Důležitou součástí ladění dotazů je pochopení algoritmů, které má optimalizátor k dispozici pro zpracování různých konstrukcí dotazů, např. filtrování, spojování, seskupování a agregace, a způsobu jejich škálování. Tyto znalosti vám pomohou připravit optimální fyzické prostředí pro vaše dotazy, jako je vytváření správných indexů. Pomáhá vám také intuitivně vycítit, který algoritmus byste měli v plánu za určitých okolností očekávat, na základě vaší znalosti prahových hodnot, kdy by měl optimalizátor přepínat z jednoho algoritmu na druhý. Při ladění dotazů se špatným výkonem pak můžete snadněji odhalit oblasti v plánu dotazů, kde mohl optimalizátor provést suboptimální volby, například kvůli nepřesným odhadům mohutnosti, a podniknout kroky k jejich nápravě.
Další důležitou součástí ladění dotazů je myšlení po vybalení – mimo algoritmy, které má optimalizátor k dispozici při použití zřejmých nástrojů. Být kreativní. Řekněme, že máte dotaz, který funguje špatně, i když jste zařídili optimální fyzické prostředí. Pro konstrukty dotazů, které jste použili, jsou algoritmy dostupné optimalizátoru x, y a z a optimalizátor vybral to nejlepší, co za daných okolností mohl. Dotaz přesto funguje špatně. Dokážete si představit teoretický plán s algoritmem, který může přinést mnohem výkonnější dotaz? Pokud si to dokážete představit, je pravděpodobné, že toho budete schopni dosáhnout nějakým přepsáním dotazu, možná s méně zřejmými konstrukty dotazů pro daný úkol.
V této sérii článků se zaměřuji na seskupování a agregaci dat. Začnu tím, že projdu algoritmy, které má optimalizátor k dispozici při použití seskupených dotazů. Poté popíšu scénáře, kdy žádný ze stávajících algoritmů nefunguje dobře, a ukážu přepisy dotazů, které vedou k vynikajícímu výkonu a škálování.
Rád bych poděkoval Craigu Freedmanovi, Vassilisovi Papadimosovi a Joe Sackovi, členům průsečíku množiny nejchytřejších lidí na planetě a množiny vývojářů SQL Serveru, za odpovědi na mé otázky týkající se optimalizace dotazů!
Pro ukázková data použiji databázi s názvem PerformanceV3. Zde si můžete stáhnout skript pro vytvoření a naplnění databáze. Použiji tabulku s názvem dbo.Orders, která obsahuje 1 000 000 řádků. Tato tabulka obsahuje několik indexů, které nejsou potřeba a mohly by narušovat mé příklady, takže spusťte následující kód, abyste tyto nepotřebné indexy odstranili:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Jediné dva indexy, které v této tabulce zůstaly, jsou seskupený index nazvaný idx_cl_od ve sloupci orderdate a neshlukovaný jedinečný index nazvaný PK_Orders ve sloupci orderid, vynucující omezení primárního klíče.
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid
Stávající algoritmy
SQL Server podporuje dva hlavní algoritmy pro agregaci dat:Stream Aggregate a Hash Aggregate. U seskupených dotazů vyžaduje algoritmus Stream Aggregate, aby byla data seřazena podle seskupených sloupců, takže musíte rozlišovat mezi dvěma případy. Jedním z nich je předobjednaný agregát toku, např. když jsou data získávána předobjednaná z indexu. Dalším je nepředobjednaný Stream Aggregate, kde je k explicitnímu třídění vstupu vyžadován další krok. Tyto dva případy se velmi liší, takže je můžete považovat za dva různé algoritmy.
Algoritmus Hash Aggregate organizuje skupiny a jejich agregáty do hashovací tabulky. Nevyžaduje objednání vstupu.
S dostatkem dat optimalizátor zvažuje paralelizaci práce a použití toho, co se nazývá lokálně-globální agregát. V takovém případě je vstup rozdělen do více vláken a každé vlákno použije jeden z výše uvedených algoritmů k místní agregaci své podmnožiny řádků. Globální agregát pak používá jeden z výše uvedených algoritmů k agregaci výsledků místních agregátů.
V tomto článku se zaměřím na předobjednaný algoritmus Stream Aggregate a jeho škálování. V budoucích dílech této série se budu zabývat dalšími algoritmy a popíšu prahové hodnoty, při kterých optimalizátor přepíná z jednoho na druhý, a kdy byste měli uvažovat o přepsání dotazu.
Předobjednaný agregát streamu
Při seskupeném dotazu s neprázdnou seskupovací sadou (množinou výrazů, podle kterých seskupujete), algoritmus Stream Aggregate vyžaduje, aby vstupní řádky byly seřazeny podle výrazů tvořících sadu seskupení. Když algoritmus zpracuje první řádek ve skupině, inicializuje člen obsahující mezilehlou agregovanou hodnotu s relevantní hodnotou (např. hodnota prvního řádku pro MAX agregaci). Když zpracuje jiný než první řádek ve skupině, přiřadí tomuto členu výsledek výpočtu zahrnujícího mezilehlou agregovanou hodnotu a hodnotu nového řádku (např. maximum mezi mezilehlou agregovanou hodnotou a novou hodnotou). Jakmile některý z členů skupiny seskupení změní svou hodnotu nebo dojde ke spotřebě vstupu, je aktuální agregovaná hodnota považována za konečný výsledek pro poslední skupinu.
Jedním ze způsobů, jak mít data uspořádaná tak, jak to potřebuje algoritmus Stream Aggregate, je získat je předobjednaná z indexu. Potřebujete, aby byl index definován pomocí sloupců seskupovací sady jako klíčů – v libovolném pořadí. Také chcete, aby index pokrýval. Zvažte například následující dotaz (budeme ho nazývat Dotaz 1):
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
Optimální index úložiště řádků pro podporu tohoto dotazu by byl definován s shipperid jako hlavním sloupcem klíče a datem objednávky buď jako zahrnutý sloupec, nebo jako druhý klíčový sloupec:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
S tímto indexem získáte odhadovaný plán zobrazený na obrázku 1 (pomocí SentryOne Plan Explorer).

Obrázek 1:Plán pro dotaz 1
Všimněte si, že operátor Index Scan má vlastnost Ordered:True, což znamená, že je vyžadováno doručit řádky uspořádané podle indexového klíče. Operátor Stream Aggregate pak zpracovává řádky uspořádané tak, jak potřebuje. Pokud jde o to, jak se vypočítávají náklady operátora; než se k tomu dostaneme, nejprve rychlá předmluva…
Jak již možná víte, když SQL Server optimalizuje dotaz, vyhodnotí více kandidátských plánů a nakonec vybere ten s nejnižší odhadovanou cenou. Odhadované náklady plánu jsou součtem odhadovaných nákladů všech operátorů. Odhadované náklady každého operátora jsou zase součtem odhadovaných I/O nákladů a odhadovaných nákladů na CPU. Nákladová jednotka sama o sobě nemá smysl. Jeho význam spočívá ve srovnání, které optimalizátor provádí mezi kandidátskými plány. To znamená, že kalkulační vzorce byly navrženy s cílem, že mezi kandidátskými plány bude ten s nejnižšími náklady (doufejme) představovat ten, který skončí rychleji. Strašně složitý úkol, který se dělá přesně!
Čím více kalkulační vzorce přiměřeně zohledňují faktory, které skutečně ovlivňují výkon a škálování algoritmu, tím jsou přesnější a tím je pravděpodobnější, že vzhledem k přesným odhadům mohutnosti optimalizátor vybere optimální plán. V každém případě, pokud chcete pochopit, proč optimalizátor volí jeden algoritmus oproti jinému, musíte pochopit dvě hlavní věci:jednou je, jak algoritmy fungují a škálují, a další je model kalkulace SQL Serveru.
Takže zpět k plánu na obrázku 1; zkusme pochopit, jak se počítají náklady. Společnost Microsoft zásadně nezveřejňuje interní kalkulační vzorce, které používá. Když jsem byl malý, fascinovalo mě rozebírání věcí. Hodinky, rádia, kazety (ano, jsem tak starý), co si jen vzpomenete. Chtěl jsem vědět, jak se věci dělají. Podobně vidím hodnotu v reverzním inženýrství vzorců, protože pokud se mi podaří předpovědět náklady přiměřeně přesně, pravděpodobně to znamená, že rozumím algoritmu dobře. Během procesu se toho hodně naučíte.
Náš dotaz obsahuje 1 000 000 řádků. I s tímto počtem řádků se zdá, že I/O náklady jsou zanedbatelné ve srovnání s náklady na CPU, takže je pravděpodobně bezpečné je ignorovat.
Pokud jde o náklady na CPU, chcete se pokusit zjistit, které faktory je ovlivňují a jakým způsobem. Teoreticky může existovat řada faktorů:počet vstupních řádků, počet skupin, mohutnost seskupovací množiny, datový typ a velikost členů seskupovací množiny. Chcete-li tedy vyzkoušet a změřit účinek kteréhokoli z těchto faktorů, chcete porovnat odhadované náklady dvou dotazů, které se liší pouze faktorem, který chcete měřit. Chcete-li například změřit dopad počtu řádků na náklady, mějte dva dotazy s různým počtem vstupních řádků, ale se všemi ostatními aspekty stejnými (počet skupin, mohutnost sady seskupení atd.). Je také důležité ověřit, že odhadovaná čísla – nikoli skutečná – jsou požadovaná, protože optimalizátor se při výpočtu nákladů spoléhá na odhadovaná čísla.
Při provádění takových srovnání je dobré mít techniky, které vám umožní plně kontrolovat odhadovaná čísla. Například jednoduchým způsobem, jak řídit odhadovaný počet vstupních řádků, je dotaz na tabulkový výraz, který je založen na TOP dotazu, a použití agregační funkce ve vnějším dotazu. Pokud se obáváte, že kvůli vašemu použití operátoru TOP použije optimalizátor cíle řádku a ty povedou k úpravě původních nákladů, týká se to pouze operátorů, kteří se v plánu objeví pod operátorem Top (pro vpravo), ne nahoře (vlevo). Operátor Stream Aggregate se přirozeně objevuje nad operátorem Top v plánu, protože přijímá filtrované řádky.
Pokud jde o řízení odhadovaného počtu výstupních skupin, můžete tak učinit pomocí seskupovacího výrazu
Abyste se ujistili, že získáte algoritmus Stream Aggregate a sériový plán, můžete to vynutit pomocí tipů dotazu:OPTION(ORDER GROUP, MAXDOP 1).
Chcete také zjistit, zda má operátor nějaké počáteční náklady, abyste je mohli vzít v úvahu ve svém reverzním inženýrství.
Začněme tím, že zjistíme, jak počet vstupních řádků ovlivňuje odhadované náklady na CPU operátora. Je zřejmé, že tento faktor by měl být relevantní pro náklady operátora. Také byste očekávali, že cena za řádek bude konstantní. Zde je několik dotazů pro srovnání, které se liší pouze odhadovaným počtem vstupních řádků (nazývejte je Dotaz 2 a Dotaz 3, v tomto pořadí):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Obrázek 2 obsahuje příslušné části odhadovaných plánů pro tyto dotazy:

Obrázek 2:Plány pro Dotaz 2 a Dotaz 3
Za předpokladu, že náklady na řádek jsou konstantní, můžete je vypočítat jako rozdíl mezi náklady operátora dělený rozdílem mezi mohutnostmi vstupu operátora:
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
Chcete-li ověřit, že číslo, které jste získali, je skutečně konstantní a správné, můžete zkusit předpovědět odhadované náklady v dotazech s jinými počty vstupních řádků. Například předpokládaná cena s 500 000 vstupními řádky je:
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
Pomocí následujícího dotazu zkontrolujte, zda je vaše předpověď přesná (nazývejte jej Dotaz 4):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Příslušná část plánu pro tento dotaz je znázorněna na obrázku 3.
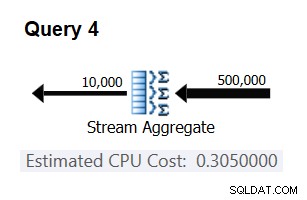
Obrázek 3:Plán pro dotaz 4
Bingo. Přirozeně je dobré zkontrolovat několik dalších vstupních mohutností. Se všemi těmi, které jsem zkontroloval, byla teze, že na vstupní řádek jsou konstantní náklady 0,0000006, správná.
Dále se pokusíme zjistit, jak odhadovaný počet skupin ovlivňuje náklady operátora na CPU. Očekávali byste, že ke zpracování každé skupiny bude potřeba nějaká práce CPU, a je také rozumné očekávat, že bude na skupinu konstantní. K otestování této práce a výpočtu nákladů na skupinu můžete použít následující dva dotazy, které se liší pouze počtem skupin výsledků (nazývejte je Dotaz 5 a Dotaz 6, v tomto pořadí):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
Příslušné části odhadovaných plánů dotazů jsou znázorněny na obrázku 4.
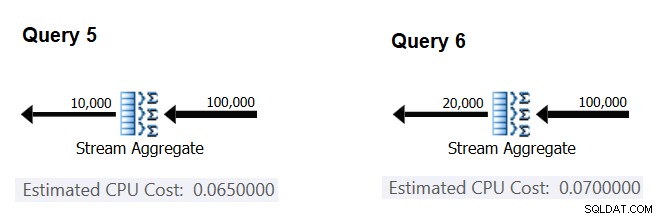
Obrázek 4:Plány pro Dotaz 5 a Dotaz 6
Podobně jako při výpočtu fixních nákladů na vstupní řádek můžete fixní náklady na výstupní skupinu vypočítat jako rozdíl mezi náklady operátora dělený rozdílem mezi mohutnostmi výstupu operátora:
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
A jak jsem předvedl dříve, svá zjištění můžete ověřit předpovídáním nákladů s jinými počty výstupních skupin a porovnáním předpokládaných čísel s těmi, které vytvořil optimalizátor. Se všemi počty skupin, které jsem zkoušel, byly předpokládané náklady přesné.
Pomocí podobných technik můžete zkontrolovat, zda náklady operátora ovlivňují další faktory. Moje testování ukazuje, že mohutnost skupiny seskupení (počet výrazů, podle kterých seskupujete), datové typy a velikosti seskupených výrazů nemají žádný vliv na odhadované náklady.
Zbývá zkontrolovat, zda operátor předpokládá nějaké smysluplné počáteční náklady. Pokud existuje, úplný (doufejme) vzorec pro výpočet nákladů operátora na CPU by měl být:
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Startovací náklady tedy můžete odvodit od zbytku:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
Pro tento účel můžete použít jakýkoli plán dotazů z tohoto článku. Například pomocí čísel z plánu pro Dotaz 5 uvedených dříve na obrázku 4 získáte:
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
Jak by se zdálo, operátor Stream Aggregate nemá žádné spouštěcí náklady související s CPU nebo jsou tak nízké, že se nezobrazují s přesností na míru nákladů.
Závěrem, reverzně navržený vzorec pro náklady operátora Stream Aggregate je:
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Obrázek 5 znázorňuje škálování nákladů operátora Stream Aggregate s ohledem na počet řádků i počet skupin.
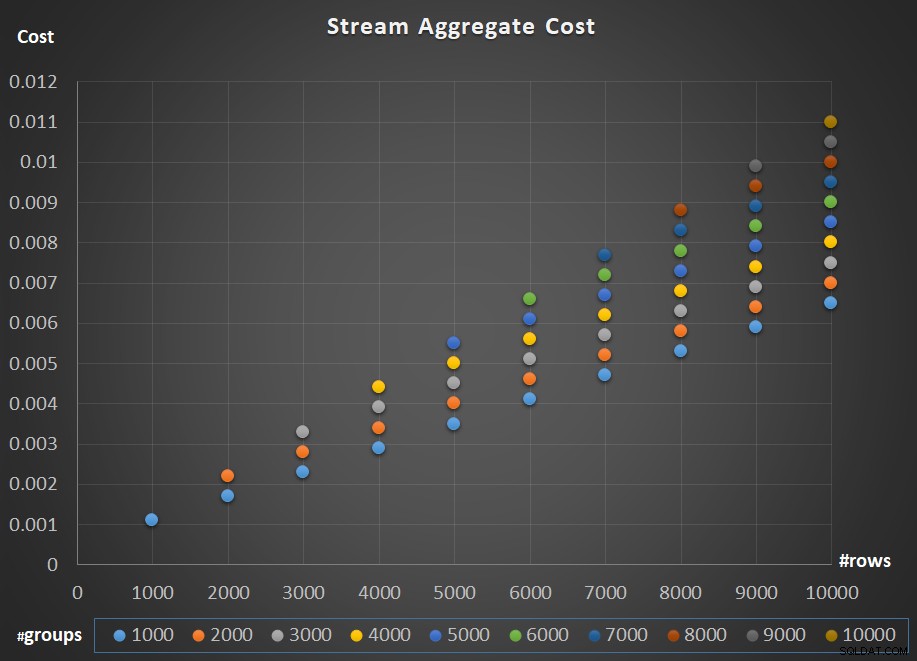
Obrázek 5:Graf měřítka algoritmu Stream Aggregate
Pokud jde o škálování operátora; je lineární. V případech, kdy je počet skupin úměrný počtu řádků, náklady celého operátora rostou stejným faktorem, jako se zvyšuje počet řádků i skupin. To znamená, že zdvojnásobení počtu jak vstupních řádků, tak vstupních skupin vede ke zdvojnásobení nákladů celého operátora. Chcete-li zjistit proč, předpokládejme, že představujeme náklady operátora jako:
r * 0.0000006 + g * 0.0000005
Pokud zvýšíte počet řádků i počet skupin o stejný faktor p, dostanete:
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
Pokud tedy pro daný počet řádků a skupin jsou náklady operátora Stream Aggregate C, zvýšení počtu řádků i skupin o stejný faktor p má za následek náklady na operátora pC. Podívejte se, zda to můžete ověřit identifikací příkladů v grafu na obrázku 5.
V případech, kdy počet skupin zůstává poměrně stabilní, i když počet vstupních řádků roste, stále získáte lineární měřítko. Jen náklady spojené s počtem skupin považujete za konstantní. To znamená, že pokud pro daný počet řádků a skupin jsou náklady operátora C =G (náklady spojené s počtem skupin) plus R (náklady spojené s počtem řádků), čímž se zvýší pouze počet řádků faktorem p vede k G + pR. V takovém případě jsou samozřejmě náklady celého operátora nižší než náklady na PC. To znamená, že zdvojnásobení počtu řádků má za následek méně než zdvojnásobení nákladů celého operátora.
V praxi je v mnoha případech při seskupování dat počet vstupních řádků podstatně větší než počet výstupních skupin. Tato skutečnost v kombinaci se skutečností, že alokované náklady na řádek a náklady na skupinu jsou téměř stejné, se část nákladů operátora, která je připisována počtu skupin, stává zanedbatelnou. Jako příklad si prohlédněte plán pro Dotaz 1 zobrazený dříve na obrázku 1. V takových případech je bezpečné uvažovat o nákladech operátora jako o jednoduchém lineárním škálování s ohledem na počet vstupních řádků.
Zvláštní případy
Existují zvláštní případy, kdy operátor Stream Aggregate nepotřebuje seřadit data vůbec. Pokud se nad tím zamyslíte, algoritmus Stream Aggregate má volnější požadavek na řazení ze vstupu ve srovnání s tím, kdy potřebujete data seřadit pro účely prezentace, např. když má dotaz vnější klauzuli ORDER BY prezentace. Algoritmus Stream Aggregate jednoduše potřebuje, aby byly všechny řádky ze stejné skupiny seřazeny dohromady. Vezměte vstupní sadu {5, 1, 5, 2, 1, 2}. Pro účely objednávání prezentací musí být tato sada objednána takto:1, 1, 2, 2, 5, 5. Pro účely agregace by algoritmus Stream Aggregate stále fungoval dobře, pokud by byla data uspořádána v následujícím pořadí:5, 5, 1, 1, 2, 2. S ohledem na to, když počítáte skalární agregaci (dotaz s agregační funkcí a bez klauzule GROUP BY), nebo seskupujete data podle prázdné seskupovací sady, nikdy neexistuje více než jedna skupina . Bez ohledu na pořadí vstupních řádků lze použít algoritmus Stream Aggregate. Algoritmus Hash Aggregate hashuje data na základě výrazů seskupovací sady jako vstupů a jak u skalárních agregátů, tak u prázdné seskupovací sady neexistují žádné vstupy, které by bylo možné hashovat. Takže jak u skalárních agregátů, tak u agregátů aplikovaných na prázdnou sadu seskupení optimalizátor vždy používá algoritmus Stream Aggregate, aniž by vyžadoval předobjednávku dat. To je alespoň případ v režimu provádění řádku, protože v současné době (od SQL Server 2017 CU4) je dávkový režim dostupný pouze s algoritmem Hash Aggregate. K demonstraci toho použiji následující dva dotazy (nazývejte je Dotaz 7 a Dotaz 8):
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
Plány pro tyto dotazy jsou znázorněny na obrázku 6.
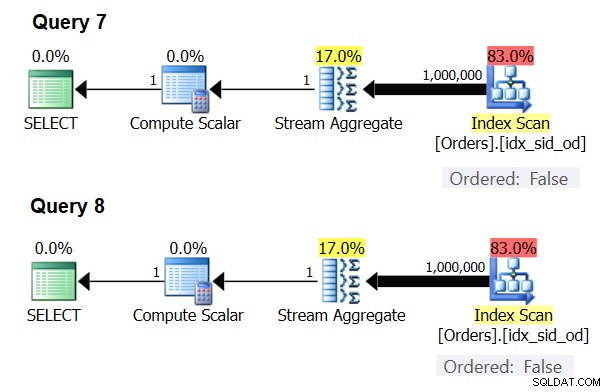
Obrázek 6:Plány pro Dotaz 7 a Dotaz 8
Zkuste v obou případech vynutit algoritmus Hash Aggregate:
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
Optimalizátor váš požadavek ignoruje a vytvoří stejné plány jako na obrázku 6.
Rychlý kvíz:jaký je rozdíl mezi skalárním agregátem a agregátem použitým na prázdnou sadu skupin?
Odpověď:s prázdnou vstupní sadou vrátí skalární agregát výsledek s jedním řádkem, zatímco agregát v dotazu s prázdnou sadou seskupení vrátí prázdnou sadu výsledků. Zkuste to:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
Až budete hotovi, spusťte následující kód pro vyčištění:
DROP INDEX idx_sid_od ON dbo.Orders;
Shrnutí a výzva
Reverzní inženýrství kalkulačního vzorce pro algoritmus Stream Aggregate je dětskou hrou. Mohl jsem vám jen říct, že kalkulační vzorec pro předobjednaný algoritmus Stream Aggregate je @numrows * 0,0000006 + @numgroups * 0,0000005 namísto celého článku, abych vysvětlil, jak na to přijdete. Smyslem však bylo popsat proces a principy reverzního inženýrství, než přejdeme ke složitějším algoritmům a prahům, kde se jeden algoritmus stává optimálnějším než ostatní. Naučit vás, jak rybařit, místo toho, abyste vám dávali ryby. Při pokusu o reverzní inženýrství kalkulačních vzorců pro různé algoritmy jsem se naučil tolik a objevil věci, o kterých jsem ani nepřemýšlel.
Jste připraveni otestovat své dovednosti? Vaše mise, pokud se rozhodnete ji přijmout, je o stupeň obtížnější než zpětné inženýrství operátora Stream Aggregate. Reverzní inženýrství kalkulačního vzorce operátora sériového řazení. To je důležité pro náš výzkum, protože algoritmus Stream Aggregate aplikovaný na dotaz s neprázdnou sadou seskupení, kde vstupní data nejsou předřazena, vyžaduje explicitní třídění. V takovém případě náklady a škálování agregované operace závisí na nákladech a škálování operátorů Sort a Stream Aggregate dohromady.
Pokud se vám podaří slušně přiblížit předpovědi nákladů na operátora Sort, můžete mít pocit, že jste získali právo přidat ke svému podpisu „Reverse Engineer“. Existuje mnoho softwarových inženýrů; ale určitě nevidíte mnoho reverzních inženýrů! Jen nezapomeňte otestovat svůj vzorec jak s malými čísly, tak s velkými; možná budete překvapeni tím, co najdete.