Opakující se událost je podle definice událost, která se opakuje v určitém intervalu; nazývá se to také periodická událost. Existuje mnoho aplikací, které svým uživatelům umožňují nastavit opakující se události. Jak databázový systém spravuje opakující se události? V tomto článku prozkoumáme jeden způsob, jak se s nimi zachází.
S opakováním není snadné se aplikace vypořádat. Může se stát hurikánovým úkolem, zejména pokud jde o pokrytí všech možných opakujících se scénářů – včetně vytváření dvoutýdenních nebo čtvrtletních událostí nebo umožnění přeplánování všech budoucích instancí událostí.
Dva způsoby správy opakujících se událostí
Napadají mě alespoň dva způsoby, jak zvládnout periodické úlohy v datovém modelu. Než je probereme, pojďme si rychle projít požadavky tohoto úkolu. Stručně řečeno, efektivní řízení znamená:
- Uživatelé mohou vytvářet pravidelné a opakující se události.
- Denní, týdenní, dvoutýdenní, měsíční, čtvrtletní, dvouleté a roční události lze vytvářet bez omezení data ukončení.
- Uživatelé mohou přeplánovat nebo zrušit instanci události nebo všechny budoucí instance události.
Vzhledem k těmto parametrům přicházejí na mysl dva způsoby, jak spravovat opakující se události v datovém modelu. Budeme jim říkat naivní a expertní.
Naivní způsob: Ukládání všech možných opakujících se instancí události jako samostatné řádky v tabulce. V tomto řešení požadujeme pouze jednu tabulku, a to event . Tato tabulka obsahuje sloupce jako event_title , start_date , end_date , is_full_day_event , atd. start_date a end_date sloupce jsou datové typy časových razítek; tímto způsobem mohou pojmout události, které netrvají celý den.
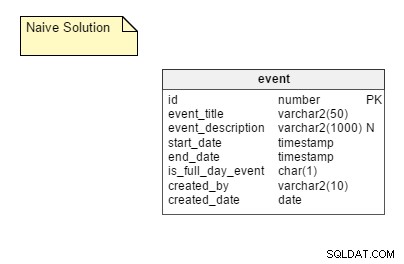
Výhody: Jedná se o poměrně přímočarý přístup a nejjednodušší na implementaci.
Nevýhody: Naivní způsob má některé významné nevýhody, včetně:
- Potřeba uložit všechny možné instance události. Pokud berete v úvahu potřeby velké uživatelské základny, je zapotřebí velký kus místa. Prostor je však docela levný, takže tento bod nemá žádný zásadní vliv.
- Velmi chaotický proces aktualizace. Předpokládejme, že událost je přeplánována. V takovém případě musí někdo aktualizovat všechny jeho instance. Při změně plánu je potřeba provést obrovské množství operací DML, což má negativní dopad na výkon aplikace.
- Zpracování výjimek. Se všemi výjimkami je třeba zacházet elegantně, zvláště pokud se musíte vrátit a upravit původní schůzku po provedení výjimky. Předpokládejme například, že přesunete třetí výskyt opakující se události o jeden den dopředu. Co když následně upravíte čas původní události? Vložíte znovu jinou událost v původní den a ponecháte tu, kterou jste přinesli? Odpojit výjimku? Zkusit to vhodně změnit?
Event_id– Na tento sloupec odkazujeeventa v této tabulce funguje jako primární klíč. Ukazuje identifikační vztah mezieventarecurring_patterntabulky. Tento sloupec také zajistí, že pro každou událost existuje maximálně jeden opakující se vzor.Recurring_type_id– Tento sloupec označuje typ opakování, ať už je to denní, týdenní, měsíční nebo roční.Max_num_of_occurrances– Jsou chvíle, kdy neznáme přesné datum ukončení události, ale víme, kolik výskytů (schůzek) je potřeba k jejímu dokončení. V tomto sloupci je uloženo libovolné číslo, které definuje logický konec události.Separation_count– Možná se divíte, jak lze nakonfigurovat dvoutýdenní nebo dvouletou událost, pokud existují pouze čtyři možné hodnoty typu opakování (denně, týdně, měsíčně, ročně). Odpověď jeseparation_countsloupec. Tento sloupec označuje interval (ve dnech, týdnech nebo měsících), než je povolena další instance události. Pokud je například potřeba konfigurovat událost každý druhý týden, pak separation_count =„1“ splnit tento požadavek. Výchozí hodnota pro tento sloupec je „0“.recurring_type_idbude „týdenní“.separation_countbude „1“.day_of_weekbude „2“.Week_of_month– Tento sloupec je pro události, které jsou naplánovány na určitý týden v měsíci – tedy první, druhý, poslední, předposlední atd. Tyto hodnoty můžeme uložit jako 1,2,3, 4,.. (počítáno od začátek měsíce) nebo -1,-2,-3,... (počítáno od konce měsíce).Day_of_month– Existují případy, kdy je událost naplánována na určitý den v měsíci, řekněme 25. Tento sloupec splňuje tento požadavek. Jakoweek_of_month, může být vyplněno kladnými čísly („7“ pro 7. den od začátku měsíce) nebo zápornými čísly („-7“ pro sedmý den od konce měsíce).recurring_type_idbude „měsíční“.separation_countbude „2“.day_of_monthbude „11“.- Všechny zbývající sloupce by byly prázdné.
- Události, ke kterým dochází o svátcích. Pokud k určité události dojde ve státní svátek, měla by být automaticky přesunuta na pracovní den bezprostředně následující po svátku? Nebo by se to mělo automaticky zrušit? Za jakých okolností by se jedna z nich použila?
- Konflikty mezi událostmi. Co když určité události (které se vzájemně vylučují) připadají na stejný den?
Postup pro odborníky: Ukládání opakujícího se vzoru a programové generování minulých a budoucích instancí událostí. Toto řešení řeší nevýhody naivního řešení. Odborné řešení podrobně vysvětlíme v tomto článku.
Navrhovaný model
Vytváření událostí
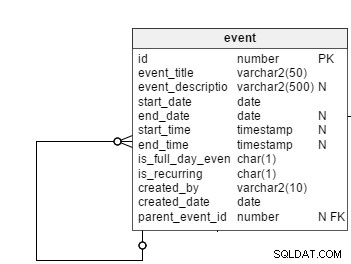
Všechny naplánované události, bez ohledu na jejich pravidelnou nebo opakující se povahu, jsou zaznamenány v event stůl. Ne všechny události jsou opakující se události, takže budeme potřebovat sloupec vlajky is_recurring , v této tabulce explicitně specifikovat opakující se události. event_title a event_description sloupce ukládají předmět a stručný souhrn událostí. Popisy událostí jsou volitelné, proto je v tomto sloupci povolena hodnota Null.
Jak jejich názvy napovídají, start_date a end_date sloupce obsahují data začátku a konce událostí. V případě pravidelných událostí jsou v těchto sloupcích uložena skutečná data zahájení a ukončení. Ukládají však také data prvního a posledního výskytu periodických událostí. end_date zachováme jako nullable, protože uživatelé mohou konfigurovat opakující se události bez data ukončení. V tomto případě by se v uživatelském rozhraní zobrazily budoucí výskyty až do hypotetického koncového data (řekněme za rok).
is_full_date_event sloupec označuje, zda se jedná o celodenní událost. V případě celodenní události start_time a end_time sloupce by byly null; to je důvod, proč ponechat oba tyto sloupce nulovatelné.
created_by a created_date sloupce ukládají, který uživatel vytvořil událost, a datum, kdy byla událost vytvořena.
Dále je zde parent_event_id sloupec. To hraje hlavní roli v našem datovém modelu. Jeho význam vysvětlím později.
Správa opakování
Nyní se dostáváme přímo k hlavnímu problému:Co když se v event tabulka – tj. is_recurring příznak události je „Y“?
Jak bylo vysvětleno dříve, budeme ukládat opakující se vzor pro události, abychom mohli sestavit všechny jeho budoucí výskyty. Začněme vytvořením recurring_pattern stůl. Tato tabulka má následující sloupce:
Podívejme se na význam zbývajících sloupců z hlediska různých typů opakování.
Denní opakování
Opravdu potřebujeme zachytit vzorec pro denně se opakující událost? Ne, protože všechny podrobnosti potřebné k vygenerování vzoru denního opakování jsou již zaznamenány v event tabulka.
Jediný scénář, který vyžaduje vzor, je, když jsou události naplánovány na jiné dny nebo každých X dní. V tomto případě separation_count nám pomůže pochopit vzorec opakování a odvodit další instance.
Týdenní opakování
Požadujeme pouze jeden další sloupec, day_of_week , k uložení, který den v týdnu se tato událost bude konat. Za předpokladu, že pondělí je první den v týdnu a neděle je poslední, možné hodnoty by byly 1,2,3,4,5,6 a 7. Podle potřeby by měly být provedeny příslušné změny v kódu, který generuje jednotlivé výskyty událostí. Všechny zbývající sloupce budou pro týdenní události prázdné.
Vezměme si klasický typ týdenní události:dvoutýdenní událost. V tomto případě řekneme, že se to stane každý druhý týden v úterý, druhý den v týdnu. Takže:

Měsíční opakování
Kromě day_of_week , potřebujeme dva další sloupce, abychom splnili jakýkoli měsíční scénář opakování. Stručně řečeno, tyto sloupce jsou:
Podívejme se nyní na složitější příklad – čtvrtletní událost. Předpokládejme, že společnost naplánuje čtvrtletní projekci výsledků na 11. den prvního měsíce v každém čtvrtletí (obvykle leden, duben, červenec a říjen). Takže v tomto případě:
Ve výše uvedeném příkladu předpokládáme, že uživatel vytváří projekci čtvrtletního výsledku v lednu. Upozorňujeme, že tato logika oddělení se začne počítat od měsíce, týdne nebo dne, kdy byla událost vytvořena.
Na podobných řádcích lze půlroční události zaznamenávat jako měsíční události s
Každoroční opakování je docela jednoduché. Máme sloupce pro konkrétní dny v týdnu a měsíc, takže potřebujeme pouze jeden další sloupec pro měsíc v roce. Tento sloupec jsme nazvali
Nyní pojďme k výjimkám. Co když je určitá instance opakující se události zrušena nebo přeplánována? Všechny takové instance jsou protokolovány samostatně ve
Podívejme se na dva sloupce,
Kromě těchto dvou sloupců fungují všechny zbývající sloupce stejně jako v
Existují aplikace, které uživatelům umožňují přeplánovat všechny budoucí výskyty opakující se události. V takových případech máme dvě možnosti. Všechny budoucí instance můžeme uložit do
S tímto řešením můžeme získat všechny minulé výskyty události, i když byl změněn její vzorec opakování.
Kolem opakujících se událostí jsou některé složitější oblasti, o kterých jsme nemluvili. Zde jsou dva:
Jaké změny musíme provést, abychom tyto schopnosti zabudovali? Sdělte nám prosím své názory v sekci komentářů.separation_count z „5“.
Roční opakování
month_of_year .
Zpracování výjimek opakujících se událostí
event_instance_exception stůl. Is_rescheduled a is_cancelled . Tyto sloupce označují, zda je tato instance přeplánována na pozdější datum/čas nebo zda byla zcela zrušena. Proč pro to mám dva samostatné sloupce? No, jen si vzpomeňte na události, které byly nejprve přeplánovány a později úplně zrušeny. To se stává a my máme způsob, jak to pomocí těchto sloupců zaznamenat. event tabulka.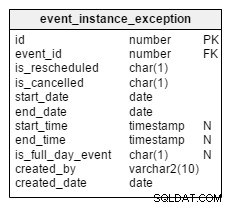
Proč propojovat dvě události pomocí
parent_event_id ?event_instance_exception (nápověda:nepřijatelné řešení). Nebo můžeme vytvořit novou událost s novými parametry data/času v event tabulku a propojte ji s její dřívější událostí (nadřazenou událostí) pomocí id_parent_event sloupec. Jak zlepšit zpracování opakujících se událostí?