Čtení z paměti bude vždy výkonnější než přechod na disk, takže pro všechny databázové technologie byste chtěli použít co nejvíce paměti. Pokud si konfigurací nejste jisti nebo máte chybu, může to způsobit vysoké využití paměti nebo dokonce problém s nedostatkem paměti.
V tomto blogu se podíváme na to, jak zkontrolovat využití paměti PostgreSQL a jaký parametr byste měli vzít v úvahu, abyste jej vyladili. Začněme tím, že se podíváme na přehled architektury PostgreSQL.
Architektura PostgreSQL
Architektura PostgreSQL je založena na třech základních částech:Procesy, Paměť a Disk.
Paměť lze rozdělit do dvou kategorií:
- Místní paměť :Je načten každým procesem backendu pro jeho vlastní použití pro zpracování dotazů. Dělí se na podoblasti:
- Pracovní paměť:Pracovní paměť se používá k řazení n-tic podle operací ORDER BY a DISTINCT a ke spojování tabulek.
- Údržbářské práce:Tuto oblast využívají některé druhy operací údržby. Například VACUUM, pokud nezadáte autovacuum_work_mem.
- Dočasné vyrovnávací paměti:Používá se pro ukládání dočasných tabulek.
- Sdílená paměť :Přiděluje ho server PostgreSQL při jeho spuštění a používají ho všechny procesy. Dělí se na podoblasti:
- Sdílený fond vyrovnávacích pamětí:Místo, kde PostgreSQL načítá stránky s tabulkami a indexy z disku, aby pracovaly přímo z paměti, což snižuje přístup k disku.
- Vyrovnávací paměť WAL:Data WAL jsou protokolem transakcí v PostgreSQL a obsahují změny v databázi. Vyrovnávací paměť WAL je oblast, kde jsou dočasně uložena data WAL před jejich zapsáním na disk do souborů WAL. To se provádí každý předem definovaný čas nazývaný kontrolní bod. To je velmi důležité, aby nedošlo ke ztrátě informací v případě selhání serveru.
- Protokol potvrzení:Ukládá stav všech transakcí pro kontrolu souběžnosti.
Jak zjistit, co se děje
Pokud máte vysoké využití paměti, měli byste nejprve potvrdit, který proces generuje spotřebu.
Použití „Top“ Linux Command
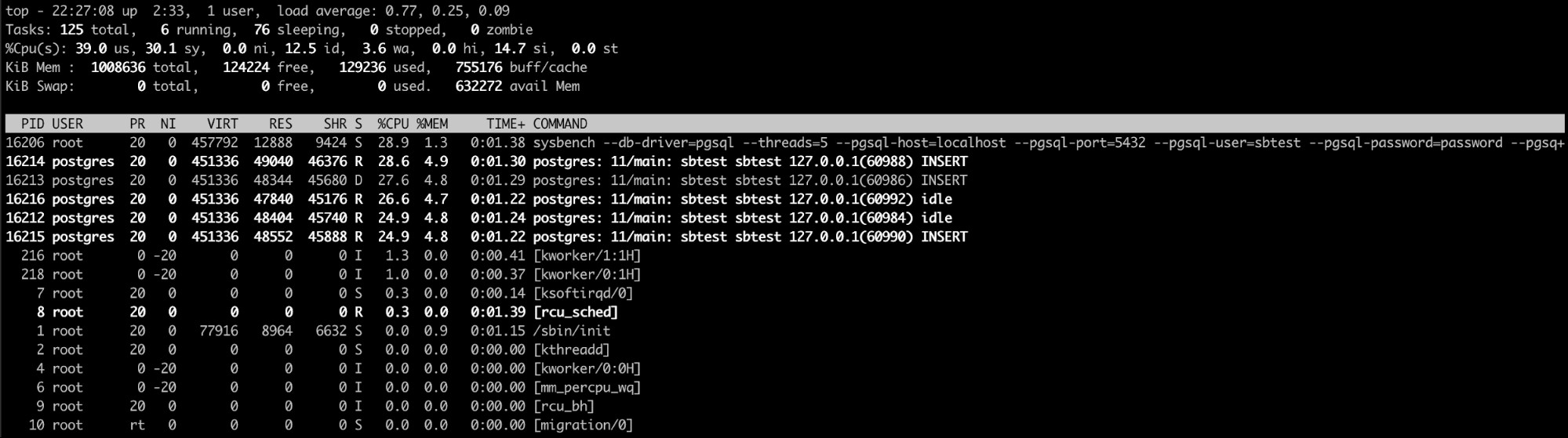
Tady je pravděpodobně nejlepší volbou horní linuxový příkaz (nebo dokonce podobný jeden jako htop). Pomocí tohoto příkazu můžete vidět proces/procesy, které spotřebovávají příliš mnoho paměti.
Když potvrdíte, že za tento problém může PostgreSQL, dalším krokem je zjistit proč.
Použití protokolu PostgreSQL
Kontrola PostgreSQL i systémových protokolů je rozhodně dobrý způsob, jak získat více informací o tom, co se děje ve vaší databázi/systému. Můžete vidět zprávy jako:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childPokud nemáte dostatek volné paměti.
Nebo dokonce více chyb databázových zpráv jako:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedKdyž zaznamenáte nějaké neočekávané chování na straně databáze. Protokoly jsou užitečné pro detekci těchto druhů problémů a ještě více. Toto sledování můžete zautomatizovat analýzou souborů protokolů a hledáním prací jako „FATAL“, „ERROR“ nebo „Kill“, takže když k tomu dojde, obdržíte upozornění.
Použití Pg_top
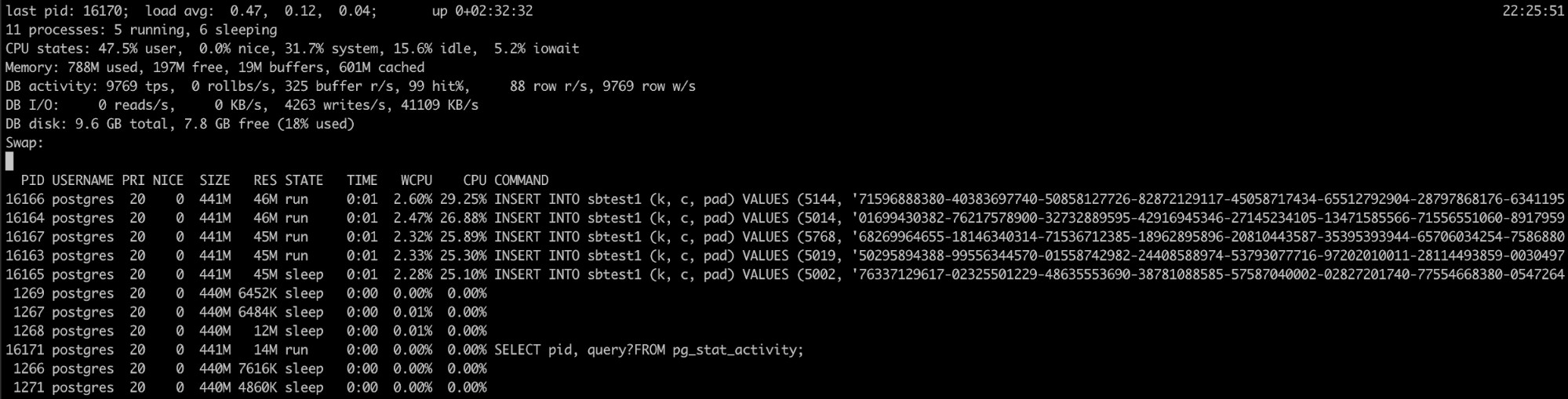
Pokud víte, že proces PostgreSQL má vysoké využití paměti, ale logy nepomohly, máte jiný nástroj, který zde může být užitečný, pg_top.
Tento nástroj je podobný špičkovému linuxovému nástroji, ale je speciálně pro PostgreSQL. Díky tomu budete mít podrobnější informace o tom, co spouští vaši databázi, a můžete dokonce zabíjet dotazy nebo spustit úlohu vysvětlení, pokud zjistíte něco špatného. Více informací o tomto nástroji naleznete zde.
Co se ale stane, když nezjistíte žádnou chybu a databáze stále využívá hodně paměti RAM. Pravděpodobně tedy budete muset zkontrolovat konfiguraci databáze.
Které konfigurační parametry vzít v úvahu
Pokud vše vypadá v pořádku, ale stále máte problém s vysokým využitím, měli byste zkontrolovat konfiguraci a ověřit, zda je správná. Níže jsou uvedeny parametry, které byste v tomto případě měli vzít v úvahu.
shared_buffers
Toto je množství paměti, kterou databázový server používá pro vyrovnávací paměti sdílené paměti. Pokud je tato hodnota příliš nízká, databáze by spotřebovala více disku, což by způsobilo větší zpomalení, ale pokud je příliš vysoká, může generovat vysoké využití paměti. Podle dokumentace, pokud máte dedikovaný databázový server s 1 GB nebo více paměti RAM, rozumná počáteční hodnota pro shared_buffers je 25 % paměti ve vašem systému.
work_mem
Udává množství paměti, které bude využito příkazy ORDER BY, DISTINCT a JOIN před zápisem do dočasných souborů na disk. Stejně jako u shared_buffers, pokud nastavíme tento parametr příliš nízko, můžeme mít na disku více operací, ale příliš vysoký je nebezpečný pro využití paměti. Výchozí hodnota je 4 MB.
max_connections
Work_mem jde také ruku v ruce s hodnotou max_connections, protože každé připojení bude provádět tyto operace ve stejnou dobu a každá operace bude mít povoleno využívat tolik paměti, kolik určuje tato hodnota před ní začne zapisovat data do dočasných souborů. Tento parametr určuje maximální počet současných připojení k naší databázi, pokud nakonfigurujeme vysoký počet připojení a nebereme to v úvahu, můžete začít mít problémy se zdroji. Výchozí hodnota je 100.
temp_buffers
Dočasné vyrovnávací paměti se používají k ukládání dočasných tabulek používaných v každé relaci. Tento parametr nastavuje maximální množství paměti pro tuto úlohu. Výchozí hodnota je 8 MB.
maintenance_work_mem
Toto je maximální paměť, kterou může zabrat operace jako vysávání, přidávání indexů nebo cizích klíčů. Dobrá věc je, že v relaci lze spustit pouze jednu operaci tohoto typu a není nejběžnější spouštět v systému několik těchto operací současně. Výchozí hodnota je 64 MB.
autovacuum_work_mem
Vakuum používá standardně maintenance_work_mem, ale můžeme jej oddělit pomocí tohoto parametru. Zde můžeme specifikovat maximální množství paměti, které může použít každý pracovník automatického vysávání.
wal_buffers
Množství sdílené paměti použité pro data WAL, která ještě nebyla zapsána na disk. Výchozí nastavení je 3 % sdílených_bufferů, ale ne méně než 64 kB a více než velikost jednoho segmentu WAL, obvykle 16 MB.
Závěr
Existují různé důvody pro vysoké využití paměti a zjišťování problému s kořenem může být časově náročný úkol. V tomto blogu jsme zmínili různé způsoby, jak zkontrolovat využití paměti PostgreSQL a který parametr byste měli vzít v úvahu při jeho vyladění, abyste se vyhnuli nadměrnému využití paměti.