V první části této série blogů jsem představil několik výsledků benchmarků, které ukazují, jak se změnil výkon PostgreSQL OLTP od verze 8.3, vydané v roce 2008. V této části plánuji udělat totéž, ale pro analytické / BI dotazy, zpracování velkých množství dat.
Existuje řada oborových benchmarků pro testování této zátěže, ale pravděpodobně nejběžněji používaným je TPC-H, takže to použiji pro tento blogový příspěvek. K dispozici je také TPC-DS, další benchmark TPC pro testování systémů pro podporu rozhodování, který lze považovat za evoluci nebo náhradu TPC-H. Rozhodl jsem se zůstat u TPC-H z několika důvodů.
Za prvé, TPC-DS je mnohem složitější, a to jak z hlediska schématu (více tabulek), tak počtu dotazů (22 vs. 99). Správné vyladění, zejména při práci s více verzemi PostgreSQL, by bylo mnohem těžší. Za druhé, některé dotazy TPC-DS používají funkce, které nejsou podporovány staršími verzemi PostgreSQL (např. seskupovací sady), takže tyto dotazy jsou pro některé verze irelevantní. A nakonec bych řekl, že lidé znají TPC-H mnohem lépe než TPC-DS.
Cílem není umožnit srovnání s jinými databázovými produkty, pouze poskytnout přiměřenou dlouhodobou charakteristiku toho, jak se výkon PostgreSQL vyvíjel od PostgreSQL 8.3.
Poznámka :Pro velmi zajímavou analýzu benchmarku TPC-H důrazně doporučuji dokument „TPC-H Analyzed:Hidden Messages and Lessons Learned from a Influencential Benchmark“ od Boncze, Neumanna a Erlinga.
Hardware
Většina výsledků v tomto příspěvku na blogu pochází z „větší krabice“, kterou mám v naší kanceláři a která má tyto parametry:
- 2x E5-2620 v4 (16 jader, 32 vláken)
- 64 GB RAM
- Intel Optane 900P 280GB NVMe SSD (data)
- 3 x 7,2 k SATA RAID0 (dočasný tabulkový prostor)
- jádro 5.6.15, souborový systém ext4
Jsem si jistý, že si můžete koupit výrazně výkonnější stroje, ale věřím, že je to dost dobré na to, abychom získali relevantní data. Existovaly dvě varianty konfigurace – jedna s vypnutým paralelismem a jedna s povoleným paralelismem. Většina hodnot parametrů je v obou případech stejná, vyladěná podle dostupných hardwarových zdrojů (CPU, RAM, úložiště). Podrobnější informace o konfiguraci naleznete na konci tohoto příspěvku.
Srovnávací
Chci velmi jasně říci, že není mým cílem implementovat platný benchmark TPC-H, který by mohl splnit všechna kritéria požadovaná TPC. Mým cílem je vyhodnotit, jak se výkon různých analytických dotazů měnil v průběhu času, a ne honit nějaké abstraktní měřítko výkonu na dolar nebo něco podobného.
Rozhodl jsem se tedy použít pouze podmnožinu TPC-H – v podstatě stačí načíst data a spustit 22 dotazů (stejné parametry ve všech verzích). Nedochází k žádné obnově dat, datová sada je po počátečním načtení statická. Vybral jsem několik měřítek, 1, 10 a 75, abychom měli výsledky pro fits-in-shared-buffers (1), fits-in-memory (10) a více než-paměť (75) . Šel bych za 100, aby to byla „hezká sekvence“, která by se v některých případech nevešla do 280GB úložiště (díky indexům, dočasným souborům atd.). Všimněte si, že měřítko 75 ani TPC-H neuznává jako platný měřítkový faktor.
Ale má vůbec smysl porovnávat 1GB nebo 10GB datové sady? Lidé mají tendenci se zaměřovat na mnohem větší databáze, takže se může zdát trochu pošetilé obtěžovat se jejich testováním. Ale nemyslím si, že by to bylo užitečné – drtivá většina databází ve volné přírodě je podle mých zkušeností poměrně malá. A i když je celá databáze velká, lidé obvykle pracují jen s její malou podmnožinou – nejnovějšími daty, nevyřešené objednávky atd. Věřím tedy, že má smysl testovat i s těmito malými soubory dat.
Načtení dat
Nejprve se podívejme, jak dlouho trvá načtení dat do databáze – bez paralelismu a s ním. Ukážu pouze výsledky ze 75GB datové sady, protože celkové chování je u menších případů téměř stejné.
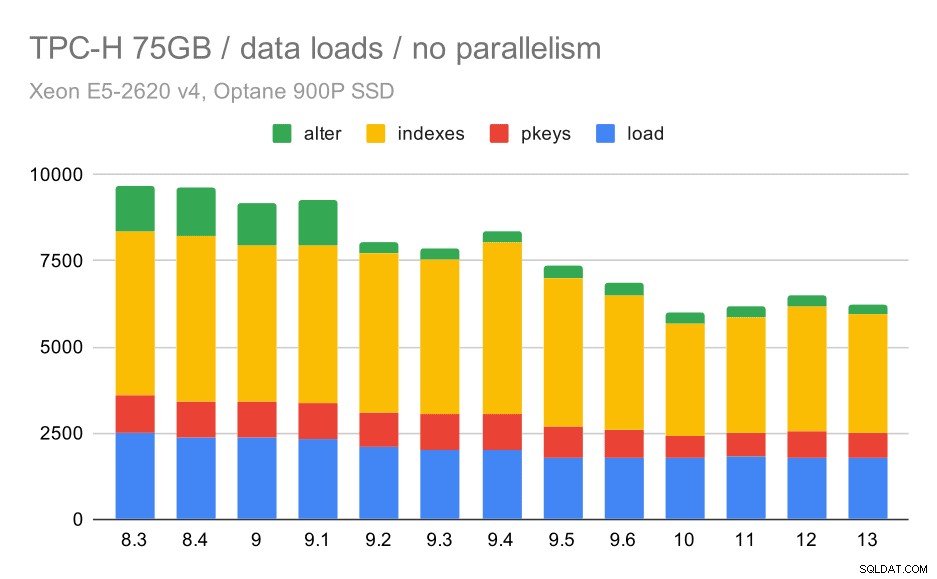
Doba načítání dat TPC-H – škálovatelnost 75 GB, žádný paralelismus
Jasně můžete vidět, že existuje stálý trend zlepšování, zkracování asi 30 % doby pouze zlepšením efektivity ve všech čtyřech krocích – KOPÍROVÁNÍ, vytváření primárních klíčů a indexů a (zejména) nastavení cizích klíčů. Zlepšení „alter“ ve verzi 9.2 je obzvláště jasné.
| KOPÍROVAT | PKEYS | INDEXY | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Nyní se podívejme, jak povolení paralelismu změní chování. Následující graf porovnává výsledky s povoleným paralelismem – označeným „(p)“ – s výsledky s vypnutým paralelismem.
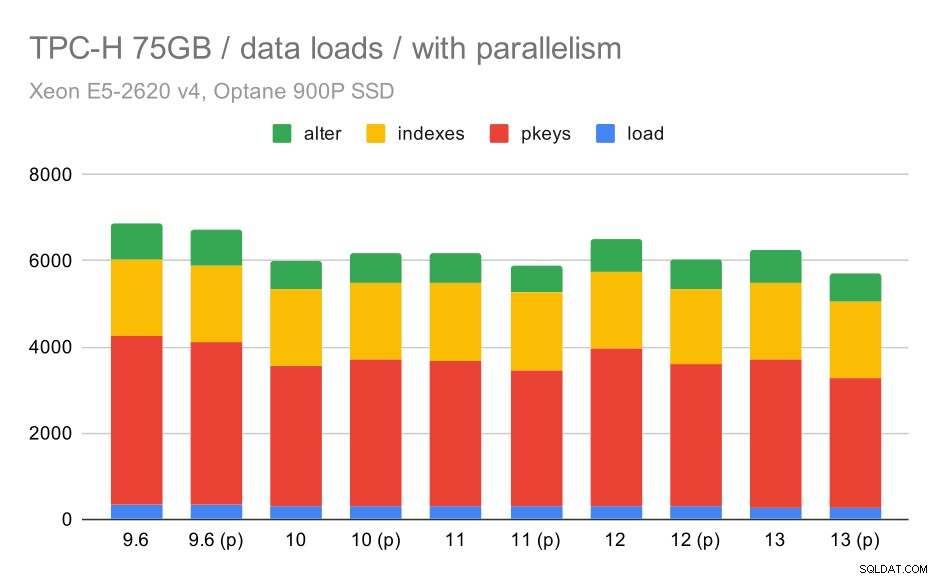
Trvání načtení dat TPC-H – měřítko 75 GB, paralelismus povolen.
Bohužel se zdá, že účinek paralelismu je v tomto testu velmi omezený – trochu to pomáhá, ale rozdíly jsou poměrně malé. Celkové zlepšení tedy zůstává asi 30 %.
| KOPÍROVAT | PKEYS | INDEXY | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Dotazy
Nyní se můžeme podívat na dotazy. TPC-H má 22 šablon dotazů – vygeneroval jsem jednu sadu skutečných dotazů a spustil jsem je na všech verzích dvakrát – nejprve po odstranění všech mezipamětí a restartování instance, poté pomocí zahřáté mezipaměti. Všechna čísla uvedená v grafech jsou nejlepší z těchto dvou běhů (ve většině případů je to samozřejmě ten druhý).
Žádný paralelismus
Bez paralelismu jsou výsledky na nejmenší sadě dat docela jasné – každý pruh je rozdělen na více částí s různými barvami pro každý z 22 dotazů. Těžko říct, která část se přesně mapuje ke kterému dotazu, ale pro identifikaci případů, kdy se jeden dotaz mezi dvěma běhy zlepší nebo výrazně zhorší, to stačí. Například v prvním grafu je velmi jasné, že Q21 bylo mnohem rychlejší mezi 8,3 a 8,4.
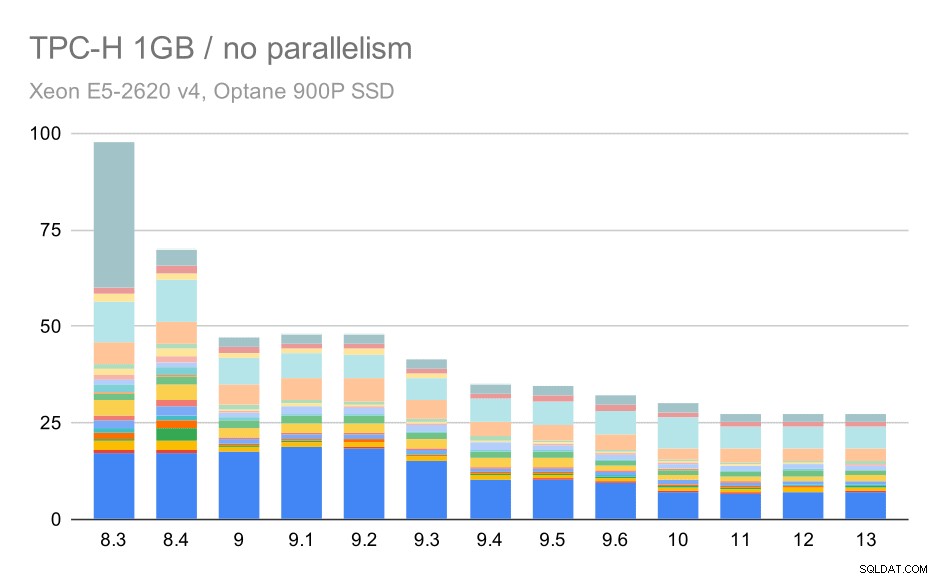
Dotazy TPC-H na malý soubor dat (1 GB) – paralelismus zakázán
U 10GB měřítka jsou výsledky poněkud obtížně interpretovatelné, protože na 8.3 trvá provedení jednoho z dotazů (Q21) tolik času, že převyšuje vše ostatní.
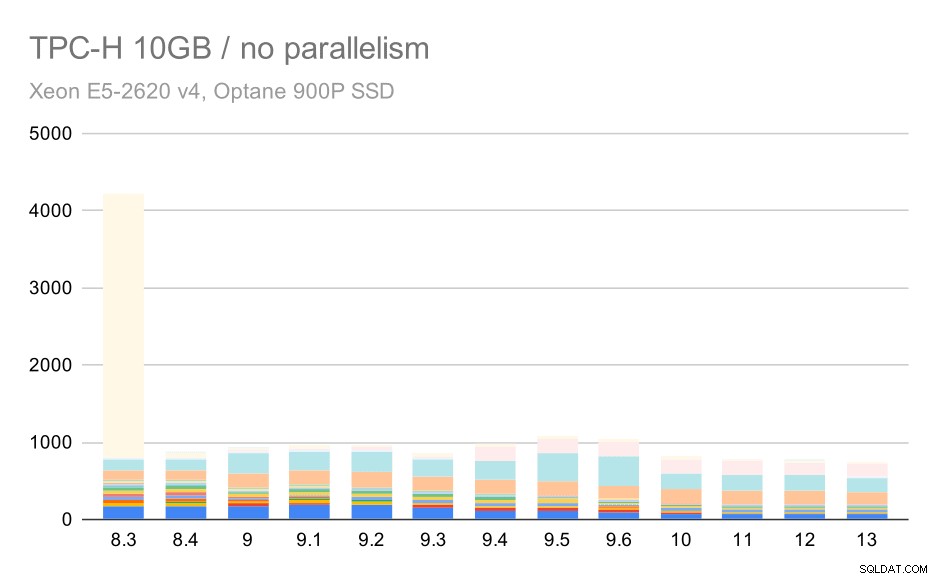
Dotazy TPC-H na střední datovou sadu (10 GB) – paralelismus zakázán
Pojďme se tedy podívat, jak by graf vypadal bez Q21:
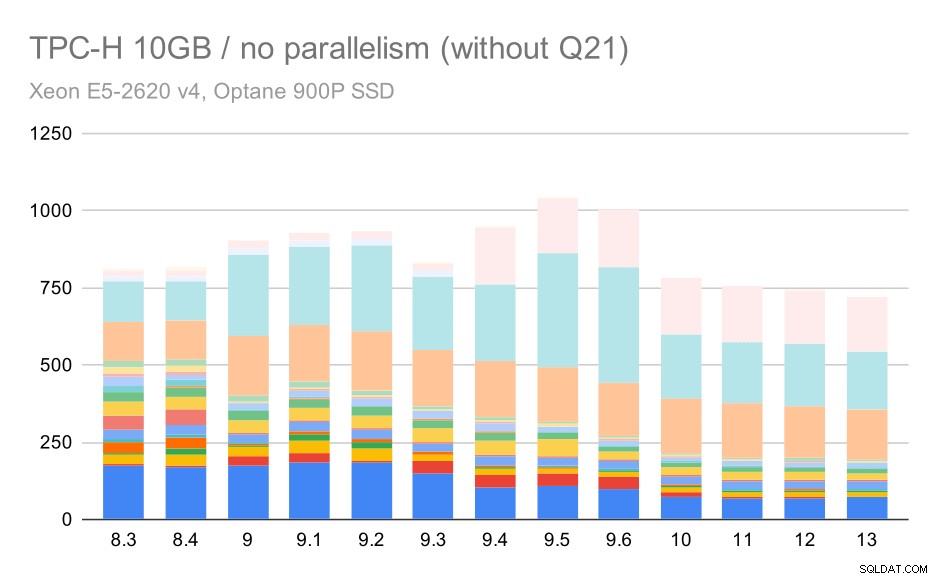
Dotazy TPC-H na střední datovou sadu (10 GB) – paralelismus zakázán, bez problémů Q2
Dobře, to se čte lépe. Jasně vidíme, že většina dotazů (až do Q17) se zrychlila, ale pak se dva z dotazů (Q18 a Q20) poněkud zpomalily. Podobný problém uvidíme u největšího souboru dat, takže poté proberu, co by mohlo být hlavní příčinou.
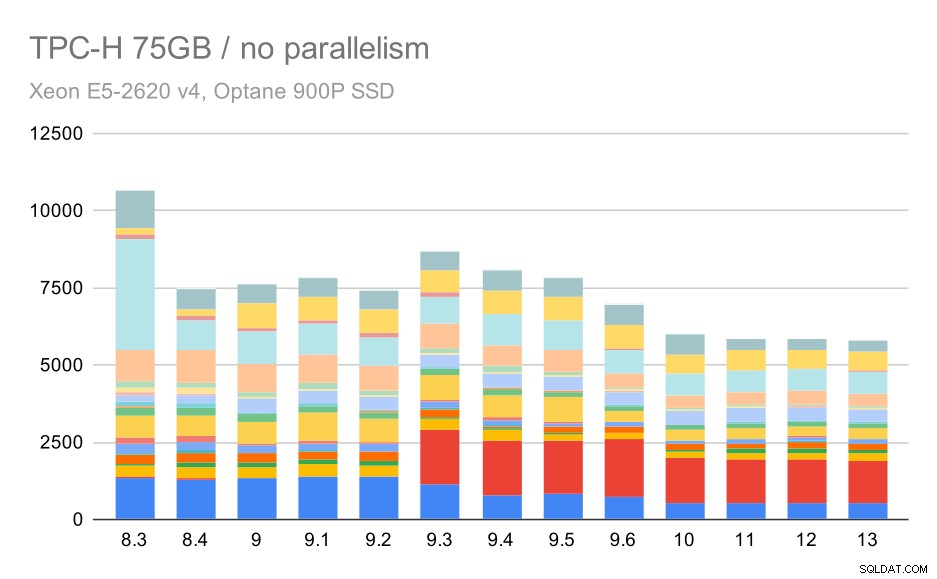
Dotazy TPC-H na velký soubor dat (75 GB) – paralelismus zakázán
Opět vidíme náhlý nárůst u jednoho z dotazů v 9.3 – tentokrát je to Q2, bez kterého graf vypadá takto:
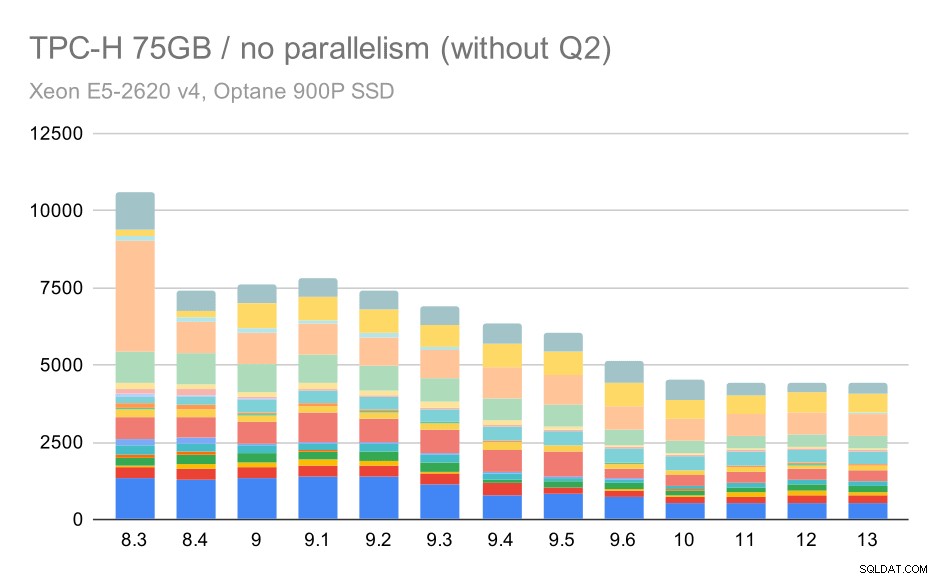
Dotazy TPC-H na velký soubor dat (75 GB) – paralelismus zakázán, bez problémů Q2
To je obecně docela pěkné zlepšení, zrychlení celého provádění z ~2,7 hodiny na pouhých ~1,2h, pouze tím, že je plánovač a optimalizátor chytřejší a exekutor je efektivnější (nezapomeňte, že paralelismus byl v těchto běhech deaktivován) .
V čem by tedy mohl být problém s Q2, kvůli kterému je v 9.3 pomalejší? Jednoduchá odpověď je, že pokaždé, když uděláte plánovač a optimalizátor chytřejší – ať už tím, že vytvoříte nové typy cest/plánů, nebo tím, že bude závislý na nějaké statistice, znamená to také, že se mohou udělat nové chyby, když jsou statistiky nebo odhady špatné. Ve 2. čtvrtletí odkazuje klauzule WHERE na souhrnný dílčí dotaz – zjednodušená verze dotazu může vypadat takto:
Vyberte 1 z částí, ps_supplycost =(vyberte Min (PS_SUPPLYCOST) z partyUpp, dodavatel, Nation, Region, kde p_partkey =p_partkey a s_suppkey =ps_suppkey a s_nationkey =n_nationkey a n_regionkey =r_regionkey a r_name ='america');pre> pre> pre> pre> pre> pre> pre> pre> pre> pre> pre> pre> preProblém je v tom, že neznáme průměrnou hodnotu v době plánování, takže není možné vypočítat dostatečně dobré odhady pro podmínku WHERE. Skutečné Q2 obsahuje další spojení a jejich plánování zásadně závisí na dobrých odhadech spojených vztahů. Ve starších verzích se zdá, že optimalizátor dělal správnou věc, ale ve verzi 9.3 jsme to nějakým způsobem udělali chytřejší, ale se špatným odhadem neučiní správné rozhodnutí. Jinými slovy, dobré plány ve starších verzích byly jen štěstím díky omezením plánovače.
Vsadil bych se, že regrese Q18 a Q20 na menším souboru dat jsou také způsobeny něčím podobným, i když jsem je podrobně nezkoumal.
Věřím, že některé z těchto problémů s optimalizátorem lze vyřešit vyladěním parametrů nákladů (např. random_page_cost atd.), ale nezkoušel jsem to kvůli časovým omezením. Ukazuje však, že upgrady automaticky nezlepší všechny dotazy – někdy může upgrade spustit regresi, takže vhodné testování vaší aplikace je dobrý nápad.
Paralelismus
Pojďme se tedy podívat, jak moc paralelismus dotazů změní výsledky. Opět se podíváme pouze na výsledky z verzí od verze 9.6 a označíme výsledky „(p)“, kde je povolen paralelní dotaz.
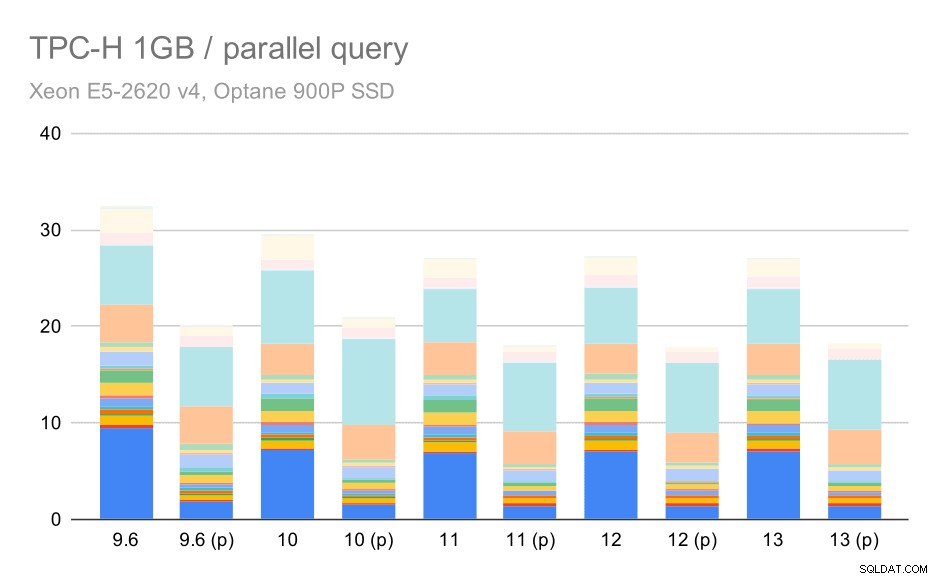
Dotazy TPC-H na malý soubor dat (1 GB) – povolen paralelismus
Je zřejmé, že paralelismus docela pomáhá – i na tomto malém souboru dat ušetří asi 30 %. Na středním datovém souboru není velký rozdíl mezi běžnými a paralelními běhy:
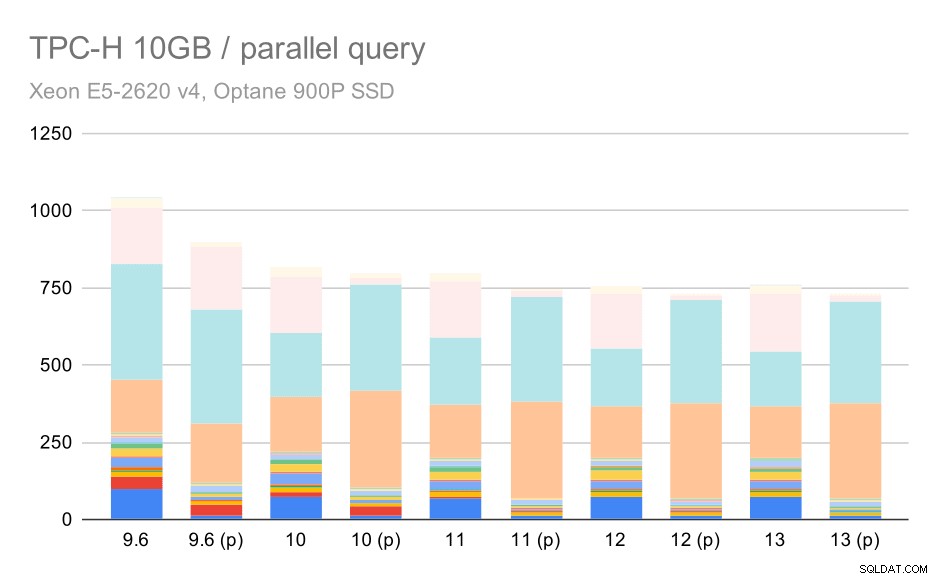
Dotazy TPC-H na střední datovou sadu (10 GB) – povolen paralelismus
Toto je další ukázka již diskutovaného problému – povolení paralelismu umožňuje zvažovat další plány dotazů a odhady nebo kalkulace zjevně neodpovídají skutečnosti, což vede ke špatným volbám plánu.
A nakonec velký soubor dat, kde kompletní výsledky vypadají takto:
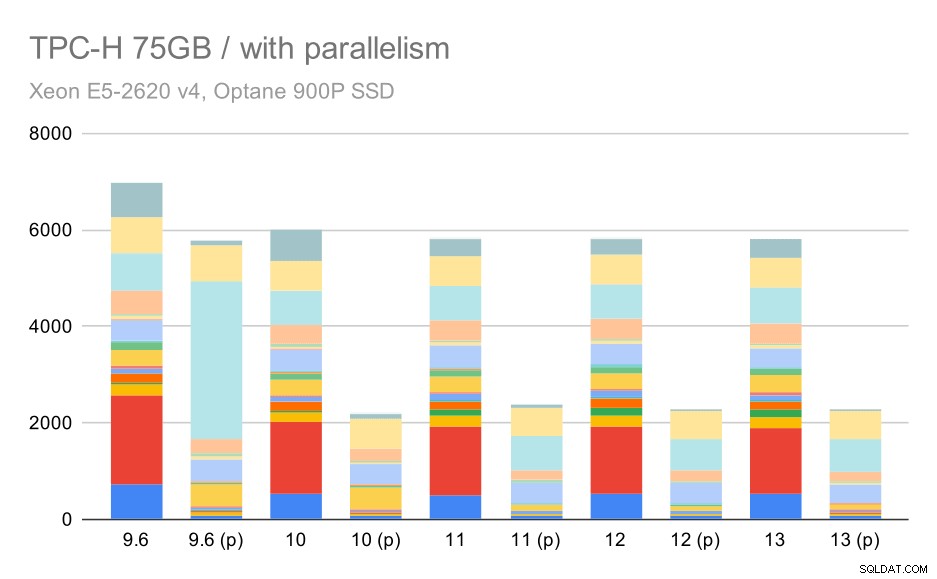
Dotazy TPC-H na velký soubor dat (75 GB) – povolen paralelismus
Zde je povolení paralelismu naší výhodou – optimalizátor dokáže sestavit levnější paralelní plán pro 2. čtvrtletí, čímž potlačí špatnou volbu plánu představenou v 9.3. Ale jen pro úplnost, zde jsou výsledky bez Q2.
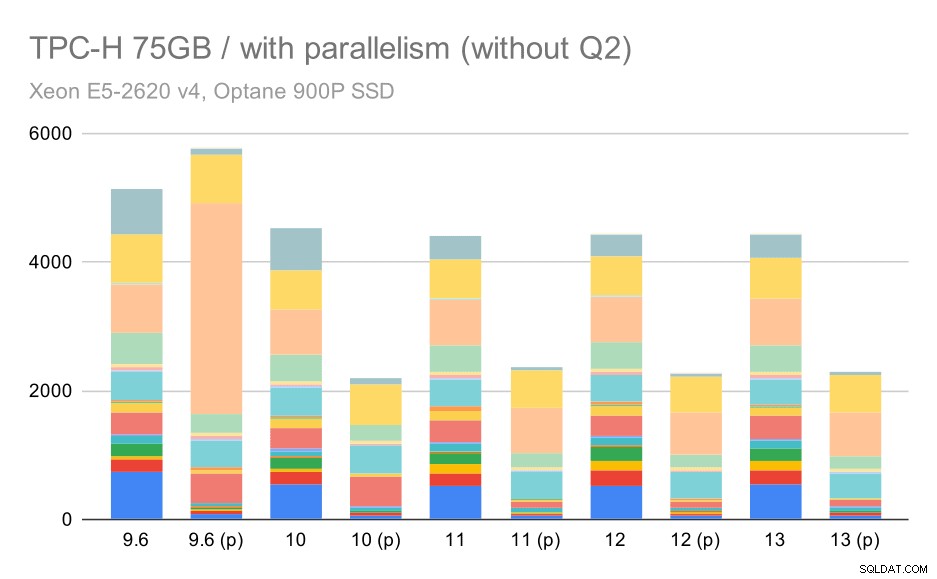
Dotazy TPC-H na velký soubor dat (75 GB) – povolen paralelismus, bez problémů Q2
I zde můžete zaznamenat některé špatné možnosti paralelního plánu – například paralelní plán pro Q9 je horší až do 11, kde se zrychluje – pravděpodobně díky 11 podporujícím další paralelní spouštěcí uzly. Na druhou stranu některé paralelní dotazy (Q18, Q20) jsou na 11 pomalejší, takže to nejsou jen duhy a jednorožci.
Shrnutí a budoucnost
Myslím, že tyto výsledky pěkně demonstrují implementaci optimalizací od PostgreSQL 8.3. Testy s deaktivovaným paralelismem ilustrují zlepšení efektivity (tj. dělat více se stejným množstvím zdrojů) – načítání dat se zrychlilo o ~30 % a dotazy ~2x rychleji. Je pravda, že jsem narazil na nějaké problémy s neefektivními plány dotazů, ale to je vlastní riziko, když je plánovač dotazů chytřejší. Neustále pracujeme na tom, aby byly výsledky spolehlivější, a jsem si jistý, že většinu těchto problémů bych mohl zmírnit trochu vyladěním konfigurace.
Výsledky s povoleným paralelismem ukazují, že můžeme efektivně využívat další zdroje (zejména jádra CPU). Zdá se, že zatížení dat z toho příliš netěží – alespoň ne v tomto benchmarku, ale dopad na provádění dotazu je významný, což má za následek ~2x zrychlení (ačkoli různé dotazy jsou samozřejmě ovlivněny odlišně).
V budoucích verzích PostgreSQL je mnoho příležitostí, jak to zlepšit. Například existuje řada patchů implementující paralelismus pro COPY, který urychluje načítání dat. Existují různé záplaty, které zlepšují provádění analytických dotazů – od malých lokalizovaných optimalizací po velké projekty, jako je sloupcové ukládání a provádění, agregované posunutí dolů atd. Hodně lze získat také použitím deklarativního dělení – funkci, kterou jsem při práci na této věci většinou ignoroval. benchmark, jednoduše proto, že by to příliš zvýšilo rozsah. A jsem si jistý, že existuje mnoho dalších příležitostí, které si ani neumím představit, ale chytřejší lidé z komunity PostgreSQL už na nich pracují.
Příloha:Konfigurace PostgreSQL
Paralelismus zakázán
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =0max_parallel_maintenance_workers =0# optimizerdefault_statistics_target =1000random_page_cost =60effective_cache_size =32 GB
Paralelismus povolen
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =16max_parallel_maintenance_workers =16max_worker_processes =32max_parallel_workers =32# optimizerdefault_statistics_target =1000random_page_cost =60effective_cache_size =32GB