Dříve v této sérii (1. část | 2. část) jsme hovořili o generování řady čísel pomocí různých technik. I když je to zajímavé a v některých scénářích užitečné, praktičtější aplikací je generování série souvislých dat; například přehled, který vyžaduje zobrazení všech dnů v měsíci, i když v některých dnech nebyly žádné transakce.
V předchozím příspěvku jsem zmínil, že je snadné odvodit řadu dní z řady čísel. Protože jsme již vytvořili několik způsobů, jak odvodit řadu čísel, podívejme se, jak vypadá další krok. Začněme velmi jednoduše a předstírejme, že chceme spustit přehled po dobu tří dnů, od 1. ledna do 3. ledna, a zahrnout řádek pro každý den. Staromódním způsobem by bylo vytvořit tabulku #temp, vytvořit smyčku, mít proměnnou, která obsahuje aktuální den, v rámci smyčky vložit řádek do tabulky #temp až do konce rozsahu a poté použít # dočasná tabulka k vnějšímu spojení s našimi zdrojovými daty. To je více kódu, než zde vůbec chci prezentovat, nehledě na to, že se vloží do výroby, udržuje a kolegové se od něj učí.
Jednoduchý začátek
Se zavedenou posloupností čísel (bez ohledu na zvolenou metodu) je tento úkol mnohem jednodušší. V tomto příkladu mohu nahradit generátory složitých sekvencí velmi jednoduchým sjednocením, protože potřebuji pouze tři dny. Udělám tuto sadu tak, aby obsahovala čtyři řady, aby bylo také snadné předvést, jak odříznout přesně na řadu, kterou potřebujete.
Za prvé, máme několik proměnných, které drží začátek a konec rozsahu, který nás zajímá:
DECLARE @s DATE = '2012-01-01', @e DATE = '2012-01-03';
Nyní, když začneme pouze s jednoduchým generátorem řad, může to vypadat takto. Chystám se přidat ORDER BY zde také pro jistotu, protože se nikdy nemůžeme spolehnout na domněnky, které o pořádku děláme.
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT n FROM n ORDER BY n; -- result: n ---- 1 2 3 4
K převodu na řadu dat můžeme jednoduše použít DATEADD() od data zahájení:
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT DATEADD(DAY, n, @s) FROM n ORDER BY n; -- result: ---- 2012-01-02 2012-01-03 2012-01-04 2012-01-05
To stále není úplně v pořádku, protože náš sortiment začíná 2. místo 1. Abychom tedy mohli jako základ použít naše počáteční datum, musíme převést naši sadu z 1 na 0. Můžeme to udělat odečtením 1:
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT DATEADD(DAY, n-1, @s) FROM n ORDER BY n; -- result: ---- 2012-01-01 2012-01-02 2012-01-03 2012-01-04
Téměř tam! Potřebujeme pouze omezit výsledek z naší větší série zdroje, což můžeme udělat přidáním DATEDIFF , ve dnech, mezi začátkem a koncem rozsahu, na TOP operátor – a poté přidání 1 (od DATEDIFF v podstatě hlásí rozsah s otevřeným koncem).
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM n ORDER BY n; -- result: ---- 2012-01-01 2012-01-02 2012-01-03
Přidávání skutečných dat
Nyní, abychom viděli, jak bychom se spojili s jinou tabulkou, abychom odvodili sestavu, stačí použít náš nový dotaz a vnější spojení proti zdrojovým datům.
;WITH n(n) AS ( SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 ), d(OrderDate) AS ( SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM n ORDER BY n ) SELECT d.OrderDate, OrderCount = COUNT(o.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeader AS o ON o.OrderDate >= d.OrderDate AND o.OrderDate < DATEADD(DAY, 1, d.OrderDate) GROUP BY d.OrderDate ORDER BY d.OrderDate;
(Všimněte si, že již nemůžeme říkat COUNT(*) , protože to bude počítat levou stranu, která bude vždy 1.)
Jiný způsob, jak to napsat, by byl:
;WITH d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s)
FROM
(
SELECT 1 UNION ALL SELECT 2 UNION ALL
SELECT 3 UNION ALL SELECT 4
) AS n(n) ORDER BY n
)
SELECT
d.OrderDate,
OrderCount = COUNT(o.SalesOrderID)
FROM d
LEFT OUTER JOIN Sales.SalesOrderHeader AS o
ON o.OrderDate >= d.OrderDate
AND o.OrderDate < DATEADD(DAY, 1, d.OrderDate)
GROUP BY d.OrderDate
ORDER BY d.OrderDate;
To by mělo usnadnit představu, jak byste nahradili úvodní CTE generováním datové sekvence z libovolného zdroje, který si vyberete. Projdeme si je (s výjimkou rekurzivního přístupu CTE, který sloužil pouze ke zkreslení grafů), pomocí AdventureWorks2012, ale použijeme SalesOrderHeaderEnlarged tabulku jsem vytvořil z tohoto skriptu od Jonathana Kehayiase. Na pomoc s tímto konkrétním dotazem jsem přidal index:
CREATE INDEX d_so ON Sales.SalesOrderHeaderEnlarged(OrderDate);
Všimněte si také, že vybírám libovolné časové období, o kterém vím, že v tabulce existuje.
Tabulka čísel
;WITH d(OrderDate) AS ( SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM dbo.Numbers ORDER BY n ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Plán (kliknutím zvětšíte):
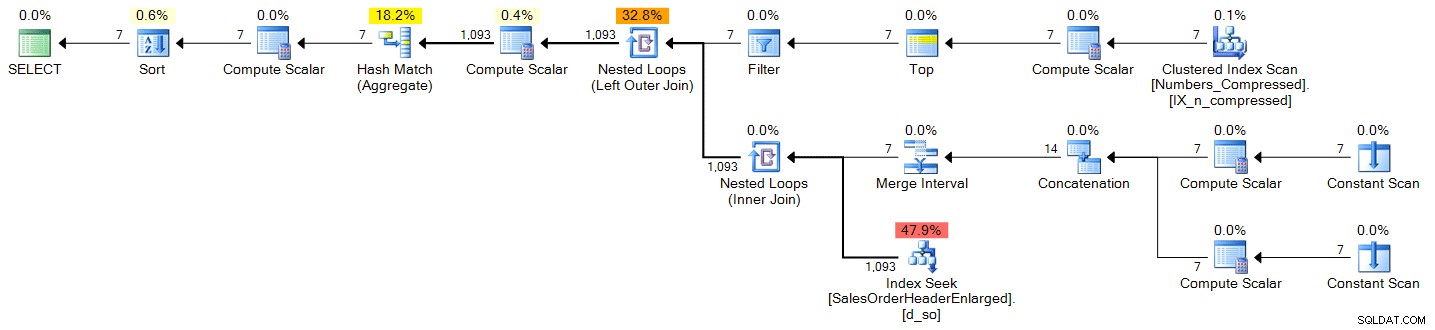
spt_values
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; ;WITH d(OrderDate) AS ( SELECT DATEADD(DAY, n-1, @s) FROM (SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) ROW_NUMBER() OVER (ORDER BY Number) FROM master..spt_values) AS x(n) ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Plán (kliknutím zvětšíte):
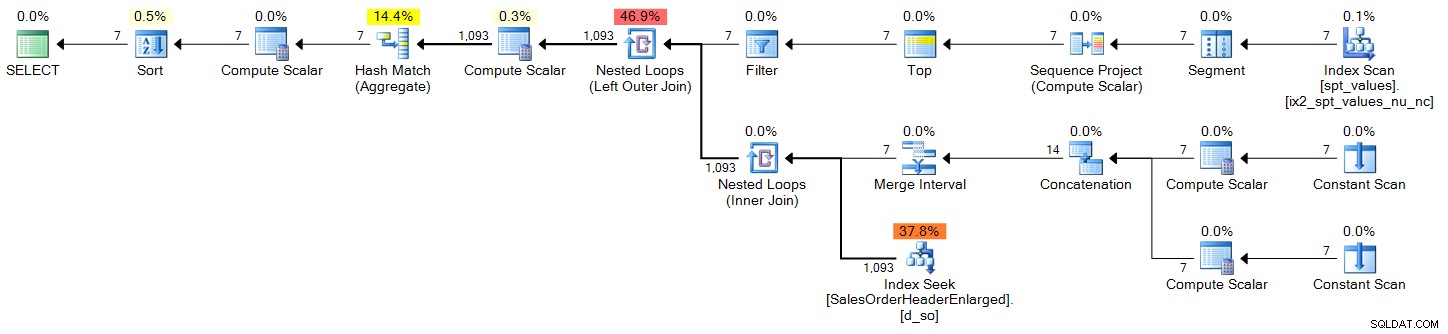
sys.all_objects
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; ;WITH d(OrderDate) AS ( SELECT DATEADD(DAY, n-1, @s) FROM (SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects) AS x(n) ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Plán (kliknutím zvětšíte):
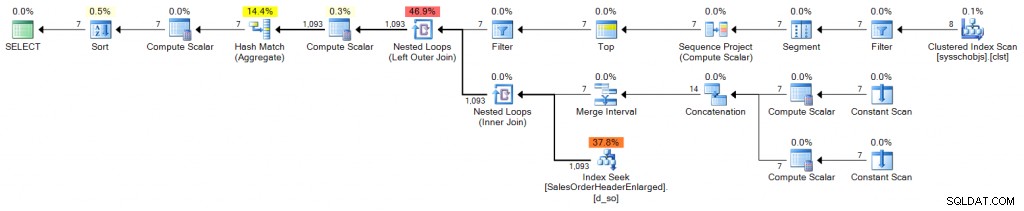
Naskládané CTE
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29';
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b),
d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1)
d = DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY n)-1, @s)
FROM e2
)
SELECT
d.OrderDate,
OrderCount = COUNT(s.SalesOrderID)
FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s
ON s.OrderDate >= @s AND s.OrderDate <= @e
AND d.OrderDate = CONVERT(DATE, s.OrderDate)
WHERE d.OrderDate >= @s AND d.OrderDate <= @e
GROUP BY d.OrderDate
ORDER BY d.OrderDate; Plán (kliknutím zvětšíte):
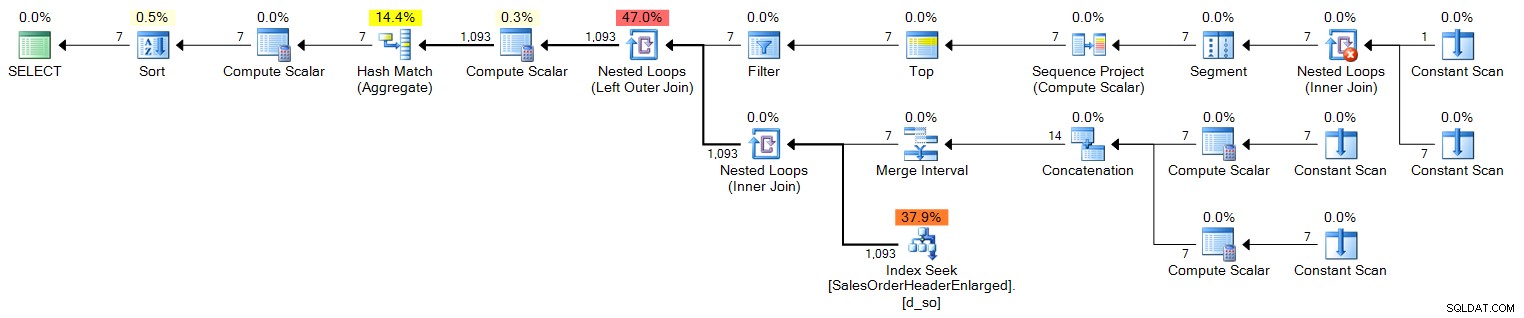
Nyní, po dobu jednoho roku, to nezkrátí, protože produkuje pouze 100 řádků. Na rok bychom potřebovali pokrýt 366 řádků (abychom zohlednili potenciální přestupné roky), takže by to vypadalo takto:
DECLARE @s DATE = '2006-10-23', @e DATE = '2007-10-22';
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b),
e3(n) AS (SELECT 1 FROM e2 CROSS JOIN (SELECT TOP (37) n FROM e2) AS b),
d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1)
d = DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY N)-1, @s)
FROM e3
)
SELECT
d.OrderDate,
OrderCount = COUNT(s.SalesOrderID)
FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s
ON s.OrderDate >= @s AND s.OrderDate <= @e
AND d.OrderDate = CONVERT(DATE, s.OrderDate)
WHERE d.OrderDate >= @s AND d.OrderDate <= @e
GROUP BY d.OrderDate
ORDER BY d.OrderDate; Plán (kliknutím zvětšíte):
Tabulka kalendáře
To je novinka, o které jsme v předchozích dvou příspěvcích moc nemluvili. Pokud používáte časové řady pro mnoho dotazů, měli byste zvážit použití tabulky Numbers i tabulky Kalendář. Stejný argument platí o tom, kolik místa je skutečně vyžadováno a jak rychlý bude přístup, když je tabulka často dotazována. Například pro uložení 30 let dat vyžaduje méně než 11 000 řádků (přesný počet závisí na tom, kolik přestupných let pokrýváte) a zabírá pouhých 200 kB. Ano, čtete správně:200 kilobajtů . (A komprimovaný má pouze 136 KB.)
Chcete-li vygenerovat tabulku Kalendáře s 30 lety dat, za předpokladu, že jste již byli přesvědčeni, že mít tabulku Numbers je dobrá věc, můžeme udělat toto:
DECLARE @s DATE = '2005-07-01'; -- earliest year in SalesOrderHeader DECLARE @e DATE = DATEADD(DAY, -1, DATEADD(YEAR, 30, @s)); SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) d = CONVERT(DATE, DATEADD(DAY, n-1, @s)) INTO dbo.Calendar FROM dbo.Numbers ORDER BY n; CREATE UNIQUE CLUSTERED INDEX d ON dbo.Calendar(d);
Abychom nyní mohli tuto tabulku Kalendáře použít v dotazu na přehled prodeje, můžeme napsat mnohem jednodušší dotaz:
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; SELECT OrderDate = c.d, OrderCount = COUNT(s.SalesOrderID) FROM dbo.Calendar AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND c.d = CONVERT(DATE, s.OrderDate) WHERE c.d >= @s AND c.d <= @e GROUP BY c.d ORDER BY c.d;
Plán (kliknutím zvětšíte):

Výkon
Vytvořil jsem komprimované i nekomprimované kopie tabulek Numbers a Calendar a testoval jsem rozsah jednoho týdne, jednoho měsíce a jednoho roku. Také jsem spouštěl dotazy s chladnou mezipamětí a teplou mezipamětí, ale to se ukázalo jako z velké části bezvýznamné.
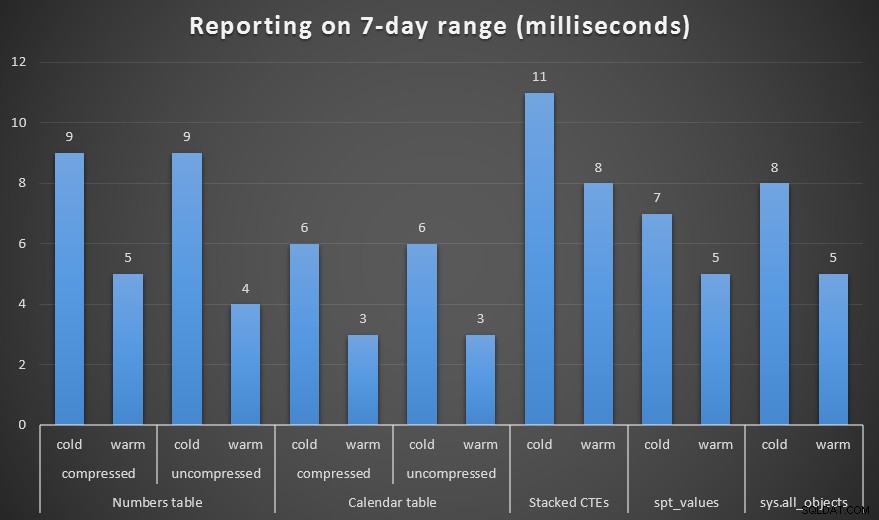
Trvání v milisekundách pro vygenerování týdenního rozsahu
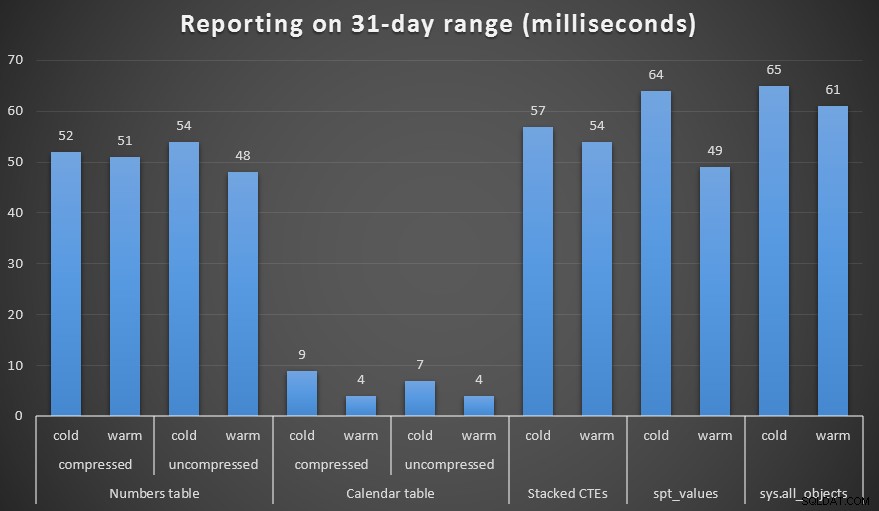
Trvání v milisekundách pro vygenerování měsíčního rozsahu
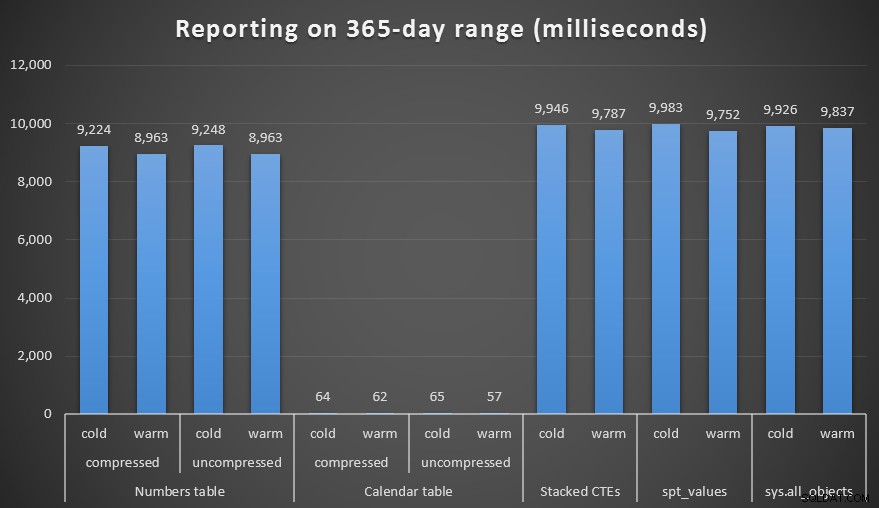
Trvání v milisekundách pro vygenerování ročního rozsahu
Dodatek
Paul White (blog | @SQL_Kiwi) poukázal na to, že pomocí následujícího dotazu můžete donutit tabulku Numbers k vytvoření mnohem efektivnějšího plánu:
SELECT OrderDate = DATEADD(DAY, n, 0), OrderCount = COUNT(s.SalesOrderID) FROM dbo.Numbers AS n LEFT OUTER JOIN Sales.SalesOrderHeader AS s ON s.OrderDate >= CONVERT(DATETIME, @s) AND s.OrderDate < DATEADD(DAY, 1, CONVERT(DATETIME, @e)) AND DATEDIFF(DAY, 0, OrderDate) = n WHERE n.n >= DATEDIFF(DAY, 0, @s) AND n.n <= DATEDIFF(DAY, 0, @e) GROUP BY n ORDER BY n;
V tuto chvíli nehodlám znovu spouštět všechny testy výkonu (cvičení pro čtenáře!), ale budu předpokládat, že to vygeneruje lepší nebo podobné časování. Přesto si myslím, že tabulka Kalendář je užitečná věc, i když to není nezbytně nutné.
Závěr
Výsledky hovoří samy za sebe. Pro generování série čísel vítězí přístup tabulky Numbers, ale jen okrajově – i při 1 000 000 řádcích. A u řady dat, na spodním konci, neuvidíte velký rozdíl mezi různými technikami. Je však zcela jasné, že jak se vaše časové období zvětšuje, zvláště když máte co do činění s velkou zdrojovou tabulkou, tabulka Kalendář skutečně prokazuje svou hodnotu – zejména s ohledem na její malou paměť. I se šíleným kanadským metrickým systémem je 60 milisekund mnohem lepších než asi 10 *sekund*, když na disku vzniklo pouze 200 kB.
Doufám, že se vám tato malá série líbila; je to téma, ke kterému jsem se chtěl vrátit už celé věky.
[ Část 1 | Část 2 | Část 3 ]