Škaredý. Tak vypadají neseřazená data. Data usnadňujeme jejich tříděním. A k tomu slouží SQL ORDER BY. Použijte jeden nebo více sloupců nebo výrazů jako základ pro řazení dat. Poté přidejte ASC nebo DESC pro seřazení vzestupně nebo sestupně.
Syntaxe SQL ORDER BY:
ORDER BY <order_by_expression> [ASC | DESC]
Výraz ORDER BY může být tak jednoduchý jako seznam sloupců nebo výrazů. Může být také podmíněné pomocí bloku CASE WHEN.
Je velmi flexibilní.
Můžete také použít stránkování pomocí OFFSET a FETCH. Zadejte počet řádků, které se mají přeskočit, a řádky, které se mají zobrazit.
Ale tady jsou špatné zprávy.
Přidání ORDER BY k vašim dotazům je může zpomalit. A některá další upozornění mohou způsobit, že ORDER BY „nefunguje“. Nemůžete je jen tak použít, kdykoli budete chtít, protože mohou být penalizovány. Takže, co budeme dělat?
V tomto článku prozkoumáme, co dělat a co nedělat při používání ORDER BY. Každá položka se bude zabývat problémem a bude následovat řešení.
Jste připraveni?
Postup v SQL ORDER BY
1. Indexujte SQL ORDER BY Column(s)
Indexy jsou o rychlém vyhledávání. A mít jeden ve sloupcích, které používáte v klauzuli ORDER BY, může urychlit váš dotaz.
Začněme používat ORDER BY ve sloupci bez indexu. Použijeme AdventureWorks ukázková databáze. Před provedením níže uvedeného dotazu deaktivujte IX_SalesOrderDetail_ProductID index v SalesOrderDetail stůl. Poté stiskněte Ctrl-M a spusťte jej.
-- Get order details by product and sort them by ProductID
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT
ProductID
,OrderQty
,UnitPrice
,LineTotal
FROM Sales.SalesOrderDetail
ORDER BY ProductID
SET STATISTICS IO OFF
GO
ANALÝZA
Výše uvedený kód zobrazí statistiku I/O na kartě Zprávy v SQL Server Management Studio. Plán provádění uvidíte na další kartě.
BEZ INDEXU
Nejprve získáme logické údaje ze STATISTICS IO. Podívejte se na obrázek 1.
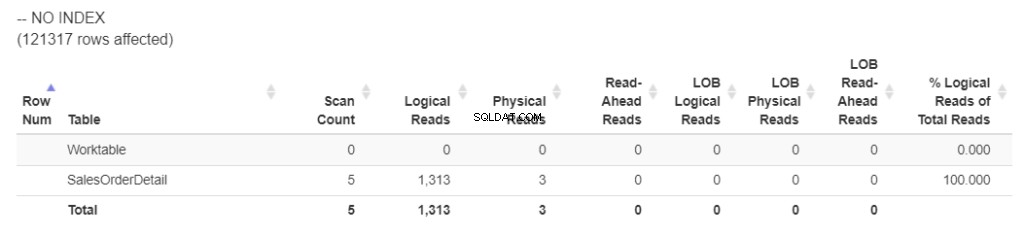
Obrázek 1 . Logické čtení pomocí ORDER BY neindexovaného sloupce. (Formátováno pomocí statisticsparser.com )
Bez indexu dotaz použil 1 313 logických čtení. A ten WorkTable ? Znamená to, že SQL Server používal TempDB zpracovat řazení.
Co se ale dělo v zákulisí? Podívejme se na plán provádění na obrázku 2.
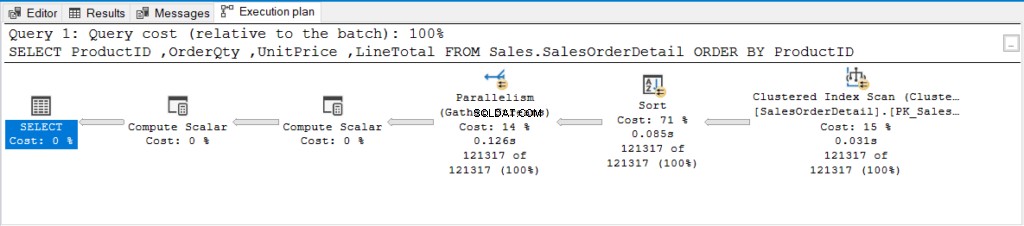
Obrázek 2 . Plán provádění dotazu pomocí ORDER BY neindexovaného sloupce.
Viděl jsi toho operátora Parallelism (Gather Streams)? Znamená to, že SQL Server použil ke zpracování tohoto dotazu více než 1 procesor. Dotaz byl dostatečně těžký, aby vyžadoval více CPU.
Co kdyby SQL Server používal TempDB a více procesorů? Na jednoduchý dotaz je to špatné.
S INDEXEM
Jak se bude dařit, pokud bude index znovu povolen? Pojďme to zjistit. Znovu vytvořte index IX_SalesOrderDetail_ProductID . Poté znovu spusťte výše uvedený dotaz.
Zkontrolujte nová logická čtení na obrázku 3.
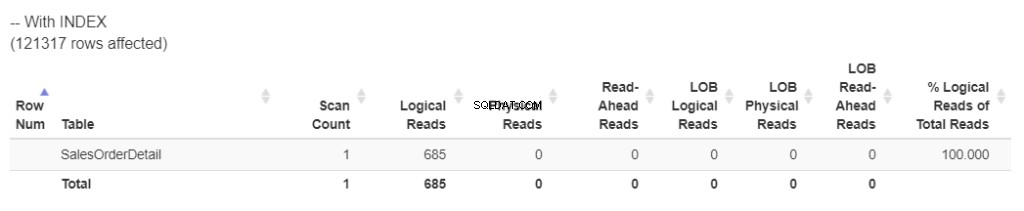
Obrázek 3 . Nové logické čtení po opětovném sestavení indexu.
Tohle je mnohem lepší. Snížili jsme počet logických čtení téměř na polovinu. To znamená, že index spotřeboval méně zdrojů. A WorkTable ? Je to pryč! Není třeba používat TempDB .
A plán realizace? Viz obrázek 4.
Obrázek 4 . Nový plán provádění je jednodušší, když byl index přestavěn.
Vidět? Plán je jednodušší. K řazení stejných 121 317 řádků nejsou potřeba další CPU.
Sečteno a podtrženo:Ujistěte se, že sloupce, které používáte pro ORDER BY, jsou indexovány .
ALE CO KDYŽ PŘIDÁNÍ INDEXU OVLIVNE VÝKON PŘI PSANÍ?
Dobrá otázka.
Pokud je to problém, můžete vypsat část zdrojové tabulky do dočasné tabulky nebo tabulky optimalizované pro paměť . Potom tuto tabulku indexujte. Použijte totéž, pokud se jedná o více stolů. Poté zhodnoťte výkon dotazu zvolené možnosti. Rychlejší možnost vyhraje.
2. Omezte výsledky pomocí WHERE a OFFSET/FETCH
Použijme jiný dotaz. Řekněme, že potřebujete zobrazit informace o produktu s obrázky v aplikaci. S obrázky mohou být dotazy ještě těžší. Nebudeme tedy kontrolovat pouze logická čtení, ale také logická čtení.
Zde je kód.
SET STATISTICS IO ON
GO
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.Color
SET STATISTICS IO OFF
GO
Výsledkem bude 97 kol s obrázky. Je velmi obtížné je procházet na mobilním zařízení.
ANALÝZA
POUŽÍVÁNÍ MINIMÁLNÍCH PODMÍNEK, BEZ ODSAHU/NAČENÍ
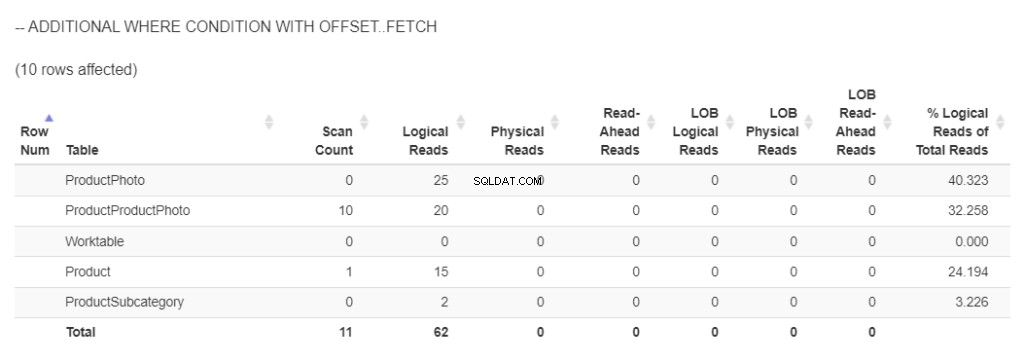
Zde je uvedeno, kolik logických čtení je potřeba k načtení 97 produktů s obrázky. Viz obrázek 5.
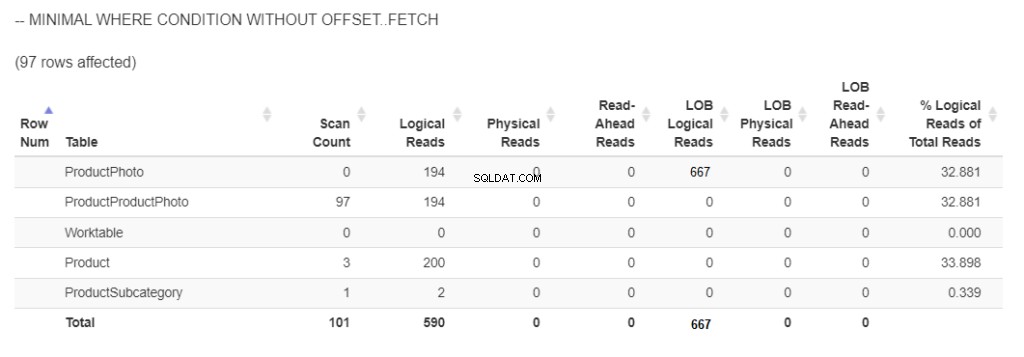
Obrázek 5 . Logická čtení a logická čtení při použití ORDER BY bez OFFSET/FETCH as minimální podmínkou WHERE . (Poznámka:statisticsparser.com neukázal logická čtení lob. Snímek obrazovky je upraveno na základě výsledku v SSMS)
Kvůli načítání obrázků ve 2 sloupcích se objevilo 667 logických čtení. Mezitím bylo pro zbytek použito 590 logických čtení.
Zde je plán provedení na obrázku 6, abychom ho později mohli porovnat s lepším plánem.
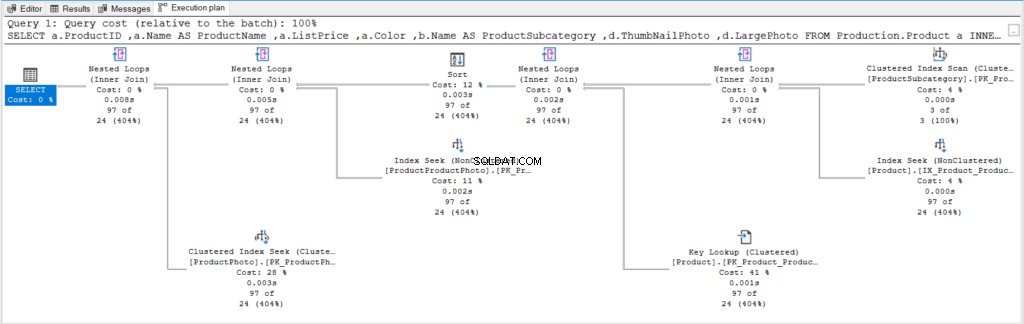
Obrázek 6 . Plán provádění pomocí ORDER BY bez OFFSET/FETCH as minimální podmínkou WHERE.
Není moc co říci, dokud neuvidíme další plán provádění.
POUŽITÍ DODATEČNÝCH STAV A OFFSET/NAČET V POŘADÍ PODLE
Nyní upravíme dotaz tak, aby bylo vráceno minimum dat. Zde je to, co uděláme:
- Přidejte podkategorii produktu podmínku. V aplikaci pro volání si můžeme představit, že necháme uživatele, aby si také vybral podkategorii.
- Potom odeberte podkategorii produktu ze seznamu sloupců SELECT a seznamu sloupců ORDER BY.
- Nakonec přidejte OFFSET/FETCH v ORDER BY. Pouze 10 produktů bude vráceno a zobrazeno v aplikaci pro volání.
Zde je upravený kód.
DECLARE @pageNumber TINYINT = 1
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
Tento kód se dále zlepší, pokud z něj uděláte uloženou proceduru. Bude mít také parametry, jako je číslo stránky a počet řádků. Číslo stránky udává, jakou stránku si uživatel aktuálně prohlíží. Toto dále vylepšete tím, že počet řádků bude flexibilní v závislosti na rozlišení obrazovky. Ale to je jiný příběh.
Nyní se podívejme na logická čtení na obrázku 7.
Obrázek 7 . Méně logických čtení po zjednodušení dotazu. OFFSET/FETCH se také používá v ORDER BY.
Potom porovnejte obrázek 7 s obrázkem 5. Logická čtení lob zmizela. Navíc došlo k výraznému snížení logických čtení, protože výsledná sada byla také snížena z 97 na 10.
Ale co dělal SQL Server v zákulisí? Podívejte se na prováděcí plán na obrázku 8.
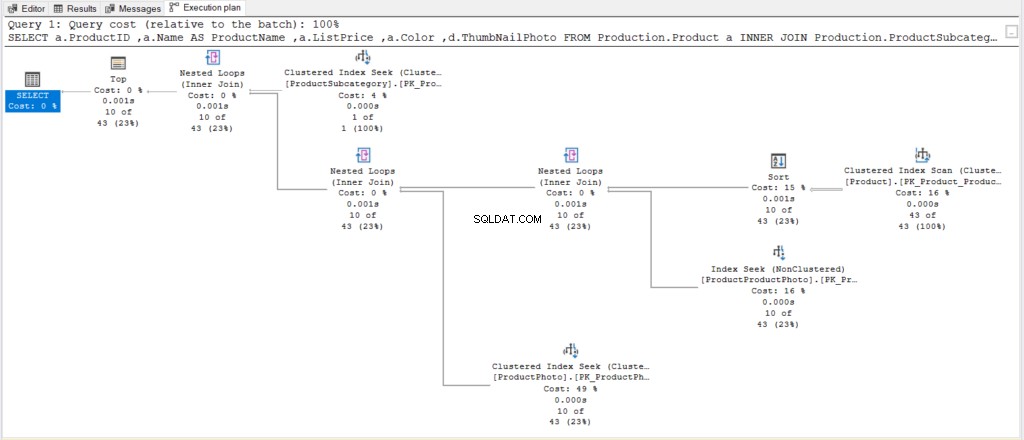
Obrázek 8 . Jednodušší plán provádění po zjednodušení dotazu a přidání OFFSET/FETCH v ORDER BY.
Poté porovnejte obrázek 8 s obrázkem 6. Aniž bychom zkoumali jednotlivé operátory, můžeme vidět, že tento nový plán je jednodušší než ten předchozí.
Lekce? Zjednodušte svůj dotaz. Kdykoli je to možné, použijte OFFSET/FETCH.
Nic v SQL ORDER BY
S tím, co musíme udělat při používání ORDER BY, jsme hotovi. Tentokrát se zaměřme na to, čemu bychom se měli vyhnout.
3. Při řazení podle klíče seskupeného rejstříku nepoužívejte ORDER BY
Protože je to zbytečné.
Ukažme si to na příkladu.
SET STATISTICS IO ON
GO
-- Using ORDER BY with BusinessEntityID - the primary key
SELECT TOP 100 * FROM Person.Person
ORDER BY BusinessEntityID;
-- Without using ORDER BY at all
SELECT TOP 100 * FROM Person.Person;
SET STATISTICS IO OFF
GO
Poté zkontrolujme logické čtení obou příkazů SELECT na obrázku 9.
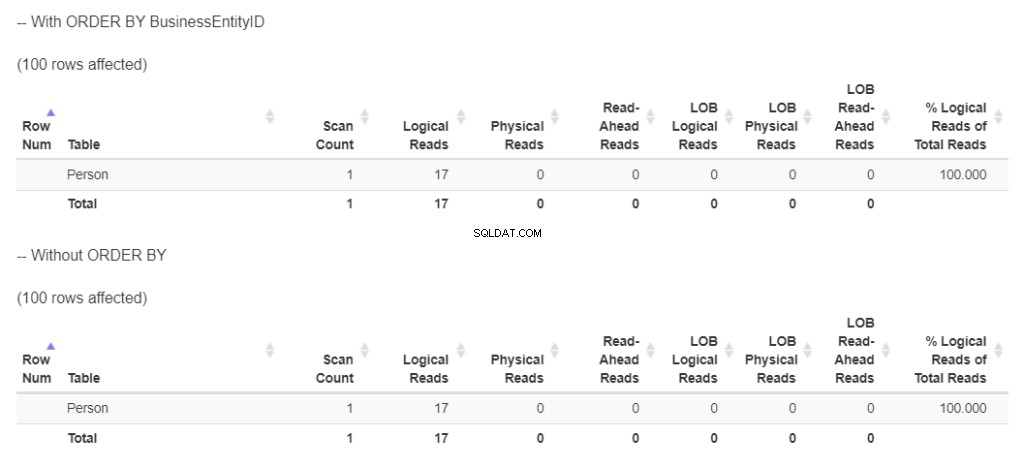
Obrázek 9 . 2 dotazy v tabulce Osoba ukazují stejná logická čtení. Jeden je s ORDER BY, druhý bez.
Oba mají 17 logických čtení. To je logické, protože se vrátilo stejných 100 řádků. Mají ale stejný plán? Podívejte se na obrázek 10.
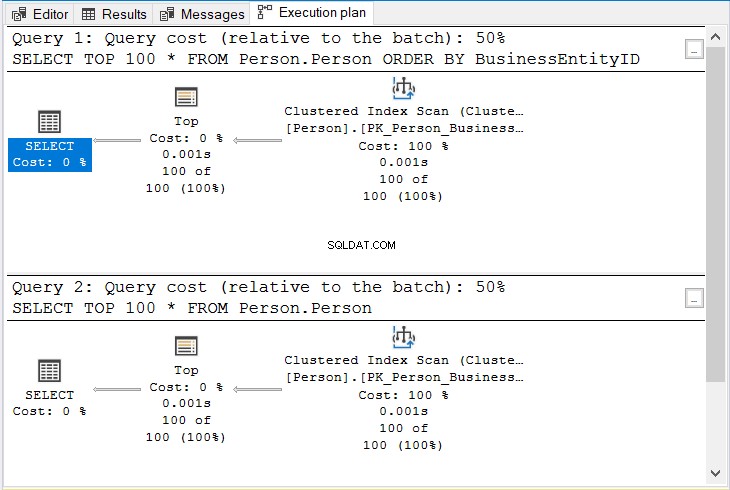
Obrázek 10 . Stejný plán bez ohledu na to, zda se při řazení podle seskupeného indexového klíče použije ORDER BY či nikoli.
Sledujte stejné operátory a stejnou cenu dotazu.
Ale proč? Při indexování jednoho nebo více sloupců do seskupeného indexu bude tabulka fyzicky seřazena pomocí seskupeného indexového klíče. Takže i když neprovedete řazení podle tohoto klíče, výsledek bude stále seřazen.
Sečteno a podtrženo? Odpusťte si tím, že v podobných případech pomocí ORDER BY nepoužijete seskupený indexový klíč . Šetřete energii menším počtem stisknutí kláves.
4. Nepoužívejte ORDER BY , když sloupec String obsahuje čísla
Pokud třídíte podle sloupce řetězce obsahujícího čísla, neočekávejte pořadí řazení jako u typů reálných čísel. Jinak vás čeká velké překvapení.
Zde je příklad.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY NationalIDNumber;
Zkontrolujte výstup na obrázku 11.
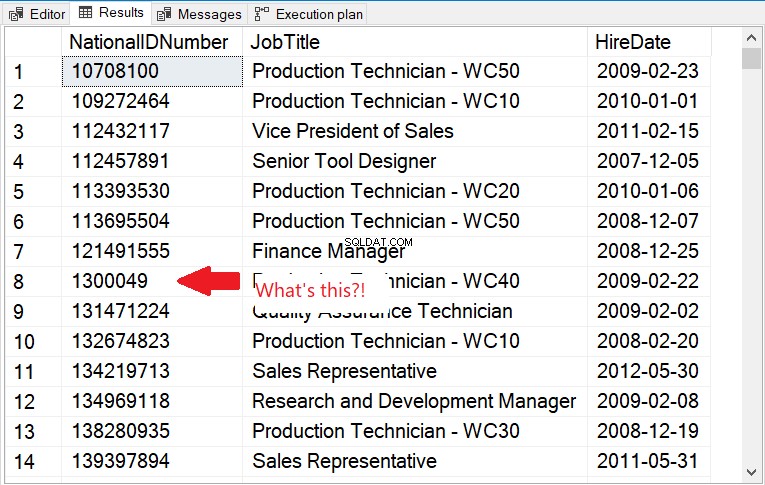
Obrázek 11 . Pořadí řazení sloupce řetězce obsahujícího čísla. Číselná hodnota není dodržena.
Na obrázku 11 je dodrženo lexikografické řazení. Chcete-li to vyřešit, použijte CAST na celé číslo.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT)
Pevný výstup naleznete na obrázku 12.
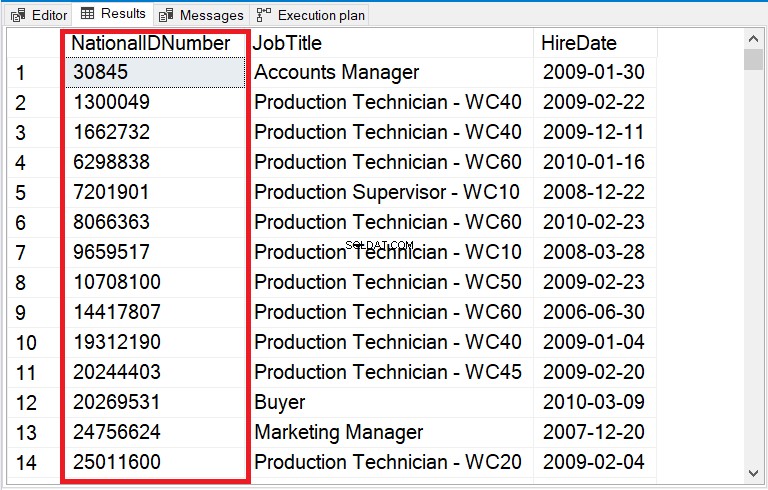
Obrázek 12 . CAST na INT opravil řazení sloupce řetězce obsahujícího čísla.
Takže místo ORDER BY
5. Nepoužívejte SELECT INTO #TempTable s ORDER BY
Požadované pořadí řazení nebude v cílové dočasné tabulce zaručeno. Podívejte se na oficiální dokumentaci .
Mějme upravený kód z předchozího příkladu.
SELECT
NationalIDNumber
,JobTitle
,HireDate
INTO #temp
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT);
SELECT * FROM #temp;
Jediný rozdíl oproti předchozímu příkladu je klauzule INTO. Výstup bude stejný jako na obrázku 11. Jsme zpět na čtverci 1, i když sloupec CASTneme do INT.
Musíte vytvořit dočasnou tabulku pomocí CREATE TABLE. Zahrňte však další sloupec identity a udělejte z něj primární klíč. Potom INSERT do dočasné tabulky.
Zde je pevný kód.
CREATE TABLE #temp2
(
id INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
NationalIDNumber NVARCHAR(15) NOT NULL,
JobTitle NVARCHAR(50) NOT NULL,
HireDate DATE NOT NULL
)
GO
INSERT INTO #temp2
(NationalIDNumber, JobTitle, HireDate)
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT);
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM #Temp2;
A výstup bude stejný jako na obrázku 12. Funguje to!
Poznámky v používání SQL ORDER BY
Probrali jsme běžná úskalí při používání SQL ORDER BY. Zde je shrnutí:
Postup :
- Indexujte sloupce ORDER BY,
- Omezte výsledky pomocí WHERE a OFFSET/FETCH,
Ne :
- Při řazení podle seskupeného indexového klíče nepoužívejte ORDER BY,
- Nepoužívejte ORDER BY, pokud sloupec řetězce obsahuje čísla. Místo toho nejprve CAST sloupec řetězce na INT.
- Nepoužívejte SELECT INTO #TempTable s ORDER BY. Místo toho nejprve vytvořte dočasnou tabulku s dalším sloupcem identity.
Jaké jsou vaše tipy a triky při používání ORDER BY? Dejte nám vědět v sekci Komentáře níže. A pokud se vám tento příspěvek líbí, sdílejte jej na svých oblíbených platformách sociálních médií.