina informací je k dispozici na linuxové manuálové stránce, kterou najdete spuštěním ‚man pg_top‘. Komunita PostgreSQL může pomoci s dotazy nebo problémy prostřednictvím PostgreSQL Mailing Lists nebo oficiální chatovací místnosti IRC na freenode, název kanálu #postgresql.