Úvod
- Při vytváření databázových objektů je třeba dodržovat určitá pravidla. Chcete-li zlepšit výkon databáze, primární klíč, klastrované a neklastrované indexy a omezení by měly být přiřazeny tabulce. Přestože dodržujeme všechna tato pravidla, v tabulce se mohou stále vyskytovat duplicitní řádky.
- Vždy je dobrým zvykem používat databázové klíče. Použití databázových klíčů sníží pravděpodobnost získání duplicitních záznamů v tabulce. Pokud se však v tabulce již vyskytují duplicitní záznamy, existují specifické způsoby, jak tyto duplicitní záznamy odstranit.
Způsoby odstranění duplicitních řádků
- Použití funkce DELETE JOIN příkaz k odstranění duplicitních řádků
Příkaz DELETE JOIN je poskytován v MySQL, který pomáhá odstranit duplicitní řádky z tabulky.
Uvažujme databázi s názvem "studentdb". Vytvoříme do ní tabulku student.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
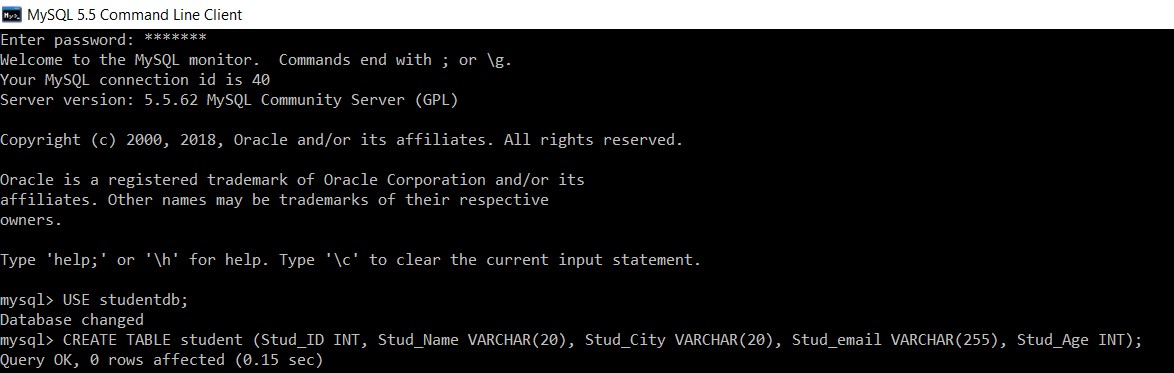
Úspěšně jsme vytvořili tabulku 'student' v databázi 'studentdb'.
Nyní napíšeme následující dotazy pro vložení dat do studentské tabulky.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
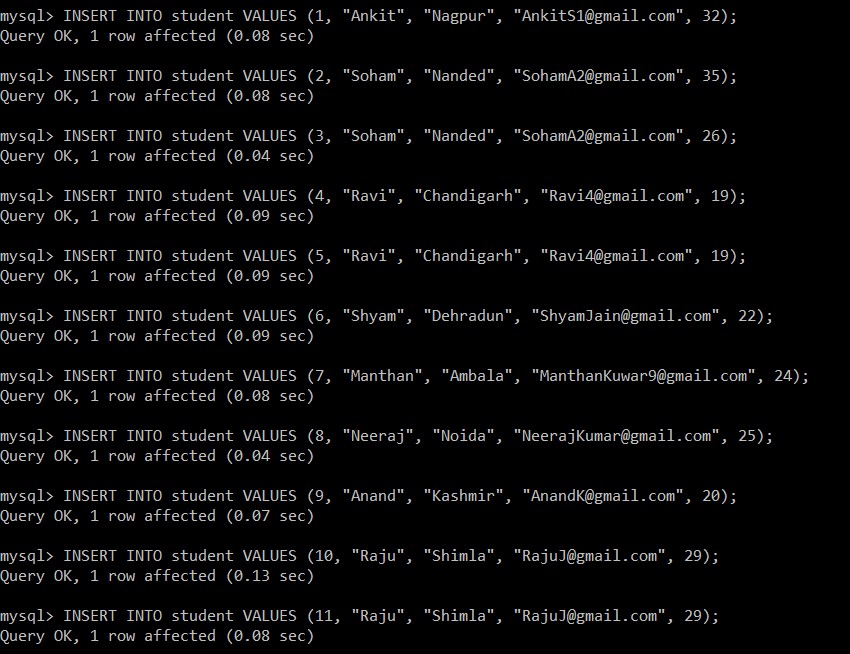
Nyní načteme všechny záznamy ze studentské tabulky. Tuto tabulku a databázi budeme uvažovat pro všechny následující příklady.
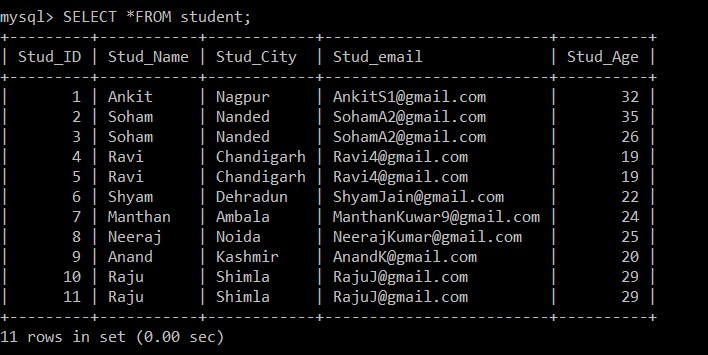
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
Příklad 1:
Napište dotaz k odstranění duplicitních řádků ze studentské tabulky pomocí DELETE JOIN prohlášení.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Použili jsme dotaz DELETE s INNER JOIN. Pro implementaci INNER JOIN na jedné tabulce jsme vytvořili dvě instance s1 a s2. Poté jsme pomocí klauzule WHERE zkontrolovali dvě podmínky, abychom zjistili duplicitní řádky ve studentské tabulce. Pokud je ID e-mailu ve dvou různých záznamech stejné a ID studenta se liší, bude se s ním nakládat jako s duplicitním záznamem podle podmínky klauzule WHERE.
Výstup:
Query OK, 3 rows affected (0.20 sec)Výsledky výše uvedeného dotazu ukazují, že v tabulce studentů jsou tři duplicitní záznamy.

K vyhledání duplicitních záznamů, které byly smazány, použijeme dotaz SELECT.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
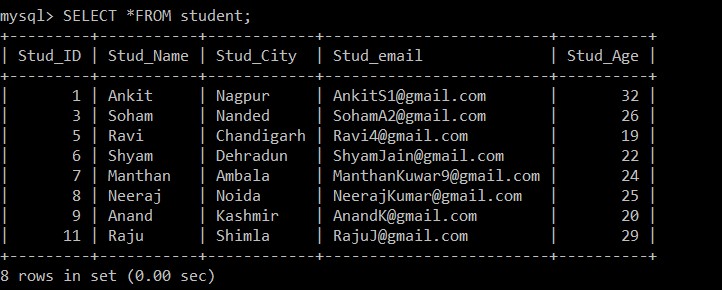
Nyní je v tabulce studentů pouze 8 záznamů, protože tři duplicitní záznamy jsou odstraněny z aktuálně vybrané tabulky. Podle následující podmínky:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Pokud jsou e-mailová ID libovolných dvou záznamů stejná, pak protože se mezi ID studenta používá znaménko menší než, bude zachován pouze záznam s větším ID zaměstnance a druhý duplicitní záznam bude mezi těmito dvěma záznamy odstraněn.
Příklad 2:
Napište dotaz na odstranění duplicitních řádků ze studentské tabulky pomocí příkazu delete join a zároveň ponechte duplicitní záznam s nižším ID zaměstnance a smažte ten druhý.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Použili jsme dotaz DELETE s INNER JOIN. Pro implementaci INNER JOIN na jedné tabulce jsme vytvořili dvě instance s1 a s2. Poté jsme pomocí klauzule WHERE zkontrolovali dvě podmínky, abychom zjistili duplicitní řádky ve studentské tabulce. Pokud je ID e-mailu ve dvou různých záznamech stejné a ID studenta se liší, bude se s ním nakládat jako s duplicitním záznamem podle podmínky klauzule WHERE.
Výstup:
Query OK, 3 rows affected (0.09 sec)Výsledky výše uvedeného dotazu ukazují, že v tabulce studentů jsou tři duplicitní záznamy.

K vyhledání duplicitních záznamů, které byly smazány, použijeme dotaz SELECT.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
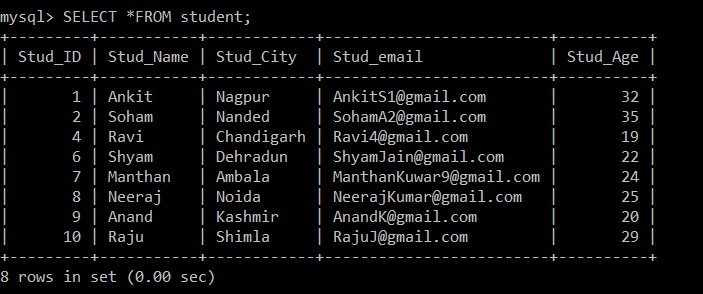
Nyní je v tabulce studentů pouze 8 záznamů, protože tři duplicitní záznamy jsou odstraněny z aktuálně vybrané tabulky. Podle následující podmínky:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Pokud jsou e-mailová ID libovolných dvou záznamů stejná, protože je mezi ID studenta použito znaménko větší než, bude zachován pouze záznam s nižším ID zaměstnance a druhý duplicitní záznam bude mezi těmito dvěma záznamy smazán.
- Použití přechodné tabulky k odstranění duplicitních řádků
Při odstraňování duplicitních řádků pomocí přechodné tabulky je třeba postupovat podle následujících kroků.
- Měla by být vytvořena nová tabulka, která bude stejná jako skutečná tabulka.
- Přidejte do nově vytvořené tabulky odlišné řádky ze skutečné tabulky.
- Zrušte aktuální tabulku a přejmenujte novou tabulku se stejným názvem jako skutečná tabulka.
Příklad:
Napište dotaz na odstranění duplicitních záznamů ze studentské tabulky pomocí přechodné tabulky.
Krok 1:
Nejprve vytvoříme přechodnou tabulku, která bude stejná jako tabulka zaměstnanců.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Zde je 'employee' původní tabulka a 'temp_student' je přechodná tabulka.
Krok 2:
Nyní načteme pouze jedinečné záznamy z tabulky studentů a všechny načtené záznamy vložíme do tabulky temp_student.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Zde před vložením odlišných záznamů z tabulky studentů do temp_student jsou všechny duplicitní záznamy filtrovány pomocí Stud_email. Poté se do temp_student vloží pouze záznamy s jedinečným e-mailovým ID.
Krok 3:
Poté odstraníme tabulku studentů a přejmenujeme tabulku temp_student na tabulku studentů.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
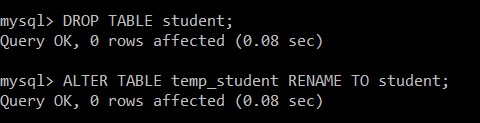
Tabulka studentů byla úspěšně odstraněna a temp_student je přejmenován na tabulku studentů, která obsahuje pouze jedinečné záznamy.
Potom musíme ověřit, že tabulka studentů nyní obsahuje pouze jedinečné záznamy. Abychom to ověřili, použili jsme dotaz SELECT, abychom viděli data obsažená v tabulce studentů.
mysql> SELECT *FROM student;Výstup:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
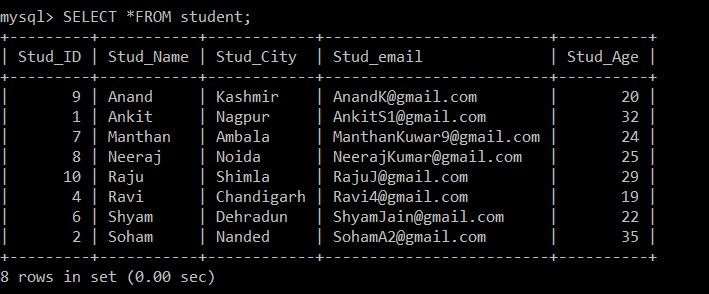
Nyní je v tabulce studentů pouze 8 záznamů, protože tři duplicitní záznamy jsou odstraněny z aktuálně vybrané tabulky. V kroku 2, při načítání odlišných záznamů z původní tabulky a jejich vkládání do přechodné tabulky, byla na Stud_email použita klauzule GROUP BY, takže všechny záznamy byly vloženy na základě e-mailových ID studentů. Zde je mezi duplicitními záznamy standardně zachován pouze záznam s nižším ID zaměstnance a druhý je smazán.