Tento příspěvek je součástí série o cílech v řadě. Ostatní díly najdete zde:
- Část 1:Stanovení a identifikace cílů řady
- Část 2:Semináře
- Část 3:Anti Joins
Použijte Anti Join s nejlepším operátorem
Ve funkci použít proti připojení často uvidíte operátor Top (1) na vnitřní straně prováděcí plány. Například pomocí databáze AdventureWorks:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Plán ukazuje horní (1) operátor na vnitřní straně použití (vnější reference) proti spojení:
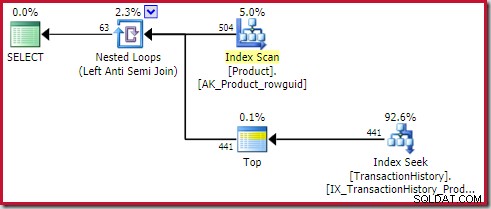
Tento top operátor je zcela nadbytečný . Není to nutné pro správnost, efektivitu nebo pro zajištění cíle řádku.
Operátor Apply anti join přestane kontrolovat řádky na vnitřní straně (pro aktuální iteraci), jakmile se na spojení objeví jeden řádek. Je dokonale možné vygenerovat plán použití proti spojení bez Top. Proč je tedy v tomto plánu top operátor?
Zdroj operátora Top
Abychom pochopili, odkud pochází tento nesmyslný operátor Top, musíme se řídit hlavními kroky, které jsme provedli během kompilace a optimalizace našeho vzorového dotazu.
Jako obvykle je dotaz nejprve analyzován do stromu. To obsahuje logický operátor 'neexistuje' s poddotazem, který se v tomto případě přesně shoduje s písemnou formou dotazu:

Dílčí dotaz neexistuje se rozvine do použití proti spojení:

To se pak dále transformuje na logické levé anti semi spojení. Výsledný strom předaný optimalizaci na základě nákladů vypadá takto:

První průzkum provedený optimalizátorem založeným na nákladech je zavedení logického odlišení operace na spodním vstupu proti spojení, aby se vytvořily jedinečné hodnoty pro klíč proti spojení. Obecnou myšlenkou je, že namísto testování duplicitních hodnot při spojení může mít plán prospěch ze seskupení těchto hodnot předem.
Pravidlo odpovědného průzkumu se nazývá LASJNtoLASJNonDist (levé proti semi spojení k levému proti semi spojení na odlišné). Dosud nebyla provedena žádná fyzická implementace ani kalkulace nákladů, takže toto je pouze optimalizátor zkoumající logickou ekvivalenci založenou na přítomnosti duplicitního ProductID hodnoty. Nový strom s přidanou operací seskupení je zobrazen níže:

Další zvažovanou logickou transformací je přepsat spojení jako použít . To se prozkoumá pomocí pravidla LASJNtoApply (levé anti semi spojení pro použití s relačním výběrem). Jak již bylo zmíněno dříve v sérii, dřívější transformace z použít na spojení měla umožnit transformace, které fungují konkrétně na spojení. Vždy je možné přepsat spojení jako žádost, takže to rozšiřuje rozsah dostupných optimalizací.
Nyní optimalizátor ne vždy zvažte přepsání aplikace jako součást optimalizace založené na nákladech. V logickém stromu musí být něco, aby se vyplatilo posouvat predikát spojení na vnitřní stranu. Obvykle se bude jednat o existenci odpovídajícího indexu, ale existují i další slibné cíle. V tomto případě je to logický klíč na ProductID vytvořené agregační operací.
Výsledkem tohoto pravidla je korelované anti spojení s výběrem na vnitřní straně:

Dále optimalizátor zvažuje přesunutí relačního výběru (predikát korelovaného spojení) dále po vnitřní straně za odlišný (skupina po agregaci) zavedený optimalizátorem dříve. To se provádí pravidlem SelOnGbAgg , který přesune co největší část výběru (predikátu) za vhodnou skupinu agregací (část výběru může zůstat pozadu). Tato aktivita pomáhá posílat výběry co nejblíže operátorům pro přístup k datům na úrovni listu, aby se řádky dříve eliminovaly a pozdější porovnávání indexů bylo jednodušší.
V tomto případě je filtr ve stejném sloupci jako operace seskupení, takže transformace je platná. Výsledkem je, že se celý výběr přesune pod agregaci:

Konečná operace, která nás zajímá, se provádí pravidlem GbAggToConstScanOrTop . Zdá se, že tato transformace nahrazuje seskupit podle agregace s konstantním skenováním nebo Top logická operace. Toto pravidlo odpovídá našemu stromu, protože sloupec seskupení je konstantní pro každý řádek procházející posunutým výběrem. Je zaručeno, že všechny řádky budou mít stejné ID produktu . Seskupení na této jediné hodnotě vždy vytvoří jeden řádek. Proto je platné transformovat agregát na Top (1). Takže odtud pochází vrchol.
Implementace a kalkulace
Optimalizátor nyní spouští řadu implementačních pravidel, aby našel fyzické operátory pro každou ze slibných logických alternativ, které dosud zvažoval (efektivně uložené ve struktuře typu memo). Fyzické možnosti hash a merge pocházejí z počátečního stromu se zavedeným agregátem (s laskavým svolením pravidla LASJNtoLASJNonDist pamatovat). Aplikace vyžaduje trochu více práce, aby vytvořila fyzický vrchol a přizpůsobila výběr hledání indexu.
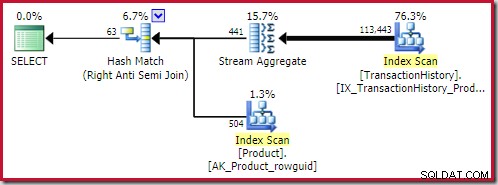
Nejlepší hash anti join Cena nalezeného řešení je 0,362143 jednotky:
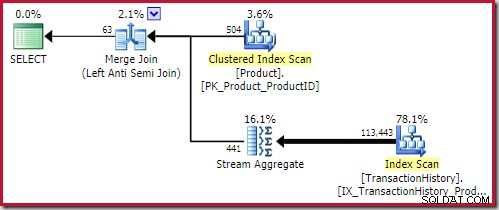
Nejlepší merge anti join řešení přichází na 0,353479 jednotky (o něco levnější):
Použijte proti připojení náklady 0,091823 jednotek (nejlevnější s velkým rozpětím):
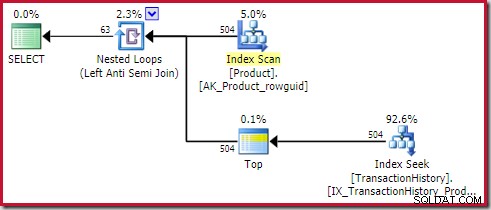
Bystrý čtenář si může všimnout, že počet řádků na vnitřní straně aplikovaného anti spojení (504) se liší od předchozího snímku obrazovky stejného plánu. Toto je totiž odhadovaný plán, zatímco předchozí plán byl po realizaci. Když je tento plán proveden, na vnitřní straně je ve všech iteracích nalezeno celkem pouze 441 řádků. To zdůrazňuje jeden z problémů se zobrazením při použití plánů semi/anti spojení:Minimální odhad optimalizátoru je jeden řádek, ale semi nebo anti spojení vždy najde jeden řádek nebo žádné řádky v každé iteraci. Výše zobrazených 504 řádků představuje 1 řádek v každé z 504 iterací. Aby se čísla shodovala, odhad by musel být pokaždé 441/504 =0,875 řádků, což by pravděpodobně lidi stejně zmátlo.
Každopádně, výše uvedený plán je „šťastný“ k tomu, aby se kvalifikoval pro cíl řady na vnitřní straně použití proti spojení ze dvou důvodů:
- Proti spojení se v optimalizátoru založeném na nákladech transformuje ze spojení na aplikaci. To stanoví cíl řádku (jak je stanoveno v části třetí).
- Operátor Top(1) také nastavuje cíl řádku ve svém podstromu.
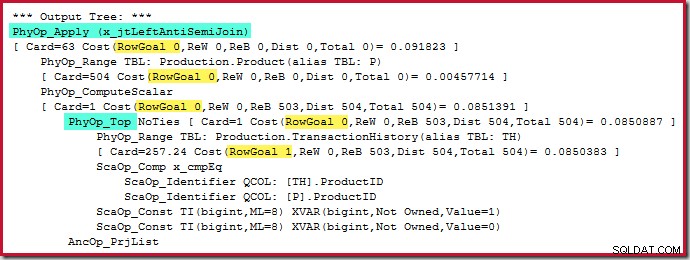
Samotný horní operátor nemá cíl řádku (z použití), protože cíl řádku 1 by nebyl nižší než běžný odhad, který je také 1 řádek (Card=1 pro PhyOp_Top níže):
Vzor Anti Join Anti
Následující obecný půdorysný tvar je ten, který považuji za anti vzor:
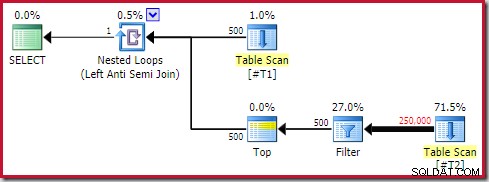
Ne každý prováděcí plán obsahující aplikované anti spojení s horním (1) operátorem na vnitřní straně bude problematický. Nicméně je to vzor k rozpoznání a ten, který téměř vždy vyžaduje další zkoumání.
Čtyři hlavní prvky, na které je třeba dávat pozor, jsou:
- Korelované vnořené smyčky (použít ) anti join
- A Nahoře (1) operátora ihned na vnitřní straně
- Značný počet řádků na vnějším vstupu (takže vnitřní strana bude spuštěna mnohokrát)
- potenciálně drahé podstrom pod vrcholem
Podstrom „$$$“ je takový, který je potenciálně drahý za běhu . To může být obtížné rozpoznat. Pokud budeme mít štěstí, bude něco zřejmého, jako je skenování celé tabulky nebo indexu. V náročnějších případech bude podstrom na první pohled vypadat naprosto nevinně, ale při bližším pohledu bude obsahovat něco nákladného. Abychom uvedli poměrně běžný příklad, můžete vidět hledání indexu, od kterého se očekává, že vrátí malý počet řádků, ale který obsahuje drahý zbytkový predikát, který testuje velmi velký počet řádků, aby našel těch pár, které splňují podmínky.
Předchozí příklad kódu AdventureWorks neměl "potenciálně drahý" podstrom. Hledání indexu (bez zbytkového predikátu) by bylo optimální metodou přístupu bez ohledu na úvahy o cíli řádku. Toto je důležitý bod:poskytuje optimalizátoru vždy efektivní přístupová cesta k datům na vnitřní straně korelovaného spojení je vždy dobrý nápad. To platí ještě více, když aplikace běží v režimu proti připojení s horním (1) operátorem na vnitřní straně.
Podívejme se nyní na příklad, který má kvůli tomuto anti vzoru docela mizerný běhový výkon.
Příklad
Následující skript vytvoří dvě dočasné tabulky haldy. První má 500 řádků obsahujících celá čísla od 1 do 500 včetně. Druhá tabulka má 500 kopií každého řádku v první tabulce, celkem tedy 250 000 řádků. Obě tabulky používají sql_variant datový typ.
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; Výkon
Nyní spustíme dotaz, který hledá řádky v menší tabulce, které nejsou přítomny ve větší tabulce (samozřejmě žádné nejsou):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); Tento dotaz běží asi 20 sekund , což je strašně dlouhá doba na srovnání 500 řádků s 250 000. Odhadovaný plán SSMS ztěžuje pochopení, proč může být výkon tak slabý:
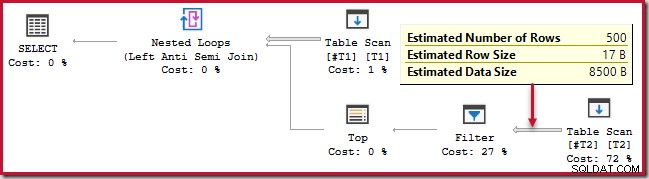
Pozorovatel si musí být vědom toho, že odhadované plány SSMS zobrazují vnitřní odhady na iteraci spojení vnořené smyčky. Je matoucí, že skutečné plány SSMS ukazují počet řádků ve všech iteracích . Průzkumník plánů automaticky provádí jednoduché výpočty nezbytné pro odhadované plány, aby také ukázal celkový počet očekávaných řádků:
I tak je běhový výkon mnohem horší, než se odhadovalo. Plán provádění (skutečného) po provedení je:
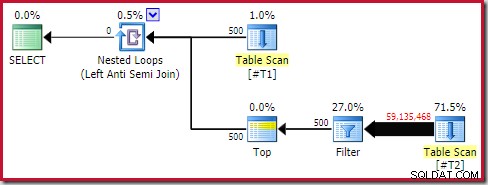
Všimněte si samostatného filtru, který by normálně byl zatlačen do skenování jako zbytkový predikát. To je důvod pro použití sql_variant datový typ; zabraňuje vtlačení predikátu, což usnadňuje viditelnost velkého počtu řádků ze skenování.
Analýza
Důvod nesrovnalosti spočívá v tom, jak optimalizátor odhaduje počet řádků, které bude muset načíst z prohledávání tabulky, aby splnil jednořádkový cíl nastavený ve filtru. Jednoduchým předpokladem je, že hodnoty jsou v tabulce rovnoměrně rozmístěny, takže k nalezení 1 z 500 přítomných jedinečných hodnot bude muset SQL Server přečíst 250 000 / 500 =500 řádků. Více než 500 iterací, což představuje 250 000 řádků.
Předpoklad uniformity optimalizátoru je obecný, ale zde nefunguje dobře. Více si o tom můžete přečíst v A Row Goal Request od Joea Obbishe a hlasovat pro jeho návrh na fóru pro zpětnou vazbu o výměně Connect na adrese Use More Than Density to cost a Scan on the Inside of a Nested Loop with TOP.
Můj názor na tento konkrétní aspekt je, že optimalizátor by měl rychle ustoupit od jednoduchého předpokladu jednotnosti, když je operátor na vnitřní straně spojení vnořených smyček (tj. odhadované přetočení plus opětovné svázání je větší než jedna). Jedna věc je předpokládat, že potřebujeme přečíst 500 řádků, abychom našli shodu v první iteraci cyklu. Předpokládat toto u každé iterace se zdá být velmi nepravděpodobné; znamená to, že prvních 500 nalezených řádků by mělo obsahovat jednu z každé odlišné hodnoty. Je velmi nepravděpodobné, že tomu tak bude v praxi.
Řada nešťastných událostí
Bez ohledu na způsob, jakým jsou kalkulováni opakovaní Top operátoři, zdá se mi, že by se celé situaci mělo v první řadě vyhnout . Připomeňme si, jak byl vytvořen Top v tomto plánu:
- Optimalizátor zavedl na vnitřní straně odlišný agregát jako optimalizaci výkonu .
- Tento agregát poskytuje klíč ve sloupci spojení podle definice (vytváří jedinečnost).
- Tento vytvořený klíč poskytuje cíl pro převod ze spojení na aplikaci.
- Predikát (výběr) spojený s aplikací je posunut dolů za agregaci.
- Nyní je zaručeno, že agregace bude fungovat s jedinou odlišnou hodnotou na iteraci (protože se jedná o korelační hodnotu).
- Souhrnný údaj je nahrazen hodnotou Top (1).
Všechny tyto transformace jsou platné jednotlivě. Jsou součástí běžných operací optimalizátoru, který hledá přiměřený plán provádění. Bohužel výsledkem je, že spekulativní agregát zavedený optimalizátorem se nakonec změní na Nejlepší (1) s přidruženým cílem řádku . Cíl řádku vede k nepřesné kalkulaci založené na předpokladu jednotnosti a poté k výběru plánu, u kterého je vysoce nepravděpodobné, že bude dobře fungovat.
Nyní by někdo mohl namítnout, že použít anti spojení by stejně mělo cíl řádku – bez výše uvedené transformační sekvence. Protiargumentem je, že optimalizátor nebude uvažovat transformace z anti join na použít anti join (nastavení cíle řádku) bez agregátu zavedeného optimalizátorem poskytujícím LASJNtoApply vládnout něčemu, k čemu se vázat. Kromě toho jsme viděli (ve třetí části), že pokud by anti-připojení vstoupilo jako žádost o optimalizaci založenou na nákladech (namísto spojení), opět by neexistoval žádný cíl řádku .
Stručně řečeno, cíl řádku v konečném plánu je zcela umělý a nemá žádný základ v původní specifikaci dotazu. Problém s cílem Top and row je vedlejším efektem tohoto zásadnějšího aspektu.
Řešení
Existuje mnoho možných řešení tohoto problému. Odstraněním kteréhokoli z kroků ve výše uvedené optimalizační sekvenci zajistíte, že optimalizátor nevytvoří implementaci aplikace proti spojení s dramaticky (a uměle) sníženými náklady. Doufejme, že tento problém bude v SQL Serveru vyřešen dříve než později.
Mezitím, moje rada je dávat si pozor na anti join anti vzor. Zajistěte, aby vnitřní strana aplikovaného anti spojení měla vždy efektivní přístupovou cestu pro všechny podmínky běhu. Pokud to není možné, možná budete muset použít nápovědu, zakázat cíle řádků, použít průvodce plánem nebo vynutit plán úložiště dotazů, abyste získali stabilní výkon z dotazů proti spojení.
Shrnutí série
Během čtyř splátek jsme prošli hodně věcí, takže zde je shrnutí na vysoké úrovni:
- Část 1 – Stanovení a identifikace cílů řady
- Syntaxe dotazu neurčuje přítomnost nebo nepřítomnost cíle řádku.
- Cíl řádku je nastaven pouze v případě, že je cíl nižší než běžný odhad.
- Operátoři fyzického vrcholu (včetně těch, které zavedl optimalizátor) přidávají do svého podstromu cíl řádku.
FASTneboSET ROWCOUNTpříkaz nastavuje cíl řádku u kořene plánu.- Semi join a anti join může přidat cíl řádku.
- SQL Server 2017 CU3 přidává atribut showplan EstimateRowsWithoutRowGoal pro operátory ovlivněné cílem řádku
- Informace o cíli řádku mohou být odhaleny pomocí nezdokumentovaných příznaků trasování 8607 a 8612.
- Část 2 – Semináře
- Přímo v T-SQL není možné vyjádřit semi join, takže používáme nepřímou syntaxi, např.
IN,EXISTSneboINTERSECT. - Tyto syntaxe jsou analyzovány do stromu obsahujícího aplikaci (korelované spojení).
- Optimalizátor se pokusí transformovat aplikaci na běžné spojení (ne vždy možné).
- Hash, sloučení a pravidelné vnořené smyčky semi spojení nenastavují cíl řádku.
- Použít poloviční spojení vždy nastaví cíl řádku.
- Použít semi spojení lze rozpoznat tak, že operátor spojení vnořených smyček má vnější reference.
- Použít semi spojení nepoužívá horní (1) operátor na vnitřní straně.
- Část 3 – Anti Joins
- Také analyzováno do aplikace s pokusem přepsat to jako spojení (ne vždy možné).
- Hash, sloučení a pravidelné vnořené smyčky proti spojení neurčují cíl řádku.
- Použití proti připojení ne vždy stanoví cíl řádku.
- Cíl řádku nastavují pouze pravidla optimalizace na základě nákladů (CBO), která transformují anti-připojení k použití.
- Anti join musí zadat CBO jako spojení (neplatí). V opačném případě nemůže dojít ke spojení za účelem použití transformace.
- Chcete-li zadat CBO jako připojení, musí být úspěšný přepis před CBO z žádosti o připojení.
- CBO pouze ve slibných případech zkoumá přepsání anti join na aplikaci.
- Zjednodušení před CBO lze zobrazit s nezdokumentovaným příznakem trasování 8621.
- Část 4 – Anti Join Anti Pattern
- Optimalizátor nastaví cíl řádku pro použití proti připojení pouze tam, kde k tomu existuje slibný důvod.
- Bohužel, několik interagujících transformací optimalizátoru přidá operátor Top (1) na vnitřní stranu použití proti spojení.
- Operátor Top je nadbytečný; není to vyžadováno pro správnost nebo účinnost.
- Nahoře vždy nastavuje cíl pro řádek (na rozdíl od žádosti, která vyžaduje dobrý důvod).
- Neoprávněný cíl řádku může vést k extrémně slabému výkonu.
- Pozor na potenciálně drahý podstrom pod umělým vrcholem (1).