Všichni děláme chyby a všichni se můžeme poučit z chyb jiných lidí. V tomto příspěvku se podíváme na četné online zdroje, jak se vyhnout špatnému návrhu databáze, který může vést k mnoha problémům a stojí čas i peníze. A v nadcházejícím článku vám řekneme, kde najdete tipy a osvědčené postupy.
Chyby v návrhu databáze a chyby, kterým je třeba se vyhnout
Existuje mnoho online zdrojů, které pomáhají návrhářům databází vyhnout se běžným chybám a omylům. Je zřejmé, že tento článek není vyčerpávajícím seznamem všech dostupných článků. Místo toho jsme zkontrolovali a okomentovali řadu různých zdrojů, abyste mohli najít ten, který vám nejlépe vyhovuje.
Naše doporučení
Pokud je mezi těmito zdroji pouze jeden článek, který se chystáte číst, měl by to být „Jak dosáhnout toho, že návrh databáze je strašně špatný“ od Roberta Sheldona
Začněme blogem DATAVERSITY, který poskytuje širokou sadu docela dobrých zdrojů:
Chyby primárního a cizího klíče, kterým je třeba se vyhnout
od Michaela Blahy | Blog DATAVERSITY | 2. září 2015
Více chyb návrhu databáze – záměna se vztahy mnoho k mnoha
od Michaela Blahy | Blog DATAVERSITY | 30. září 2015
Různé chyby návrhu databáze
od Michaela Blahy | Blog DATAVERSITY | 26. října 2015
Michael Blaha přispěl pěkným souborem tří článků. Každý článek se zabývá různými úskalími databázového modelování a fyzického návrhu; témata zahrnují klíče, vztahy a obecné chyby. Kromě toho probíhají s Michaelem diskuse ohledně některých bodů. Pokud hledáte úskalí kolem klíčů a vztahů, tady by bylo dobré začít.
Pan Blaha uvádí, že „asi 20 % databází porušuje pravidla primárního klíče“. Páni! To znamená, že asi 20 % vývojářů databází nevytvořilo správně primární klíče. Pokud je tato statistika pravdivá, pak skutečně ukazuje důležitost nástrojů pro modelování dat, které silně „vybízejí“ nebo dokonce vyžadují, aby modeláři definovali primární klíče.
Pan Blaha také sdílí heuristiku, že „asi 50 % databází“ má problémy s cizím klíčem (podle jeho zkušeností se staršími databázemi, které studoval). Připomíná nám, abychom se vyhnuli neformálnímu propojení mezi tabulkami vložením hodnoty z jedné tabulky do druhé namísto použití cizího klíče.
Tento problém jsem viděl mnohokrát. Připouštím, že neformální propojení může vyžadovat implementovaná funkcionalita, ale častěji k němu dochází z důvodu prosté lenosti. Můžeme například chtít zobrazit ID uživatele někoho, kdo něco upravil, takže ID uživatele uložíme přímo do tabulky. Ale co když tento uživatel změní své uživatelské ID? Pak je tento neformální odkaz přerušen. To je často způsobeno špatným designem a modelováním.
Navrhování databáze:5 hlavních chyb, kterým je třeba se vyhnout
od Henrique Netzky | Blog DATAVERSITY | 2. listopadu 2015
Tento článek mě trochu zklamal, protože měl pár docela specifických položek (ukládání protokolu do CLOB) a pár velmi obecných (přemýšlejte o lokalizaci). Celkově je článek v pořádku, ale je toto opravdu 5 hlavních chyb, kterým je třeba se vyhnout? Podle mého názoru existuje několik dalších běžných chyb, které by se měly dostat do seznamu.
Pozitivní však je, že se jedná o jeden z mála článků, který jakkoli smysluplně zmiňuje globalizaci a lokalizaci. Pracuji ve velmi mnohojazyčném prostředí a viděl jsem několik hrozných implementací lokalizace, takže jsem byl rád, že jsem našel tento problém zmíněný. Sloupce pro jazyk a časové pásmo se mohou zdát zřejmé, ale v databázových modelech se objevují velmi zřídka.
Jak již bylo řečeno, myslel jsem si, že by bylo zajímavé vytvořit model obsahující překlady, které mohou koncoví uživatelé měnit (na rozdíl od používání balíků zdrojů). Před časem jsem psal o modelu pro online databázi průzkumů. Zde jsem modeloval zjednodušený překlad otázek a možností odpovědí:
Za předpokladu, že musíme umožnit koncovým uživatelům udržovat překlady, preferovanou metodou by bylo přidat překladové tabulky pro otázky a odpovědi:
Do user_account tabulky, abychom mohli ukládat data/časy v místním čase uživatelů:
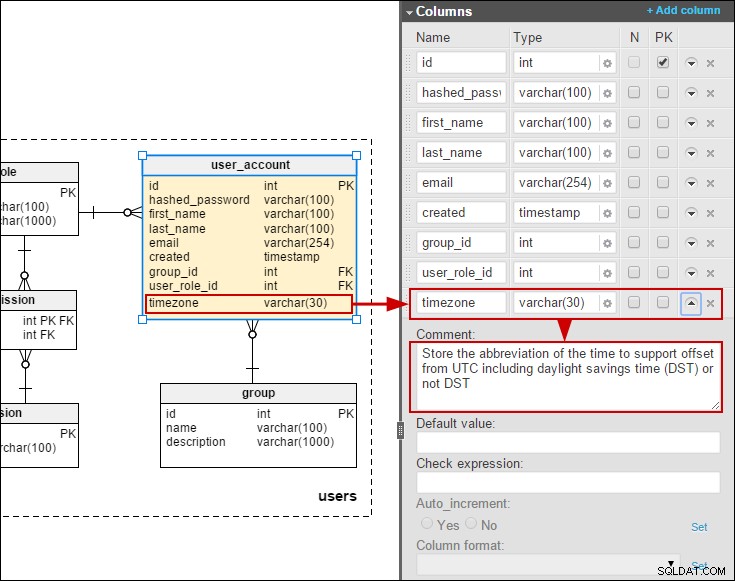
7 běžných chyb návrhu databáze
od Grzegorze Kaczora | Vertabelo blog | 17. července 2015
Udělám zde malou sebepropagaci. Snažíme se zde pravidelně zveřejňovat zajímavé a poutavé články.
Tento konkrétní článek poukazuje na několik důležitých oblastí zájmu, jako je pojmenování, indexování, úvahy o objemu a auditní záznamy. Článek se dokonce zabývá problémy souvisejícími s konkrétními systémy DBM, jako jsou omezení Oracle týkající se názvů tabulek. Opravdu se mi líbí pěkné jasné příklady, i když ilustrují, jak designéři dělají chyby a chyby.
Je zřejmé, že není možné uvést všechny chyby návrhu a ty uvedené nemusí být vaše nejčastější chyby. Když píšeme o běžných chybách, čerpáme z těch, které jsme udělali nebo které jsme našli v práci ostatních. Úplný seznam chyb seřazený podle četnosti by nedokázal sestavit jediný člověk. Přesto si myslím, že tento článek poskytuje několik užitečných postřehů o potenciálních úskalích. Celkově je to pěkný solidní zdroj.
Zatímco pan Kaczor ve svém článku uvádí několik zajímavých bodů, jeho poznámky o „neuvažování možného objemu nebo návštěvnosti“ mi přišly docela zajímavé. Zvláště vhodné je doporučení oddělit často používaná data od historických dat. Toto je řešení, které často používáme v našich aplikacích pro zasílání zpráv; musíme mít prohledávatelnou historii všech zpráv, ale nejpravděpodobnější přístup ke zprávám jsou ty, které byly odeslány během několika posledních dnů. Takže rozdělení „aktivních“ nebo nedávných dat, ke kterým se často přistupuje (mnohem menší objem dat) od dlouhodobých historických dat (velké množství dat), je obecně velmi dobrá technika.
Běžné chyby návrhu databáze
od Troye Blakea | Senior DBA blog | 11. července 2015
Dalším dobrým zdrojem je článek Troye Blakea, i když jsem tento článek možná přejmenoval na „Běžné chyby v návrhu serveru SQL“.
Máme například komentář:„Uložené procedury jsou vaším nejlepším přítelem, pokud jde o efektivní používání SQL Serveru“. To je v pořádku, ale je to běžná obecná chyba, nebo je to konkrétnější pro SQL Server? Musel bych se rozhodnout pro to, že je to trochu specifické pro SQL Server, protože používání uložených procedur má nevýhody, jako je konec s uloženými procedurami specifickými pro dodavatele a tedy uzamčením dodavatele. Nejsem tedy příznivcem zahrnutí „Nepoužívání uložených procedur“ na tento seznam.
Pozitivní však je, že autor identifikoval některé velmi časté chyby, jako je špatné plánování, nekvalitní návrh systému, omezená dokumentace, slabé standardy pojmenování a nedostatek testování.
Takže bych to klasifikoval jako velmi užitečnou referenci pro uživatele SQL Server a užitečnou referenci pro ostatní.
Sedm chyb datového modelování
od Kurta Cagle | LinkedIn | 12. června 2015
Opravdu jsem si užil čtení seznamu chyb při modelování databáze pana Cagla. Ty jsou z pohledu databázového architekta; jasně identifikuje chyby v modelování na vyšší úrovni, kterých je třeba se vyvarovat. S tímto větším zobrazením obrázku můžete zrušit potenciální nepořádek při modelování.
Některé z typů zmíněných v článku lze nalézt jinde, ale některé z nich jsou jedinečné:příliš brzké získávání abstraktů nebo míchání konceptuálních, logických a fyzických modelů. Jiní autoři je často nezmiňují, pravděpodobně proto, že se zaměřují spíše na proces modelování dat než na větší systémový pohled.
Konkrétně příklad „Příliš abstraktní příliš brzy“ popisuje zajímavý myšlenkový proces vytváření několika vzorových „příběhů“ a testování, které vztahy jsou v této oblasti důležité. To zaměřuje myšlení na vztahy mezi objekty, které jsou modelovány. Výsledkem jsou otázky jako jaké jsou důležité vztahy v této doméně ?
Na základě tohoto porozumění vytváříme model kolem vztahů, spíše než abychom začínali u jednotlivých položek domény a budovali vztahy na nich. I když mnozí z nás mohou tento přístup použít, mezi těmito zdroji jej žádný jiný autor nekomentoval. Tento popis a příklady mi přišly docela zajímavé.
Jak dostat návrh databáze strašně špatně
od Roberta Sheldona | Simple Talk | 6. března 2015
Pokud je mezi těmito zdroji pouze jeden článek, který se chystáte číst, měl by to být tento od Roberta Sheldona
Na tomto článku se mi moc líbí, že u každé ze zmíněných chyb jsou tipy, jak to udělat správně. Většina z nich se zaměřuje spíše na vyhnutí se selhání než na jeho nápravu, ale stále si myslím, že jsou velmi užitečné. Teorií je zde velmi málo; většinou přímé odpovědi o vyvarování se chyb při datovém modelování. Existuje několik konkrétních bodů pro SQL Server, ale většinou se SQL Server používá k poskytnutí příkladů, jak se vyhnout chybám nebo jak se vyhnout selhání.
Rozsah článku je také poměrně široký:pokrývá zanedbávání plánování, neobtěžování se s dokumentací, používání mizerných konvencí pojmenování, problémy s normalizací (příliš mnoho nebo příliš málo), selhání klíčů a omezení, nesprávné indexování a provádění nedostatečné testování.
Zejména se mi líbily praktické rady ohledně integrity dat – kdy použít kontrolní omezení a kdy definovat cizí klíče. Kromě toho pan Sheldon také popisuje situaci, kdy týmy odkládají aplikaci, aby prosadily integritu. Je přímo na místě, když uvádí, že k databázi lze přistupovat mnoha způsoby a mnoha aplikacemi. Jeho závěrem je, že „data by měla být chráněna tam, kde jsou uložena:v databázi“. To je tak pravdivé, že to lze opakovat vývojovým týmům a manažerům, aby vysvětlili důležitost implementace kontrol integrity v datovém modelu.
Toto je můj druh článku a můžete říct, že ostatní souhlasí na základě četných komentářů, které jej podporují. Takže nejlepší známky zde; je to velmi cenný zdroj.
Deset běžných chyb návrhu databáze
od Louise Davidsona | Simple Talk | 26. února 2007
Tento článek mi přišel docela dobrý, protože pokryl spoustu běžných chyb v designu. Byly tam smysluplné analogie, příklady, modely a dokonce i některé klasické citace od Williama Shakespeara a J.R.R. Tolkiena.
Několik chyb bylo vysvětleno podrobněji než ostatní, s dlouhými příklady a úryvky SQL, které mi připadaly trochu těžkopádné. Ale to je věc vkusu.
Opět máme několik témat specifických pro SQL Server. Například to, že nepoužíváte uložené procedury pro přístup k datům, je dobré pro SQL, ale SP nejsou vždy dobrý nápad, když je cílem podpora na více DBMS. Kromě toho jsme varováni před pokusy o kódování generických objektů T-SQL. Vzhledem k tomu, že se serverem SQL Server nebo Sybase pracuji jen zřídka, nepovažoval jsem tento tip za relevantní.
Seznam je docela podobný seznamu Roberta Sheldona, ale pokud primárně pracujete na SQL Serveru, najdete několik dalších nugetů informací.
Pět jednoduchých chyb návrhu databáze, kterých byste se měli vyvarovat
od Anith Sen Larson | Simple Talk | 16. října 2009
Tento článek uvádí několik smysluplných příkladů pro každou z jednoduchých chyb návrhu, které pokrývá. Na druhou stranu se spíše zaměřuje na podobné typy chyb:běžné vyhledávací tabulky, tabulky entit-atribut-hodnota a rozdělení atributů.
Pozorování jsou v pořádku a článek má dokonce odkazy, které bývají vzácné. Přesto bych rád viděl obecnější chyby návrhu databáze. Tyto chyby se zdály poněkud specifické, ale jak jsem již napsal, chyby, o kterých píšeme, jsou obecně ty, se kterými máme osobní zkušenost.
Jedna položka, která se mi líbila, bylo specifické pravidlo pro rozhodování, kdy použít kontrolní omezení oproti samostatné tabulce s omezením cizího klíče. Několik autorů poskytuje podobná doporučení, ale pan Larson je rozděluje na „musí“, „zvažovat“ a „silný případ“ – s tím, že „design je mix umění a vědy, a proto zahrnuje kompromisy“. Považuji to za velmi pravdivé.
Deset nejčastějších chyb návrhu fyzické databáze
od Craiga Mullinse | Data a technologie dnes | 5. srpna 2013
Jak již název napovídá, „Top Ten Nejčastější chyby při návrhu fyzické databáze“ je o něco více orientováno na fyzický návrh spíše než na logický a koncepční návrh. Žádná z chyb, které autor Craig Mullins zmiňuje, skutečně nevyčnívá nebo není jedinečná, takže bych tuto informaci doporučil lidem, kteří pracují na fyzické stránce DBA.
Kromě toho jsou popisy trochu krátké, takže je občas těžké pochopit, proč konkrétní chyba způsobí problémy. Na krátkých popisech není nic špatného, ale nedají vám moc přemýšlet. A nejsou uvedeny žádné příklady.
Existuje jeden zajímavý bod, který se týká selhání sdílení dat. Tento bod je občas zmíněn v jiných článcích, ale ne jako konstrukční chyba. Tento problém však vidím poměrně často u databází „znovuvytvářených“ na základě velmi podobných požadavků, ale novým týmem nebo pro nový produkt
.Často se stává, že si produktový tým později uvědomí, že by rád použil data, která již byla v „otci“ jejich aktuální databáze. Ve skutečnosti však měli spíše vylepšit rodiče, než vytvářet nové potomky. Aplikace jsou určeny ke sdílení dat; dobrý design může umožnit častější opakované použití databáze.
Děláte těchto 5 chyb v návrhu databáze?
od Thomase Larocka | Blog Thomase Larocka | 2. ledna 2012
Při zodpovězení otázky Thomase Larocka:Děláte těchto 5 chyb v návrhu databáze?
Tento článek je poněkud silně zaměřen na klíče (cizí klíče, náhradní klíče a generované klíče). Přesto to má jeden důležitý bod:neměli bychom předpokládat, že funkce DBMS jsou ve všech systémech stejné. Myslím, že je to velmi dobrý bod. Je to také článek, který se nenachází ve většině ostatních článků, možná proto, že mnoho autorů se zaměřuje a pracuje převážně s jediným DBMS.
Navrhování databáze:7 věcí, které nechcete dělat
od Thomase Larocka | Blog Thomase Larocka | 16. ledna 2013
Pan Larock recykloval pár svých „5 chyb v návrhu databáze“, když psal „7 věcí, které nechcete dělat“, ale jsou zde i další dobré body.
Je zajímavé, že některé body, které pan Larock uvádí, se v mnoha jiných zdrojích nenacházejí. Získáte několik dosti jedinečných postřehů, jako například „bez očekávání výkonu“. To je vážná chyba, která se podle mých zkušeností stává poměrně často. I při vývoji kódu aplikace často až po vytvoření datového modelu, databáze a samotné aplikace lidé začnou přemýšlet o nefunkčních požadavcích (kdy je třeba vytvořit nefunkční testy) a začít definovat výkonová očekávání. .
A naopak, je zde několik bodů, které bych do svého vlastního seznamu Top Ten nezahrnul, jako například „pro jistotu jít do krámu“. Chápu smysl, ale není to tak vysoko na mém seznamu při vytváření datového modelu. Neexistuje žádná specifičnost pro konkrétní systém DBM, takže je to bonus.
Abych to uzavřel, mnoho z těchto bodů by mohlo být zapouzdřeno pod bodem:„nerozumím požadavkům“, který je skutečně v mém seznamu 10 nejčastějších chyb.
Jak se vyhnout 8 běžným chybám při vývoji databáze
od Base36 | 6. prosince 2012
Docela mě zaujalo čtení tohoto článku. Nicméně jsem byl trochu zklamaný. O vyhýbání se příliš nediskutuje a pointa článku se skutečně zdá být „toto jsou běžné chyby v databázi“ a „proč jsou to chyby“; popisy, jak se vyhnout chybě, jsou méně nápadné.
Navíc některé z 8 hlavních chyb článku jsou ve skutečnosti sporné. Příkladem je zneužití primárního klíče. Base36 nám říká, že je musí generovat systém a nikoli na základě aplikačních dat v řádku. I když s tím do určité míry souhlasím, nejsem přesvědčen, že vše PK by měly vždy být generován; to je trochu příliš kategorické.
Na druhou stranu, chyba „Hard Deletes“ je zajímavá a jinde se často nezmiňuje. Měkká odstranění způsobují další problémy, ale je pravda, že jednoduché označení řádku jako neaktivního má své výhody, když se snažíte zjistit, kam zmizela data, která byla včera v systému. Prohledávání protokolů transakcí není moje představa o příjemném způsobu, jak strávit den.
Sedm smrtelných hříchů návrhu databáze
od Jasona Tireta | Enterprise Systems Journal | 16. února 2010
Docela jsem doufal, když jsem začal číst článek Jasona Tireta „Sedm smrtelných hříchů návrhu databáze“. S radostí jsem tedy zjistil, že nejde jen o recyklaci chyb, které se nacházejí v mnoha jiných článcích. Naopak nabídl „hřích“, který jsem v jiných seznamech nenašel:pokusit se provést veškerý návrh databáze „vpředu“ a neaktualizovat model poté, co je databáze ve výrobě, když se v databázi provádějí změny. (Nebo, jak to říká Jason, „Nezacházet s datovým modelem jako s živým, dýchajícím organismem“).
Tuto chybu jsem viděl mnohokrát. Většina lidí si svou chybu uvědomí, až když musí provést aktualizaci modelu, který již neodpovídá skutečné databázi. Výsledkem je samozřejmě zbytečný model. Jak je uvedeno v článku, „změny si musí najít cestu zpět k modelu.“
Na druhou stranu je většina položek Jasonova seznamu docela dobře známá. Popisy jsou dobré, ale příkladů není příliš mnoho. Bylo by užitečné více příkladů a podrobností.
Nejčastější chyby návrhu databáze
od Briana Prince | eWeek.com | 19. března 2008

Článek „Nejčastější chyby návrhu databáze“ je ve skutečnosti série snímků z prezentace. Je tam pár zajímavých myšlenek, ale některé unikáty jsou možná trochu esoterické. Mám na mysli body jako „Seznamte se s RAID“ a zapojení zainteresovaných stran.
Obecně bych to nedával na váš seznam četby, pokud se nezaměřujete na obecné záležitosti (plánování, pojmenování, normalizace, indexy) a fyzické detaily.
10 běžných chyb při návrhu
od davidma | Blogy SQL Server – SQLTeam.com | 12. září 2005
Některé body v „Deset běžných konstrukčních chyb“ jsou zajímavé a relativně nové. Některé z těchto chyb jsou však poměrně kontroverzní, například „používání hodnot NULL“ a denormalizace.
Souhlasím s tím, že vytvoření všech sloupců jako s možnou hodnotou null je chyba, ale definování sloupce jako s možnou hodnotou null může být vyžadováno pro konkrétní obchodní funkci. Lze to tedy považovat za obecnou chybu? Myslím, že ne.
Dalším bodem, se kterým mám problém, je denormalizace. Ne vždy se jedná o konstrukční chybu. Denormalizace může být například vyžadována z důvodu výkonu.
V tomto článku také do značné míry chybí podrobnosti a příklady. Rozhovory mezi DBA a programátorem nebo manažerem jsou zábavné, ale upřednostnil bych konkrétnější příklady a podrobnější zdůvodnění těchto běžných chyb.
OTLT a EAV:dvě velké konstrukční chyby, kterých se dopouštějí všichni začátečníci
od Tonyho Andrewse | Tony Andrews o Oracle a databázích | 21. října 2004
Článek pana Andrewse nám připomíná chyby „One True Lookup Table“ (OTLT) a Entity-Attribute-Value (EAV), které jsou zmíněny v jiných článcích. Jedna pěkná věc na této prezentaci je, že se zaměřuje na tyto dvě chyby, takže popisy a příklady jsou přesné. Kromě toho je uvedeno možné vysvětlení, proč někteří návrháři implementují OTLT a EAV.
Abychom vám připomněli, tabulka OTLT obvykle vypadá nějak takto, se záznamy z více domén vhozenými do stejné tabulky:
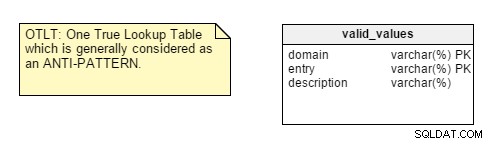
Jako obvykle se diskutuje o tom, zda je OTLT funkční řešení a dobrý návrhový vzor. Musím říci, že stojím na straně anti-OTLT skupiny; tyto tabulky přináší řadu problémů. Můžeme použít analogii použití jediného enumerátoru k reprezentaci všech možných hodnot všech možných konstant. To jsem zatím nikdy neviděl.
Běžné chyby databáze
od Johna Paula Ashenfeltera | Dr. Dobba | 1. ledna 2002
Článek pana Ashenfeltera uvádí neuvěřitelných 15 běžných chyb v databázi. Existuje dokonce několik chyb, které se v jiných článcích často nezmiňují. Bohužel jsou popisy poměrně krátké a chybí příklady. Předností tohoto článku je, že seznam pokrývá mnoho oblastí a lze jej použít jako „kontrolní seznam“ chyb, kterým je třeba se vyhnout. I když je možná neklasifikuji jako nejdůležitější databázové chyby, určitě patří mezi nejčastější.
Pozitivní je, že toto je jeden z mála článků, který zmiňuje nutnost zvládnout internacionalizaci formátů dat, jako je datum, měna a adresa. Zde by se hodil příklad. Mohlo by to být tak jednoduché jako „ujistěte se, že stát je sloupec s možností nulování; v mnoha zemích není s adresou spojen žádný stát.“
Dříve v tomto článku jsem zmínil další obavy a některé přístupy k přípravě na globalizaci vaší databáze, jako jsou časová pásma a překlady (lokalizace). Skutečnost, že žádný jiný článek nezmiňuje obavy z formátů měny a data, je znepokojující. Jsou naše databáze připraveny pro globální použití našich aplikací?
Čestná uznání
Je zřejmé, že existují další články, které popisují běžné chyby a chyby při návrhu databáze, ale my jsme vám chtěli poskytnout široký přehled různých zdrojů. Další informace můžete najít v článcích jako:
10 běžných chyb návrhu databáze | Blog třídy MIS | 29. ledna 2012
10 běžných chyb v návrhu databáze | IDG.se | 24. června 2010
Online zdroje:Kde začít? Kam jít?
Jak již bylo zmíněno, tento seznam rozhodně nemá být vyčerpávajícím prozkoumáním každého online článku popisujícího chyby a chyby v návrhu databáze. Spíše jsme identifikovali několik zdrojů, které jsou obzvláště užitečné nebo mají konkrétní zaměření, které by vám mohly být užitečné.
Neváhejte a doporučte další články.