Toto je třetí díl série o řešení problému generátoru číselných řad. V části 1 jsem pokryl řešení, která generují řádky za běhu. V části 2 jsem pokryl řešení, která se dotazují na fyzickou základní tabulku, kterou předem vyplníte řádky. Tento měsíc se zaměřím na fascinující techniku, kterou lze použít ke zvládnutí naší výzvy, ale která má také zajímavé aplikace daleko za ní. Nevím o oficiálním názvu této techniky, ale svým pojetím je do jisté míry podobná eliminaci horizontálních oddílů, takže ji budu neformálně označovat jako eliminaci horizontálních jednotek technika. Technika může mít zajímavé pozitivní výkonnostní přínosy, ale jsou zde také výhrady, kterých si musíte být vědomi, kdy za určitých podmínek může způsobit výkonnostní penalizaci.
Ještě jednou děkujeme Alanu Bursteinovi, Joe Obbishovi, Adamu Machanicovi, Christopheru Fordovi, Jeffu Modenovi, Charliemu, NoamGr, Kamilu Kosnovi, Dave Masonovi, Johnu Nelsonovi #2, Edu Wagnerovi, Michaelu Burbeovi a Paulu Whiteovi za sdílení vašich nápadů a komentářů.
Provedu své testování v tempdb a povolím statistiky času:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME ON;
Dřívější nápady
Techniku horizontální eliminace jednotek lze použít jako alternativu k logice eliminace sloupců nebo eliminaci vertikálních jednotek technika, na kterou jsem spoléhal v několika řešeních, která jsem popsal dříve. O základech logiky eliminace sloupců s tabulkovými výrazy si můžete přečíst v Základy tabulkových výrazů, Část 3 – Odvozené tabulky, úvahy o optimalizaci v části „Projekce sloupců a slovo na SELECT *.“
Základní myšlenkou techniky eliminace vertikálních jednotek je, že pokud máte vnořený tabulkový výraz, který vrací sloupce x a y, a váš vnější dotaz odkazuje pouze na sloupec x, proces kompilace dotazu eliminuje y z původního stromu dotazů, a proto plán není potřeba to hodnotit. To má několik pozitivních důsledků souvisejících s optimalizací, jako je dosažení indexového pokrytí pouze pomocí x, a pokud je y výsledkem výpočtu, není třeba vůbec hodnotit základní výraz y. Tato myšlenka byla jádrem řešení Alana Bursteina. Spoléhal jsem na to také v několika dalších řešeních, která jsem pokryl, jako je například funkce dbo.GetNumsAlanCharlieItzikBatch (z části 1), funkce dbo.GetNumsJohn2DaveObbishAlanCharlieItzik a dbo.GetNumsJohn2DaveCharlieItzik a další (z části 1.Alan2CharlieItzik) a další. Jako příklad použiji dbo.GetNumsAlanCharlieItzikBatch jako základní řešení s logikou vertikální eliminace.
Připomínáme, že toto řešení používá k dávkovému zpracování spojení s fiktivní tabulkou, která má index columnstore. Zde je kód pro vytvoření fiktivní tabulky:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
A zde je kód s definicí funkce dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Použil jsem následující kód k otestování výkonu funkce se 100 miliony řádků, přičemž jsem vrátil vypočítaný výsledný sloupec n (manipulace s výsledkem funkce ROW_NUMBER), seřazený podle n:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Zde jsou časové statistiky, které jsem získal pro tento test:
CPU čas =9328 ms, uplynulý čas =9330 ms.Použil jsem následující kód k otestování výkonu funkce se 100 miliony řádků, přičemž jsem vrátil sloupec rn (přímý, nemanipulovaný, výsledek funkce ROW_NUMBER), seřazený podle rn:
DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY rn OPTION(MAXDOP 1);
Zde jsou časové statistiky, které jsem získal pro tento test:
Čas CPU =7296 ms, uplynulý čas =7291 ms.Pojďme se podívat na důležité myšlenky, které jsou součástí tohoto řešení.
Alan se spoléhal na logiku eliminace sloupců a přišel s nápadem vrátit nejen jeden sloupec s číselnou řadou, ale tři:
- Sloupec rn představuje nemanipulovaný výsledek funkce ROW_NUMBER, která začíná 1. Je to levné počítat. Zachovává pořadí, když poskytujete konstanty i když poskytujete nekonstanty (proměnné, sloupce) jako vstupy do funkce. To znamená, že když váš vnější dotaz používá ORDER BY rn, nezískáte v plánu operátor řazení.
- Sloupec n představuje výpočet založený na @low, konstantě a rownum (výsledek funkce ROW_NUMBER). Je to zachování pořadí s ohledem na rownum, když zadáte konstanty jako vstupy do funkce. Je to díky Charlieho pochopení neustálého skládání (podrobnosti viz část 1). Pokud však jako vstupy zadáte nekonstanty, nezachovává se pořadí, protože nedochází k neustálému skládání. Ukážu to později v části o upozorněních.
- Sloupec op představuje n v opačném pořadí. Je to výsledek výpočtu a nezachovává pořadí.
Pokud se spoléháte na logiku eliminace sloupců, pokud potřebujete vrátit číselnou řadu začínající 1, dotazujete se na sloupec rn, což je levnější než dotazování na n. Pokud potřebujete číselnou řadu začínající jinou hodnotou než 1, zeptáte se n a zaplatíte příplatek. Pokud potřebujete výsledek seřadit podle číselného sloupce, s konstantami jako vstupy, můžete použít buď ORDER BY rn nebo ORDER BY n. Ale s nekonstantami jako vstupy se chcete ujistit, že používáte ORDER BY rn. Možná by bylo dobré se vždy držet používání ORDER BY rn, když potřebujete, aby byl výsledek objednán na bezpečné straně.
Myšlenka eliminace horizontální jednotky je podobná myšlence eliminace vertikální jednotky, pouze se vztahuje na sady řádků namísto sad sloupců. Ve skutečnosti na tuto myšlenku spoléhal Joe Obbish ve své funkci dbo.GetNumsObbish (z části 2) a my ji posuneme o krok dále. Ve svém řešení Joe sjednotil více dotazů představujících nesouvislé podrozsahy čísel pomocí filtru v klauzuli WHERE každého dotazu, aby definoval použitelnost podrozsahu. Když zavoláte funkci a předáte konstantní vstupy představující oddělovače požadovaného rozsahu, SQL Server eliminuje nepoužitelné dotazy v době kompilace, takže je plán ani neodráží.
Vodorovná eliminace jednotek, doba kompilace versus doba běhu
Možná by bylo dobré začít demonstrací konceptu eliminace horizontálních jednotek na obecnějším případě a také diskutovat o důležitém rozdílu mezi eliminací v době kompilace a eliminací za běhu. Pak můžeme diskutovat o tom, jak tuto myšlenku aplikovat na naši výzvu číselné řady.
V mém příkladu použiji tři tabulky nazvané dbo.T1, dbo.T2 a dbo.T3. K vytvoření a naplnění těchto tabulek použijte následující kód DDL a DML:
DROP TABLE IF EXISTS dbo.T1, dbo.T2, dbo.T3; GO CREATE TABLE dbo.T1(col1 INT); INSERT INTO dbo.T1(col1) VALUES(1); CREATE TABLE dbo.T2(col1 INT); INSERT INTO dbo.T2(col1) VALUES(2); CREATE TABLE dbo.T3(col1 INT); INSERT INTO dbo.T3(col1) VALUES(3);
Předpokládejme, že chcete implementovat inline TVF s názvem dbo.OneTable, která přijímá jeden ze tří výše uvedených názvů tabulek jako vstup a vrací data z požadované tabulky. Na základě konceptu horizontální eliminace jednotek můžete funkci implementovat takto:
CREATE OR ALTER FUNCTION dbo.OneTable(@WhichTable AS NVARCHAR(257)) RETURNS TABLE AS RETURN SELECT col1 FROM dbo.T1 WHERE @WhichTable = N'dbo.T1' UNION ALL SELECT col1 FROM dbo.T2 WHERE @WhichTable = N'dbo.T2' UNION ALL SELECT col1 FROM dbo.T3 WHERE @WhichTable = N'dbo.T3'; GO
Pamatujte, že inline TVF používá vkládání parametrů. To znamená, že když předáte jako vstup konstantu, jako je N'dbo.T2', proces vkládání nahradí všechny odkazy na @WhichTable konstantou před optimalizací . Proces eliminace pak může odstranit odkazy na T1 a T3 z počátečního stromu dotazů, a optimalizace dotazu tak vede k plánu, který odkazuje pouze na T2. Pojďme tento nápad otestovat pomocí následujícího dotazu:
SELECT * FROM dbo.OneTable(N'dbo.T2');
Plán pro tento dotaz je znázorněn na obrázku 1.
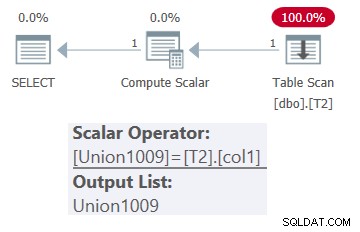 Obrázek 1:Plán pro dbo.OneTable s konstantním vstupem
Obrázek 1:Plán pro dbo.OneTable s konstantním vstupem
Jak vidíte, v plánu se objevuje pouze tabulka T2.
Věci jsou trochu složitější, když jako vstup předáte nekonstantu. K tomu může dojít při použití proměnné, parametru procedury nebo předání sloupce přes APPLY. Vstupní hodnota je buď neznámá v době kompilace, nebo je třeba vzít v úvahu parametrizovaný potenciál opětovného použití plánu.
Optimalizátor nemůže odstranit žádnou z tabulek z plánu, ale stále má trik. Může používat spouštěcí operátory filtru nad podstromy, které přistupují k tabulkám, a spouštět pouze relevantní podstrom na základě runtime hodnoty @WhichTable. K otestování této strategie použijte následující kód:
DECLARE @T AS NVARCHAR(257) = N'dbo.T2'; SELECT * FROM dbo.OneTable(@T);
Plán tohoto provedení je znázorněn na obrázku 2:
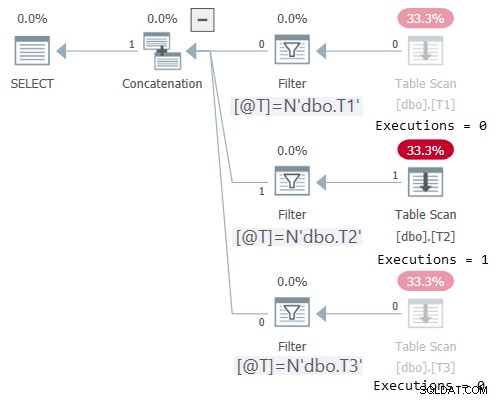 Obrázek 2:Plán pro dbo.OneTable s nekonstantním vstupem
Obrázek 2:Plán pro dbo.OneTable s nekonstantním vstupem
V Průzkumníku plánu je úžasně zřejmé, že byl proveden pouze příslušný podstrom (Provedení =1), a podstromy, které nebyly provedeny, zašedí (Provedení =0). STATISTICS IO také zobrazuje I/O informace pouze pro tabulku, ke které byl přístup:
Tabulka 'T2'. Počet skenování 1, logické čtení 1, fyzické čtení 0, stránkovací server čte 0, čtení napřed čte 0, stránkovací server napřed čtení 0, logické čtení 0, fyzické čtení 0, server lob čte 0, lob čtení- vpřed čte 0, lob stránkový server čte napřed čte 0.Aplikace horizontální logiky eliminace jednotek na výzvu číselné řady
Jak již bylo zmíněno, koncept horizontální eliminace jednotek můžete použít úpravou kteréhokoli z dřívějších řešení, která v současnosti používají logiku vertikální eliminace. Jako výchozí bod pro svůj příklad použiji funkci dbo.GetNumsAlanCharlieItzikBatch.
Připomeňme, že Joe Obbish použil horizontální eliminaci jednotek k extrakci příslušných disjunktních podrozsahů číselné řady. Tento koncept použijeme k horizontálnímu oddělení levnějšího výpočtu (rn), kde @nízká =1, od dražšího výpočtu (n), kde @nízká <> 1.
Když už jsme u toho, můžeme experimentovat přidáním nápadu Jeffa Modena do jeho funkce fnTally, kde používá řádek sentinelu s hodnotou 0 pro případy, kdy rozsah začíná @low =0.
Máme tedy čtyři horizontální jednotky:
- Řádek Sentinel s 0, kde @nízká =0, s n =0
- NEJLEPŠÍ (@vysoké) řádky, kde @nízká =0, s levným n =rownum a op =@high – rownum
- TOP (@high) řádky, kde @nízká =1, s levným n =rownum a op =@high + 1 – rownum
- NEJLEPŠÍ (@vysoké – @nízké + 1) řádky, kde @nízká <> 0 A @nízká <> 1, přičemž dražší n =@nízká – 1 + rownum a op =@vysoká + 1 – rownum
Toto řešení kombinuje nápady od Alana, Charlieho, Joea, Jeffa a mě, takže budeme volat verzi funkce v dávkovém režimu dbo.GetNumsAlanCharlieJoeJeffItzikBatch.
Nejprve se nezapomeňte ujistit, že máte stále přítomnou fiktivní tabulku dbo.BatchMe, abyste získali dávkové zpracování v našem řešení, nebo použijte následující kód, pokud nemáte:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Zde je kód s definicí funkce dbo.GetNumsAlanCharlieJoeJeffItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeJeffItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT @low AS n, @high AS op WHERE @low = 0 AND @high > @low
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 0
ORDER BY rownum
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 0 AND @low <> 1
ORDER BY rownum;
GO Důležité:Koncept eliminace horizontálních jednotek je nepochybně složitější na implementaci než koncept vertikální, tak proč se obtěžovat? Protože to uživatele zbavuje odpovědnosti za výběr správného sloupce. Uživatel se musí starat pouze o dotazování na sloupec s názvem n, na rozdíl od toho, aby si pamatoval použití rn, když rozsah začíná 1, a jinak n.
Začněme testováním řešení s konstantními vstupy 1 a 100 000 000 a požádáme o objednání výsledku:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Plán tohoto provedení je znázorněn na obrázku 3.
 Obrázek 3:Plán pro dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1),
Obrázek 3:Plán pro dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1),
Všimněte si, že jediný vrácený sloupec je založen na přímém, nemanipulovaném výrazu ROW_NUMBER (Expr1313). Všimněte si také, že v plánu není potřeba řazení.
Získal jsem následující časové statistiky pro toto provedení:
Čas CPU =7359 ms, uplynulý čas =7354 ms.Runtime přiměřeně odráží skutečnost, že plán používá dávkový režim, nemanipulovaný výraz ROW_NUMBER a žádné řazení.
Dále otestujte funkci s konstantním rozsahem 0 až 99 999 999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Plán tohoto provedení je znázorněn na obrázku 4.
 Obrázek 4:Plán pro dbo.GetNumsAlanCharlieJoeJeffItzikBatch9999>
Obrázek 4:Plán pro dbo.GetNumsAlanCharlieJoeJeffItzikBatch9999>
Plán používá operátor Merge Join (Concatenation) ke sloučení řádku sentinelu s hodnotou 0 a ostatními. I když je druhá část stejně efektivní jako předtím, logika sloučení si vybírá poměrně velkou daň ve výši asi 26 % z doby běhu, což má za následek následující časové statistiky:
Čas CPU =9265 ms, uplynulý čas =9298 ms.Pojďme otestovat funkci s konstantním rozsahem 2 až 100 000 001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Plán tohoto provedení je znázorněn na obrázku 5.
 Obrázek 5:Plán pro dbo.GetNumsAlanCharlieJoeJeffItzikBatch10001)
Obrázek 5:Plán pro dbo.GetNumsAlanCharlieJoeJeffItzikBatch10001)
Tentokrát to není žádná drahá logika sloučení, protože část hlídacího řádku je irelevantní. Všimněte si však, že vrácený sloupec je manipulovaný výraz @low – 1 + rownum, který se po vložení/vložení parametru a konstantním skládání stal 1 + rownum.
Zde jsou časové statistiky, které jsem získal pro toto provedení:
CPU Time =9000 ms, uplynulý čas =9015 ms.Jak se očekávalo, není to tak rychlé jako u rozsahu začínajícího 1, ale je zajímavé, že rychlejší než u rozsahu začínajícího 0.
Odebrání řádku 0 sentinelu
Vzhledem k tomu, že technika s řádkem sentinelu s hodnotou 0 se zdá být pomalejší než aplikace manipulace na rownum, má smysl se jí jednoduše vyhnout. To nás přivádí ke zjednodušenému řešení založenému na horizontální eliminaci, které kombinuje myšlenky Alana, Charlieho, Joea a mě. Zavolám funkci s tímto řešením dbo.GetNumsAlanCharlieJoeItzikBatch. Zde je definice funkce:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 1
ORDER BY rownum;
GO Pojďme to otestovat s rozsahem 1 až 100 M:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Plán je podle očekávání stejný jako plán na obrázku 3.
V souladu s tím jsem získal následující časové statistiky:
Čas CPU =7219 ms, uplynulý čas =7243 ms.Otestujte to v rozsahu 0 až 99 999 999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Tentokrát získáte stejný plán jako ten na obrázku 5 – nikoli na obrázku 4.
Zde jsou časové statistiky, které jsem získal pro toto provedení:
CPU Time =9313 ms, uplynulý čas =9334 ms.Otestujte to v rozsahu 2 až 100 000 001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Opět získáte stejný plán jako ten, který je zobrazen dříve na obrázku 5.
Získal jsem následující časové statistiky pro toto provedení:
CPU Time =9125 ms, uplynulý čas =9148 ms.Upozornění při použití nekonstantních vstupů
S technikami vertikální i horizontální eliminace jednotek věci fungují ideálně, pokud jako vstupy předáváte konstanty. Musíte si však být vědomi upozornění, která mohou mít za následek snížení výkonu, když předáváte nekonstantní vstupy. Technika odstraňování vertikálních jednotek má méně problémů a problémy, které existují, se snáze vypořádávají, takže začněme s ní.
Pamatujte, že v tomto článku jsme použili funkci dbo.GetNumsAlanCharlieItzikBatch jako náš příklad, který se opírá o koncept eliminace vertikálních jednotek. Proveďme sérii testů s nekonstantními vstupy, jako jsou proměnné.
Jako první test vrátíme rn a požádáme o data objednaná rn:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Pamatujte, že rn představuje nemanipulovaný výraz ROW_NUMBER, takže skutečnost, že používáme nekonstantní vstupy, nemá v tomto případě žádný zvláštní význam. V plánu není potřeba explicitní řazení.
Mám následující časové statistiky pro toto provedení:
CPU Time =7390 ms, uplynulý čas =7386 ms.Tato čísla představují ideální případ.
V dalším testu seřaďte řádky výsledků podle n:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Plán tohoto provedení je znázorněn na obrázku 6.
 Obrázek 6:Plán pro dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) n
Obrázek 6:Plán pro dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) n
Vidíte problém? Po vložení byl @low nahrazen @mylow – nikoli hodnotou v @mylow, což je 1. V důsledku toho neproběhlo konstantní skládání, a proto n nezachovává pořadí vzhledem k rownum. To vedlo k explicitnímu řazení v plánu.
Zde jsou časové statistiky, které jsem získal pro toto provedení:
CPU Time =25141 ms, uplynulý čas =25628 ms.Doba provedení se téměř ztrojnásobila ve srovnání s situací, kdy nebylo potřeba explicitní řazení.
Jednoduchým řešením je použít původní nápad Alana Bursteina objednávat vždy podle rn, když potřebujete výsledek objednat, a to jak při vracení rn, tak při vracení n, například takto:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Tentokrát v plánu není žádné explicitní řazení.
Získal jsem následující časové statistiky pro toto provedení:
CPU Time =9156 ms, uplynulý čas =9184 ms.Čísla přiměřeně odrážejí skutečnost, že vracíte zmanipulovaný výraz, ale bez explicitního řazení.
S řešeními, která jsou založena na technice eliminace horizontálních jednotek, jako je naše funkce dbo.GetNumsAlanCharlieJoeItzikBatch, je situace komplikovanější při použití nekonstantních vstupů.
Nejprve otestujme funkci s velmi malým rozsahem 10 čísel:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
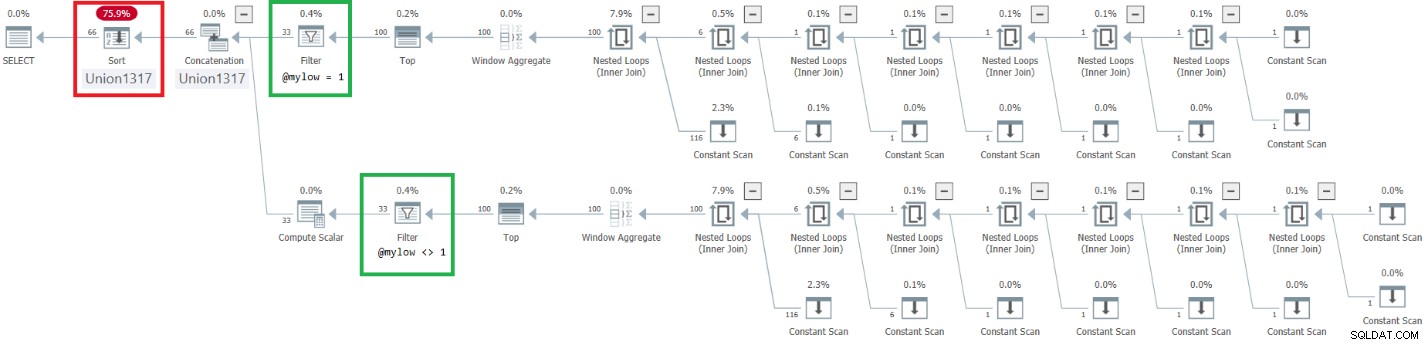
Plán tohoto provedení je znázorněn na obrázku 7.
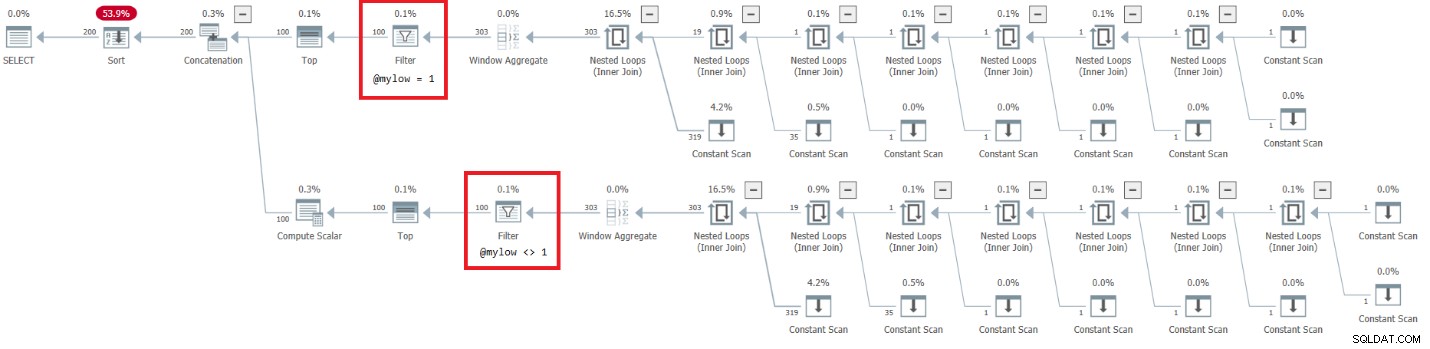 Obrázek 7:Plán pro dbo.GetNumsAlanCharlieJoeItzikBatch(ighmylow), @ em>
Obrázek 7:Plán pro dbo.GetNumsAlanCharlieJoeItzikBatch(ighmylow), @ em>
Tento plán má velmi alarmující stránku. Všimněte si, že operátory filtru jsou uvedeny níže nejlepší operátoři! V jakémkoli daném volání funkce s nekonstantními vstupy bude přirozeně jedna z větví pod operátorem Concatenation mít vždy falešnou podmínku filtru. Oba Top operátoři však požadují nenulový počet řádků. Operátor Top nad operátorem s falešnou podmínkou filtru tedy požádá o řádky a nikdy nebude spokojen, protože operátor filtru bude neustále zahazovat všechny řádky, které získá ze svého podřízeného uzlu. Práce v podstromu pod operátorem Filtr bude muset být dokončena. V našem případě to znamená, že podstrom projde prací na generování 4B řádků, které operátor Filtr zahodí. Divíte se, proč se operátor filtru obtěžuje vyžadovat řádky ze svého podřízeného uzlu, ale zdá se, že to tak aktuálně funguje. Je těžké to vidět se statickým plánem. Je to snazší vidět to naživo, například s možností živého spuštění dotazu v SentryOne Plan Explorer, jak je znázorněno na obrázku 8. Vyzkoušejte to.
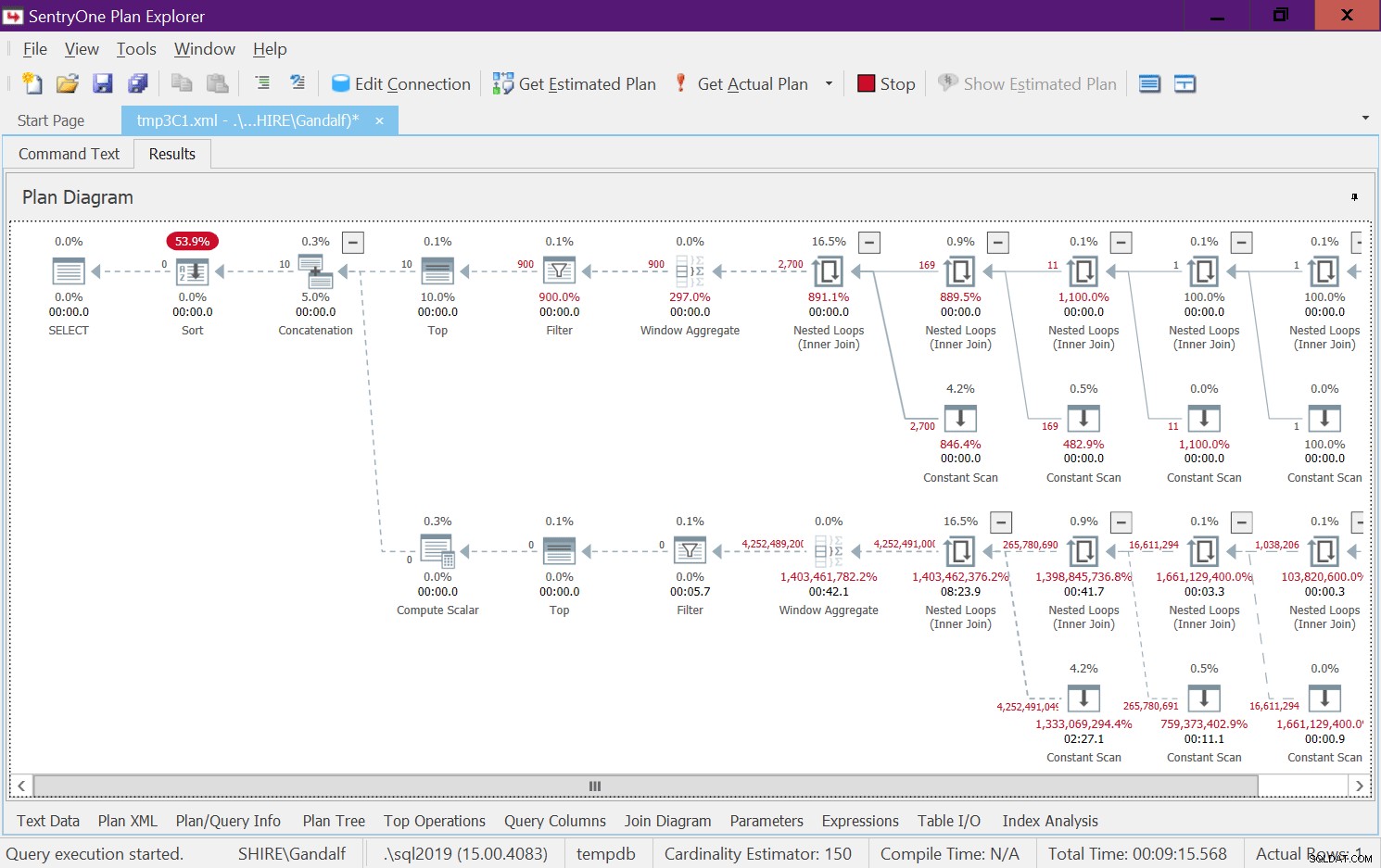 Obrázek 8:Živé statistiky dotazů pro dbo.GetNumsAlanCharlieJoeItzikighmyhmy
Obrázek 8:Živé statistiky dotazů pro dbo.GetNumsAlanCharlieJoeItzikighmyhmy
Dokončení tohoto testu na mém počítači trvalo 9:15 minut a nezapomeňte, že požadavek byl vrátit rozsah 10 čísel.
Zamysleme se, zda existuje způsob, jak se vyhnout aktivaci irelevantního podstromu jako celku. Chcete-li toho dosáhnout, měli byste chtít, aby se spouštěcí operátory filtru objevily výše horní operátoři místo pod nimi. Pokud čtete Základy tabulkových výrazů, část 4 – Odvozené tabulky, úvahy o optimalizaci, pokračování, víte, že TOP filtr zabraňuje rozkládání tabulkových výrazů. Takže vše, co musíte udělat, je umístit TOP dotaz do odvozené tabulky a použít filtr ve vnějším dotazu proti odvozené tabulce.
Zde je naše upravená funkce implementující tento trik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT *
FROM ( SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D1
WHERE @low = 1
UNION ALL
SELECT *
FROM ( SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D2
WHERE @low <> 1;
GO Jak se očekávalo, popravy s konstantami se chovají a fungují stejně jako bez triku.
Pokud jde o nekonstantní vstupy, nyní s malými rozsahy je to velmi rychlé. Zde je test s rozsahem 10 čísel:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Plán tohoto provedení je znázorněn na obrázku 9.
 Obrázek 9:Plán pro vylepšené dbo.GetNumsAlanCharlie
Obrázek 9:Plán pro vylepšené dbo.GetNumsAlanCharlie
Všimněte si, že bylo dosaženo požadovaného efektu umístění operátorů Filtr nad horní operátory. Se sloupcem řazení n se však zachází jako s výsledkem manipulace, a proto se nepovažuje za sloupec zachovávající pořadí vzhledem k rownum. V důsledku toho je v plánu explicitní třídění.
Otestujte funkci s velkým rozsahem 100 milionů čísel:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Mám následující časové statistiky:
CPU Time =29907 ms, uplynulý čas =29909 ms.Jaký průšvih; bylo to téměř dokonalé!
Shrnutí a statistiky výkonu
Obrázek 10 obsahuje souhrn časových statistik pro různá řešení.
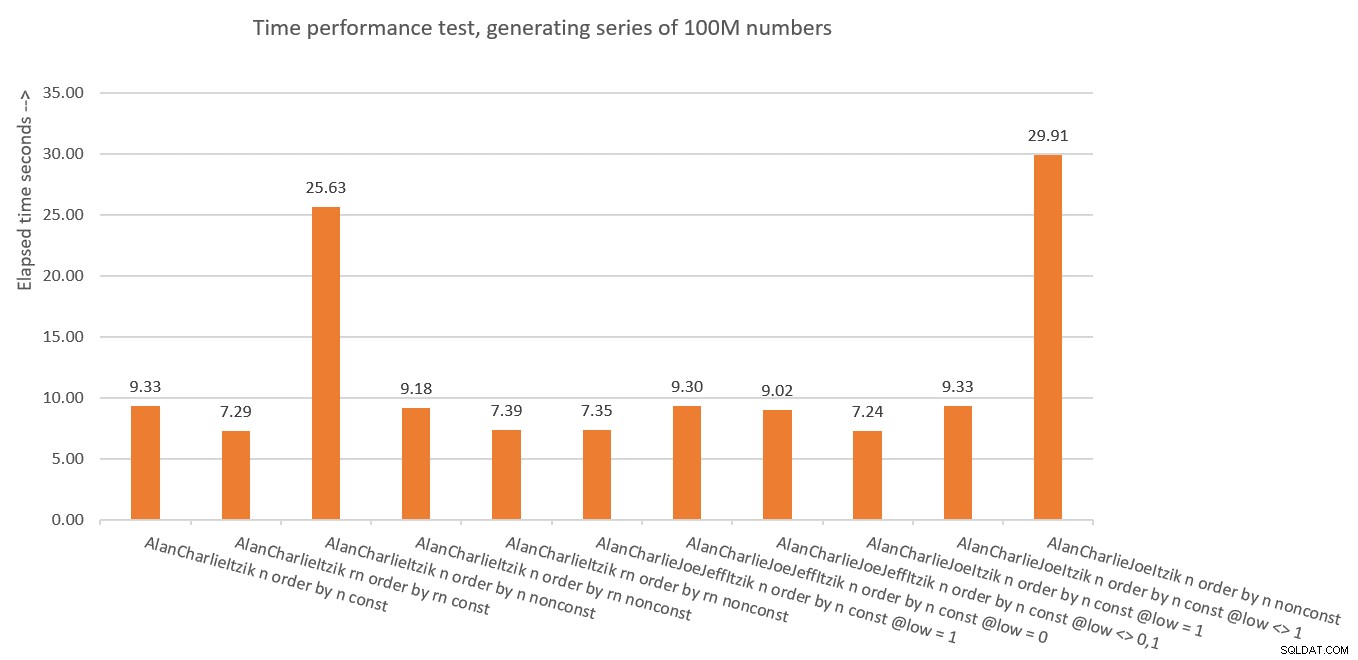 Obrázek 10:Souhrn řešení podle časové výkonnosti
Obrázek 10:Souhrn řešení podle časové výkonnosti
Co jsme se tedy z toho všeho naučili? Myslím, že už to neudělám! Dělám si srandu. Zjistili jsme, že je bezpečnější použít koncept vertikální eliminace jako v dbo.GetNumsAlanCharlieItzikBatch, který odhaluje jak nemanipulovaný výsledek ROW_NUMBER (rn), tak zmanipulovaný výsledek (n). Jen se ujistěte, že když potřebujete vrátit objednaný výsledek, vždy objednávejte podle rn, ať už vracíte rn nebo n.
Pokud jste si absolutně jisti, že vaše řešení bude vždy použito s konstantami jako vstupy, můžete použít koncept horizontální eliminace jednotek. To bude mít za následek intuitivnější řešení pro uživatele, protože bude interagovat s jedním sloupcem pro vzestupné hodnoty. Stále bych pro jistotu doporučoval použít trik s odvozenými tabulkami, aby se zabránilo rozkládání a umístění operátorů filtru nad horní operátory, pokud je funkce někdy použita s nekonstantními vstupy, pro jistotu.
Ještě jsme neskončili. Příští měsíc budu pokračovat ve zkoumání dalších řešení.