Mít referenční tabulky v databázi není žádný velký problém, že? Pro každý typ reference stačí propojit kód nebo ID s popisem. Ale co když máte doslova desítky a desítky referenčních tabulek? Existuje alternativa k přístupu jedné tabulky na typ? Čtěte dále a objevte obecné a rozšiřitelné návrh databáze pro zpracování všech vašich referenčních dat.
Tento neobvykle vypadající diagram je pohledem z ptačí perspektivy na logický datový model (LDM) obsahující všechny referenční typy pro podnikový systém. Pochází od vzdělávací instituce, ale může se vztahovat na datový model jakékoli organizace. Čím větší model, tím více typů referencí pravděpodobně objevíte.
Referenčními typy mám na mysli referenční data nebo vyhledávací hodnoty nebo – chcete-li flash – taxonomie . Zde definované hodnoty se obvykle používají v rozevíracích seznamech v uživatelském rozhraní vaší aplikace. Mohou se také objevit jako nadpisy v přehledu.
Tento konkrétní datový model měl asi 100 referenčních typů. Pojďme si to přiblížit a podívat se jen na dva z nich.
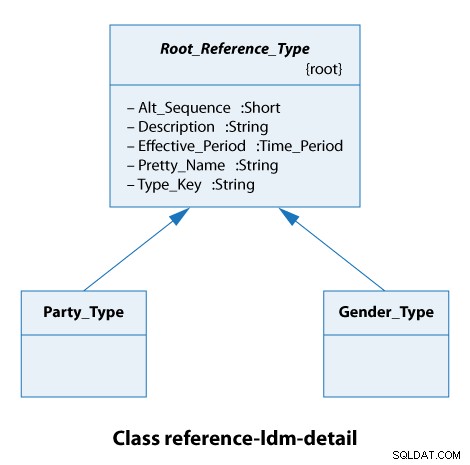
Z tohoto diagramu tříd vidíme, že všechny referenční typy rozšiřují Root_Reference_Type . V praxi to znamená, že všechny naše referenční typy mají stejné atributy z Alt_Sequence přes Type_Key včetně, jak je uvedeno níže.
| Atribut | Popis |
|---|---|
Alt_Sequence | Používá se k definování alternativní sekvence, když je vyžadováno neabecední pořadí. |
Description | Popis typu. |
Effective_Period | Efektivně definuje, zda je či není povolen záznam reference. Jakmile byl odkaz použit, nemůže být odstraněn kvůli referenčním omezením; lze jej pouze zakázat. |
| Hezký název pro typ. To je to, co uživatel vidí na obrazovce. |
Type_Key | Jedinečný interní KLÍČ pro typ. To je před uživatelem skryté, ale vývojáři aplikací to mohou ve svém SQL široce využít. |
Typ strany je zde buď organizace, nebo osoba. Typy pohlaví jsou mužské a ženské. Takže to jsou opravdu jednoduché případy.
Řešení tradiční referenční tabulky
Jak tedy implementujeme logický model ve fyzickém světě skutečné databáze?
Mohli bychom se domnívat, že každý typ reference bude mapován do své vlastní tabulky. Můžete to označit jako tradičnější jeden stůl na třídu řešení. Je to dost jednoduché a vypadalo by to nějak takto:
Nevýhodou toho je, že těchto tabulek mohou být desítky a desítky, všechny mají stejné sloupce a všechny dělají v podstatě totéž.
Kromě toho možná vytváříme mnohem více práce na vývoji . Pokud je pro správu hodnot vyžadováno uživatelské rozhraní pro každý typ, množství práce se rychle znásobí. Neexistují pro to žádná tvrdá a rychlá pravidla – opravdu to závisí na vašem vývojovém prostředí – takže budete muset mluvit se svými vývojáři abyste pochopili, jaký to má dopad.
Ale vzhledem k tomu, že všechny naše referenční typy mají stejné atributy nebo sloupce, existuje obecnější způsob implementace našeho logického datového modelu? Ano, tam je! A vyžaduje pouze dvě tabulky .
Řešení se dvěma tabulkami
První diskuse, kterou jsem kdy na toto téma vedl, byla v polovině 90. let, kdy jsem pracoval pro londýnskou pojišťovací společnost. Tehdy jsme šli rovnou k fyzickému designu a většinou jsme používali přirozené/obchodní klíče, ne ID. Tam, kde existovala referenční data, jsme se rozhodli ponechat jednu tabulku na typ, která se skládala z jedinečného kódu (VARCHAR PK) a popisu. Ve skutečnosti tehdy bylo mnohem méně referenčních tabulek. Častěji by se ve sloupci používala omezená sada obchodních kódů, případně s definovaným omezením kontroly databáze; neexistovala by vůbec žádná referenční tabulka.
Od té doby se ale hra posunula dál. Toto je řešení se dvěma tabulkami může vypadat takto:
Jak vidíte, tento fyzický datový model je velmi jednoduchý. Ale je to docela odlišné od logického modelu, a ne proto, že by něco vypadalo jako hruška. Je to proto, že řada věcí byla provedena jako součást fyzického designu .
reference_type tabulka představuje každou jednotlivou referenční třídu z LDM. Pokud tedy máte v LDM 20 typů referencí, budete mít v tabulce 20 řádků metadat. reference_value tabulka obsahuje přípustné hodnoty pro všechny typy odkazů.
V době vzniku tohoto projektu probíhaly mezi vývojáři poměrně živé diskuze. Někteří upřednostňovali řešení se dvěma tabulkami a jiní upřednostňovali jeden stůl na typ metoda.
Každé řešení má své klady a zápory. Jak asi tušíte, vývojáři se většinou zabývali množstvím práce, kterou UI zabere. Někteří si mysleli, že vytvoření uživatelského rozhraní pro správu pro každou tabulku by bylo docela rychlé. Jiní si mysleli, že vytvoření jediného uživatelského rozhraní pro správu by bylo složitější, ale nakonec se vyplatí.
U tohoto konkrétního projektu bylo preferováno dvoustolové řešení. Podívejme se na to podrobněji.
Rozšiřitelný a flexibilní vzor referenčních dat
Protože se váš datový model v průběhu času vyvíjí a jsou vyžadovány nové typy referencí, nemusíte provádět změny v databázi pro každý nový typ reference. Stačí definovat nová konfigurační data. Chcete-li to provést, přidejte nový řádek do reference_type a přidejte její kontrolovaný seznam povolených hodnot do reference_value tabulka.
Důležitým konceptem obsaženým v tomto řešení je definování efektivních časových úseků pro určité hodnoty. Vaše organizace může například potřebovat zachytit novou hodnotu reference_value „Proof of ID“, který bude v budoucnu přijatelný. Je to jednoduchá záležitost přidání této nové reference_value s effective_period_from datum správně nastaveno. To lze provést předem. Dokud toto datum nenastane, nový záznam se nezobrazí v rozevíracím seznamu hodnot, které uživatelé vaší aplikace vidí. Je to proto, že vaše aplikace zobrazuje pouze hodnoty, které jsou aktuální nebo povolené.
Na druhou stranu možná budete muset uživatelům zabránit v používání konkrétní reference_value . V takovém případě jej aktualizujte pomocí effective_period_to datum správně nastaveno. Po uplynutí tohoto dne se již hodnota v rozevíracím seznamu nezobrazí. Od tohoto okamžiku bude deaktivována. Ale protože stále fyzicky existuje jako řádek v tabulce, referenční integrita je zachována pro ty tabulky, kde již byl odkazován.
Nyní, když jsme pracovali na dvoutabulkovém řešení, ukázalo se, že některé další sloupce by byly užitečné pro reference_type stůl. Ty se většinou soustředily na obavy týkající se uživatelského rozhraní.
Například pretty_name na reference_type tabulka byla přidána pro použití v uživatelském rozhraní. Pro velké taxonomie je užitečné použít okno s funkcí vyhledávání. Poté pretty_name lze použít pro nadpis okna.
Na druhou stranu, pokud rozbalovací seznam hodnot stačí, pretty_name lze použít pro výzvu LOV. Podobným způsobem lze popis použít v uživatelském rozhraní k vyplnění nápovědy při převrácení.
Když se podíváte na typ konfigurace nebo metadat, která jsou součástí těchto tabulek, pomůže vám to trochu objasnit.
Jak to všechno spravovat
Zatímco zde použitý příklad je velmi jednoduchý, referenční hodnoty pro velký projekt se mohou rychle stát poměrně složitými. Takže může být vhodné udržovat toto vše v tabulce. Pokud ano, můžete použít samotnou tabulku ke generování SQL pomocí zřetězení řetězců. To se vloží do skriptů, které se spouštějí proti cílovým databázím podporujícím životní cyklus vývoje a produkční (živé) databázi. Tím se do databáze vloží všechna nezbytná referenční data.
Zde jsou konfigurační data pro dva typy LDM, Gender_Type a Party_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
V reference_type pro každý podtyp LDM Root_Reference_Type . Popis v reference_type je převzato z popisu třídy LDM. Pro Gender_Type , to by znělo „Identifikuje pohlaví osoby“. Fragmenty DML ukazují rozdíly v popisech mezi typem a hodnotou, které lze použít v uživatelském rozhraní nebo v přehledech.
Uvidíte tento reference_type s názvem Gender_Type byl přidělen rozsah 13000000 až 13999999 pro související reference_value.ids . V tomto modelu každý reference_type je přidělen jedinečný, nepřekrývající se rozsah ID. Není to nezbytně nutné, ale umožňuje nám to seskupit související ID hodnot dohromady. Napodobuje to, co byste získali, kdybyste měli samostatné stoly. Je hezké to mít, ale pokud si nemyslíte, že to má nějakou výhodu, můžete se toho zbavit.
Další sloupec, který byl přidán do PDM, je admin_role . Zde je důvod.
Kdo jsou správci
Některé taxonomie mohou mít přidané nebo odebrané hodnoty s malým nebo žádným dopadem. K tomu dojde, když žádné programy nevyužívají hodnoty ve své logice nebo když typ není propojen s jinými systémy. V takových případech je pro administrátory uživatelů bezpečné je udržovat aktuální.
Ale v jiných případech je třeba věnovat mnohem větší opatrnosti. Nová referenční hodnota může způsobit nezamýšlené důsledky pro logiku programu nebo navazující systémy.
Předpokládejme například, že do taxonomie Gender Type přidáme následující:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
To se rychle stane problémem, pokud máme někde zabudovanou následující logiku:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
Je zřejmé, že v rozšířené taxonomii již neplatí logika „pokud nejste muž, musíte být žena“.
Zde se nachází admin_role sloupec přichází do hry. Zrodil se z diskusí s vývojáři o fyzickém designu a fungoval ve spojení s jejich řešením uživatelského rozhraní. Ale pokud by bylo zvoleno řešení jedna tabulka na třídu, pak reference_type by neexistovalo. Metadata, která obsahuje, by byla pevně zakódována do aplikace Gender_Type tabulka – , která není flexibilní ani rozšiřitelná.
Spravovat taxonomii mohou pouze uživatelé se správnými oprávněními. To bude pravděpodobně založeno na odborných znalostech předmětu (MSP ). Na druhou stranu může být nutné, aby některé taxonomie byly spravovány IT oddělením, aby bylo možné provést analýzu dopadu, důkladné testování a všechny změny kódu, aby byly harmonicky uvolněny včas pro novou konfiguraci. (Zda to bude provedeno žádostmi o změnu nebo nějakým jiným způsobem, je na vaší organizaci.)
Možná jste si všimli, že sloupce auditu created_by , created_date , updated_by a updated_date nejsou ve výše uvedeném skriptu vůbec odkazovány. Opět, pokud o ně nemáte zájem, nemusíte je používat. Tato konkrétní organizace měla standard, který nařizoval mít sloupce auditu na každé tabulce.
Spouštěče:Udržování konzistentních věcí
Spouštěče zajišťují, že tyto sloupce auditu jsou konzistentně aktualizovány bez ohledu na to, jaký je zdroj SQL (skripty, vaše aplikace, plánované dávkové aktualizace, ad-hoc aktualizace atd.).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
Mým pozadím je většinou Oracle a bohužel Oracle omezuje identifikátory na 30 bajtů. Aby nedošlo k překročení tohoto, je každé tabulce přiřazen krátký alias o třech až pěti znacích a další artefakty související s tabulkou používají tento alias ve svých názvech. Takže reference_value Alias uživatele je reva – první dva znaky z každého slova. Před vložením řádku a před aktualizací řádku je zkráceno na bri a bru resp. Název sekvence reva_seq , a tak dále.
Ruční kódování spouštěčů, jako je tento, stůl za stolem, vyžaduje pro vývojáře spoustu demoralizující práce. Naštěstí lze tyto spouštěče vytvořit pomocí generování kódu , ale to je téma jiného článku!
Význam klíčů
ref_type_key a type_key oba sloupce jsou omezeny na 30 bajtů. To umožňuje jejich použití v dotazech SQL typu PIVOT (v Oracle. Jiné databáze nemusí mít stejné omezení délky identifikátoru).
Protože jedinečnost klíče je zajištěna databází a spouštěč zajišťuje, že jeho hodnota zůstane po celou dobu stejná, mohou být – a měly by být – použity v dotazech a kódu, aby byly čitelnější . co tím chci říct? No, místo:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
Píšete:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
V zásadě klíč jasně vysvětluje, co dotaz dělá .
Z LDM do PDM, s prostorem pro růst
Cesta z LDM do PDM nemusí být nutně rovná cesta. Není to ani přímá transformace z jednoho na druhého. Je to samostatný proces, který zavádí své vlastní úvahy a své vlastní obavy.
Jak modelujete referenční data ve vaší databázi?