Ve svém předchozím příspěvku jsem mluvil o způsobech generování posloupnosti souvislých čísel od 1 do 1 000. Nyní bych chtěl mluvit o dalších úrovních měřítka:generování sad 50 000 a 1 000 000 čísel.
Generování sady 50 000 čísel
Když jsem začínal tuto sérii, byl jsem skutečně zvědavý, jak se různé přístupy změní na větší sady čísel. Na nejnižší úrovni jsem byl trochu zděšen, když jsem zjistil, že můj oblíbený přístup – pomocí sys.all_objects – nebyla nejúčinnější metodou. Ale jak by se tyto různé techniky zvětšily na 50 000 řádků?
Tabulka čísel
Protože jsme již vytvořili tabulku Numbers s 1 000 000 řádky, zůstává tento dotaz prakticky identický:
VYBRAT TOP (50000) n Z dbo.Numbers ORDER BY n;
Plán:
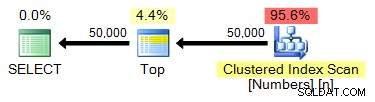
spt_values
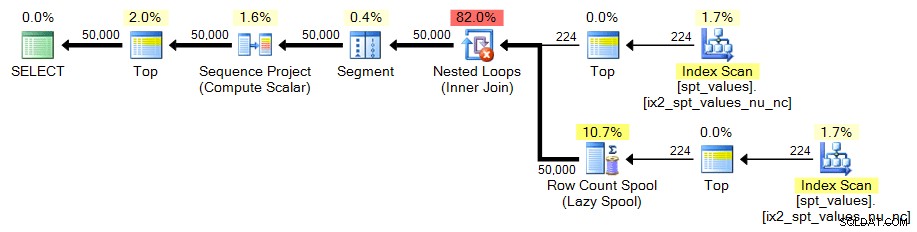
Protože v spt_values je pouze ~2500 řádků , musíme být trochu kreativnější, pokud jej chceme použít jako zdroj našeho generátoru množin. Jedním ze způsobů, jak simulovat větší tabulku, je CROSS JOIN to proti sobě. Pokud bychom to udělali surově, skončili bychom s ~ 2 500 řádky na druhou (přes 6 milionů). Potřebujeme pouze 50 000 řádků, potřebujeme asi 224 čtverečních řádků. Takže můžeme udělat toto:
;WITH x AS ( SELECT TOP (224) number FROM [master]..spt_values)SELECT TOP (50000) n =ROW_NUMBER() OVER (ORDER BY x.number) FROM x CROSS JOIN x AS yORDER BY n;
Všimněte si, že toto je ekvivalentní, ale výstižnější než tato varianta:
SELECT TOP (50000) n =ROW_NUMBER() OVER (ORDER BY x.number) FROM (SELECT TOP (224) number FROM FROM [master]..spt_values) AS xCROSS JOIN(SELECT TOP (224) number FROM [master] ]..spt_values) AS yORDER BY n;
V obou případech vypadá plán takto:
sys.all_objects
Jako spt_values , sys.all_objects sama o sobě zcela nesplňuje náš požadavek na 50 000 řádků, takže budeme muset provést podobné CROSS JOIN .
;;WITH x AS ( SELECT TOP (224) [object_id] FROM sys.all_objects)SELECT TOP (50000) n =ROW_NUMBER() OVER (ORDER BY x.[object_id]) FROM x CROSS JOIN x AS y ORDER BY n;
Plán:

Naskládané CTE
Abychom získali přesně 50 000 řádků, potřebujeme provést pouze malou úpravu našich naskládaných CTE:
;WITH e1(n) AS( VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1) , -- 10e2(n) AS (VYBERTE 1 Z e1 CROSS JOIN e1 AS b), -- 10*10e3(n) AS (VYBERTE 1 Z e2 CROSS JOIN e2 AS b), -- 100*100e4(n) AS (VYBERTE 1 Z e3 CROSS JOIN (VYBERTE NEJLEPŠÍCH 5 n Z e1) JAKO b) -- 5*10000 VYBERTE n =ŘÁDEK_ČÍSLO() PŘES (ORDER BY n) OD e4 ORDER BY n;
Plán:

Rekurzivní CTE
K získání 50 000 řádků z našeho rekurzivního CTE je nutná ještě méně podstatná změna:změňte WHERE klauzuli na 50 000 a změňte MAXRECURSION možnost na nulu.
;WITH n(n) AS( SELECT 1 UNION ALL SELECT n+1 FROM n WHERE n <50000)SELECT n FROM n ORDER BY nOPTION (MAXRECURSION 0);
Plán:
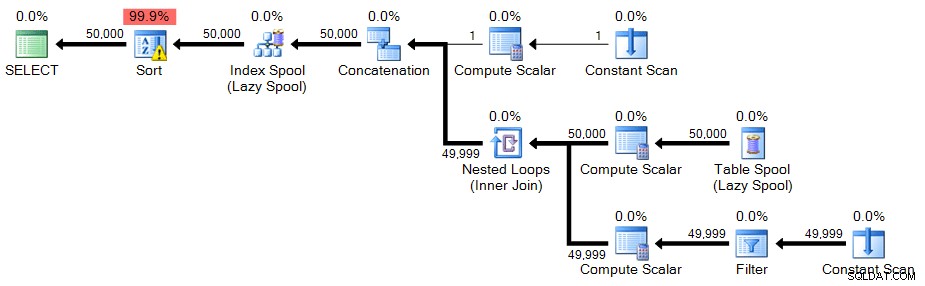
V tomto případě je na řazení varovná ikona – jak se ukázalo, v mém systému je řazení nutné k přelití do tempdb. Možná neuvidíte únik na vašem systému, ale mělo by to být varování o zdrojích požadovaných pro tuto techniku.
Výkon
Stejně jako u poslední sady testů porovnáme každou techniku, včetně tabulky čísel, se studenou i teplou mezipamětí a komprimovanou i nekomprimovanou:
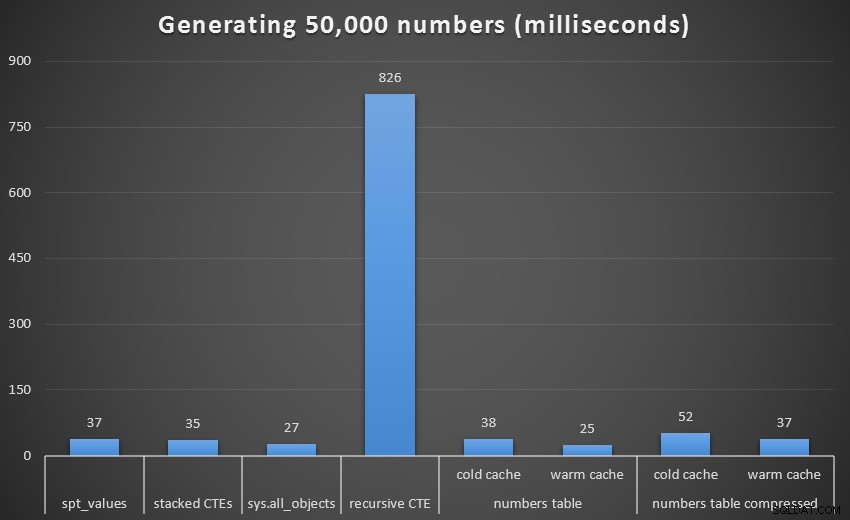
Běh v milisekundách pro vygenerování 50 000 po sobě jdoucích čísel
Abychom získali lepší vizuál, odeberme rekurzivní CTE, což byl v tomto testu totální pes a který zkresluje výsledky:
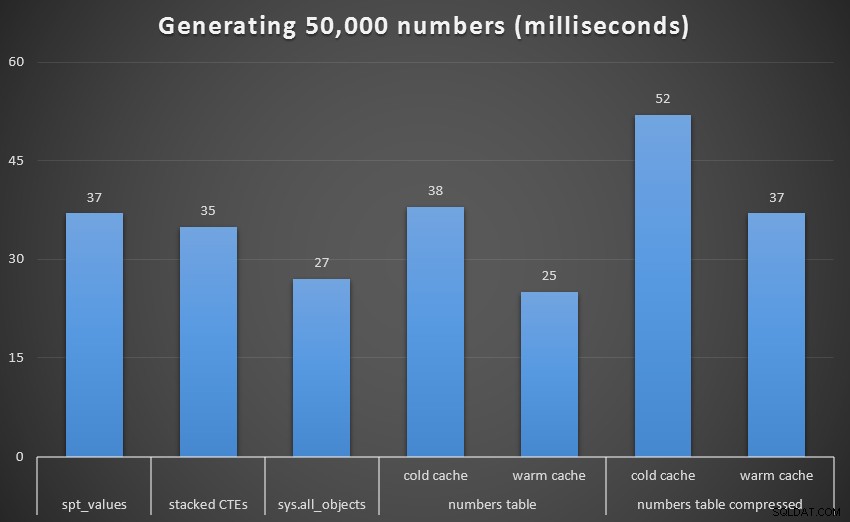
Běh v milisekundách pro vygenerování 50 000 souvislých čísel (kromě rekurzivních CTE)
U 1 000 řádků byl rozdíl mezi komprimovaným a nekomprimovaným marginální, protože dotaz potřeboval přečíst pouze 8 a 9 stránek. Při 50 000 řádcích se mezera trochu zvětšuje:74 stránek oproti 113. Zdá se však, že celkové náklady na dekompresi dat převažují nad úsporami v I/O. Takže s 50 000 řádky se nekomprimovaná tabulka čísel jeví jako nejúčinnější způsob odvození souvislé množiny – i když je pravda, že výhoda je marginální.
Generování sady 1 000 000 čísel
I když si nedovedu představit mnoho případů použití, kdy byste potřebovali takto velkou souvislou sadu čísel, chtěl jsem ji zahrnout pro úplnost, a protože jsem v tomto měřítku učinil několik zajímavých pozorování.
Tabulka čísel
Žádné překvapení, náš dotaz je nyní:
VYBERTE NEJLEPŠÍCH 1000000 n Z dbo.Numbers ORDER BY n;
TOP není nezbytně nutné, ale to jen proto, že víme, že naše tabulka Numbers a požadovaný výstup mají stejný počet řádků. Plán je stále dost podobný předchozím testům:
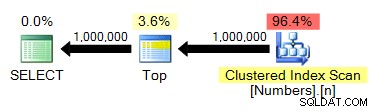
spt_values
Chcete-li získat CROSS JOIN což dává 1 000 000 řádků, musíme vzít 1 000 na druhou:
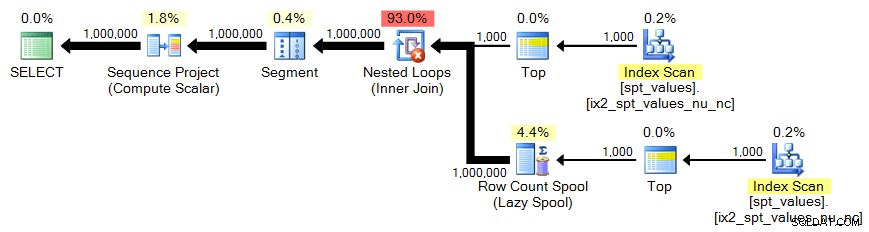
;WITH x AS ( SELECT TOP (1000) number FROM [master]..spt_values)SELECT n =ROW_NUMBER() OVER (ORDER BY x.number) FROM x CROSS JOIN x AS y ORDER BY n;
Plán:
sys.all_objects
Opět potřebujeme křížový součin 1000 řádků:
;WITH x AS ( SELECT TOP (1000) [object_id] FROM sys.all_objects)SELECT n =ROW_NUMBER() OVER (ORDER BY x.[object_id]) FROM x CROSS JOIN x AS y ORDER BY n;Plán:
Naskládané CTE
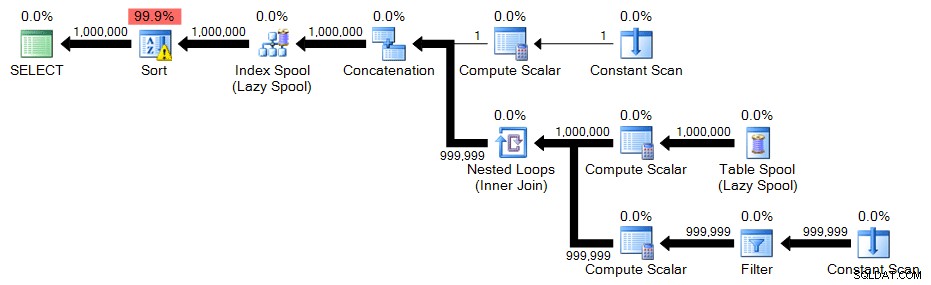
Pro skládaný CTE potřebujeme jen trochu jinou kombinaci
CROSS JOINs, abyste se dostali na 1 000 000 řádků:;WITH e1(n) AS( VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1 UNION VŠECHNY VYBRAT 1) , -- 10e2(n) AS (VYBERTE 1 Z e1 CROSS JOIN e1 AS b), -- 10*10e3(n) AS (VYBERTE 1 Z e1 CROSS JOIN e2 AS b), -- 10*100e4(n) AS (SELECT 1 FROM e3 CROSS JOIN e3 AS b) -- 1000*1000 SELECT n =ROW_NUMBER() OVER (ORDER BY n) FROM e4 ORDER BY n;Plán:
Při této velikosti řádku můžete vidět, že skládané řešení CTE jde paralelně. Tak jsem také spustil verzi s
MAXDOP 1získat podobný půdorysný tvar jako dříve a zjistit, zda rovnoběžnost skutečně pomáhá:
Rekurzivní CTE
Rekurzivní CTE má opět jen malou změnu; pouze
WHEREklauzule je třeba změnit:;WITH n(n) AS( SELECT 1 UNION ALL SELECT n+1 FROM n WHERE n <1000000)SELECT n FROM n ORDER BY nOPTION (MAXRECURSION 0);Plán:
Výkon
Opět vidíme, že výkon rekurzivního CTE je propastný:
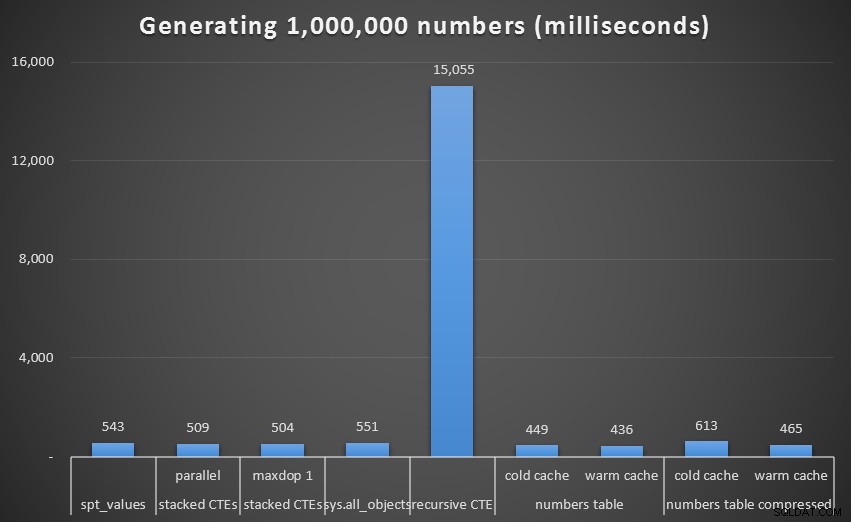
Běh v milisekundách pro vygenerování 1 000 000 souvislých číselOdstraněním této odlehlé hodnoty z grafu získáme lepší obrázek o výkonu:
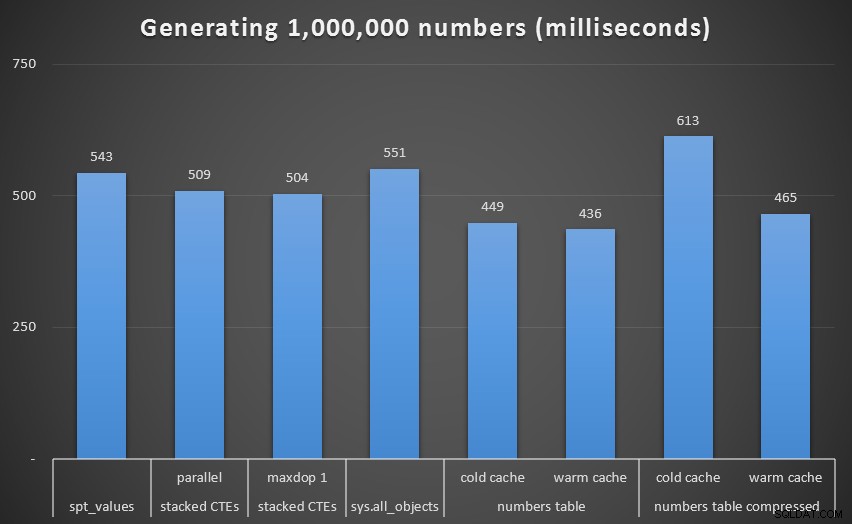
Běh v milisekundách pro vygenerování 1 000 000 souvislých čísel (kromě rekurzivních CTE)I když opět vidíme nekomprimovanou tabulku Numbers (alespoň s teplou mezipamětí) jako vítěze, rozdíl ani v tomto měřítku není až tak markantní.
Pokračování…
Nyní, když jsme důkladně prozkoumali několik přístupů ke generování posloupnosti čísel, přejdeme k datům. V posledním příspěvku této série si projdeme konstrukci časového období jako množiny, včetně použití kalendářní tabulky a několika případů použití, kde se to může hodit.
[ Část 1 | Část 2 | Část 3 ]
Příloha:Počet řádků
Možná se nepokoušíte vygenerovat přesný počet řádků; můžete místo toho chtít jednoduchý způsob generování velkého množství řádků. Níže je uveden seznam kombinací zobrazení katalogu, které vám umožní získat různé počty řádků, pokud jednoduše
SELECTbezWHEREdoložka. Všimněte si, že tato čísla budou záviset na tom, zda používáte RTM nebo service pack (protože některé systémové objekty se přidávají nebo upravují), a také na tom, zda máte prázdnou databázi.



| Zdroj | Počet řádků | ||
|---|---|---|---|
| SQL Server 2008 R2 | SQL Server 2012 | SQL Server 2014 | |
| master..spt_values | 2 508 | 2 515 | 2 519 |
| master..spt_values CROSS JOIN master..spt_values | 6 290 064 | 6 325 225 | 6 345 361 |
| sys.all_objects | 1 990 | 2 089 | 2 165 |
| sys.all_columns | 5 157 | 7 276 | 8 560 |
| sys.all_objects CROSS JOIN sys.all_objects | 3 960 100 | 4 363 921 | 4 687 225 |
| sys.all_objects CROSS JOIN sys.all_columns | 10 262 430 | 15 199 564 | 18 532 400 |
| sys.all_columns CROSS JOIN sys.all_columns | 26 594 649 | 52 940 176 | 73 273 600 |
Tabulka 1:Počet řádků pro různé dotazy zobrazení katalogu