V tomto článku SQL se dozvíme o klauzuli GROUP BY a o tom, jak ji používat v SQL. Budeme také diskutovat o použití klauzule GROUP BY s klauzulí WHERE.
Co je klauzule GROUP BY?
Klauzule GROUP BY je klauzule SQL používaná v příkazu SELECT ke správě stejných záznamů sloupce ve skupině pomocí funkcí SQL.
Syntaxe klauzule GROUP BY:
SELECT columnname1, columnname2, columnname3 FROM tablename GROUP BY columnname;V klauzuli GROUP BY můžeme použít více sloupců z tabulky.
Existuje několik kroků, které se musíme naučit používat klauzuli GROUP BY v dotazu SQL:
1. Vytvořte novou databázi nebo použijte existující databázi výběrem databáze pomocí klíčového slova USE následovaného názvem databáze.
2. Vytvořte novou tabulku ve vybrané databázi nebo můžete použít již vytvořenou tabulku.
3. Pokud je tabulka nově vytvořena, vložte záznamy do nově vytvořené databáze pomocí dotazu INSERT a prohlédněte si vložená data pomocí dotazu SELECT bez klauzule GROUP BY.
4. Nyní jsme připraveni použít klauzuli GROUP BY v dotazech SQL.
Krok 1:Vytvořte novou databázi nebo použijte již vytvořenou databázi.
Již jsem vytvořil databázi. Použiji svůj existující vytvořený název databáze, Společnost.
USE Company;
Společnost je název databáze.
Ti, kteří si databázi nevytvořili, se při vytváření databáze řídí následujícím dotazem:
CREATE DATABASE database_name;
Po vytvoření databáze vyberte databázi pomocí klíčového slova USE následovaného názvem databáze.
Krok 2:Vytvořte novou tabulku nebo použijte již existující tabulku:
Již jsem vytvořil tabulku. Použiji existující tabulku s názvem Zaměstnanci.
Chcete-li vytvořit nové tabulky, postupujte podle syntaxe CREATE TABLE:
CREATE TABLE table_name(
columnname1 datatype(column size),
columnname2 datatype(column size),
columnname3 datatype(column size)
);
Krok 3:Vložte záznamy do nově vytvořené tabulky pomocí dotazu INSERT a zobrazte záznamy pomocí dotazu SELECT.
Pro vložení nových záznamů do tabulky použijte následující syntaxi:
INSERT INTO table_name VALUES(value1, value2, value3);
K zobrazení záznamů z tabulky použijte následující syntaxi:
SELECT * FROM table_name;
Následující dotaz zobrazí záznamy zaměstnanců:
SELECT * FROM Employees;
Výstup výše uvedeného dotazu SELECT je:
| ID ZAMĚSTNANCE | FIRST_NAME | LAST_NAME | PLAT | MĚSTO | ODDĚLENÍ | ID SPRÁVCE |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
| 1002 | VAIBHAV | SHARMA | 60 000 | NOIDA | C# | 5 |
| 1003 | NIKHIL | VANI | 50500 | JAIPUR | FMW | 2 |
| 2001 | PRACHI | SHARMA | 55500 | CHANDIgarH | ORACLE | 1 |
| 2002 | BHAVESH | JAIN | 65500 | PUNE | FMW | 2 |
| 2003 | RUCHIKA | JAIN | 50 000 | MUMBAI | C# | 5 |
| 3001 | PRANOTI | SHENDE | 55500 | PUNE | JAVA | 3 |
| 3002 | ANUJA | WANRE | 50500 | JAIPUR | FMW | 2 |
| 3003 | DEEPAM | JAUHARI | 58500 | MUMBAI | JAVA | 3 |
| 4001 | RAJESH | GOUD | 60500 | MUMBAI | TESTOVÁNÍ | 4 |
| 4002 | ASHWINI | BAGHAT | 54500 | NOIDA | JAVA | 3 |
| 4003 | RUCHIKA | AGARWAL | 60 000 | DELHI | ORACLE | 1 |
| 5001 | ARCHIT | SHARMA | 55500 | DELHI | TESTOVÁNÍ | 4 |
| 5002 | SANKET | CHAUHAN | 70 000 | HYDERABAD | JAVA | 3 |
| 5003 | ROSHAN | NEHTE | 48500 | CHANDIgarH | C# | 5 |
| 6001 | RAHUL | NIKAM | 54500 | BANGALOR | TESTOVÁNÍ | 4 |
| 6002 | ATISH | JADHAV | 60500 | BANGALOR | C# | 5 |
| 6003 | NIKITA | INGALE | 65 000 | HYDERABÁD | ORACLE | 1 |
Krok 4:Jsme připraveni použít v dotazech klauzuli GROUP BY
Nyní se hluboce ponoříme do klauzule GROUP BY pomocí příkladů
Příklad 1: Napište dotaz pro zobrazení skupiny záznamů zaměstnanců podle města.
SELECT * FROM EMPLOYEES GROUP BY CITY;
Výše uvedený dotaz zobrazí záznamy zaměstnanců, kde bude zaměstnanec ze stejného města považován za jednu skupinu. Pokud je například v tabulce 10 záznamů zaměstnanců, kde 3 jsou z města Pune, 3 z města Bombaj, 2 jsou z Hyderabad a Bangalore, pak výše uvedený dotaz seskupí zaměstnance města Pune zaměstnance města Bombaj jako jeden záznam atd. .
Výstup výše uvedeného dotazu:
| ID ZAMĚSTNANCE | FIRST_NAME | LAST_NAME | PLAT | MĚSTO | ODDĚLENÍ | ID SPRÁVCE |
| 6001 | RAHUL | NIKAM | 54500 | BANGALOR | TESTOVÁNÍ | 4 |
| 2001 | PRACHI | SHARMA | 55500 | CHANDIgarH | ORACLE | 1 |
| 4003 | RUCHIKA | AGARWAL | 60 000 | DELHI | ORACLE | 1 |
| 5002 | SANKET | CHAUHAN | 70 000 | HYDERABAD | JAVA | 3 |
| 1003 | NIKHIL | VANI | 50500 | JAIPUR | FMW | 2 |
| 2003 | RUCHIKA | JAIN | 50 000 | MUMBAI | C# | 5 |
| 1002 | VAIBHAV | SHARMA | 60 000 | NOIDA | C# | 5 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
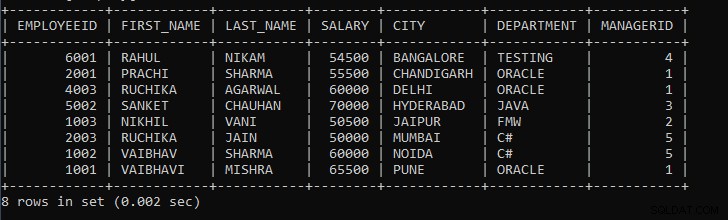
Jak vidíme, záznamy zaměstnanců jsou seskupeny podle města a záznamy se standardně zobrazují vzestupně.
Příklad 2: Napište dotaz pro zobrazení skupiny záznamů zaměstnanců podle mezd v sestupném pořadí.
SELECT * FROM EMPLOYEES GROUP BY SALARY DESC;
Výše uvedený dotaz zobrazí záznamy zaměstnanců, kde zaměstnanci se stejným platem budou považováni za jednu skupinu, a záznamy se zobrazí v sestupném pořadí.
Výstup výše uvedeného dotazu:
| ID ZAMĚSTNANCE | FIRST_NAME | LAST_NAME | PLAT | MĚSTO | ODDĚLENÍ | ID SPRÁVCE |
| 5002 | SANKET | CHAUHAN | 70 000 | HYDERABAD | JAVA | 3 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
| 6003 | NIKITA | INGALE | 65 000 | HYDERABAD | ORACLE | 1 |
| 4001 | RAJESH | GOUD | 60500 | MUMBAI | TESTOVÁNÍ | 4 |
| 1002 | VAIBHAV | SHARMA | 60 000 | NOIDA | C# | 5 |
| 3003 | DEEPAM | JAUHARI | 58500 | MUMBAI | JAVA | 3 |
| 2001 | PRACHI | SHARMA | 55500 | CHANDIgarH | ORACLE | 1 |
| 4002 | ASHWINI | BAGHAT | 54500 | NOIDA | JAVA | 3 |
| 1003 | NIKHIL | VANI | 50500 | JAIPUR | FMW | 2 |
| 2003 | RUCHIKA | JAIN | 50 000 | MUMBAI | C# | 5 |
| 5003 | ROSHAN | NEHTE | 48500 | CHANDIgarH | C# | 5 |
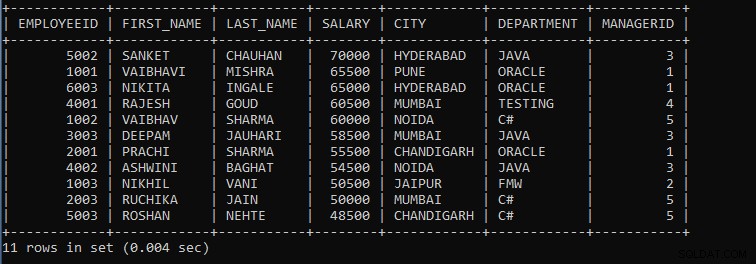
Jak vidíme, záznamy zaměstnanců jsou seskupeny podle mezd a záznamy se zobrazují v sestupném pořadí, jak zmiňujeme na konci popis.
Příklad 3: Napište dotaz pro zobrazení skupiny záznamů zaměstnanců podle platu a města.
SELECT * FROM EMPLOYEES GROUP BY SALARY, CITY;
Výše uvedený dotaz zobrazí záznamy zaměstnanců, kde zaměstnanci se stejným platem a městem budou považováni za jednu skupinu.
Předpokládejme například, že tabulka měla 10 záznamů zaměstnanců. Od 10 zaměstnanců se plat 2 zaměstnanců a město shoduje s dalšími dvěma zaměstnanci a zbytek platu šesti zaměstnanců a město se nevyrovná, pak bude 6 zaměstnanců považováno za 6 samostatných skupin a 2 zaměstnanci, kteří se shodují s dalšími 2 zaměstnanci, budou považováni za jednu skupinu . Stručně řečeno, vznikne 8 skupin.
Výstup výše uvedeného dotazu:
| ID ZAMĚSTNANCE | FIRST_NAME | LAST_NAME | PLAT | MĚSTO | ODDĚLENÍ | ID SPRÁVCE |
| 5003 | ROSHAN | NEHTE | 48500 | CHANDIgarH | C# | 5 |
| 2003 | RUCHIKA | JAIN | 50 000 | MUMBAI | C# | 5 |
| 1003 | NIKHIL | VANI | 50500 | JAIPUR | FMW | 2 |
| 6001 | RAHUL | NIKAM | 54500 | BANGALOR | TESTOVÁNÍ | 4 |
| 4002 | ASHWINI | BAGHAT | 54500 | NOIDA | JAVA | 3 |
| 2001 | PRACHI | SHARMA | 55500 | CHANDIgarH | ORACLE | 1 |
| 5001 | ARCHIT | SHARMA | 55500 | DELHI | TESTOVÁNÍ | 4 |
| 3001 | PRANOTI | SHENDE | 55500 | PUNE | JAVA | 3 |
| 3003 | DEEPAM | JAUHARI | 58500 | MUMBAI | JAVA | 3 |
| 4003 | RUCHIKA | AGARWAL | 60 000 | DELHI | ORACLE | 1 |
| 1002 | VAIBHAV | SHARMA | 60 000 | NOIDA | C# | 5 |
| 6002 | ATISH | JADHAV | 60500 | BANGALOR | C# | 5 |
| 4001 | RAJESH | GOUD | 60500 | MUMBAI | TESTOVÁNÍ | 4 |
| 6003 | NIKITA | INGALE | 65 000 | HYDERABÁD | ORACLE | 1 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
| 5002 | SANKET | CHAUHAN | 70 000 | HYDERABAD | JAVA | 3 |
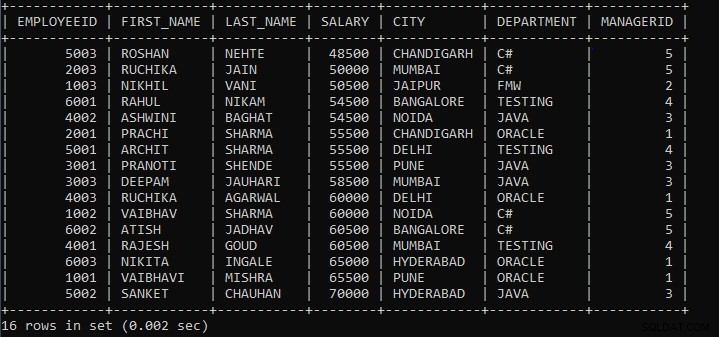
Jak vidíme, záznamy zaměstnanců jsou seskupeny podle platu a města a záznamy se standardně zobrazují vzestupně.
Příklad 4: Napište dotaz pro zobrazení záznamů zaměstnanců podle města a oddělení.
SELECT * FROM EMPLOYEES GROUP BY CITY, DEPARTMENT;
Výše uvedený dotaz zobrazí záznamy zaměstnanců, kde jsou zaměstnanci ve stejném městě, a oddělení bude považováno za jednu skupinu.
Výstup výše uvedeného dotazu:
| ID ZAMĚSTNANCE | FIRST_NAME | LAST_NAME | PLAT | MĚSTO | ODDĚLENÍ | ID SPRÁVCE |
| 6002 | ATISH | JADHAV | 60500 | BANGALOR | C# | 5 |
| 6001 | RAHUL | NIKAM | 54500 | BANGALOR | TESTOVÁNÍ | 4 |
| 5003 | ROSHAN | NEHTE | 48500 | CHANDIgarH | C# | 5 |
| 2001 | PRACHI | SHARMA | 55500 | CHANDIgarH | ORACLE | 1 |
| 4003 | RUCHIKA | AGARWAL | 60 000 | DELHI | ORACLE | 1 |
| 5001 | ARCHIT | SHARMA | 55500 | DELHI | TESTOVÁNÍ | 4 |
| 5002 | SANKET | CHAUHAN | 70 000 | HYDERABAD | JAVA | 3 |
| 6003 | NIKITA | INGALE | 65 000 | HYDERABAD | ORACLE | 1 |
| 1003 | NIKHIL | VANI | 50500 | JAIPUR | FMW | 2 |
| 2003 | RUCHIKA | JAIN | 50 000 | MUMBAI | C# | 5 |
| 3003 | DEEPAM | JAUHARI | 58500 | MUMBAI | JAVA | 3 |
| 4001 | RAJESH | GOUD | 60500 | MUMBAI | TESTOVÁNÍ | 4 |
| 1002 | VAIBHAV | SHARMA | 60 000 | NOIDA | C# | 5 |
| 4002 | ASHWINI | BAGHAT | 54500 | NOIDA | JAVA | 3 |
| 2002 | BHAVESH | JAIN | 65500 | PUNE | FMW | 2 |
| 3001 | PRANOTI | SHENDE | 55500 | PUNE | JAVA | 3 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
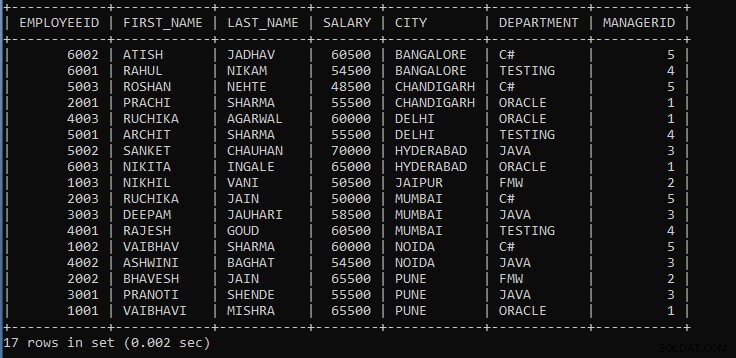
Jak vidíme, záznamy zaměstnanců jsou seskupeny podle města a oddělení a záznamy se standardně zobrazují vzestupně.
Příklad 5: Napište dotaz, abyste spočítali seznam zaměstnanců v každém oddělení z tabulky zaměstnanců.
SELECT DEPARTMENT, COUNT(DEPARTMENT) FROM EMPLOYEES GROUP BY DEPARTMENT;Výše uvedený dotaz zobrazuje počet zaměstnanců v každé skupině oddělení podle oddělení. Stejně jako šest zaměstnanců pracuje v HR oddělení, pět pracuje v jiném oddělení.
Výstup výše uvedeného dotazu:
| ODDĚLENÍ | POČET (ODDĚLENÍ) |
| C# | 4 |
| FMW | 3 |
| JAVA | 4 |
| ORACLE | 4 |
| TESTOVÁNÍ | 3 |
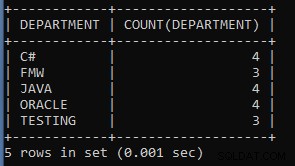
Jak vidíme, čtyři zaměstnanci pracují v oddělení C#, tři pracují v oddělení FMW atd.
Příklad 6: Napište dotaz, abyste spočítali seznam zaměstnanců z každého města z tabulky zaměstnanců.
SELECT CITY, COUNT(CITY) FROM EMPLOYEES GROUP BY CITY;
Výše uvedený dotaz zobrazuje počet zaměstnanců v každé skupině měst podle města. Stejně jako tři zaměstnanci pracují z města Pune, čtyři pracují z jiného města a tak dále.
Výstup výše uvedeného dotazu:
| MĚSTO | POČET(MĚSTO) |
| BANGALOR | 2 |
| CHANDIGARH | 2 |
| DELHI | 2 |
| HYDERABÁD | 2 |
| JAIPUR | 2 |
| MUMBAI | 3 |
| NOIDA | 2 |
| PUNE | 3 |
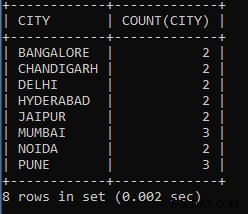
Jak vidíme, dva zaměstnanci pracují z města Bangalore, tři pracují z města Bombaj a tak dále.
Příklad 7: Napište dotaz pro sečtení mzdové skupiny zaměstnanců podle města.
SELECT CITY, SUM(SALARY) AS SALARY FROM EMPLOYEES GROUP BY CITY;Výše uvedené se používá k součtu platů zaměstnanců seskupených podle názvu města. Například pro zaměstnance ze stejného města bude jejich plat součtem a považován za jednu skupinu. Pro přidání platu jsme použili funkci agregovaného součtu následovanou sloupcem plat.
Výstup výše uvedeného dotazu:
| MĚSTO | PLAT |
| BANGALOR | 115 000 |
| CHANDIGARH | 104 000 |
| DELHI | 115500 |
| HYDERABÁD | 135 000 |
| JAIPUR | 101 000 |
| MUMBAI | 169 000 |
| NOIDA | 114500 |
| PUNE | 186500 |
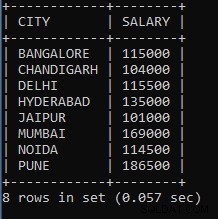
Jak vidíme, celkový plat ve městě Bangalore je 115 000, celkový plat ve městě Chandigarh je 104 000, což je součet různých platů zaměstnanců, ale z města se pro každé město používá stejný přístup.
Příklad 8: Napište dotaz a zjistěte minimální mzdu z každého oddělení.
SELECT DEPARTMENT, MIN(SALARY) FROM EMPLOYEES GROUP BY DEPARTMENT;Výše uvedený dotaz slouží k nalezení minimální mzdy zaměstnance z každého oddělení. Jeden ze zaměstnanců z oddělení Java má plat 54500, což je nejnižší z celého oddělení Java. Stejných 48 500 je nejnižší mzda vyplacená zaměstnanci v oddělení C#.
Výstup výše uvedeného dotazu:
| ODDĚLENÍ | MIN (PLAT) |
| C# | 48500 |
| FMW | 50500 |
| JAVA | 54500 |
| ORACLE | 55500 |
| TESTOVÁNÍ | 54500 |
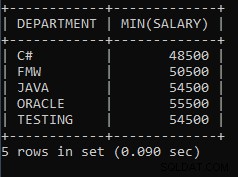
Jak vidíme, 50500 je nejnižší plat vyplácený jednomu ze zaměstnanců v oddělení FMW, 55500 je nejnižší plat vyplácený jednomu ze zaměstnanců v oddělení ORACLE.
Příklad 9: Napište dotaz a zjistěte minimální mzdu z každého města.
SELECT CITY, MAX(SALARY) FROM EMPLOYEES GROUP BY CITY;Výše uvedený dotaz slouží k nalezení maximální mzdy z každého města. Plat jednoho ze zaměstnanců z města Pune je 65 500, což je nejvyšší plat v celém městě Pune, stejných 60 500 je nejvyšší plat vyplácený zaměstnanci ve městě Bombaj.
Výstup výše uvedeného dotazu:
| MĚSTO | MAXIMÁLNÍ (PLAT) |
| BANGALOR | 60500 |
| CHANDIGARH | 55500 |
| DELHI | 60 000 |
| HYDERABÁD | 70 000 |
| JAIPUR | 50500 |
| MUMBAI | 60500 |
| NOIDA | 60 000 |
| PUNE | 65500 |
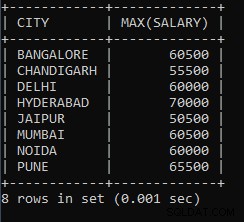
Jak vidíme, 50500 je nejvyšší plat vyplácený jednomu ze zaměstnanců ve městě Džajpur, 55500 je nejvyšší plat vyplácený jednomu ze zaměstnanců ve městě Čandígarh.