Data profesionálové ne vždy mohou používat databáze, které mají optimální design. Někdy věci, které vás rozpláčou, jsou věci, které jsme udělali sami sobě, protože to v té době vypadalo jako dobré nápady. Někdy je to kvůli aplikacím třetích stran. Někdy vás prostě předcházejí.
Ten, o kterém v tomto příspěvku přemýšlím, je, když váš sloupec datetime (nebo datetime2, nebo ještě lépe, datetimeoffset) jsou ve skutečnosti dva sloupce – jeden pro datum a jeden pro čas. (Pokud máte opět samostatný sloupec pro offset, pak vás příště obejmu, protože jste se pravděpodobně museli vypořádat se všemi druhy zranění.)
Udělal jsem průzkum na Twitteru a zjistil jsem, že jde o velmi reálný problém, se kterým se asi polovina z vás musí čas od času potýkat s datem a časem.
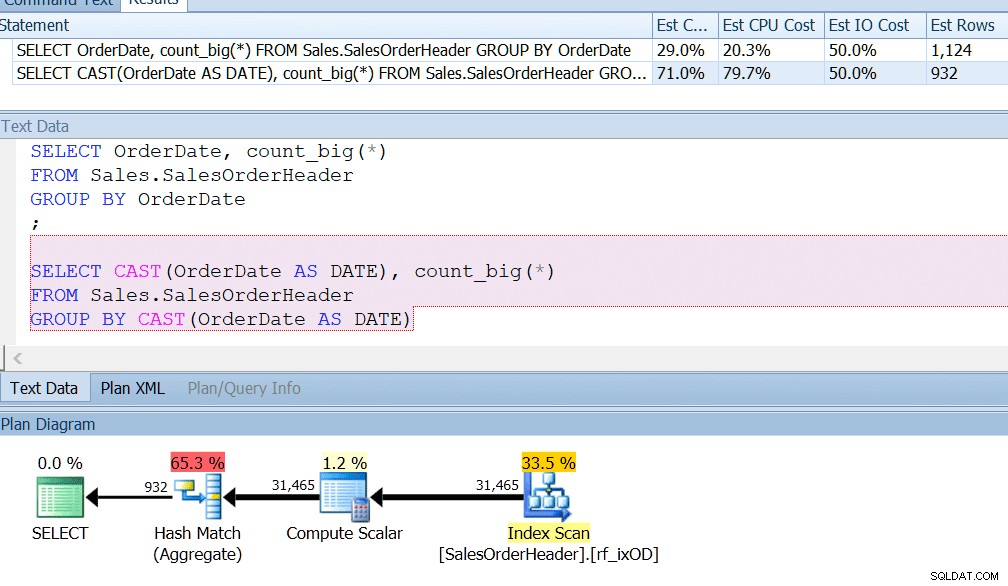
AdventureWorks to téměř dělá – když se podíváte do tabulky Sales.SalesOrderHeader, uvidíte sloupec data a času s názvem OrderDate, který má vždy přesná data. Vsadím se, že pokud jste vývojář sestav v AdventureWorks, pravděpodobně jste napsali dotazy, které hledají počet objednávek v konkrétní den, pomocí GROUP BY OrderDate nebo něčeho podobného. I kdybyste věděli, že se jedná o sloupec datum a čas a existuje možnost, že bude také ukládat jiný než půlnoční čas, přesto byste řekli GROUP BY OrderDate jen kvůli správnému použití indexu. GROUP BY CAST (Datum objednávky JAKO DATUM) to prostě nevyřeší.
Mám index na OrderDate, jako byste měli, kdybyste pravidelně dotazovali tento sloupec, a vidím, že seskupení podle CAST (OrderDate AS DATE) je z pohledu CPU asi čtyřikrát horší.
Takže chápu, proč byste rádi dotazovali na svůj sloupec, jako by to bylo datum, jednoduše s vědomím, že pokud se použití tohoto sloupce změní, budete mít spoustu bolesti. Možná to vyřešíte tím, že budete mít na stole omezení. Možná jen strčíš hlavu do písku.
A když někdo přijde a řekne:„Víte, měli bychom ukládat i čas, kdy došlo k objednávkám“, dobře, vybavíte si všechen kód, který předpokládá, že Datum objednávky je prostě datum, a zjistíte, že má samostatný sloupec nazvaný Čas objednávky (datový typ času, prosím) bude nejrozumnější možností. Chápu. Není to ideální, ale funguje to, aniž by se příliš rozbilo.
V tomto bodě doporučuji také vytvořit OrderDateTime, což by byl vypočítaný sloupec spojující tyto dva (což byste měli udělat přidáním počtu dní ode dne 0 do CAST (Datum objednávky jako datetime2), než se snažit přidat čas do datum, které je obecně mnohem komplikovanější). A pak index OrderDateTime, protože to by bylo rozumné.
Poměrně často se ale setkáte s datem a časem jako v samostatných sloupcích, v podstatě s tím nemůžete nic dělat. Nemůžete přidat vypočítaný sloupec, protože je to aplikace třetí strany a nevíte, co by se mohlo pokazit. Jste si jisti, že nikdy nedělají SELECT *? Jednoho dne doufám, že nám dovolí přidat sloupce a skrýt je, ale prozatím určitě riskujete, že něco rozbijete.
A víte, že to dělá i msdb. Oba jsou celá čísla. A je to kvůli zpětné kompatibilitě, předpokládám. Ale pochybuji, že uvažujete o přidání vypočítaného sloupce do tabulky v msdb.
Jak se tedy na to ptáme? Předpokládejme, že chceme najít záznamy, které byly v určitém časovém rozmezí?
Pojďme trochu experimentovat.
Nejprve vytvořte tabulku se 3 miliony řádků a indexujte sloupce, na kterých nám záleží.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (Mohl jsem z toho udělat seskupený index, ale domnívám se, že pro vaše prostředí je typičtější neshlukovaný index.)
Naše data vypadají takto a já chci najít řádky mezi řekněme 2. srpna 2011 v 8:30 a 5. srpna 2011 v 21:30.
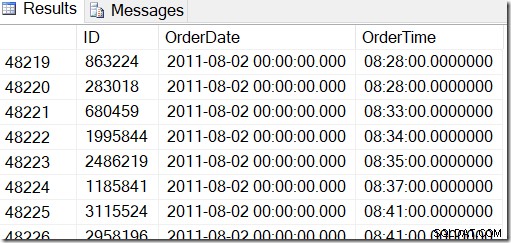
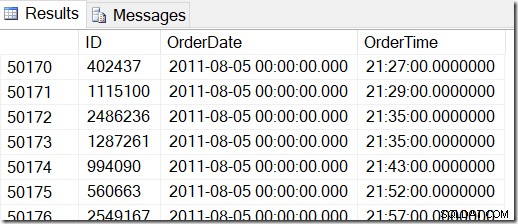
Když se podívám na data, vidím, že chci všechny řádky mezi 48221 a 50171. To je 50171-48221+1=1951 řádků (+1 je, protože jde o celý rozsah). To mi pomáhá mít jistotu, že mé výsledky jsou správné. Na svém počítači byste pravděpodobně měli podobné, ale ne přesné, protože při generování tabulky jsem použil náhodné hodnoty.
Vím, že něco takového prostě udělat nemůžu:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
…protože to nezahrnuje něco, co se stalo přes noc 4. To mi dává 1268 řádků – zjevně to není správné.
Jednou z možností je zkombinovat sloupce:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
To dává správné výsledky. ano. Jde jen o to, že je to zcela neprodejné a poskytuje nám skenování napříč všemi řádky v naší tabulce. Na našich 3 milionech řádků to může trvat několik sekund.
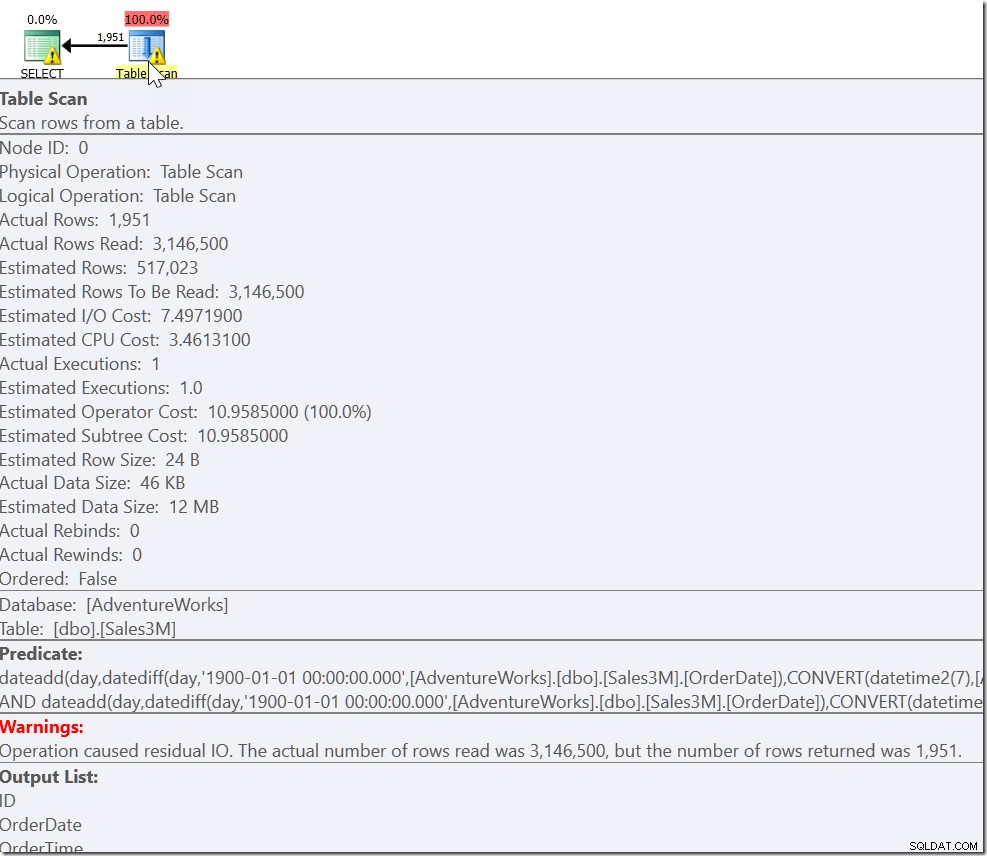
Náš problém je, že máme obyčejný případ a dva speciální případy. Víme, že každý řádek, který vyhovuje OrderDate> ‚20110802‘ A OrderDate <‚20110805‘, je ten, který chceme. Potřebujeme však také každý řádek, který je v 8:30 v 20110802 a v 21:30 v 20110805. A to nás vede k:
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
OR je hrozné, já vím. Může také vést ke skenování, i když ne nutně. Zde vidím tři hledání indexu, která jsou zřetězena a poté kontrolována na jedinečnost. Optimalizátor dotazů si samozřejmě uvědomuje, že by neměl vracet stejný řádek dvakrát, ale neuvědomuje si, že tyto tři podmínky se vzájemně vylučují. A ve skutečnosti, pokud byste to dělali na rozsahu během jediného dne, dostali byste špatné výsledky.
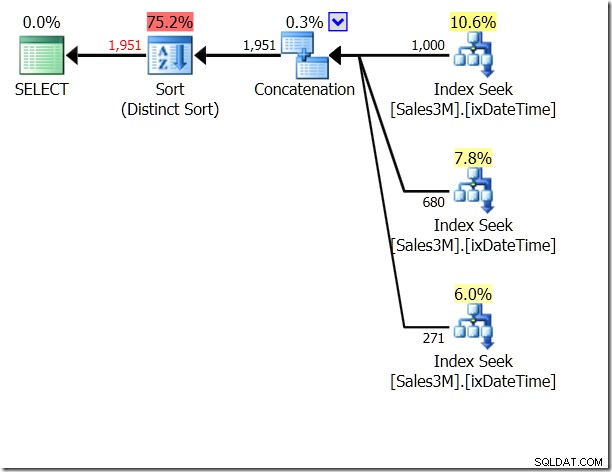
Na to bychom mohli použít UNION ALL, což by znamenalo, že QO by bylo jedno, zda se podmínky vzájemně vylučují. To nám dává tři hledání, která jsou zřetězená – to je docela dobré.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Ale stále jsou to tři hledání. Statistika IO mi říká, že na mém počítači je to 20 čtení.

Když teď přemýšlím o proměnlivosti, nemyslím jen na to, jak se vyhnout vkládání sloupců indexů do výrazů, ale také přemýšlím o tom, co by mohlo pomoci něčemu, co se zdá sargable.
Vezměte si například WHERE LastName LIKE 'Far%'. Když se podívám na tento plán, vidím Seek, přičemž predikát Seek hledá jakékoli jméno od Far až po (ale ne včetně) FaS. A pak je tu reziduální predikát, který kontroluje podmínku LIKE. Není to proto, že by QO považovalo LIKE za proměnlivé. Pokud by tomu tak bylo, bylo by možné použít LIKE v predikátu Seek. Je to proto, že ví, že vše, co je splněno touto podmínkou LIKE, musí být v tomto rozsahu.
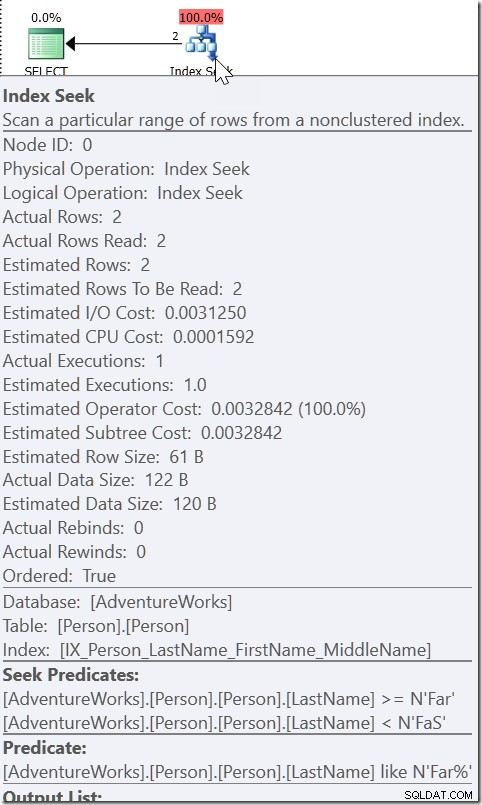
Take WHERE CAST(OrderDate AS DATE) ='20110805'
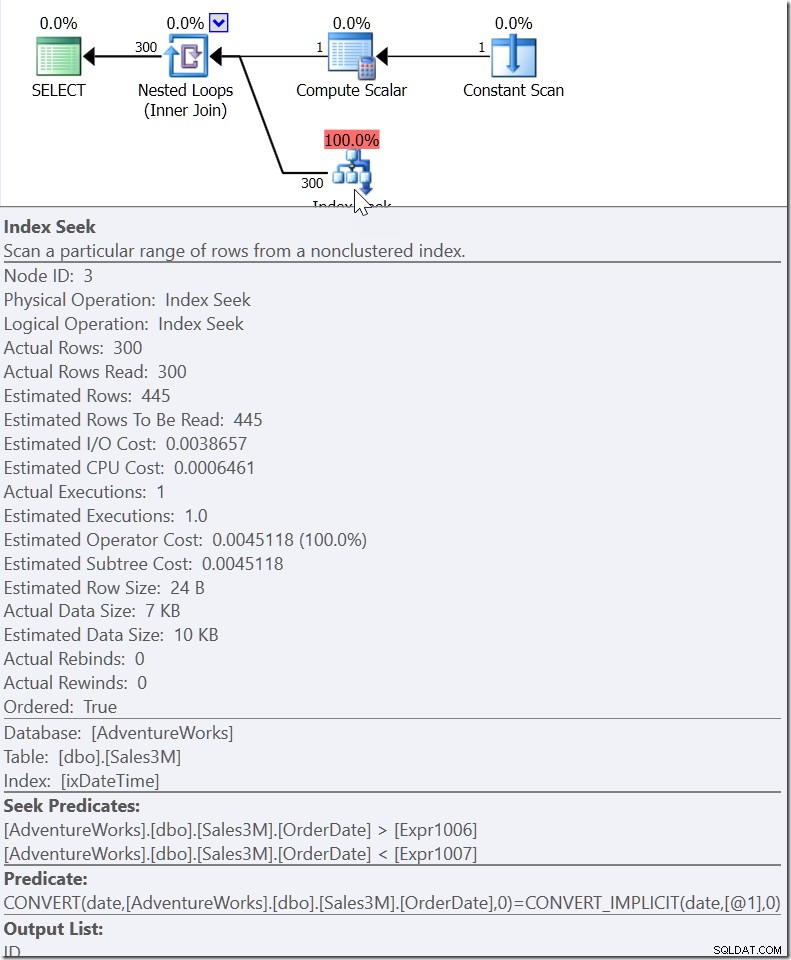
Zde vidíme predikát hledání, který hledá hodnoty OrderDate mezi dvěma hodnotami, které byly zpracovány jinde v plánu, ale vytváří rozsah, ve kterém musí existovat správné hodnoty. Tohle není>=20110805 00:00 a <20110806 00:00 (což bych udělal já), je to něco jiného. Hodnota pro začátek tohoto rozsahu musí být menší než 20110805 00:00, protože je>, nikoli>=. Skutečně můžeme říci jen to, že když někdo v Microsoftu implementoval, jak má QO reagovat na tento druh predikátu, dal mu dostatek informací, aby přišel s tím, čemu říkám „pomocný predikát“.
Nyní bych byl rád, kdyby společnost Microsoft umožnila rozšiřování více funkcí, ale tento konkrétní požadavek byl uzavřen dlouho předtím, než vyřadili Connect.
Ale možná mám na mysli, aby vytvořili více pomocných predikátů.
Problém s pomocnými predikáty je v tom, že téměř jistě čtou více řádků, než chcete. Ale pořád je to mnohem lepší než procházet celý index.
Vím, že všechny řádky, které chci vrátit, budou mít Datum objednávky mezi 20110802 a 20110805. Jen jsou některé, které nechci.
Mohl bych je jen odstranit a toto by platilo:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
Ale mám pocit, že toto je řešení, které vyžaduje určité úsilí, abychom na něj přišli. Menší úsilí na straně vývojáře je jednoduše poskytnout pomocný predikát naší správné, ale pomalé verzi.
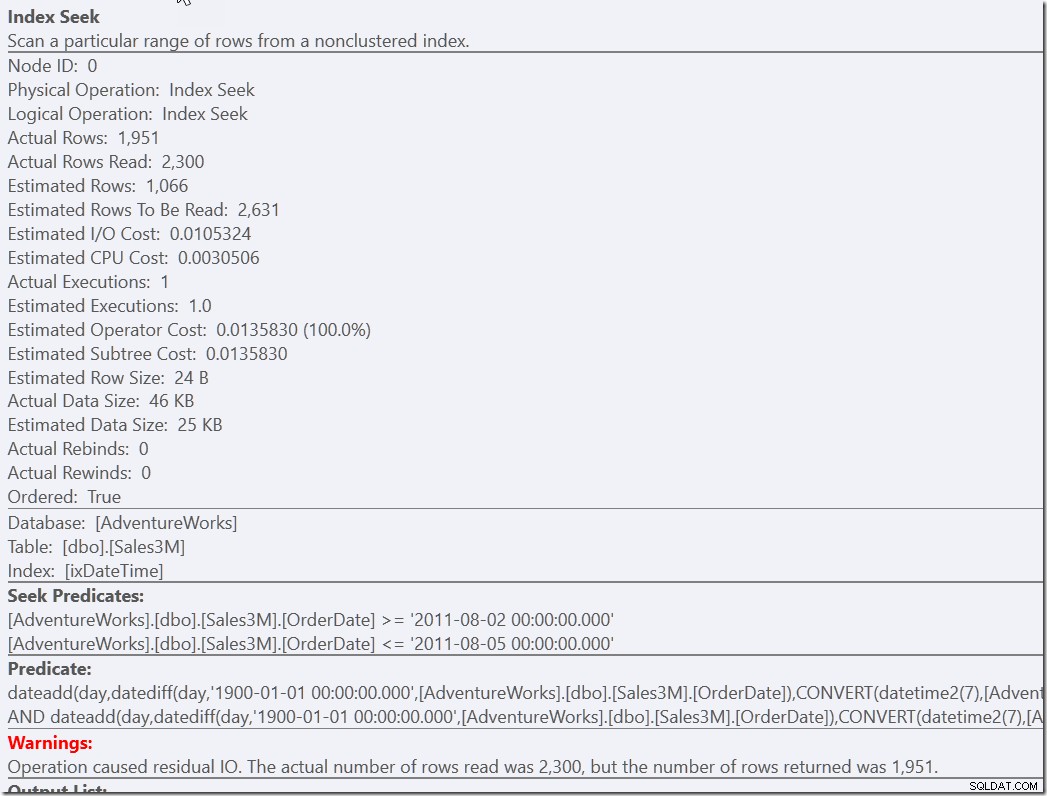
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
Oba tyto dotazy najdou 2300 řádků, které jsou ve správných dnech, a pak je potřeba všechny tyto řádky porovnat s ostatními predikáty. Jeden musí zkontrolovat dvě podmínky NOT, druhý musí provést konverzi typu a počítat. Ale oba jsou mnohem rychlejší než to, co jsme měli předtím, a provedou jediné Seek (13 přečtení). Jistě, dostávám varování o neefektivním RangeScanu, ale toto je moje přednost před prováděním tří účinných.
V některých ohledech je největším problémem tohoto posledního příkladu to, že někdo, kdo to myslí dobře, uvidí, že pomocný predikát je nadbytečný a mohl by ho smazat. To je případ všech pomocných predikátů. Takže vložte komentář.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Pokud máte něco, co se nehodí do pěkného predikátu, který se dá libovolně přecházet, vymyslete ten, který ano, a pak zjistěte, co z toho musíte vyloučit. Možná přijdeš na lepší řešení.
@rob_farley