Seskupování dat o datu a čase zahrnuje uspořádání dat do skupin představujících pevné časové intervaly pro analytické účely. Vstupem jsou často data časových řad uložená v tabulce, kde řádky představují měření prováděná v pravidelných časových intervalech. Měřením mohou být například měření teploty a vlhkosti každých 5 minut a vy chcete data seskupit pomocí hodinových segmentů a vypočítat agregace jako průměr za hodinu. Přestože jsou data časových řad běžným zdrojem pro analýzu založenou na segmentech, tento koncept je stejně relevantní pro všechna data, která zahrnují atributy data a času a související měření. Můžete například chtít uspořádat údaje o prodeji do segmentů fiskálního roku a vypočítat agregace, jako je celková hodnota prodeje za fiskální rok. V tomto článku se zaměřím na dva způsoby bucketizace dat a času. Jeden používá funkci s názvem DATE_BUCKET, která je v době psaní tohoto článku dostupná pouze v Azure SQL Edge. Další používá vlastní výpočet, který emuluje funkci DATE_BUCKET, kterou můžete použít v jakékoli verzi, edici a variantě SQL Serveru a Azure SQL Database.
Ve svých příkladech použiji ukázkovou databázi TSQLV5. Skript, který vytváří a naplňuje TSQLV5, najdete zde a jeho ER diagram zde.
DATE_BUCKET
Jak bylo zmíněno, funkce DATE_BUCKET je aktuálně dostupná pouze v Azure SQL Edge. SQL Server Management Studio již má podporu IntelliSense, jak je znázorněno na obrázku 1:
 Obrázek 1:Podpora inteligence pro DATE_BUCKET v SSMS
Obrázek 1:Podpora inteligence pro DATE_BUCKET v SSMS
Syntaxe funkce je následující:
DATE_BUCKET ( <část data>, <šířka kbelíku>, <časové razítko>[,Vstupní původ představuje kotevní bod na šipce času. Může to být jakýkoli z podporovaných datových typů data a času. Pokud není specifikováno, výchozí je 1900, 1. ledna, půlnoc. Pak si můžete představit časovou osu rozdělenou do samostatných intervalů počínaje počátečním bodem, kde délka každého intervalu je založena na vstupech šířka segmentu a část data . První je množství a to druhé je jednotka. Chcete-li například uspořádat časovou osu v jednotkách po 2 měsících, zadali byste 2 jako šířku kbelíku vstup a měsíc jako část data vstup.
Vstupní časové razítko je libovolný bod v čase, který je třeba přiřadit k jeho obsahujícímu segmentu. Jeho datový typ musí odpovídat datovému typu vstupu původ . Vstupní časové razítko je hodnota data a času spojená s mírami, které zaznamenáváte.
Výstup funkce je pak počátečním bodem obsahujícího kbelíku. Datový typ výstupu je datový typ vstupu časové razítko .
Pokud by to již nebylo zřejmé, obvykle byste použili funkci DATE_BUCKET jako prvek seskupovací sady v klauzuli GROUP BY dotazu a přirozeně ji také vrátili v seznamu SELECT spolu s agregovanými mírami.
Stále jste trochu zmatení funkcí, jejími vstupy a výstupy? Možná by pomohl konkrétní příklad s vizuálním znázorněním logiky funkce. Začnu příkladem, který používá vstupní proměnné, a později v článku demonstruji typičtější způsob, jakým byste je použili jako součást dotazu na vstupní tabulku.
Zvažte následující příklad:
DECLARE @timestamp AS DATETIME2 ='20210510 06:30:00', @bucketwidth AS INT =2, @origin AS DATETIME2 ='20210115 00:00:00'; SELECT DATE_BUCKET(měsíc, @bucketwidth, @časové razítko, @původ);
Vizuální znázornění logiky funkce můžete najít na obrázku 2.
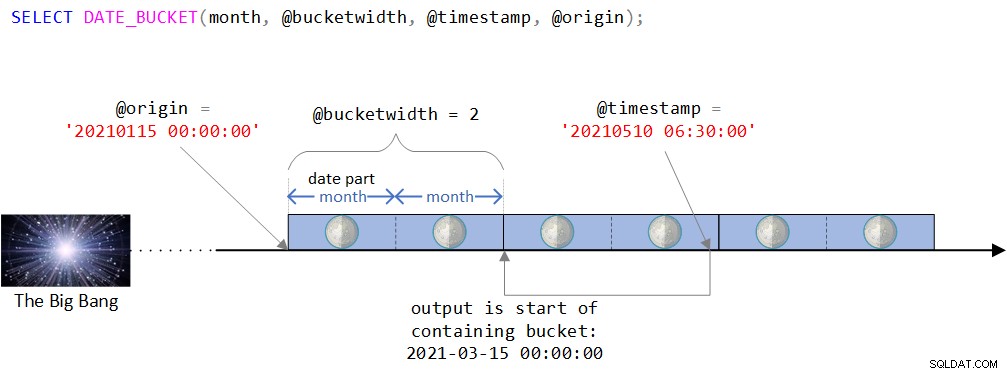 Obrázek 2:Vizuální znázornění logiky funkce DATE_BUCKET
Obrázek 2:Vizuální znázornění logiky funkce DATE_BUCKET
Jak můžete vidět na obrázku 2, výchozím bodem je hodnota DATETIME2 15. ledna 2021 o půlnoci. Pokud se vám tento výchozí bod zdá trochu zvláštní, měli byste pravdu, když intuitivně vycítili, že normálně byste použili přirozenější bod, jako je začátek nějakého roku nebo začátek nějakého dne. Ve skutečnosti byste se často spokojili s výchozím nastavením, které, jak si vzpomínáte, je 1. ledna 1900 o půlnoci. Záměrně jsem chtěl použít méně triviální výchozí bod, abych mohl diskutovat o určitých složitostech, které by při použití přirozenějšího bodu nemusely být relevantní. Více o tom již brzy.
Časová osa je pak rozdělena do samostatných 2měsíčních intervalů počínaje výchozím bodem. Vstupní časové razítko je hodnota DATETIME2 10. května 2021, 6:30.
Všimněte si, že vstupní časové razítko je součástí segmentu, který začíná 15. března 2021 o půlnoci. Funkce skutečně vrací tuto hodnotu jako hodnotu typu DATETIME2:
---------------------------2021-03-15 00:00:00.0000000
Emulace DATE_BUCKET
Pokud nepoužíváte Azure SQL Edge, pokud chcete bucketizovat data a časová data, budete si prozatím muset vytvořit vlastní vlastní řešení, které bude emulovat to, co dělá funkce DATE_BUCKET. Není to příliš složité, ale není to ani příliš jednoduché. Práce s daty o datu a čase často zahrnuje složitou logiku a úskalí, na která je třeba si dávat pozor.
Výpočet sestavím v krocích a použiji stejné vstupy, jaké jsem použil v příkladu DATE_BUCKET, který jsem ukázal dříve:
DECLARE @timestamp AS DATETIME2 ='20210510 06:30:00', @bucketwidth AS INT =2, @origin AS DATETIME2 ='20210115 00:00:00';
Ujistěte se, že jste tuto část zahrnuli před každou ukázku kódu, kterou ukážu, pokud chcete kód skutečně spustit.
V kroku 1 použijete funkci DATEDIFF k výpočtu rozdílu v části data jednotek mezi původem a časové razítko . Tento rozdíl budu označovat jako diff1 . To se provádí pomocí následujícího kódu:
VYBRAT DATUMDIFF(měsíc, @původ, @časové razítko) JAKO rozdíl1;
S našimi vzorovými vstupy tento výraz vrátí 4.
Záludná část je v tom, že musíte spočítat, kolik celých jednotek části data existují mezi původem a časové razítko . U našich vzorových vstupů jsou mezi těmito dvěma celé 3 měsíce a ne 4. Důvodem, proč funkce DATEDIFF hlásí 4, je to, že když počítá rozdíl, dívá se pouze na požadovanou část vstupů a vyšší části, ale nikoli na nižší části. . Když se tedy zeptáte na rozdíl v měsících, funkce se stará pouze o části vstupů typu rok a měsíc, nikoli o části pod měsícem (den, hodina, minuta, sekunda atd.). Mezi lednem 2021 a květnem 2021 jsou 4 měsíce, ale mezi úplnými vstupy jsou jen 3 celé měsíce.
Účelem kroku 2 je pak vypočítat, kolik celých jednotek části data existují mezi původem a časové razítko . Tento rozdíl budu označovat jako diff2 . Chcete-li toho dosáhnout, můžete přidat diff1 jednotky části data k původu . Pokud je výsledek větší než časové razítko , odečtete 1 od diff1 pro výpočet diff2 , jinak odečtěte 0, a proto použijte diff1 jako diff2 . To lze provést pomocí výrazu CASE, například takto:
SELECT DATEDIFF(měsíc, @origin, @timestamp) - CASE WHEN DATEADD( month, DATEDIFF(měsíc, @origin, @timestamp), @origin)> @timestamp THEN 1 ELSE 0 END AS diff2;
Tento výraz vrátí 3, což je počet celých měsíců mezi dvěma vstupy.
Připomeňme, že dříve jsem zmínil, že ve svém příkladu jsem záměrně použil počáteční bod, který není přirozený, jako je kulatý začátek období, abych mohl diskutovat o určitých složitostech, které by pak mohly být relevantní. Pokud například použijete měsíc jako část data a přesný začátek některého měsíce (1 některého měsíce o půlnoci) jako počátek, můžete bezpečně přeskočit krok 2 a použít diff1 jako diff2 . To proto, že původ + rozdíl1 nikdy nemůže být> časové razítko v takovém případě. Mým cílem je však poskytnout logicky ekvivalentní alternativu k funkci DATE_BUCKET, která by fungovala správně pro jakýkoli počáteční bod, společný nebo ne. Takže do svých příkladů zahrnu logiku pro Krok 2, ale pamatujte si, že až zjistíte případy, kdy tento krok není relevantní, můžete bezpečně odstranit část, kde odečítáte výstup výrazu CASE.
V kroku 3 určíte, kolik jednotek části data existuje v celých segmentech, které existují mezi origin a časové razítko . Tuto hodnotu budu označovat jako diff3 . To lze provést pomocí následujícího vzorce:
diff3 =diff2 / <šířka kbelíku> * <šířka kbelíku>
Trik je v tom, že při použití operátoru dělení / v T-SQL s celočíselnými operandy získáte celočíselné dělení. Například 3 / 2 v T-SQL je 1 a ne 1,5. Výraz diff2 / <šířka kbelíku> udává počet celých segmentů, které existují mezi původem a časové razítko (v našem případě 1). Vynásobením výsledku šířkou segmentu pak vám dá počet jednotek části data které existují v rámci těchto celých kbelíků (v našem případě 2). Tento vzorec se v T-SQL převádí na následující výraz:
SELECT ( DATEDIFF(měsíc, @origin, @timestamp) - CASE WHEN DATEADD( month, DATEDIFF(měsíc, @origin, @timestamp), @origin)> @timestamp THEN 1 ELSE 0 END ) / @bucketwidth * @ bucketwidth AS diff3;
Tento výraz vrátí 2, což je počet měsíců v celých 2měsíčních segmentech, které existují mezi dvěma vstupy.
V kroku 4, který je posledním krokem, přidáte diff3 jednotky části data k původu pro výpočet začátku obsahujícího segmentu. Zde je kód, jak toho dosáhnout:
SELECT DATEADD( měsíc, ( DATEDIFF(měsíc, @počátek, @časové razítko) - CASE WHEN DATEADD( měsíc, DATEDIFF(měsíc, @počátek, @časové razítko), @počátek)> @timestamp THEN 1 ELSE 0 END ) / @bucketwidth * @bucketwidth, @origin);
Tento kód generuje následující výstup:
---------------------------2021-03-15 00:00:00.0000000
Jak si vzpomínáte, jedná se o stejný výstup vytvořený funkcí DATE_BUCKET pro stejné vstupy.
Navrhuji, abyste tento výraz vyzkoušeli s různými vstupy a částmi. Ukážu vám zde několik příkladů, ale můžete zkusit svůj vlastní.
Zde je příklad původu je jen mírně před časovým razítkem v měsíci:
DECLARE @timestamp AS DATETIME2 ='20210510 06:30:00', @bucketwidth AS INT =2, @origin AS DATETIME2 ='20210110 06:30:01'; -- SELECT DATE_BUCKET(týden, @šířka segmentu, @časové razítko, @původ); VYBERTE DATEADD( měsíc, ( DATEDIFF(měsíc, @počátek, @časové razítko) - CASE WHEN DATEADD( měsíc, DATEDIFF(měsíc, @počátek, @časové razítko), @počátek)> @časové razítko THEN 1 ELSE 0 END ) / @bucketwidth * @bucketwidth, @origin);
Tento kód generuje následující výstup:
---------------------------2021-03-10 06:30:01.0000000
Všimněte si, že začátek obsahujícího segmentu je v březnu.
Zde je příklad původu je ve stejném bodě měsíce jako časové razítko :
DECLARE @timestamp AS DATETIME2 ='20210510 06:30:00', @bucketwidth AS INT =2, @origin AS DATETIME2 ='20210110 06:30:00'; -- SELECT DATE_BUCKET(týden, @šířka segmentu, @časové razítko, @původ); VYBERTE DATEADD( měsíc, ( DATEDIFF(měsíc, @počátek, @časové razítko) - CASE WHEN DATEADD( měsíc, DATEDIFF(měsíc, @počátek, @časové razítko), @počátek)> @časové razítko THEN 1 ELSE 0 END ) / @bucketwidth * @bucketwidth, @origin);
Tento kód generuje následující výstup:
---------------------------2021-05-10 06:30:00.0000000
Všimněte si, že tentokrát je začátek obsahujícího segmentu v květnu.
Zde je příklad se 4týdenními segmenty:
DECLARE @timestamp AS DATETIME2 ='20210303 21:22:11', @bucketwidth AS INT =4, @origin AS DATETIME2 ='20210115'; -- SELECT DATE_BUCKET(týden, @šířka segmentu, @časové razítko, @původ); VYBERTE DATEADD( týden, ( DATEDIFF(týden, @počátek, @časové razítko) - CASE WHEN DATEADD( týden, DATEDIFF(týden, @počátek, @časové razítko), @počátek)> @časové razítko THEN 1 ELSE 0 END ) / @bucketwidth * @bucketwidth, @origin);
Všimněte si, že kód používá týden tentokrát.
Tento kód generuje následující výstup:
---------------------------2021-02-12 00:00:00.0000000
Zde je příklad s 15minutovými segmenty:
DECLARE @timestamp AS DATETIME2 ='20210203 21:22:11', @bucketwidth AS INT =15, @origin AS DATETIME2 ='19000101'; -- SELECT DATE_BUCKET(minuta, @šířka segmentu, @časové razítko); SELECT DATEADD( minuta, ( DATEDIFF(minuta, @počátek, @časové razítko) - CASE WHEN DATEADD( minuta, DATEDIFF(minuta, @počátek, @časové razítko), @počátek)> @časové razítko THEN 1 ELSE 0 END ) / @bucketwidth * @bucketwidth, @origin);
Tento kód generuje následující výstup:
---------------------------2021-02-03 21:15:00.0000000
Všimněte si, že část je minuta . V tomto příkladu chcete použít 15minutové segmenty začínající na konci hodiny, takže by fungoval počáteční bod, který je koncem jakékoli hodiny. Ve skutečnosti by fungoval počáteční bod, který má minutovou jednotku 00, 15, 30 nebo 45 s nulami v dolních částech, s libovolným datem a hodinou. Tedy výchozí hodnota, kterou funkce DATE_BUCKET používá pro vstup origin by fungovalo. Samozřejmě, když používáte vlastní výraz, musíte být explicitní ohledně počátečního bodu. Chcete-li tedy sympatizovat s funkcí DATE_BUCKET, můžete použít základní datum o půlnoci jako já ve výše uvedeném příkladu.
Mimochodem, chápete, proč by to byl dobrý příklad, kdy je naprosto bezpečné přeskočit krok 2 v řešení? Pokud jste se skutečně rozhodli přeskočit krok 2, získáte následující kód:
DECLARE @timestamp AS DATETIME2 ='20210203 21:22:11', @bucketwidth AS INT =15, @origin AS DATETIME2 ='19000101'; -- SELECT DATE_BUCKET(minuta, @šířka segmentu, @časové razítko); SELECT DATEADD( minuta, ( DATEDIFF( minuta, @počátek, @časové razítko ) ) / @bucketwidth * @bucketwidth, @origin );
Je jasné, že kód se výrazně zjednoduší, když krok 2 není potřeba.
Seskupování a agregace dat podle intervalů data a času
Existují případy, kdy potřebujete seskupit data a čas, které nevyžadují sofistikované funkce nebo nepraktické výrazy. Předpokládejme například, že se chcete dotazovat na zobrazení Sales.OrderValues v databázi TSQLV5, seskupit data ročně a vypočítat celkový počet objednávek a hodnoty za rok. Je zřejmé, že stačí použít funkci YEAR(orderdate) jako prvek sady seskupení, například takto:
POUŽÍVEJTE TSQLV5; VYBERTE ROK(datum objednávky) JAKO rok objednávky, COUNT(*) JAKO čísla, SUM(hodnota) JAKO celková hodnotaFROM Sales.OrderValuesGROUP BY YEAR(datum objednávky)ORDER BY orderyear;
Tento kód generuje následující výstup:
orderyear numorders totalvalue----------- ----------- ------------2017 152 208083.992018 408 617085.302019 270 440623.Co když ale chcete data seskupit podle fiskálního roku vaší organizace? Některé organizace používají fiskální rok pro účely účetnictví, rozpočtu a finančního výkaznictví, který není v souladu s kalendářním rokem. Řekněme například, že fiskální rok vaší organizace funguje podle fiskálního kalendáře od října do září a je označen kalendářním rokem, ve kterém fiskální rok končí. Takže událost, která se odehrála 3. října 2018, patří do fiskálního roku, který začal 1. října 2018, skončil 30. září 2019 a je označen rokem 2019.
Toho lze poměrně snadno dosáhnout pomocí funkce DATE_BUCKET, například takto:
DECLARE @bucketwidth AS INT =1, @origin AS DATETIME2 ='19001001'; -- toto je 1. října nějakého roku SELECT YEAR(startofbucket) + 1 JAKO fiskální rok, COUNT(*) JAKO čísla, SUM(val) AS totalvalueFROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET(rok, @bucketwidth, orderdate, @ origin ) ) ) JAKO A(startofbucket)GROUP BY startofbucketORDER BY startofbucket;A zde je kód využívající vlastní logický ekvivalent funkce DATE_BUCKET:
DECLARE @bucketwidth AS INT =1, @origin AS DATETIME2 ='19001001'; -- toto je 1. října nějakého roku SELECT YEAR(startofbucket) + 1 JAKO fiskální rok, COUNT(*) JAKO čísla, SUM(val) AS totalvalueFROM Sales.OrderValues CROSS APPLY (VALUES(DATEADD(rok, (DATEDIFF(year, @) origin, orderdate) - CASE WHEN DATEADD( rok, DATEDIFF(rok, @origin, orderdate), @origin)> orderdate THEN 1 ELSE 0 END ) / @bucketwidth * @bucketwidth, @origin) ) ) AS A(startofbucket)GROUP BY startofbucketORDER BY startofbucket;Tento kód generuje následující výstup:
čísla fiskálního roku celková hodnota----------- ----------- ------------2017 70 79728,582018 370 563759,242019 390 6223055.40Použil jsem zde proměnné pro šířku segmentu a počáteční bod, aby byl kód více zobecněný, ale můžete je nahradit konstantami, pokud vždy používáte stejné, a poté výpočet podle potřeby zjednodušit.
Jako mírná obměna výše uvedeného předpokládejme, že váš fiskální rok trvá od 15. července jednoho kalendářního roku do 14. července následujícího kalendářního roku a je označen kalendářním rokem, do kterého patří začátek fiskálního roku. Takže událost, která se odehrála 18. července 2018, patří do fiskálního roku 2018. Událost, která se odehrála 14. července 2018, patří do fiskálního roku 2017. Pomocí funkce DATE_BUCKET byste toho dosáhli takto:
DECLARE @bucketwidth AS INT =1, @origin AS DATETIME2 ='19000715'; -- 15. července začíná fiskální rok SELECT YEAR(startofbucket) JAKO fiskální rok, -- zde není třeba přidávat 1 COUNT(*) AS numorders, SUM(val) AS totalvalueFROM Sales.OrderValues CROSS APPLY (VALUES( DATE_BUCKET( rok,), @bucketwidth, orderdate, @origin ) ) ) JAKO (startofbucket)GROUP BY startofbucketORDER BY startofbucket;Změny oproti předchozímu příkladu můžete vidět v komentářích.
A zde je kód využívající vlastní logický ekvivalent funkce DATE_BUCKET:
DECLARE @bucketwidth AS INT =1, @origin AS DATETIME2 ='19000715'; SELECT YEAR(startofbucket) AS fiskal year, COUNT(*) AS numorders, SUM(val) AS totalvalueFROM Sales.OrderValues CROSS APPLY (VALUES( DATEADD( year, DATEDIFF(year, @origin, orderdate)) - CASE WHEN DATEADD( year, DATEDIFF(rok, @origin, orderdate), @origin)> orderdate THEN 1 ELSE 0 END ) / @bucketwidth * @bucketwidth, @origin) ) ) AS (startofbucket)GROUP BY startofbucketORDER BY startofbucket;Tento kód generuje následující výstup:
čísla fiskálního roku celková hodnota----------- ----------- -----------2016 8 12599,882017 343 495118,142018 479 758075,20Je zřejmé, že v konkrétních případech můžete použít alternativní metody. Vezměte si příklad před posledním, kde fiskální rok trvá od října do září a je označen kalendářním rokem, ve kterém končí fiskální rok. V takovém případě můžete použít následující, mnohem jednodušší výraz:
ROK (datum objednávky) + PŘÍPAD KDYŽ MĚSÍC (datum objednávky) MEZI 10 A 12 PAK 1 JINÝ 0 KONECA váš dotaz by pak vypadal takto:
VYBERTE fiskální rok, COUNT(*) JAKO čísla, SUM(hodnota) JAKO celková hodnotaFROM Prodej.Hodnoty objednávky KŘÍŽOVÉ POUŽITÍ ( HODNOTY( ROK(datum objednávky) + PŘÍPAD, KDYŽ MĚSÍC(datum objednávky) MEZI 10 A 12 POTOM 1 JINÝ) 0 KONEC) A(fiskální rok)SKUPINA PODLE fiskálního rokuORDER BY fiskální rok;Pokud však chcete zobecněné řešení, které by fungovalo v mnoha dalších případech a které byste mohli parametrizovat, přirozeně byste chtěli použít obecnější formu. Pokud máte přístup k funkci DATE_BUCKET, je to skvělé. Pokud ne, můžete použít vlastní logický ekvivalent.
Závěr
Funkce DATE_BUCKET je docela šikovná funkce, která vám umožňuje seskupit data a čas. Je to užitečné pro práci s daty časových řad, ale také pro seskupování jakýchkoli dat, která zahrnují atributy data a času. V tomto článku jsem vysvětlil, jak funguje funkce DATE_BUCKET, a poskytl jsem vlastní logický ekvivalent pro případ, že ji platforma, kterou používáte, nepodporuje.