Toto je první článek ze série článků o In-Memory OLTP. Pomůže vám pochopit, jak nový motor Hekaton interně funguje. Zaměříme se na detaily in-memory optimalizovaných tabulek a indexů. Toto je základní článek, což znamená, že nemusíte být odborníkem na SQL Server, ale musíte mít určité základní znalosti o tradičním stroji SQL Server.
Úvod
Engine SQL Server 2014 In-Memory OLTP (projekt Hekaton) byl vytvořen od samého počátku, aby využíval terabajty dostupné paměti a obrovské množství procesorových jader. In-Memory OLTP umožňuje uživatelům pracovat s tabulkami a indexy optimalizovanými pro paměť a nativně kompilovanými uloženými procedurami. Můžete jej použít spolu s diskovými tabulkami a indexy a uloženými procedurami T-SQL, které SQL Server vždy poskytoval.
Vnitřní části a možnosti in-Memory OLTP enginu se výrazně liší od standardního relačního enginu. Potřebujete zrevidovat téměř vše, co jste věděli o tom, jak se zachází s více souběžnými procesy.
Motor SQL Server je optimalizován pro disková úložiště. Načte 8KB datové stránky do paměti pro zpracování a po úpravách zapíše 8KB datové stránky zpět na disk. SQL Server samozřejmě především opravuje změny na disku v protokolu transakcí. Čtení 8 KB datových stránek z disku a jejich zpětný zápis může generovat velké množství I/O a vede k vyšším nákladům na latenci. I když jsou data ve vyrovnávací paměti, SQL server je navržen tak, aby předpokládal, že tomu tak není, což vede k neefektivnímu využití CPU.
S ohledem na omezení tradičních diskových struktur úložiště začal tým SQL Server budovat databázový stroj optimalizovaný pro velkou hlavní paměť a vícejádrové CPU. Tým si stanovil následující cíle:
- Optimalizováno pro data, která byla zcela uložena v paměti, ale byla odolná i při restartování SQL Server
- Plně integrováno do stávajícího stroje SQL Server
- Velmi vysoký výkon pro operace OLTP
- Navrženo pro moderní CPU
SQL Server In-Memory OLTP splňuje všechny tyto cíle.
O OLTP v paměti
SQL Server 2014 In-Memory OLTP poskytuje řadu technologií pro práci s tabulkami optimalizovanými pro paměť spolu s tabulkami na disku. Umožňuje vám například přistupovat k datům v paměti pomocí standardních rozhraní, jako jsou T-SQL a SSMS. Následující obrázek ukazuje tabulky a indexy optimalizované pro paměť jako součást In-Memory OLTP (vlevo) a diskové tabulky (vlevo), které vyžadují čtení a zápis datových stránek o velikosti 8 kB. In-Memory OLTP také podporuje nativně kompilované uložené procedury a poskytuje nový in-memory OLTP kompilátor.
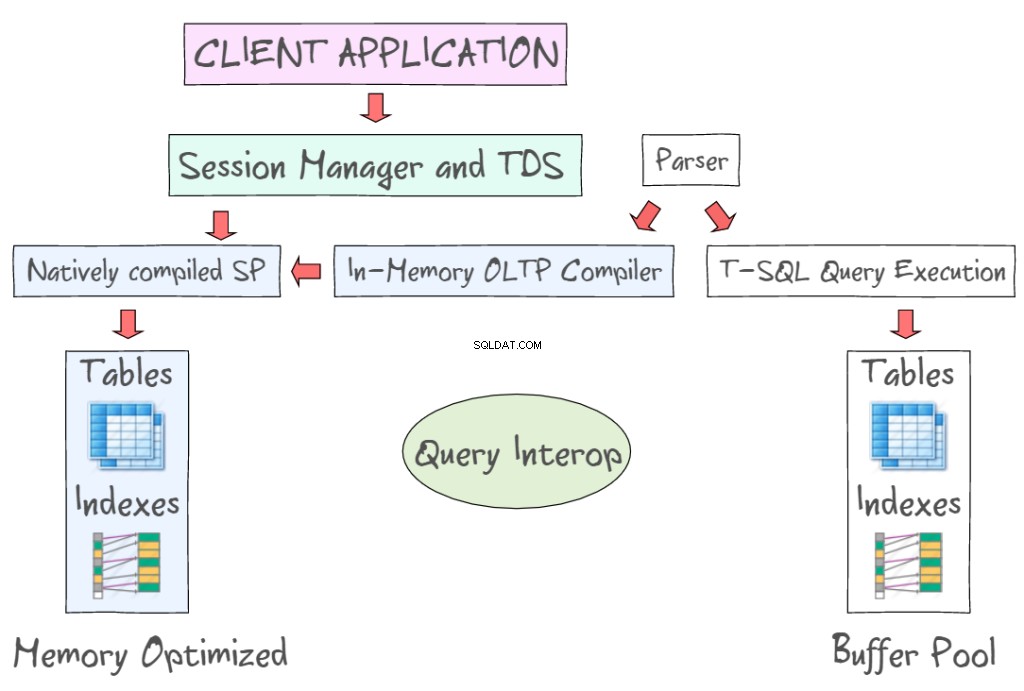
Query Interop umožňuje interpretaci T-SQL tak, aby odkazovala na tabulky optimalizované pro paměť. Pokud transakce odkazuje jak na tabulky optimalizované pro paměť, tak na tabulky založené na disku, lze ji označit jako transakci mezi kontejnery. Klientská aplikace využívá Tabular Data Stream – protokol aplikační vrstvy používaný k přenosu dat mezi databázovým serverem a klientem. Původně byl navržen a vyvinut společností Sybase Inc. pro jejich relační databázový stroj Sybase SQL Server v roce 1984 a později společností Microsoft v Microsoft SQL Server.
Tabulky optimalizované pro paměť
Při přístupu k tabulkám na disku mohou být požadovaná data již v paměti, i když tomu tak nemusí být. Pokud data nejsou v paměti, SQL Server je potřebuje načíst z disku. Nejzásadnějším rozdílem při používání tabulek optimalizovaných pro paměť je to, že celá tabulka a její indexy jsou neustále uloženy v paměti . Souběžné datové operace nevyžadují žádné zamykání nebo blokování.
Zatímco uživatel upravuje data v paměti, SQL Server provádí určité vstupy a výstupy na disku pro jakoukoli tabulku, která musí být odolná, jinak řečeno tam, kde potřebujeme, aby tabulka uchovala data v paměti v době selhání nebo restartu serveru.
Řádková struktura úložiště
Dalším významným rozdílem je základní skladovací struktura. Tabulky založené na disku jsou optimalizovány pro adresovatelnost bloků diskové úložiště, zatímco tabulky optimalizované v paměti jsou optimalizovány pro bajtově adresovatelné úložiště paměti.
SQL Server uchovává datové řádky na 8K datových stránkách s alokací místa z oblastí pro tabulky na disku. Datová stránka je základní jednotkou diskového a paměťového úložiště. Při čtení a zápisu dat z disku SQL Server čte a zapisuje pouze relevantní datové stránky. Datová stránka bude obsahovat pouze data z jedné tabulky nebo indexu. Aplikační procesy podle potřeby upravují řádky na různých datových stránkách. Později během operace CHECKPOINT SQL Server nejprve opraví záznamy protokolu na disk a poté zapíše všechny špinavé stránky na disk. Tato operace často způsobuje mnoho náhodných fyzických I/O.
U tabulek optimalizovaných pro paměť neexistují žádné datové stránky ani žádné rozsahy. Do paměti se zapisují pouze datové řádky sekvenčně v pořadí, v jakém transakce proběhly. Každý řádek obsahuje ukazatel indexu na další řádek. Všechny I/O jsou skenování těchto struktur v paměti. Neexistuje žádná představa o zapisování datových řádků do konkrétního umístění, které patří zadanému objektu. Nemusíte si však myslet, že tabulky optimalizované pro paměť jsou uloženy jako neuspořádaná sada datových řádků (podobně jako haldy na disku). Každý příkaz CREATE TABLE pro tabulku optimalizovanou pro paměť vytváří alespoň jeden index, který SQL Server používá k propojení všech datových řádků v této tabulce.
Každý jednotlivý datový řádek se skládá ze záhlaví řádku a užitečného zatížení, což jsou skutečná data sloupce. V záhlaví jsou uloženy informace o příkazu, který vytvořil řádek, ukazatele pro každý index v cílové tabulce a hodnoty časového razítka. Časové razítko označuje čas, kdy transakce vložila a odstranila řádek. Záznamy SQL Server byly aktualizovány vložením nové verze řádku a označením staré verze jako odstraněné. V danou chvíli může existovat několik verzí stejného řádku. To umožňuje současný přístup ke stejnému řádku během úpravy dat. SQL Server zobrazuje verzi řádku relevantní pro každou transakci podle času zahájení transakce vzhledem k časovým razítkům verze řádku. Toto je jádro nového řízení souběžnosti více verzí mechanismus pro tabulky v paměti.
Mimochodem, Oracle má vynikající systém řízení více verzí. V zásadě to funguje následovně:
- Uživatel A zahájí transakci a aktualizuje 1000 řádků s nějakou hodnotou v čase T1.
- Uživatel B čte stejných 1000 řádků v čase T2.
- Uživatel A aktualizuje řádek 565 hodnotou Y (původní hodnota byla X).
- Uživatel B se dostane na řádek 565 a zjistí, že transakce je v provozu od času T1.
- Databáze vrací neupravený záznam z protokolů. Vrácená hodnota je hodnota, která byla potvrzena v době menší nebo rovna T2.
- Pokud záznam nelze načíst z opakovaných protokolů, znamená to, že databáze není správně nastavena. Protokolům je třeba přidělit více místa.
- Vrácené výsledky jsou vždy stejné s ohledem na čas zahájení transakce. V rámci transakce je tedy dosaženo konzistence čtení.
Nativně zkompilované tabulky
Posledním hlavním rozdílem je, že tabulky optimalizované v paměti jsou nativně kompilovány . Když uživatel vytvoří tabulku nebo index optimalizovanou pro paměť, SQL Server uloží strukturu každé tabulky (spolu se všemi indexy) do metadat. Později SQL Server využívá tato metadata ke kompilaci sady rutin v nativním jazyce pro přístup k tabulce do DDL. Takové DDL jsou spojeny s databází, ale nejsou ve skutečnosti její součástí.
Jinými slovy, SQL Server uchovává v paměti nejen tabulky a indexy, ale také DDL pro přístup a úpravu těchto struktur. Jakmile byla tabulka změněna, SQL Server potřebuje znovu vytvořit všechny DDL pro operace s tabulkami. Proto již vytvořenou tabulku nelze změnit. Tyto operace jsou pro uživatele neviditelné.
Nativně zkompilované uložené procedury
Nejlepšího výkonu je dosaženo při použití nativně kompilovaných uložených procedur pro přístup k nativně kompilovaným tabulkám. Takové procedury obsahují instrukce procesoru a mohou být prováděny přímo CPU bez další kompilace. Existují však určitá omezení týkající se konstrukcí T-SQL pro nativně kompilované uložené procedury (ve srovnání s tradičně interpretovaným kódem). Dalším významným bodem je, že nativně kompilované uložené procedury mohou přistupovat pouze k tabulkám optimalizovaným pro paměť.
Žádné zámky
In-Memory OLTP je systém bez zámku. To je možné, protože SQL Server nikdy neupravuje žádný existující řádek. Operace UPDATE vytvoří novou verzi a označí předchozí verzi jako smazanou. Poté vloží novou verzi řádku s novými daty.
Indexy
Jak jste možná uhodli, indexy se velmi liší od tradičních. Tabulky optimalizované v paměti nemají žádné stránky. SQL Server využívá indexy k propojení všech řádků, které patří do tabulky, do jediné struktury. Nemůžeme použít příkaz CREATE INDEX k vytvoření indexu pro tabulku optimalizovanou v paměti. Jakmile vytvoříte PRIMARY KEY ve sloupci, SQL Server automaticky vytvoří jedinečný index pro tento sloupec. Ve skutečnosti je to jediný povolený jedinečný index. V tabulce optimalizované pro paměť můžete vytvořit maximálně osm indexů.
Analogicky s tabulkami uchovává SQL Server indexy optimalizované pro paměť v paměti. SQL Server však nikdy nezaznamenává operace na indexech. SQL Server automaticky udržuje indexy během úprav tabulek.
Tabulky optimalizované pro paměť podporují dva typy indexů:hash index a index rozsahu . Obě jsou neshlukované struktury.
Hash index je nový typ indexu, navržený speciálně pro tabulky optimalizované pro paměť. Je to mimořádně užitečné pro provádění vyhledávání konkrétních hodnot. Samotný index je uložen jako hashovací tabulka. Jedná se o pole hashových segmentů, kde každý segment je ukazatelem na jeden řádek.
Index rozsahu (non-clustered) je užitečné pro získávání rozsahů hodnot.
Obnovení
Základní mechanismus obnovy pro databázi s tabulkami optimalizovanými pro paměť je stejný jako mechanismus obnovy databází s tabulkami na disku. Obnova tabulek s optimalizovanou pamětí však zahrnuje krok načtení tabulek s optimalizovanou pamětí do paměti předtím, než je databáze dostupná pro uživatele.
Když se SQL Server restartuje, každá databáze projde následujícími fázemi procesu obnovy:analýza , zopakovat a vrátit zpět .
Ve fázi analýzy stroj In-Memory OLTP identifikuje inventář kontrolních bodů, který se má načíst, a předběžně načte záznamy protokolu systémové tabulky. Zpracuje také některé záznamy protokolu alokace souborů.
Ve fázi opakování se do paměti načtou data z párů dat a delta souborů. Poté se aktualizují data z aktivního protokolu transakcí na základě posledního trvalého kontrolního bodu a vyplní se tabulky v paměti a znovu sestaví indexy. Během této fáze souběžně probíhá obnova tabulek na základě disku a paměti optimalizovaná.
Fáze zpět není potřeba u tabulek s optimalizovanou pamětí, protože In-Memory OLTP nezaznamenává žádné nepotvrzené transakce pro tabulky s optimalizovanou pamětí.
Po dokončení všech operací je databáze dostupná pro přístup.
Shrnutí
V tomto článku jsme se rychle podívali na modul SQL Server In-Memory OLTP. Naučili jsme se, že struktury optimalizované pro paměť jsou uloženy v paměti. Aplikační procesy mohou najít požadovaná data přístupem k těmto strukturám v paměti bez potřeby diskových I/O. V následujících článcích se podíváme na to, jak vytvářet a přistupovat k databázím a tabulkám In-Memory OLTP.
Další čtení
In-Memory OLTP:Co je nového v SQL Server 2016
Použití indexů v tabulkách s optimalizovanou pamětí serveru SQL