Lidé obecně neradi dostávají nevyžádané e-maily. Přesto se někdy přihlásí k odběru novinek, aby získali slevu nebo aby byli informováni o nových produktech. Tento článek představí jeden přístup k navrhování databáze newsletterů.
Proč se obávat e-mailů s newsletterem?
Odběratelé newsletteru představují mimořádně cennou skupinu klientů – zajímají se o naše produkty, důvěřují nám a tráví čas prohlížením našich nabídek a akcí. Zasílání e-mailů klientům je navíc jedním z nejlevnějších nástrojů online marketingu. Je však potřeba to dělat opatrně – data musí být denně aktualizována (protože se lidé přihlašují a odhlašují) a musí být kvalitní (nechceme posílat nevyžádané e-maily, protože to negativně ovlivňuje image značky).
Nabízí se tedy otázka, jak zvládnout tento proces získávání kvalitních dat a jejich každodenní aktualizaci. Existuje mnoho možností ...
A vítězem je...
Zákaznická analytika! V dnešní době je nejdůležitějším faktorem, jak si udržet náskok před konkurencí, najít poznatky z dat a na jejich základě přijímat obchodní rozhodnutí. Nebylo by skvělé podívat se do historie zasílání newsletterů a analyzovat jejich intenzitu a efektivitu? Pro každého zákazníka? A pak se k tomu připojit s údaji o nákupu, odhalit zájmy zákazníka, připravit individuální doporučení a odeslat je pomocí personalizovaných e-mailů?
Takový přístup by jistě zvýšil náš konverzní poměr (CR). Konverzní poměr je jedním z nejdůležitějších klíčových ukazatelů výkonnosti online marketingu; ukazuje, kolik lidí provedlo nákup poté, co viděli některé z našich propagačních materiálů (reklamy, informační bulletiny atd.). Vysoká CR znamená vyšší efektivitu podnikání.
Nyní, když rozumíme některým souvisejícím marketingům, pojďme se pustit do datového modelu!
Začněme modelovat databázi newsletterů!
Když se do toho pustíme, vidíme, že dvě hlavní tabulky v modelu jsou client a newsletter tabulky.
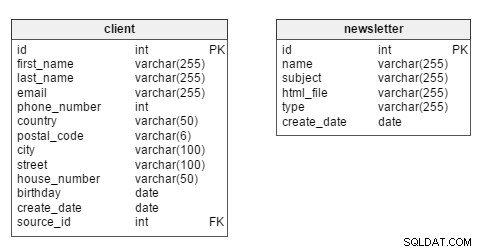
Protože nás bude nejvíce zajímat analýza klienta, client stůl by měl zůstat ve středu modelu. V této tabulce má každý klient své vlastní jedinečné id . Uložíme také takové informace, jako je first_name klienta a last_name , kontaktní údaje (email , phone_number , adresa), birthday , create_date (když byl záznam zákazníka vložen do databáze) a jeho source_id – tj. zda se zaregistrovali na našich stránkách nebo nám jejich údaje poskytl nějaký obchodní partner.
newsletter tabulka ukládá data týkající se každého vytvoření newsletteru. Zpravodaje lze identifikovat na základě jejich jedinečného id . Každý je popsán name (např. „Nová kolekce dámského oblečení – podzim 2016“) e-mailem subject („Nejmódnější oblečení pro ni – kup teď!“), html_file (soubor obsahující HTML kód pro daný newsletter), newsletter type (např. „nová kolekce“, „narozeninový zpravodaj“) a create_date .
Marketingové souhlasy
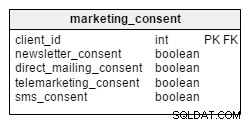
Aby společnost mohla zasílat marketingové informace (poštou, telefonicky, e-mailem nebo SMS), potřebuje od svých zákazníků získat souhlas. V našem modelu jsou souhlasy uloženy v samostatné tabulce s názvem marketing_consent . Uchovává informace o aktuální sadě marketingových souhlasů pro všechny naše zákazníky. Souhlasy jsou kódovány jako booleovské proměnné – TRUE (souhlasí s marketingovou komunikací) nebo FALSE (nesouhlasí).
Je velmi důležité uchovávat informace o tom, kdy zákazník souhlasil s přijímáním reklam prostřednictvím jednotlivých komunikačních kanálů. Je také užitečné zaznamenat, kdy odvolali svůj souhlas pro každý kanál. Pro tyto účely consent_change stůl byl navržen.
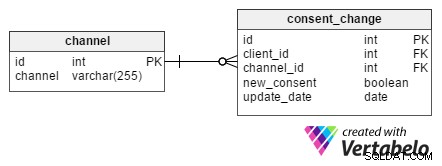
Každá změna má jedinečné id a je přiřazeno konkrétnímu klientovi pomocí jeho client_id . Když klient požádá o odebrání z e-mailů se zpravodajem, id zpravodaje z channel tabulka bude také uložena v consent_change channel_id tabulky atribut. new_consent je logická hodnota (TRUE nebo FALSE) a představuje nové marketingové souhlasy.
update_date sloupec obsahuje datum, kdy zákazník požádal o změnu. Tato struktura nám umožňuje extrahovat sadu souhlasů pro všechny klienty v daný den. Je velmi užitečné, pokud si klient stěžuje na obdržení e-mailu poté, co se již odhlásil z odběru našeho newsletteru. S těmito uloženými informacemi můžeme zkontrolovat, kdy došlo k odhlášení z odběru, a doufejme, že k tomu došlo po odeslání e-mailového zpravodaje.
Udržování pořádku v rozesílání
Navrhnout dokonalý databázový model pro zasílání newsletterů není hračka. Proč? Je zřejmé, že musíme být schopni identifikovat jakýkoli jednotlivý výtvor newsletteru (myšleno rozložení, grafika, produkty, odkazy atd.). Víme také, že jeden výtvor lze odeslat vícekrát:manažeři se mohou rozhodnout, že jeden kyblík e-mailů bude poslán ráno polovině klientů a večer druhé polovině. Je tedy klíčové evidovat, kteří klienti obdrželi jaký newsletter a kdy. Proto se tato část modelu skládá ze tří tabulek:
newslettertabulka – kterou jsme popsali dříve.newsletter_sendouttabulka – která identifikuje jedno odeslání. Například vánoční zpravodaj (id =“2512”) byl zaslán e-mailem 10. prosince v 18:00. Toto vedení záznamů umožňuje obchodníkům zasílat stejný newsletter různým skupinám zákazníků v různých časech.sendout_receiverstabulka – která shromažďuje údaje o příjemcích každého rozeslání. Pro každý e-mail z každého odeslání bude jeden záznam. Každý řádek má tři sloupce:id(identifikující událost odeslání e-mailu klientovi),client_id(identifikující klienty z naší databáze) anl_sendout_id(identifikující zasílání newsletteru).
Zde je úplný model zpravodaje:
Nějaké nápady, jak tento model vylepšit?
Jedním z možných způsobů je přidat response stůl. To by uložilo reakce zákazníků – ať už otevřeli e-mail, klikli na reklamu nebo zprávu nikdy neviděli, protože byla označena jako spam. Kam máme přidat response tabulky k našemu modelu a jaký vztah by měl být aplikován? Podělte se o své myšlenky v sekci komentářů níže.