
T-SQL Tuesday #78 je hostitelem Wendy Pastrick a výzvou tohoto měsíce je jednoduše „naučit se něco nového a blogovat o tom“. Její sdělení se přiklání k novým funkcím v SQL Server 2016, ale protože jsem o mnoha z nich psal a prezentoval, myslel jsem si, že z první ruky prozkoumám něco jiného, co mě vždy opravdu zajímalo.
Viděl jsem několik lidí, kteří uvedli, že halda může být pro určité scénáře lepší než seskupený index. S tím nemohu nesouhlasit. Jedním ze zajímavých důvodů, které jsem uvedl, je, že vyhledávání RID je rychlejší než vyhledávání klíčů. Jsem velkým fanouškem seskupených indexů a ne velkým fanouškem hald, takže jsem cítil, že to potřebuje nějaké testování.
Takže, pojďme to otestovat!
Myslel jsem, že by bylo dobré vytvořit databázi se dvěma tabulkami, identickými, až na to, že jedna měla klastrovaný primární klíč a druhá měla klastrovaný primární klíč. Chtěl bych načasovat načtení několika řádků do tabulky, aktualizaci řady řádků ve smyčce a výběr z indexu (vynucení vyhledávání klíče nebo RID).
Specifikace systému
Tato otázka se často objevuje, takže abych si ujasnil důležité detaily o tomto systému, jsem na 8jádrovém VM s 32 GB RAM, podpořené PCIe úložištěm. Verze SQL Serveru je 2014 SP1 CU6, bez spuštěných speciálních změn konfigurace nebo příznaků trasování:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)13. dubna 2016 12:41:07
Copyright (c) Microsoft Corporation
Developer Edition (64- bit) v systému Windows NT 6.3
Databáze
Vytvořil jsem databázi se spoustou volného místa v souboru dat i protokolu, abych zabránil tomu, aby jakékoli události autogrow narušovaly testy. Také jsem nastavil databázi na jednoduchou obnovu, abych minimalizoval dopad na protokol transakcí.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
Tabulky
Jak jsem řekl, dvě tabulky, s jediným rozdílem, zda je primární klíč seskupený.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Tabulka pro zachycení doby běhu
Mohl bych monitorovat CPU a vše ostatní, ale ve skutečnosti je zvědavost téměř vždy kolem běhu. Vytvořil jsem tedy protokolovací tabulku pro zachycení doby běhu každého testu:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
Test vložení
Jak dlouho tedy trvá vložení 2 000 řádků 100krát? Získávám několik docela základních dat z sys.all_objects a vytažením definice pro všechny procedury, funkce atd.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Test aktualizace
U testu aktualizace jsem chtěl jen otestovat rychlost zápisu do seskupeného indexu vs. hromadu způsobem velmi řádek po řádku. Vysypal jsem tedy 200 náhodných řádků do tabulky #temp a poté jsem kolem ní postavil kurzor (tabulka #temp pouze zajišťuje aktualizaci stejných 200 řádků v obou verzích tabulky, což je pravděpodobně přehnané).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Test výběru
Takže výše jste viděli, že jsem vytvořil index s Name jako klíčový sloupec v každé tabulce; za účelem vyhodnocení nákladů na provádění vyhledávání pro značné množství řádků jsem napsal dotaz, který přiřazuje výstup proměnné (eliminuje síťový I/O a dobu vykreslování klienta), ale vynucuje použití indexu:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; V tomto případě jsem chtěl ukázat některé zajímavé aspekty plánů, než shromáždím výsledky testů. Pokud je spouštíte jednotlivě přímo, poskytuje tyto srovnávací metriky:

Doba trvání je u jednoho příkazu nepodstatná, ale podívejte se na tato čtení. Pokud používáte pomalé úložiště, je to velký rozdíl, který v menším měřítku a/nebo na vašem místním vývojovém SSD disku neuvidíte.
A pak plány ukazující dvě různá vyhledávání pomocí SQL Sentry Plan Explorer:

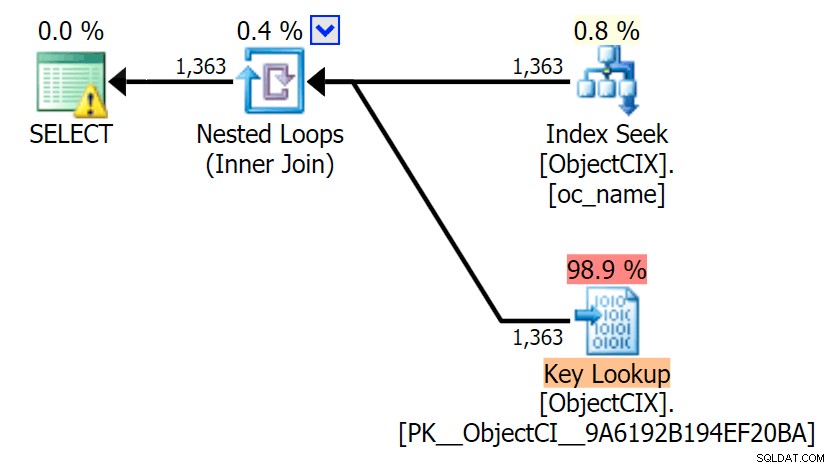
Plány vypadají téměř identicky a možná si nevšimnete rozdílu ve čteních v SSMS, pokud jste nezachycovali Statistiky I/O. Dokonce i odhadované I/O náklady pro tato dvě vyhledávání byly podobné – 1,69 pro vyhledávání klíčů a 1,59 pro vyhledávání RID. (Ikona varování v obou plánech se týká chybějícího indexu pokrytí.)
Je zajímavé poznamenat, že pokud nevynutíme vyhledávání a neumožníme SQL Serveru rozhodnout, co má dělat, zvolí v obou případech standardní skenování – žádné chybějící varování indexu a podíváme se na to, o kolik bližší jsou hodnoty:

Optimalizátor ví, že skenování bude v tomto případě mnohem levnější než vyhledávání + vyhledávání. Sloupec LOB jsem pro přiřazení proměnných zvolil pouze pro efekt, ale výsledky byly podobné i při použití sloupce bez LOB.
Výsledky testu
S tabulkou Časování jsem byl schopen snadno spustit testy vícekrát (provedl jsem tucet testů) a poté přijít s průměry pro testy s následujícím dotazem:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
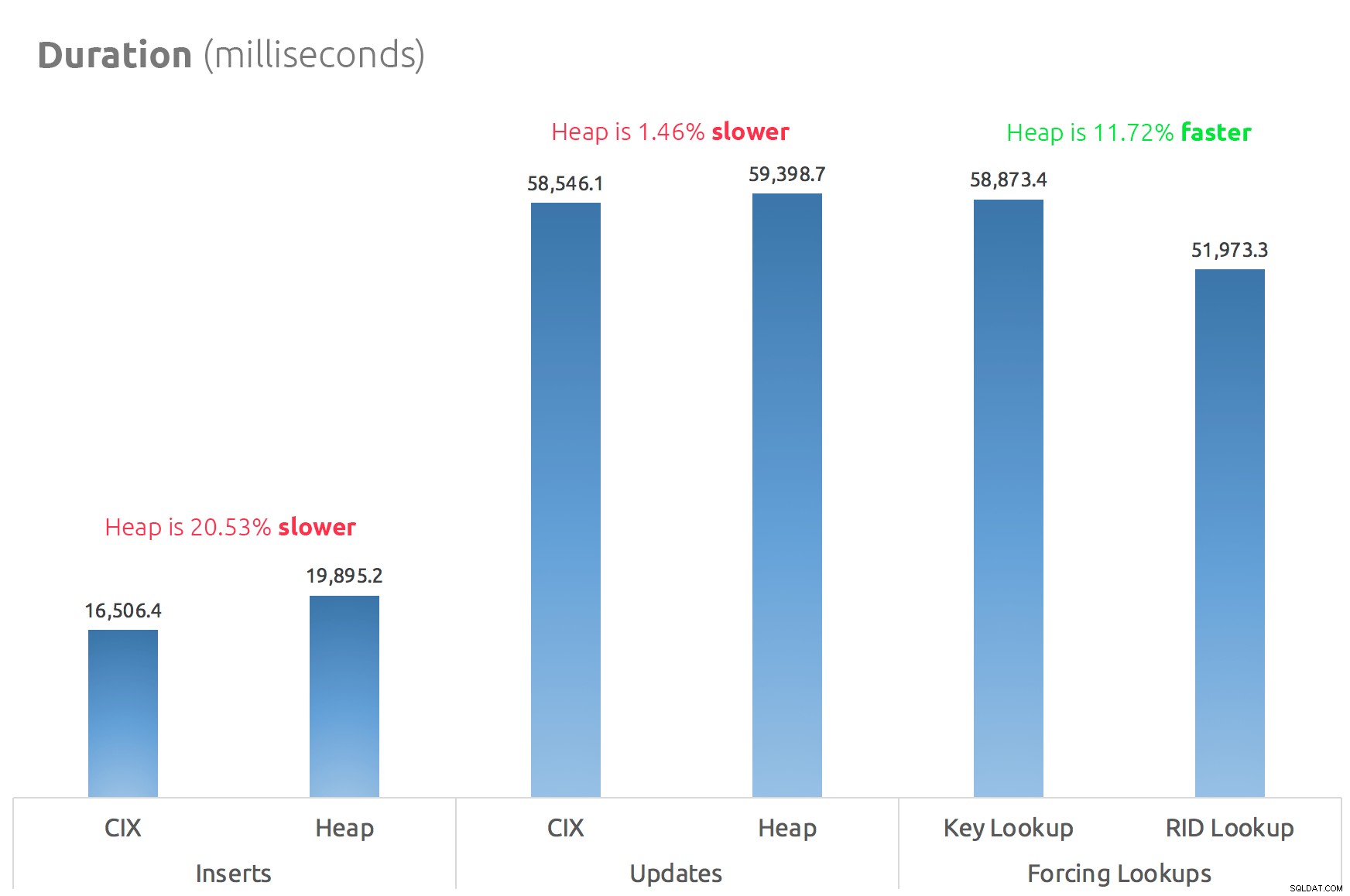
Jednoduchý sloupcový graf ukazuje, jak se porovnávají:
Závěr
Pověsti jsou tedy pravdivé:alespoň v tomto případě je vyhledávání RID výrazně rychlejší než vyhledávání klíčů. Přejít přímo na file:page:slot je samozřejmě efektivnější z hlediska I/O než sledování b-stromu (a pokud nepoužíváte moderní úložiště, může být delta mnohem znatelnější).
Zda toho chcete využít a vzít s sebou všechny další aspekty haldy, bude záviset na vaší zátěži – halda je o něco dražší pro operace zápisu. Ale to není definitivní – může se značně lišit v závislosti na struktuře tabulky, indexech a vzorech přístupu.
Testoval jsem zde velmi jednoduché věci, a pokud jste v tomto ohledu na plot, vřele doporučuji otestovat vaši skutečnou zátěž na vlastním hardwaru a porovnat sami (a nezapomeňte otestovat stejnou zátěž tam, kde jsou přítomny krycí indexy; pravděpodobně dosáhnete mnohem lepšího celkového výkonu, pokud jednoduše úplně odstraníte vyhledávání). Ujistěte se, že měříte všechny metriky, které jsou pro vás důležité; to, že se zaměřuji na trvání, neznamená, že je to ten, na kterém se musíte nejvíce zajímat. :-)