Monitorování je jedním ze základních úkolů každého systému. Může nám pomoci odhalit problémy a přijmout opatření, nebo jednoduše znát aktuální stav našich systémů. Používání vizuálních displejů nás může učinit efektivnějšími, protože můžeme snadněji odhalit problémy s výkonem.
V tomto blogu uvidíme, jak pomocí SCUMM monitorovat naše PostgreSQL databáze a jaké metriky můžeme pro tento úkol použít. Projdeme si také dostupné dashboardy, takže můžete snadno zjistit, co se skutečně děje s vašimi instancemi PostgreSQL.
Co je SCUMM?
Nejprve se podívejme, co je SCUMM (Severalnines ClusterControl Unified Monitoring and Management).
Je to nové řešení založené na agentech s agenty nainstalovanými na uzlech databáze.
Agenti SCUMM jsou exportéři Prometheus, kteří exportují metriky ze služeb jako PostgreSQL jako metriky Prometheus.
Server Prometheus se používá k seškrabování a ukládání dat časových řad z agentů SCUMM.
Prometheus je open-source sada nástrojů pro monitorování a upozornění systému původně vytvořená na SoundCloud. Nyní je to samostatný open source projekt a je spravován nezávisle.
Prometheus je navržen tak, aby byl spolehlivý, aby byl systémem, na který přejdete během výpadku, a umožní vám rychle diagnostikovat problémy.
Jak používat SCUMM?
Když používáme ClusterControl, když vybereme cluster, můžeme vidět přehled našich databází a také některé základní metriky, které lze použít k identifikaci problému. Na níže uvedeném řídicím panelu můžeme vidět nastavení master-slave s jedním masterem a 2 slave, s HAProxy a Keepalived.
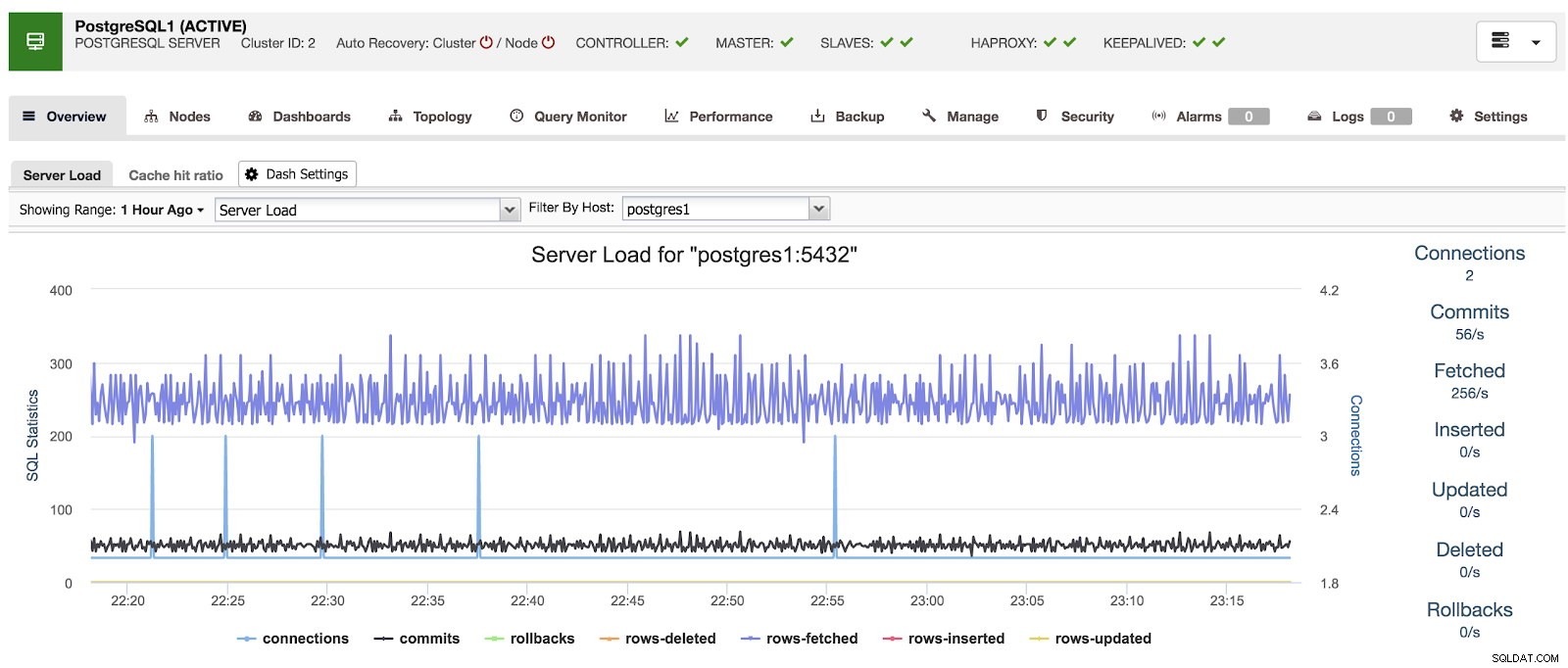 Přehled ClusterControl
Přehled ClusterControl Pokud přejdeme na možnost „Dashboards“, můžeme vidět zprávu jako je následující.
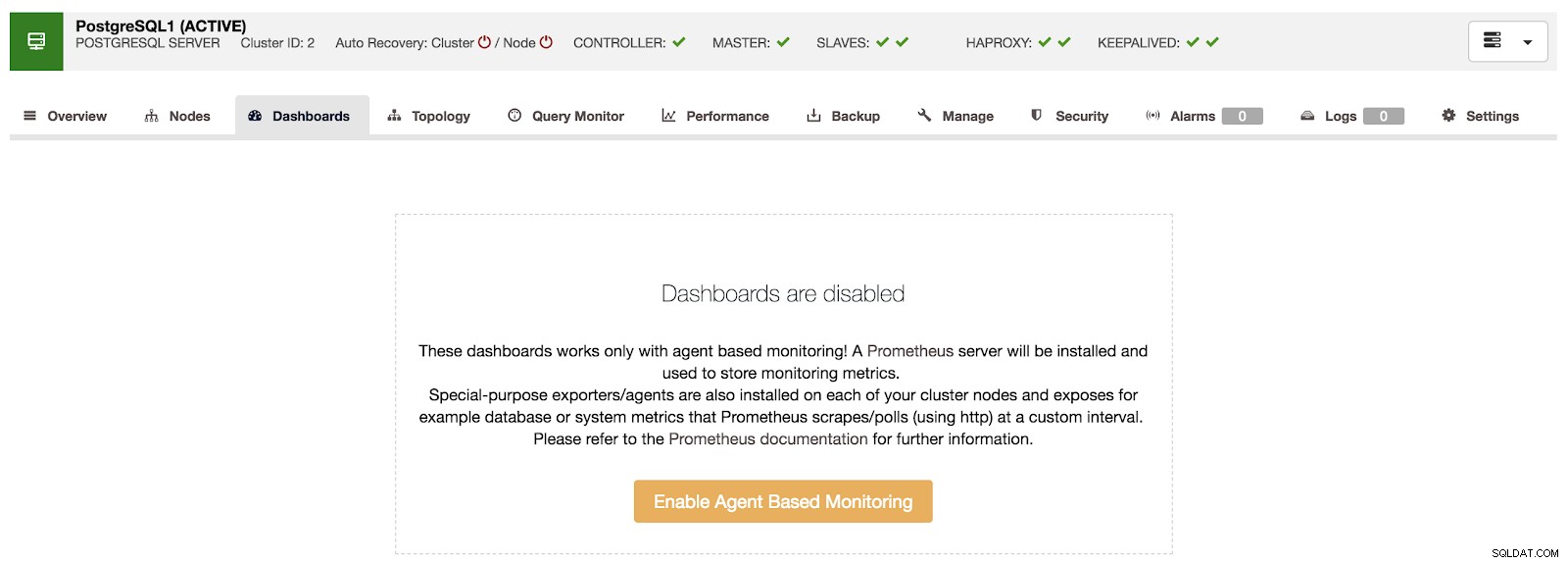 Řídicí panely ClusterControl deaktivovány
Řídicí panely ClusterControl deaktivovány Pro použití této funkce musíme aktivovat výše uvedeného agenta. Za tímto účelem musíme pouze stisknout tlačítko "Povolit monitorování založené na agentech" v této části.
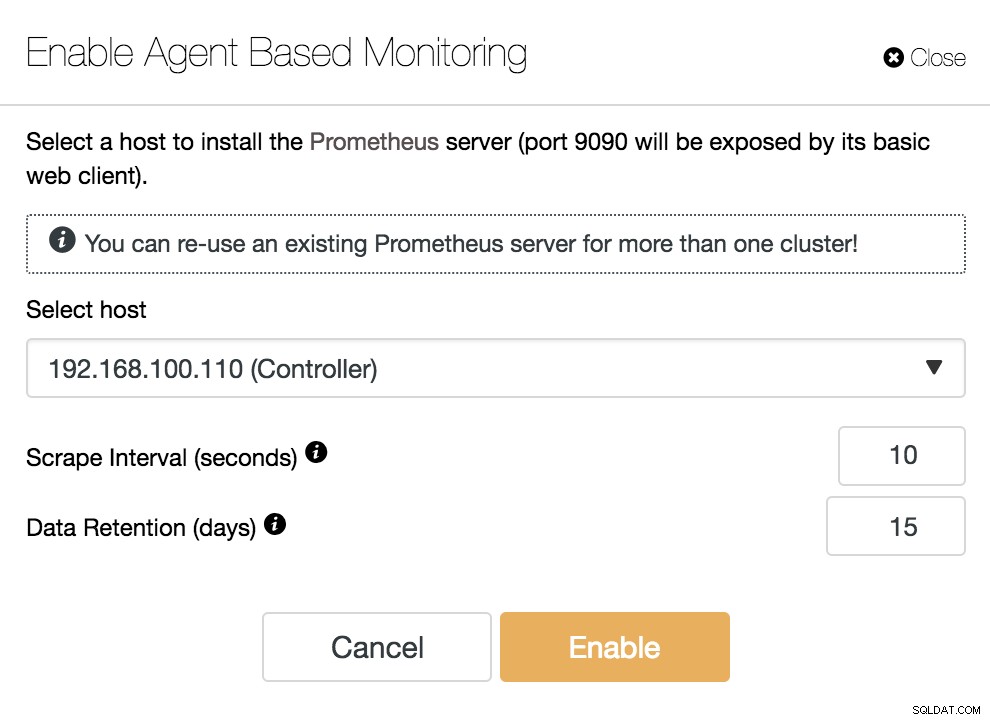 ClusterControl Povolit monitorování založené na agentech
ClusterControl Povolit monitorování založené na agentech Abychom aktivovali našeho agenta, musíme určit hostitele, kam nainstalujeme náš server Prometheus, což, jak vidíme v příkladu, může být náš server ClusterControl.
Musíme také specifikovat:
- Interval seškrabování (v sekundách):Nastavte, jak často jsou uzly zpracovány pro metriky. Výchozí hodnota je 10 sekund.
- Uchovávání údajů (dny):Nastavte, jak dlouho budou metriky uchovávány, než budou odstraněny. Výchozí hodnota je 15 dní.
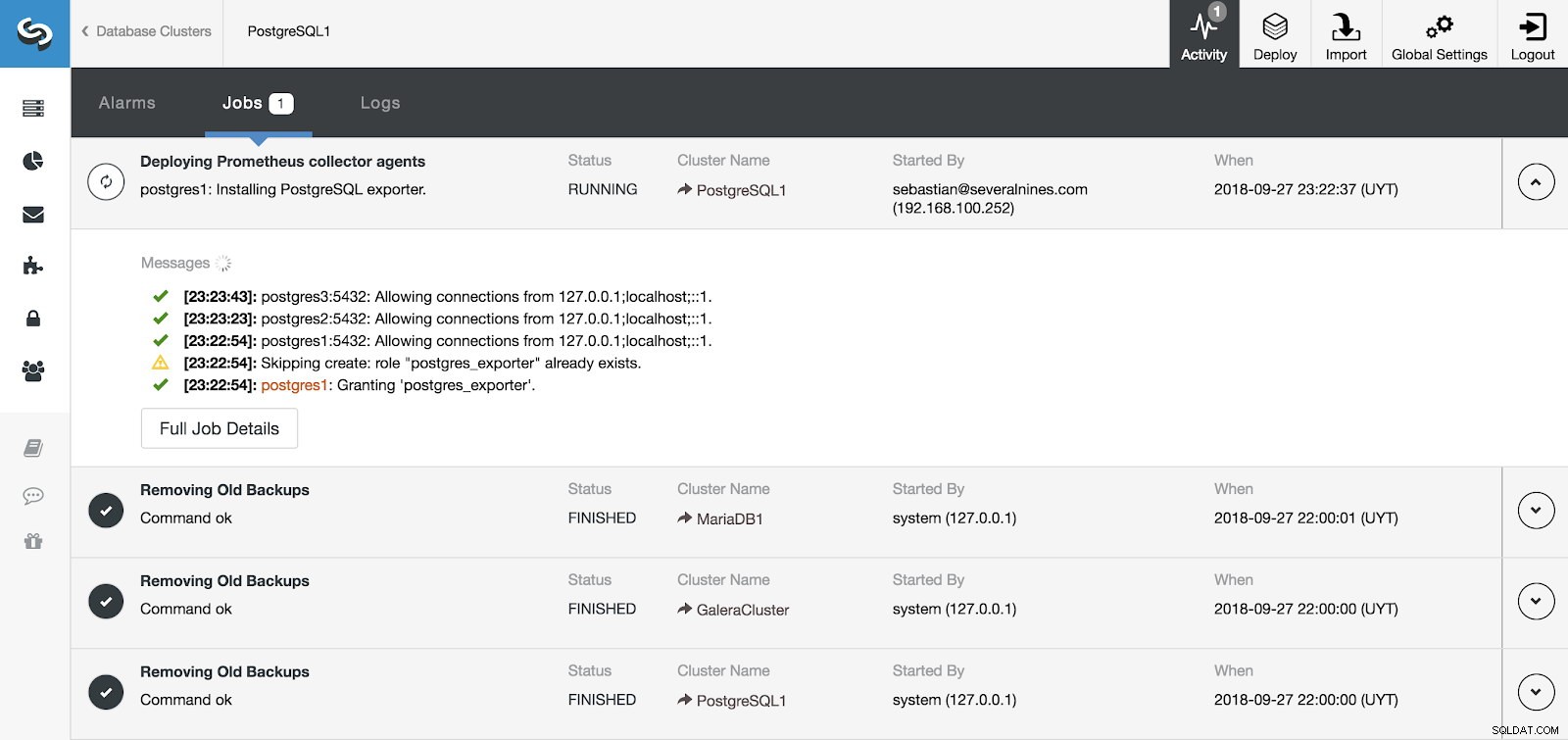 Činnost ClusterControl
Činnost ClusterControl Instalaci našeho serveru a agentů můžeme sledovat ze sekce Aktivita v ClusterControl a po jejím dokončení můžeme vidět náš cluster s aktivovanými agenty z hlavní obrazovky ClusterControl.
 Agenti ClusterControl povoleni
Agenti ClusterControl povoleni Panely
Po aktivaci našich agentů, pokud přejdeme do sekce Dashboards, uvidíme něco takového:
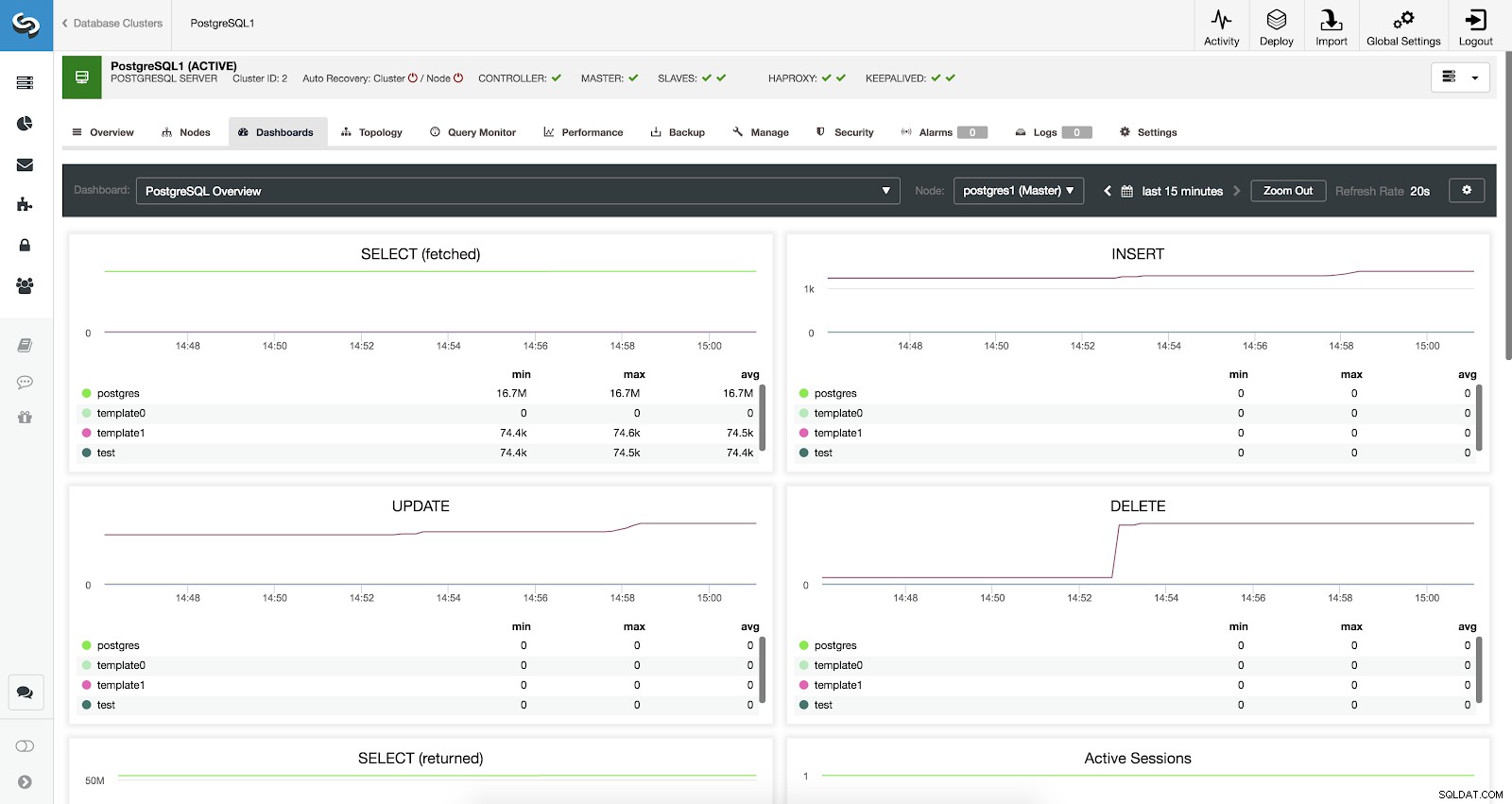 Řídicí panely ClusterControl povoleny
Řídicí panely ClusterControl povoleny Máme k dispozici tři různé druhy dashboardů, System Overview, Cross Server Graphs a PostgreSQL Overview. Poslední je to, co vidíme ve výchozím nastavení při vstupu do této sekce.
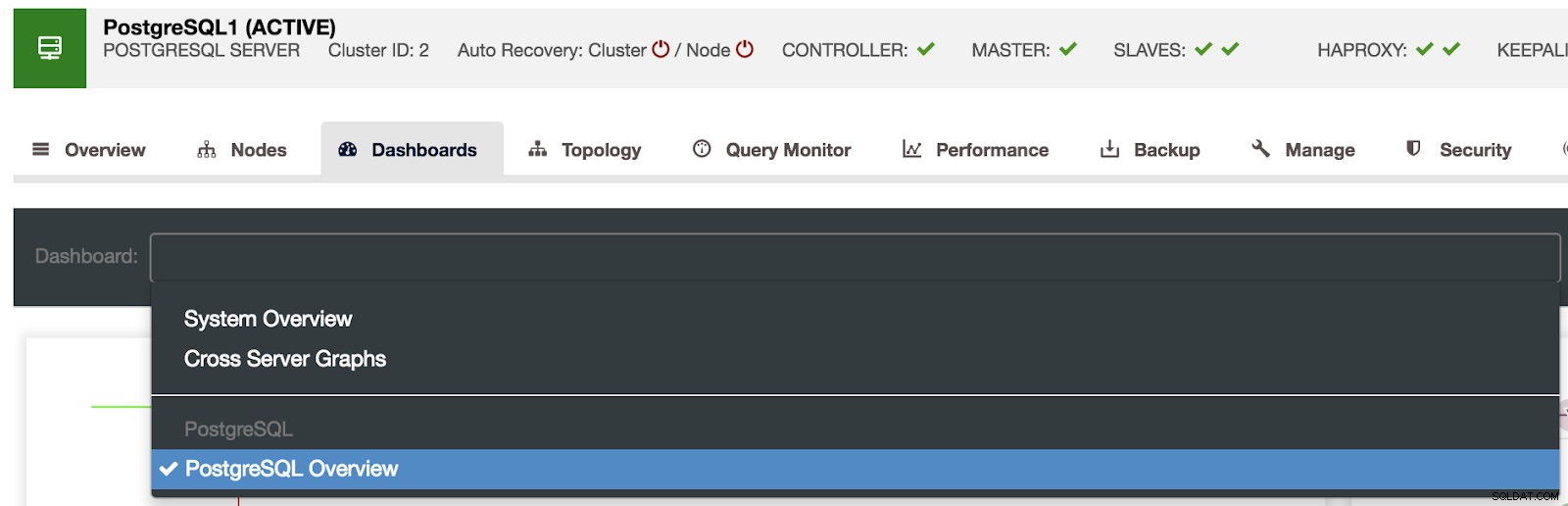 Výběr řídicích panelů ClusterControl
Výběr řídicích panelů ClusterControl Zde můžeme také určit, který uzel se má sledovat, časový rozsah a obnovovací frekvenci.
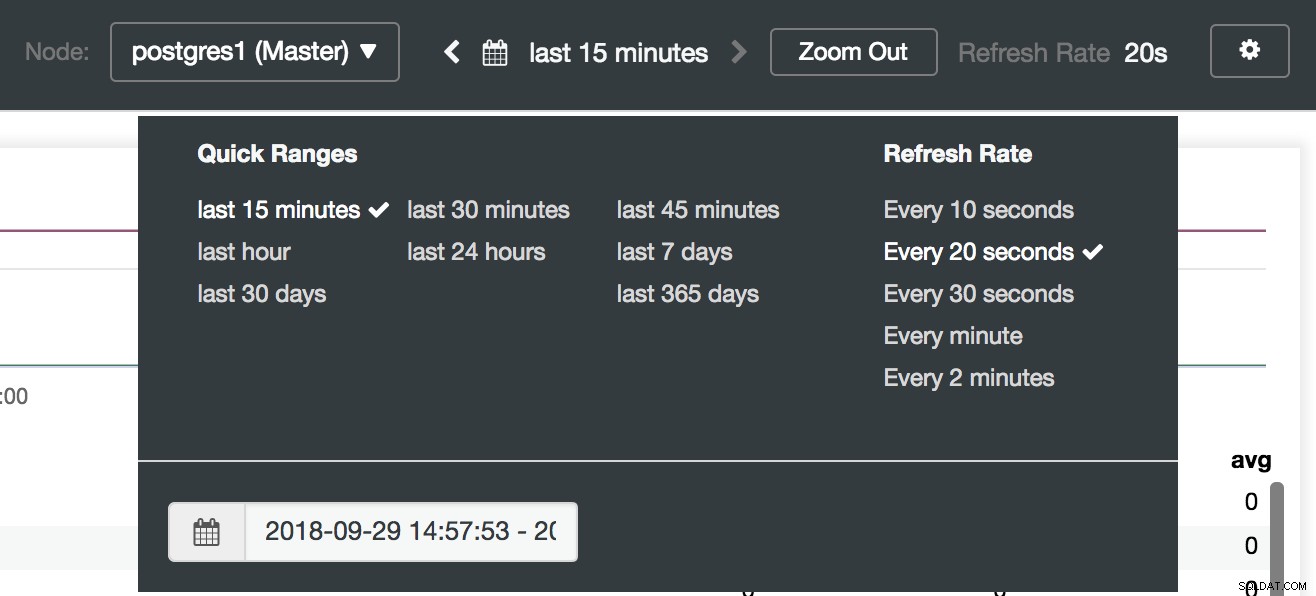 Možnosti panelu ClusterControl
Možnosti panelu ClusterControl V sekci konfigurace můžeme povolit nebo zakázat naše agenty (Exportéry), zkontrolovat stav agentů a ověřit verzi našeho serveru Prometheus.
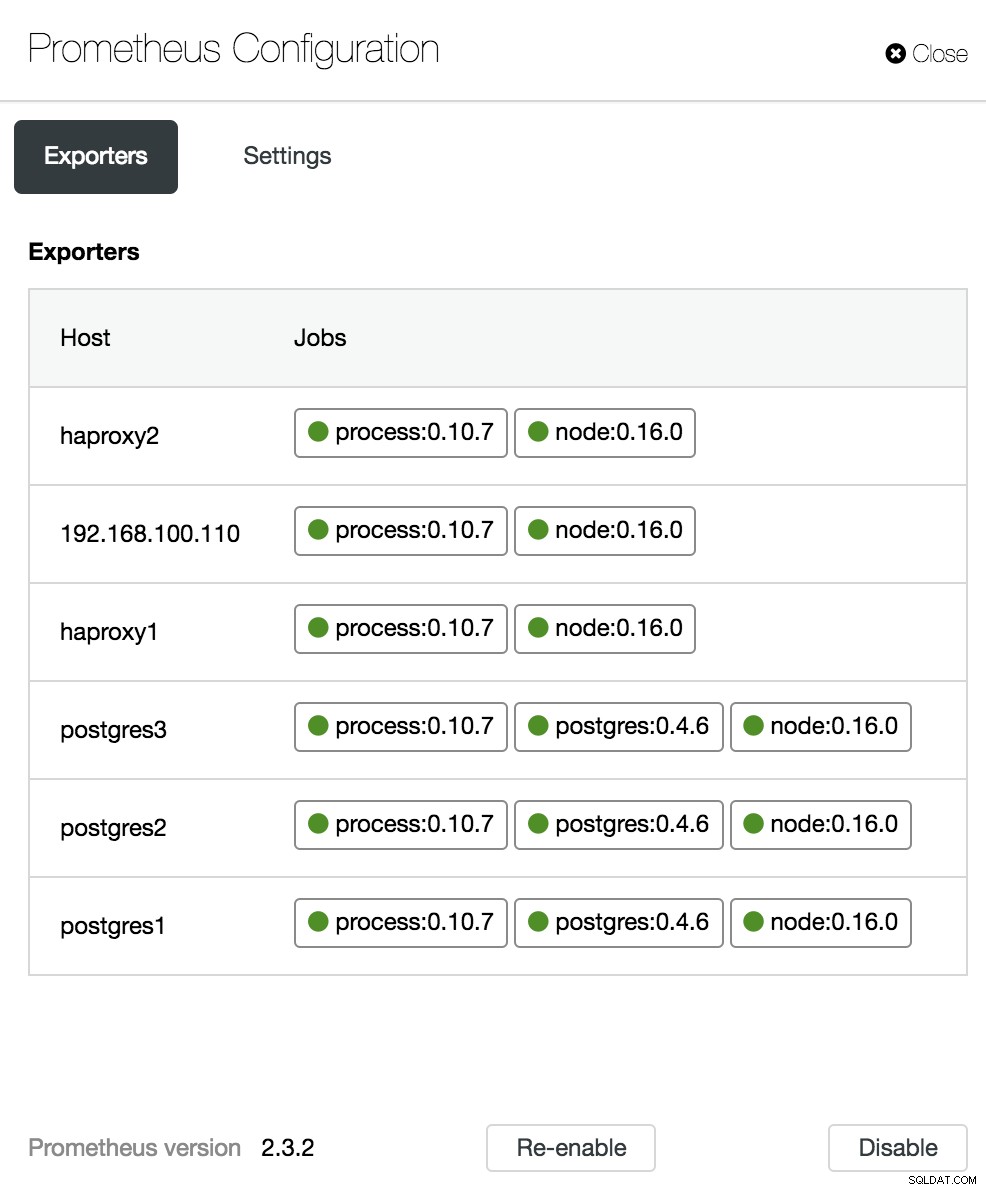 Konfigurace řídicího panelu ClusterControl
Konfigurace řídicího panelu ClusterControl Přehledové metriky PostgreSQL
Pojďme se nyní podívat, jaké metriky máme k dispozici pro každou z našich PostgreSQL databází (všechny pro vybraný uzel).
- SELECT (načteno):Počet řádků vybraných (načtených) pro každou databázi. Načtené řádky odkazují na aktuální řádky načtené z tabulky.
- SELECT (vráceno):Počet vybraných (vrácených) řádků pro každou databázi. Vrácené řádky odkazují na všechny řádky načtené z tabulky, což zahrnuje mrtvé řádky a dosud nepotvrzené řádky (na rozdíl od načtených řádků, které počítají pouze živé n-tice).
- INSERT:Počet řádků vložených pro každou databázi.
- AKTUALIZACE:Počet aktualizovaných řádků pro každou databázi.
- DELETE:Počet smazaných řádků pro každou databázi.
- Aktivní relace:Počet aktivních relací (min., max. a průměr) pro každou databázi.
- Nečinné relace:Počet nečinných relací (min., max. a průměr) pro každou databázi.
- Tabulky zámků:Počet zámků (min., max. a průměr) oddělených podle typu pro každou databázi.
- Využití IO disku:Využití IO disku serveru.
- Využití disku:Procento využití disku serveru (minimální, maximální a průměrné).
- Latence disku:Latence disku serveru.
ClusterControl Přehled PostgreSQL metriky Metriky přehledu systému
Pro sledování našeho systému máme pro každý server k dispozici následující metriky (všechny pro vybraný uzel):
- Doba provozu systému:Doba od spuštění serveru.
- CPU:Počet CPU.
- RAM:Velikost paměti RAM.
- Dostupná paměť:Procento dostupné paměti RAM.
- Průměrné zatížení:Minimální, maximální a průměrné zatížení serveru.
- Paměť:Dostupná, celková a použitá paměť serveru.
- Využití CPU:Informace o minimálním, maximálním a průměrném využití CPU serveru.
- Distribuce paměti:Distribuce paměti (vyrovnávací paměť, mezipaměť, volná a použitá) na vybraném uzlu.
- Metriky saturace:Minimální, maximální a průměrná zátěž IO a CPU ve vybraném uzlu.
- Pokročilé podrobnosti o paměti:Podrobnosti o využití paměti, jako jsou stránky, vyrovnávací paměť a další, ve vybraném uzlu.
- Forky:Počet procesů fork. Fork je operace, při které proces vytváří svou kopii. Obvykle se jedná o systémové volání implementované v jádře.
- Procesy:Množství procesů běžících nebo čekajících v operačním systému.
- Přepínače kontextu:Přepínání kontextu je akce uložení stavu procesu nebo vlákna.
- Přerušení:Počet přerušení. Přerušení je událost, která mění normální tok provádění programu a může být generována hardwarovými zařízeními nebo dokonce samotným CPU.
- Síťový provoz:Příchozí a odchozí síťový provoz v kB za sekundu na vybraném uzlu.
- Využití sítě za hodinu:Provoz odeslaný a přijatý za poslední den.
- Zaměnit:Zaměnit využití (zdarma a použité) na vybraném uzlu.
- Činnost swapu:Čte a zapisuje data na swapu.
- I/O Activity:Vstup a stránkování na IO.
- Deskriptory souborů:Přidělené a limitní deskriptory souborů.
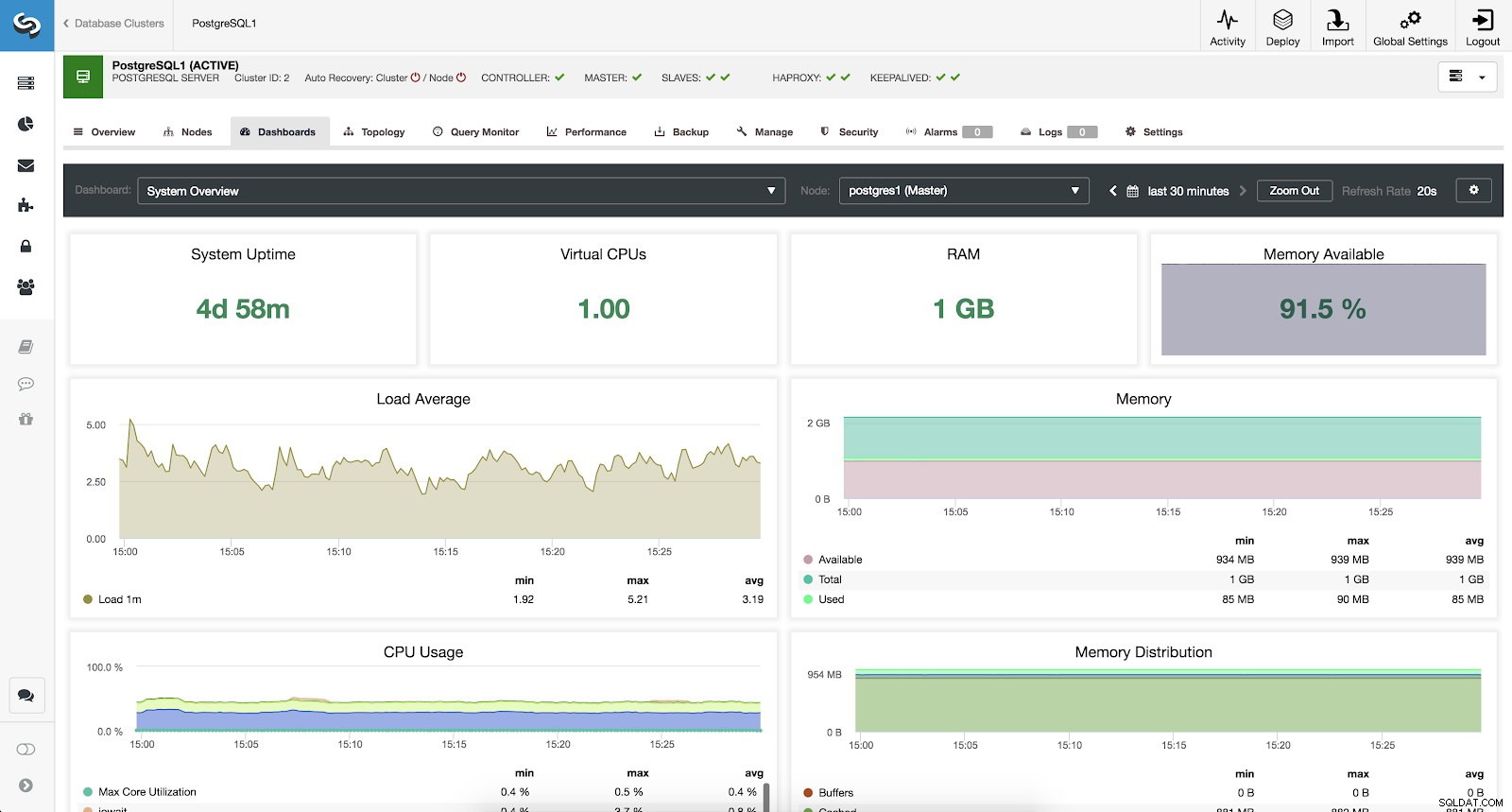 Metriky Přehled systému ClusterControl
Metriky Přehled systému ClusterControl Metriky grafů napříč servery
Pokud chceme vidět obecný stav všech našich serverů, můžeme použít tento řídicí panel s následujícími metrikami:
- Průměrná zátěž:Průměrná zátěž serverů pro každý server.
- Využití paměti:Procento využití paměti pro každý server.
- Síťový provoz:Minimální, maximální a průměrný kB síťového provozu za sekundu.
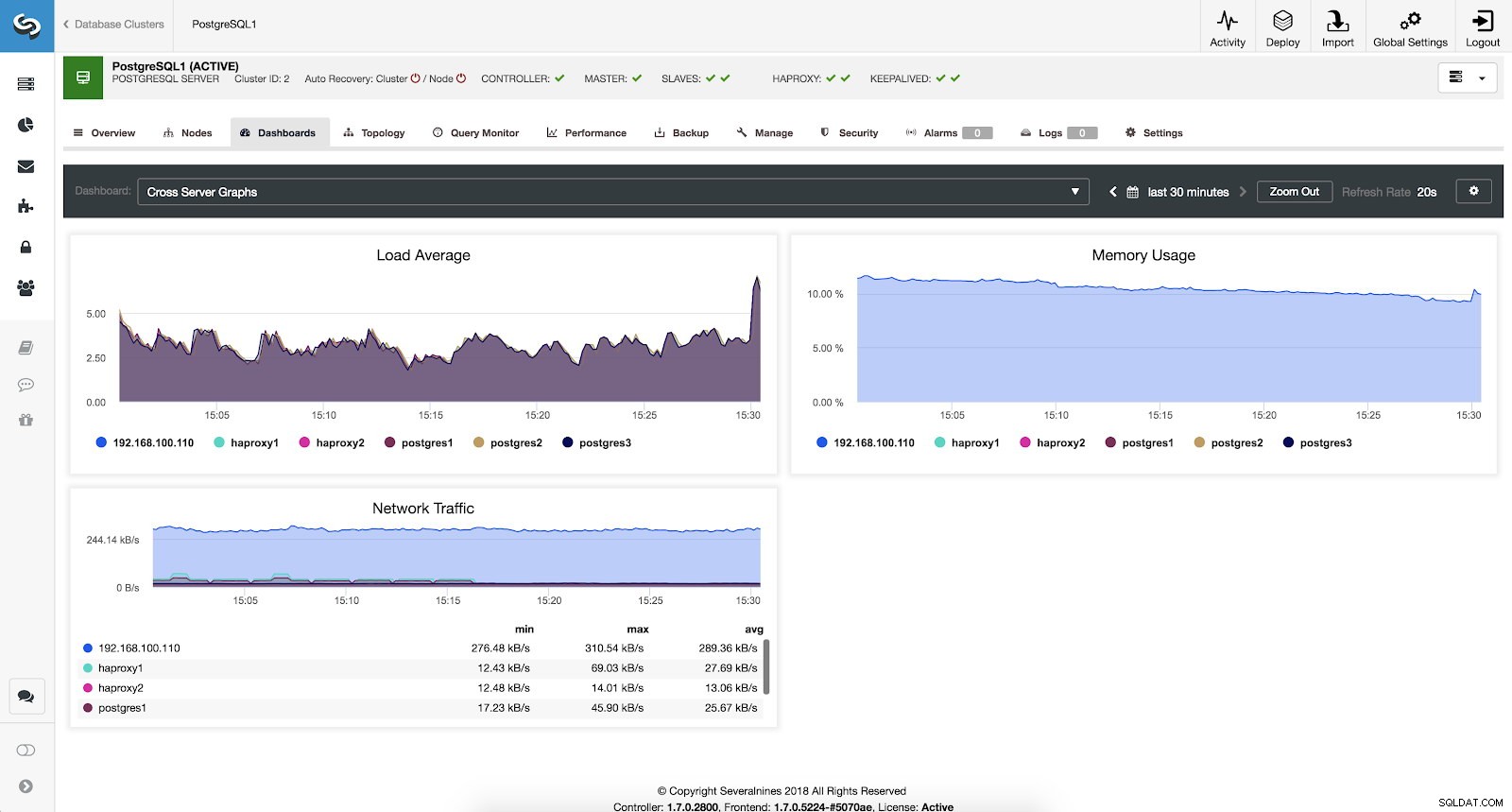 Metriky ClusterControl Cross Server Graphs
Metriky ClusterControl Cross Server Graphs Závěr
Existuje několik způsobů, jak monitorovat PostgreSQL. ClusterControl poskytuje monitorování bez agentů a nyní monitorování založené na agentech prostřednictvím Prometheus. Poskytuje monitorovací data ve vyšším rozlišení a také různé řídicí panely pro pochopení výkonu databáze. ClusterControl lze také integrovat s externími nástroji, jako je Slack nebo PagerDuty pro upozornění.