V únoru jsem napsal blogový příspěvek o automatické korekci plánu v SQL Server a v tomto příspěvku chci mluvit o automatické správě indexů, druhé součásti funkce Automatické ladění. Automatická správa indexů je k dispozici pouze v Azure SQL Database a v současné době není v plánu, aby byla k dispozici v příštím vydání místního SQL Serveru. Tato možnost je povolena nezávisle na automatické korekci plánu a jak název napovídá, bude spravovat indexy ve vaší databázi. Konkrétně může vytvořit indexy, které chybí, a může odstranit indexy, které se nepoužívají, a ty, které jsou duplicitní. Podívejme se, jak k tomu dochází.
Pod krytem
Automatická správa indexů se při rozhodování opírá o data. Pro potenciální vytvoření indexu používá informace o chybějícím indexu DMV a sleduje je v průběhu času a kombinuje tato data s interním modelem, aby určil přínos indexu. Také používá úložiště dotazů k určení, zda index poskytuje výhody, takže musí být povolen pro databázi, stejně jako u automatické opravy plánu. S ohledem na zahazování indexů se používají data z DMV využití indexu (sys.dm_db_index_usage_stats) a také metadata indexu (např. počet sloupců, datové typy sloupců).
Povolení automatické správy indexů
Jak bylo zmíněno, pro databázi musí být povoleno úložiště dotazů. To lze provést v SSMS, s T-SQL a pomocí REST API pro Azure SQL Database. Všimněte si, že Query Store je ve výchozím nastavení povolený pro databáze v Azure a je od 4. čtvrtletí 2016.
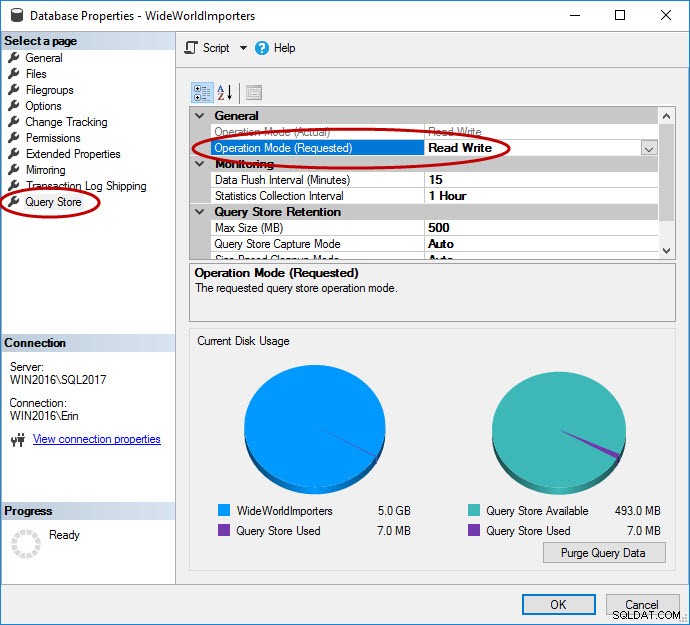
USE [master]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO
Jakmile je Query Store povoleno, můžete pomocí Azure Portal, T-SQL nebo EST API povolit automatickou správu indexů v Azure SQL Database (C# a PowerShell jsou v práci).
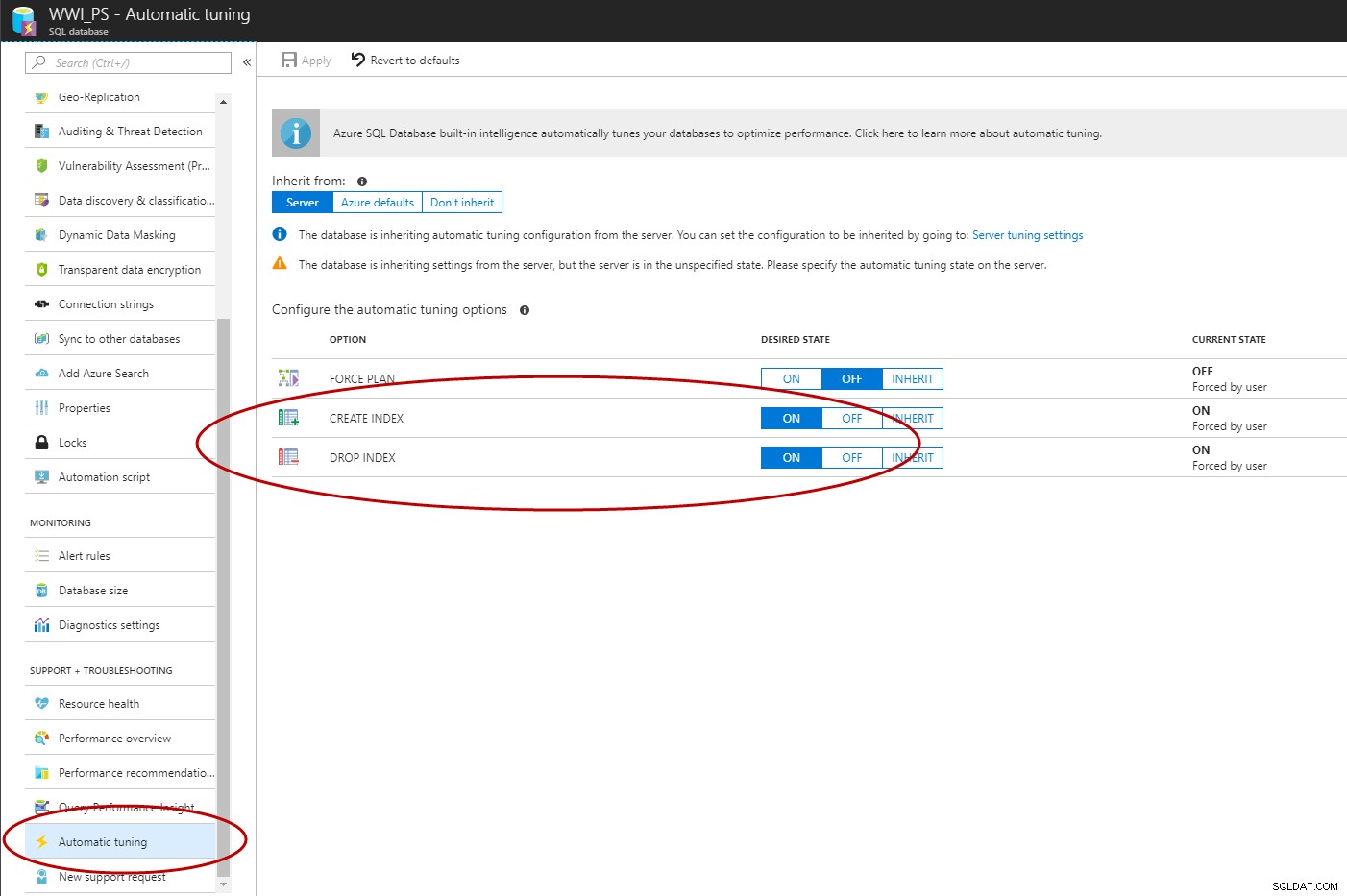
ALTER DATABASE [WWI_PS] SET AUTOMATIC_TUNING (CREATE_INDEX = ON, DROP_INDEX = ON); GO
Automatická správa indexu bude v blízké budoucnosti standardně povolena pro nové databáze v Azure (https://azure.microsoft.com/en-us/blog/automatic-tuning-will-be-a-new-default/). Počínaje lednem 2018 společnost Microsoft zahájila zavádění, aby povolila automatické ladění pro Azure SQL Databases, které ještě neměly povoleno, s upozorněními zasílanými správcům, takže tuto možnost lze v případě potřeby zakázat. Tento proces trvá několik měsíců, takže pokud jste ještě nedostali upozornění, nepropadejte panice!
Jak to funguje
Pro vytváření indexu v současné době existuje klouzavé okno sedmi (7) dnů*, během kterých jsou data sledována, a model potřebuje minimálně devět (9) hodin* dat, aby mohl doporučit index, s 12 hodinami* dat v Query Store, která budou použita jako výchozí. Pokud se zjistí, že index poskytne významnou výhodu, SQL Server index vytvoří.
*Tyto hodnoty se mohou v budoucnu podle vývoje modelu měnit.
Poznámka:v současné době model slučuje doporučení. To znamená, že pokud je pro tabulku doporučeno více indexů, ale lze vytvořit jeden index pokrývající všechny možnosti, může aktuálně vytvořit tento jeden index. Model však aktuálně není dostatečně inteligentní, aby sloučil doporučený index s již existujícím.
Jakmile je index vytvořen, SQL Server ověří, že poskytuje výhody pomocí úložiště dotazů (proto musí být povoleno pro databázi). Sleduje výkon jakéhokoli dotazu, který používá nový index, a porovnává CPU dotazu před přidáním indexu a při použití indexu. Pokud v důsledku indexu dojde k regresi ve výkonu dotazu, index se vrátí (zahodí). SQL Server monitoruje výkon dotazů po dobu až tří (3) dnů, nebo dokud nebude analyzováno 100 % relevantní zátěže. Pokud po tomto časovém období index nevykazuje žádné známky regrese, nebude pro něj znovu hodnotit výkon.
Pochopte, že pokud Automatická správa indexu vytvoří index a o dva měsíce později se vaše pracovní zatížení změní a bude mít prospěch ze stejného indexu, který byl automaticky vytvořen dříve, ale s jedním dalším sloupcem, pak SQL Server v současnosti vytvoří nový index. V současné době neexistuje žádná logika pro změnu existujícího automaticky vytvořeného indexu, ale tato funkce je na plánu pro tuto funkci.
Pokud jde o odstraňování indexů, pokud index neprovádí žádné vyhledávání nebo skenování po dobu 90 dnů, ale má náklady na údržbu (to znamená, že existují vkládání, aktualizace nebo odstraňování), bude vyřazen. Duplicitní indexy budou také odstraněny za předpokladu, že se jedná o přesný duplikát (a schéma se používá k určení, zda jsou indexy přesně stejné). Pokud existují duplicitní indexy, pokud jde o klíčové sloupce a zahrnuté sloupce (pokud jsou relevantní), ale jeden nebo více z nich má filtr, nejsou skutečně duplicitní a žádné indexy nebudou odstraněny.
Pro informaci, v Azure SQL Database je dvakrát tolik doporučení DROP INDEX než doporučení CREATE INDEX.
Když povolíte možnost DROP INDEX, SQL Server zruší indexy vytvořené uživatelem. Když povolíte možnost CREATE INDEX, SQL Server má schopnost vytvářet indexy automaticky a může také tyto indexy zrušit (ale nezruší indexy vytvořené uživatelem). Nakonec jsou indexy vytvářeny a rušeny během období mimo špičku, jak určuje DTU. Pokud je zátěž nad 80 % DTU, SQL Server počká s vytvořením nebo zrušením indexu, dokud se zátěž systému nesníží.
Opravdu nechám SQL Server mít kontrolu?
Možná. Moje doporučení ohledně této funkce zpočátku vyžaduje přístup „důvěřuj, ale prověřuj“.
Stejně jako u Automatic Plan Correction byla Automatic Index Management vyvinuta se značným množstvím dat zachycených z téměř dvou milionů Azure SQL Database. Funkce Automatic Index Management je k dispozici v Azure SQL Database od prvního čtvrtletí roku 2016 jako součást Index Advisor.
Algoritmy používané funkcí se vyvíjely a vyvíjejí se v průběhu času, protože ji používá více databází a zachycuje a analyzuje více dat. V současnosti však existují určitá omezení.
- Doporučení indexu se nevyhodnocují vůči stávajícím indexům, proto konsolidace indexů mezi novými a stávajícími indexy není v současné době k dispozici.
- Pokud by index poskytoval výhody pro SELECT, není před vytvořením známa režie úprav v důsledku INSERT, UPDATE a DELETE. SQL Server monitoruje tuto režii během procesu ověřování po implementaci indexu.
Automatická správa indexů má výhody, které stojí za to uvést:
- Pro každého, kdo musí spravovat databázi SQL Server, ale není správcem databáze, mohou být doporučení indexu mimořádně užitečná.
- Doporučení indexu jsou zachycena v sys.dm_db_tuning_recommendations DMV, i když nejsou povoleny možnosti indexu CREATE a DROP. Pokud si tedy nejste jisti změnami, které může SQL Server provést, můžete zkontrolovat, co je zachyceno v DMV, a poté se rozhodnout ručně implementovat doporučení.
Poznámka:Pokud doporučení implementujete ručně, SQL Server neprovede žádné ověření. Pokud doporučení implementujete prostřednictvím portálu (pomocí tlačítka Použít) nebo REST API, bude provedeno, jako by šlo o automatickou akci, a provede se ověření (a index by mohl být automaticky vrácen, pokud dojde k regresi).
- Funkce se neustále zlepšuje. Jak jsem již řekl dříve, Microsoft se nesnaží kódovat DBA nebo vývojáře bez práce, ale snaží se vypořádat se s nedostatečným ovocem, abyste měli více času na úkoly a projekty, které nelze inteligentně automatizovat.
Shrnutí
Pokud nejste připraveni předat otěže nad správou indexů, chápu to. Ale pokud máte alespoň Azure SQL Database, měli byste pravidelně kontrolovat sys.dm_db_tuning_recommendations DMV, abyste viděli, co SQL Server doporučuje, a porovnat to s daty, které vy nebo váš monitorovací nástroj třetí strany zachycuje o využití indexu. Koneckonců, kdy jste naposledy provedli kompletní a důkladnou kontrolu svých indexů, abyste pochopili, co chybí, co se skutečně používá a co jednoduše vytváří režii v databázi?