Diskový prostor je v dnešní době náročným zdrojem. Obvykle budete chtít ukládat data co nejdéle, ale to může být problém, pokud neprovedete nezbytná opatření, abyste předešli potenciálnímu problému s nedostatkem místa na disku.
V tomto blogu uvidíme, jak můžeme tento problém pro PostgreSQL odhalit, předcházet mu, a pokud je příliš pozdě, některé možnosti, které vám pravděpodobně pomohou jej opravit.
Jak identifikovat problémy s místem na disku PostgreSQL
Pokud se bohužel nacházíte v této situaci nedostatku místa na disku, budete moci vidět některé chyby v protokolech databáze PostgreSQL:
2020-02-20 19:18:18.131 UTC [4400] LOG: could not close temporary statistics file "pg_stat_tmp/global.tmp": No space left on devicenebo dokonce ve vašem systémovém protokolu:
Feb 20 19:29:26 blog-pg1 rsyslogd: imjournal: fclose() failed for path: '/var/lib/rsyslog/imjournal.state.tmp': No space left on device [v8.24.0-41.el7_7.2 try https://www.rsyslog.com/e/2027 ]PostgreSQL může chvíli pokračovat v práci s dotazy pouze pro čtení, ale nakonec selže pokus o zápis na disk, pak v relaci klienta uvidíte něco takového:
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.Pokud se pak podíváte na místo na disku, budete mít tento nechtěný výstup…
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/pve-vm--125--disk--0 30G 30G 0 100% /Jak předejít problémům s místem na disku PostgreSQL
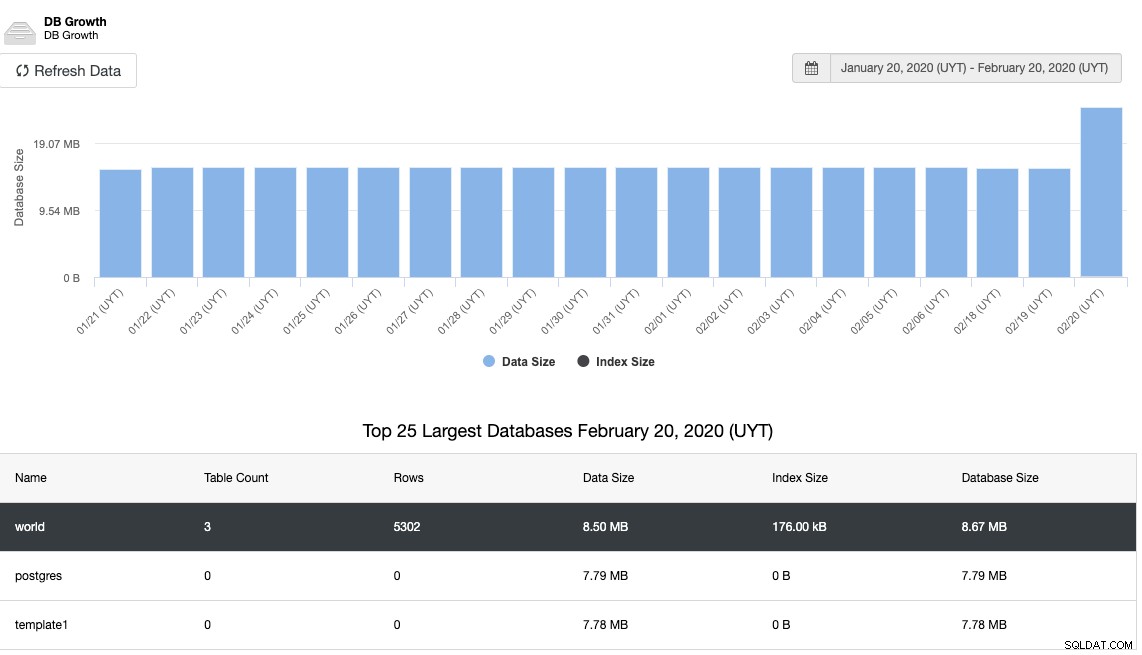
Hlavním způsobem, jak předejít tomuto druhu problému, je sledování využití místa na disku a nárůst využití databáze nebo disku. Za tímto účelem by měl být graf vhodným způsobem sledování přírůstku místa na disku:

A to samé pro růst databáze:
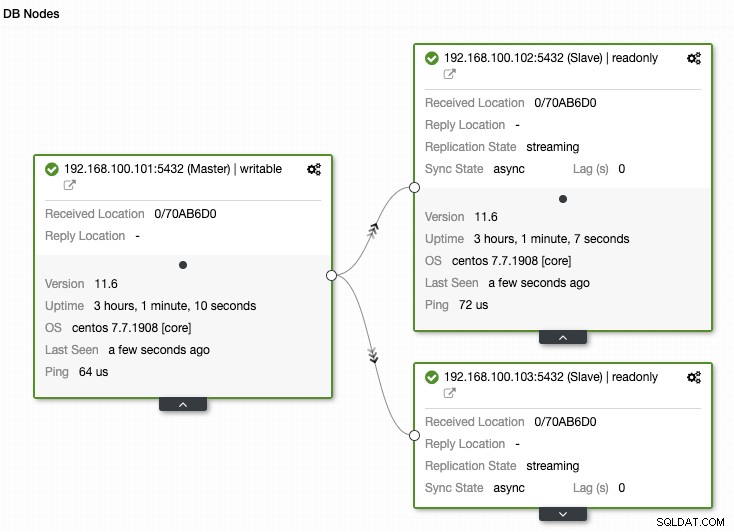
Další důležitou věcí, kterou je třeba sledovat, je stav replikace. Pokud máte repliku a z nějakého důvodu to přestane fungovat, v závislosti na konfiguraci je možné, že PostgreSQL uloží všechny soubory WAL, aby repliku obnovil, až se vrátí.
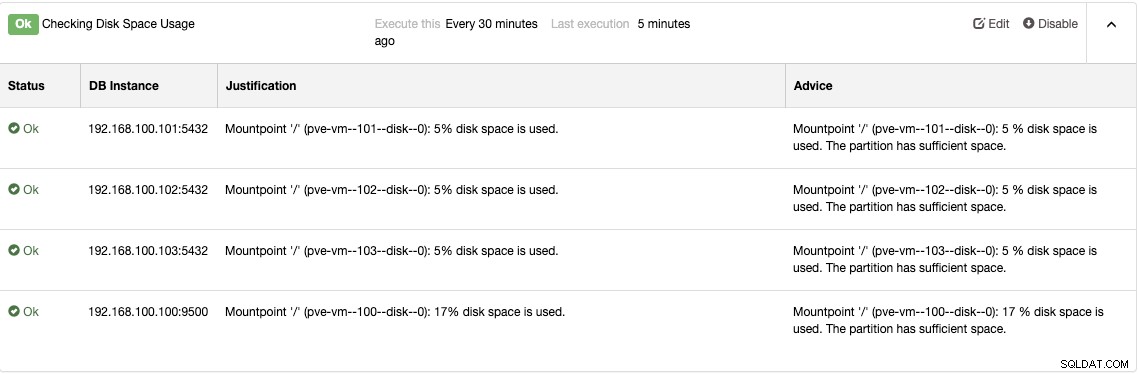
Celý tento monitorovací systém nedává smysl bez varovného systému. když potřebujete provést akci:
Jak opravit problémy s místem na disku PostgreSQL
Pokud se potýkáte s tímto problémem s nedostatkem místa na disku, i když je implementován monitorovací a výstražný systém (nebo ne), existuje mnoho možností, jak se pokusit tento problém vyřešit bez ztráty dat (nebo méně jak je to možné).
Co zabírá místo na disku?
Prvním krokem by mělo být určení místa na disku. Nejlepším postupem je mít samostatné oddíly, alespoň jeden samostatný oddíl pro úložiště databáze, takže můžete snadno ověřit, zda vaše databáze nebo váš systém nevyužívá příliš místa na disku. Další výhodou je minimalizace škod. Pokud je váš kořenový oddíl plný, může vaše databáze stále bez problémů zapisovat do vlastního oddílu.
Využití databázového prostoru
Podívejme se nyní na některé užitečné příkazy pro kontrolu využití místa na disku databáze.
Základním způsobem kontroly využití databázového prostoru je kontrola datového adresáře v souborovém systému:
$ du -sh /var/lib/pgsql/11/data/
819M /var/lib/pgsql/11/data/Nebo pokud máte samostatný oddíl pro svůj datový adresář, můžete přímo použít df -h.
Příkaz PostgreSQL „\l+“ zobrazí seznam databází s informacemi o velikosti:
$ postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace
| Description
-----------+----------+-----------+---------+-------+-----------------------+---------+------------
+--------------------------------------------
postgres | postgres | SQL_ASCII | C | C | | 7965 kB | pg_default
| default administrative connection database
template0 | postgres | SQL_ASCII | C | C | =c/postgres +| 7817 kB | pg_default
| unmodifiable empty database
| | | | | postgres=CTc/postgres | |
|
template1 | postgres | SQL_ASCII | C | C | =c/postgres +| 7817 kB | pg_default
| default template for new databases
| | | | | postgres=CTc/postgres | |
|
world | postgres | SQL_ASCII | C | C | | 8629 kB | pg_default
|
(4 rows)Použitím pg_database_size a názvu databáze můžete vidět velikost databáze:
postgres=# SELECT pg_database_size('world');
pg_database_size
------------------
8835743
(1 row)A použití pg_size_pretty k zobrazení této hodnoty v lidsky čitelné podobě by mohlo být ještě lepší:
postgres=# SELECT pg_size_pretty(pg_database_size('world'));
pg_size_pretty
----------------
8629 kB
(1 row)Když víte, kde je místo, můžete provést odpovídající akci a opravit jej. Mějte na paměti, že pouhé smazání řádků k obnovení místa na disku nestačí, k dokončení úlohy budete muset spustit VACUUM nebo VACUUM FULL.
Soubory protokolu
Nejjednodušší způsob, jak obnovit místo na disku, je smazání souborů protokolu. Můžete zkontrolovat adresář protokolů PostgreSQL nebo dokonce systémové protokoly a ověřit, zda odtud můžete získat nějaké místo. Pokud máte něco takového:
$ du -sh /var/lib/pgsql/11/data/log/
18G /var/lib/pgsql/11/data/log/Měli byste zkontrolovat obsah adresáře, abyste zjistili, zda nedošlo k problému s rotací/uchováváním protokolu nebo se něco neděje ve vaší databázi a zápisu do protokolů.
$ ls -lah /var/lib/pgsql/11/data/log/
total 18G
drwx------ 2 postgres postgres 4.0K Feb 21 00:00 .
drwx------ 21 postgres postgres 4.0K Feb 21 00:00 ..
-rw------- 1 postgres postgres 18G Feb 21 14:46 postgresql-Fri.log
-rw------- 1 postgres postgres 9.3K Feb 20 22:52 postgresql-Thu.log
-rw------- 1 postgres postgres 3.3K Feb 19 22:36 postgresql-Wed.logPřed odstraněním protokolů, pokud máte jeden velký, je dobrým zvykem ponechat si posledních zhruba 100 řádků a poté je smazat. Takže můžete zkontrolovat, co se děje po vygenerování volného místa.
$ tail -100 postgresql-Fri.log > /tmp/log_temp.logA pak:
$ cat /dev/null > /var/lib/pgsql/11/data/log/postgresql-Fri.logPokud jej pouze smažete pomocí „rm“ a soubor protokolu je používán serverem PostgreSQL (nebo jinou službou), prostor se neuvolní, takže byste měli tento soubor zkrátit pomocí této kočky / místo toho příkaz dev/null.
Tato akce je pouze pro PostgreSQL a systémové protokolové soubory. Neodstraňujte obsah pg_wal ani jiný soubor PostgreSQL, protože by to mohlo způsobit kritické poškození vaší databáze.
Nafouknutí
V normální operaci PostgreSQL nejsou n-tice, které jsou odstraněny nebo zastaralé aktualizací, fyzicky odstraněny z tabulky; jsou přítomny, dokud není provedeno VAKUUM. Je tedy nutné provádět VACUUM periodicky (AUTOVACUUM), zejména v často aktualizovaných tabulkách.
Problémem je, že prostor není vrácen operačnímu systému pouze pomocí VACUUM, je k dispozici pouze pro použití ve stejné tabulce.
VACUUM FULL přepíše tabulku na nový diskový soubor a vrátí nevyužité místo operačnímu systému. Bohužel vyžaduje exkluzivní zámek na každém stole, když je spuštěn.
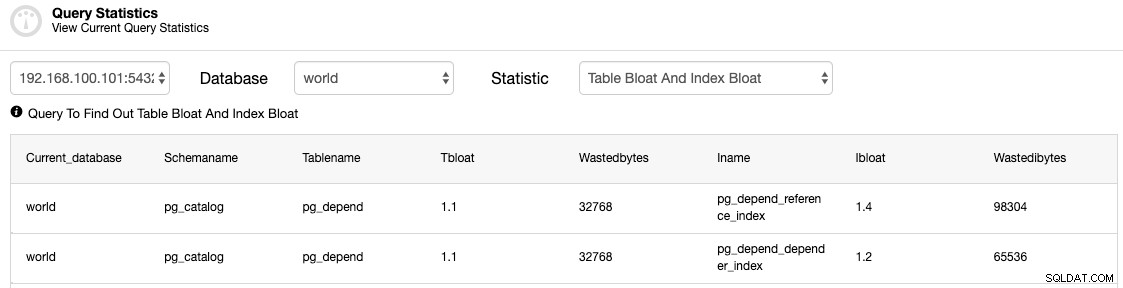
Měli byste zkontrolovat tabulky, abyste zjistili, zda je vyžadován proces VACUUM (FULL).
Replikační sloty
Pokud používáte replikační sloty a z nějakého důvodu není aktivní:
postgres=# SELECT slot_name, slot_type, active FROM pg_replication_slots;
slot_name | slot_type | active
-----------+-----------+--------
slot1 | physical | f
(1 row)Může to být problém s místem na disku, protože bude ukládat soubory WAL, dokud je neobdrží všechny pohotovostní uzly.
Způsob, jak to opravit, je obnovení repliky (pokud je to možné) nebo smazání slotu:
postgres=# SELECT pg_drop_replication_slot('slot1');
pg_drop_replication_slot
--------------------------
(1 row)Místo využívané soubory WAL bude tedy uvolněno.
Závěr
Jak jsme zmínili, monitorovací a výstražné systémy jsou klíčem k tomu, jak se těmto problémům vyhnout. Tímto způsobem vám ClusterControl může pomoci zprovoznit vaše systémy a v případě potřeby vám zasílat alarmy nebo dokonce provádět obnovu, aby váš databázový cluster fungoval. Můžete také nasadit/importovat různé databázové technologie a v případě potřeby je škálovat.