Před pár lety (na pgconf.eu 2014 v Madridu) jsem prezentoval přednášku nazvanou „Archeologie výkonu“, která ukázala, jak se výkon změnil v posledních vydáních PostgreSQL. Pronesl jsem tuto přednášku, protože si myslím, že dlouhodobý pohled je zajímavý a může nám poskytnout poznatky, které mohou být velmi cenné. Pro lidi, kteří skutečně pracují na kódu PostgreSQL jako já, je to užitečný průvodce pro budoucí vývoj a uživatelům PostgreSQL může pomoci s vyhodnocením upgradů.
Rozhodl jsem se tedy toto cvičení zopakovat a napsat pár blogových příspěvků analyzujících výkon pro řadu verzí PostgreSQL. V přednášce v roce 2014 jsem začal s PostgreSQL 7.4, který byl v té době asi 10 let starý (vydán v roce 2003). Tentokrát začnu s PostgreSQL 8.3, který je asi 12 let starý.
Proč nezačít znovu s PostgreSQL 7.4? Existují asi tři hlavní důvody, proč jsem se rozhodl začít s PostgreSQL 8.3. Za prvé, všeobecná lenost. Čím starší verze, tím obtížnější může být sestavení pomocí aktuálních verzí kompilátoru atd. Za druhé, spuštění správných benchmarků, zvláště s větším objemem dat, nějakou dobu trvá, takže přidání jedné hlavní verze může snadno přidat několik dní strojového času. Prostě se nezdálo, že by to stálo za to. A konečně verze 8.3 přinesla řadu důležitých změn – vylepšení autovakuování (ve výchozím nastavení povoleno, souběžné pracovní procesy, …), fulltextové vyhledávání integrované do jádra, rozšířené kontrolní body a tak dále. Takže si myslím, že má smysl začít s PostgreSQL 8.3. Který byl vydán asi před 12 lety, takže toto srovnání bude ve skutečnosti pokrývat delší časové období.
Rozhodl jsem se porovnat tři základní typy zátěže – OLTP, analytiku a fulltextové vyhledávání. Myslím, že OLTP a analytika jsou docela zřejmé volby, protože většina aplikací je kombinací těchto dvou základních typů. Fulltextové vyhledávání mi umožňuje demonstrovat vylepšení ve speciálních typech indexů, které se také používají k indexování oblíbených datových typů jako JSONB, typů používaných PostGIS atd.
Proč to vůbec děláte?
Stojí to vlastně za námahu? Koneckonců, děláme benchmarky během vývoje neustále, abychom ukázali, že patch pomáhá a/nebo že nezpůsobuje regrese, že? Problém je v tom, že se obvykle jedná pouze o „dílčí“ benchmarky, porovnávající dvě konkrétní odevzdání a obvykle s poměrně omezeným výběrem pracovních zátěží, o kterých si myslíme, že mohou být relevantní. Což dává dokonalý smysl – prostě nemůžete spustit plnou baterii zátěže pro každý odevzdání.
Jednou za čas (obvykle krátce po vydání nové hlavní verze PostgreSQL) lidé spouštějí testy porovnávající novou verzi s předchozí, což je hezké a doporučuji vám spouštět takové benchmarky (ať už je to nějaký standardní benchmark, nebo něco specifického pro vaši aplikaci). Je však těžké tyto výsledky zkombinovat do dlouhodobějšího pohledu, protože tyto testy používají různé konfigurace a hardware (obvykle novější pro novější verzi) a tak dále. Je tedy těžké činit jasné soudy o změnách obecně.
Totéž platí pro výkon aplikací, který je samozřejmě „ultimátním měřítkem“. Lidé však nemusí upgradovat na každou hlavní verzi (někdy mohou několik verzí přeskočit, např. z 9.5 na 12). A když upgradují, je to často kombinováno s upgrady hardwaru atd. Nemluvě o tom, že aplikace se postupem času vyvíjejí (nové funkce, další složitost), rostou objemy dat a počet souběžných uživatelů atd.
To je to, co se tato série blogů snaží ukázat – dlouhodobé trendy ve výkonu PostgreSQL pro některé základní pracovní zátěže, abychom my – vývojáři – získali vřelý a nejasný pocit z dobré práce za ta léta. A ukázat uživatelům, že i když je PostgreSQL v tuto chvíli vyspělým produktem, stále existují významná vylepšení v každé nové hlavní verzi.
Není mým cílem používat tyto benchmarky pro porovnávání s jinými databázovými produkty nebo vytvářet výsledky, které by splnily jakékoli oficiální hodnocení (jako je TPC-H). Mým cílem je jednoduše se vzdělávat jako vývojář PostgreSQL, možná identifikovat a prozkoumat některé problémy a sdílet zjištění s ostatními.
Spravedlivé srovnání?
Nemyslím si, že takové srovnání verzí vydaných za 12 let nemůže být úplně fér, protože jakýkoli software je vyvíjen v konkrétním kontextu – hardware je dobrým příkladem pro databázový systém. Když se podíváte na stroje, které jste používali před 12 lety, kolik měly jader a kolik RAM? Jaký typ úložiště použili?
Typický server střední třídy měl v roce 2008 možná 8–12 jader, 16 GB RAM a RAID s několika disky SAS. Typický server střední třídy dnes může mít několik desítek jader, stovky GB RAM a úložiště SSD.
Vývoj softwaru je organizován podle priority – vždy existuje více potenciálních úkolů, než na které máte čas, takže musíte vybrat úkoly s nejlepším poměrem nákladů a přínosů pro vaše uživatele (zejména ty, kteří financují projekt, přímo nebo nepřímo). A v roce 2008 některé optimalizace pravděpodobně ještě nebyly relevantní – většina strojů neměla extrémní množství paměti RAM, takže optimalizace pro velké sdílené vyrovnávací paměti se například ještě nevyplatila. A mnoho překážek CPU bylo zastíněno I/O, protože většina počítačů měla úložiště typu „spinning rust“.
Poznámka:Samozřejmě už tehdy existovali zákazníci, kteří používali docela velké stroje. Někteří používali komunitní Postgres s různými vychytávkami, jiní se rozhodli spustit s jedním z různých Postgres forků s dalšími možnostmi (např. masivní paralelismus, distribuované dotazy, použití FPGA atd.). A to samozřejmě ovlivnilo i rozvoj komunity.
Jak se větší stroje v průběhu let staly běžnějšími, více lidí si mohlo dovolit stroje s velkým množstvím paměti RAM a vysokým počtem jader, čímž se posunul poměr cena/přínos. Úzká místa byla prozkoumána a vyřešena, což umožnilo novějším verzím fungovat lépe.
To znamená, že benchmark, jako je tento, je vždy trochu nespravedlivý – upřednostní buď starší nebo novější verzi, v závislosti na nastavení (hardware, konfigurace). Snažil jsem se vybrat parametry hardwaru a konfigurace tak, aby to nebylo příliš špatné pro starší verze.
Pointa, kterou se snažím zdůraznit, je, že to neznamená, že starší verze PostgreSQL byly svinstvo – takhle funguje vývoj softwaru. Řešíte úzká místa, s nimiž se vaši uživatelé pravděpodobně setkají, nikoli úzká místa, na která mohou narazit za 10 let.
Hardware
Raději dělám benchmarky na fyzickém hardwaru, ke kterému mám přímý přístup, protože to mi umožňuje ovládat všechny detaily, mám přístup ke všem detailům a tak dále. Použil jsem tedy stroj, který mám v naší kanceláři – nic přepychového, ale doufejme, že je pro tento účel dost dobrý.
- 2x E5-2620 v4 (16 jader, 32 vláken)
- 64 GB RAM
- Intel Optane 900P 280GB NVMe SSD (data)
- 3 x 7,2 k SATA RAID0 (dočasný tabulkový prostor)
- jádro 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
Použil jsem také druhý – mnohem menší – stroj s pouhými 4 jádry a 8 GB RAM, který obecně vykazuje stejná zlepšení / regrese, jen méně výrazné.
pgbench
Jako benchmarkingový nástroj jsem použil dobře známý pgbench s nejnovější verzí (z PostgreSQL 13) k testování všech verzí. To eliminuje možné zkreslení kvůli optimalizacím prováděným v pgbench v průběhu času, díky čemuž jsou výsledky srovnatelnější.
Benchmark testuje řadu různých případů, které mění řadu parametrů, jmenovitě:
měřítko
- malé – data se vejdou do sdílených vyrovnávacích pamětí, zobrazují se problémy se zamykáním atd.
- střední – data větší než sdílené vyrovnávací paměti, ale vejdou se do paměti RAM, obvykle vázané na CPU (nebo případně I/O pro zátěže čtení a zápisu)
- velké – data větší než RAM, primárně vázaná na I/O
režimy
- pouze pro čtení – pgbench -S
- čtení i zápis – pgbench -N
počet klientů
- 1, 4, 8, 16, 32, 64, 128, 256
- počet vláken pgbench (-j) se odpovídajícím způsobem upraví
Výsledky
Dobře, podívejme se na výsledky. Nejprve představím výsledky z úložiště NVMe a poté ukážu některé zajímavé výsledky pomocí úložiště SATA RAID.
NVMe SSD / pouze pro čtení
Pro malou sadu dat (která se plně vejde do sdílených vyrovnávacích pamětí) vypadají výsledky pouze pro čtení takto:
výsledky pgbench / pouze pro čtení na malém souboru dat (měřítko 100, tj. 1,6 GB)
Je zřejmé, že došlo k výraznému zvýšení propustnosti ve verzi 9.2, která obsahovala řadu vylepšení výkonu, například rychlou cestu pro zamykání. Propustnost pro jednoho klienta ve skutečnosti trochu klesá – ze 47 000 tps na pouhých 42 000 tps. Ale pro vyšší počty klientů je zlepšení v 9.2 celkem jasné.
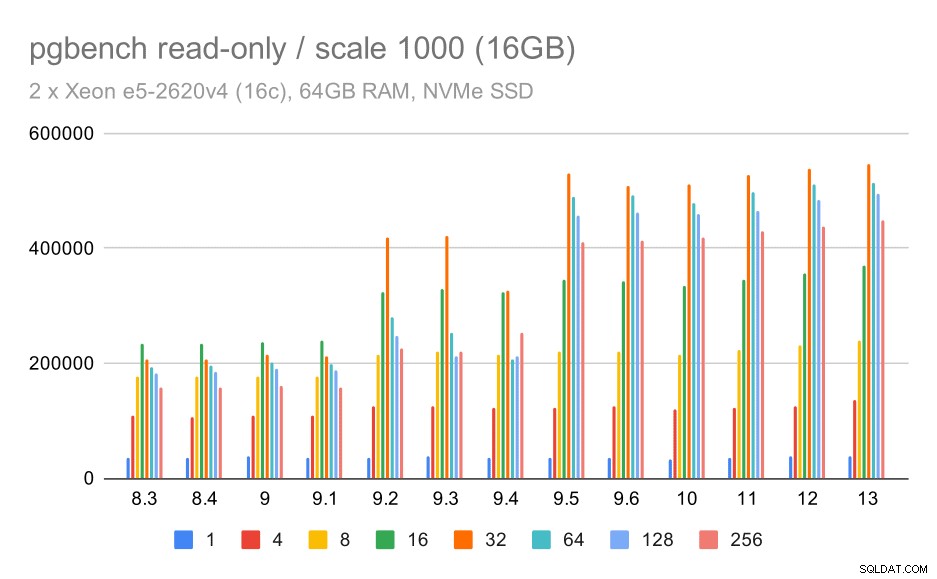
výsledky pgbench / pouze pro čtení na středním datovém souboru (měřítko 1000, tj. 16 GB)
U střední datové sady (která je větší než sdílené vyrovnávací paměti, ale stále se vejde do RAM) se zdá, že také došlo k určitému zlepšení ve verzi 9.2, i když ne tak jasné jako výše, následované mnohem jasnějším vylepšením ve verzi 9.5 s největší pravděpodobností díky vylepšením škálovatelnosti zámků. .
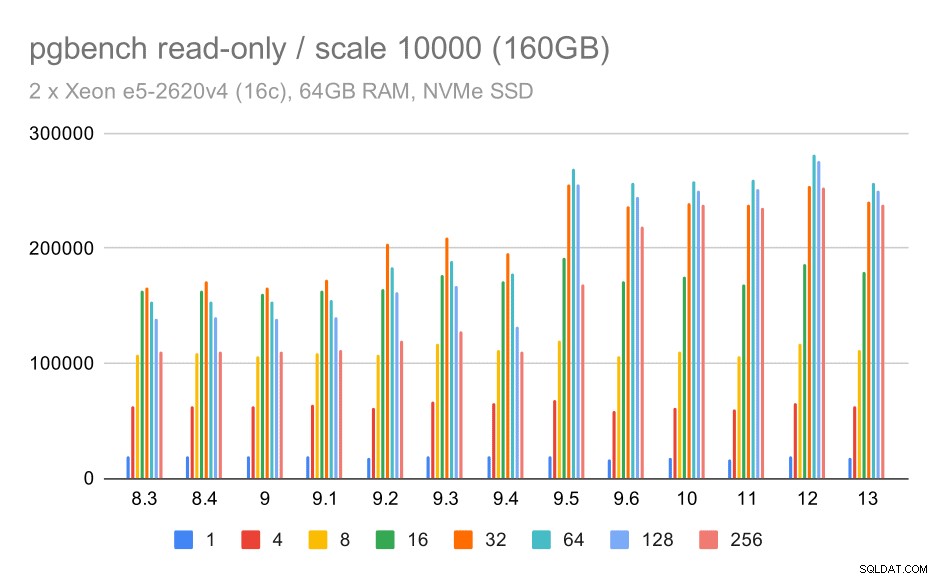
výsledky pgbench / pouze pro čtení na velkém souboru dat (měřítko 10 000, tj. 160 GB)
U největšího souboru dat, který se týká především schopnosti efektivně využívat úložiště, dochází také k určitému zrychlení – pravděpodobně také díky vylepšením 9.5.
NVMe SSD / čtení a zápis
Výsledky čtení a zápisu také vykazují určitá zlepšení, i když ne tak výrazná. Na malém souboru dat vypadají výsledky takto:
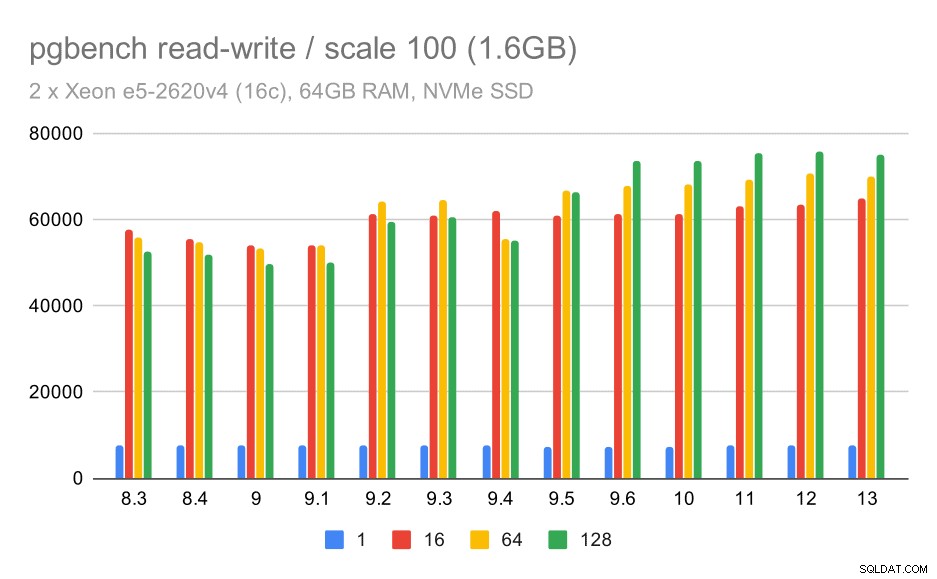
výsledky pgbench / čtení a zápis na malém souboru dat (měřítko 100, tj. 1,6 GB)
Takže mírné zlepšení z asi 52 000 na 75 000 tps s dostatečným počtem klientů.
U středního souboru dat je zlepšení mnohem jasnější – z přibližně 27 000 na 63 000 tps, tj. propustnost se více než zdvojnásobuje.
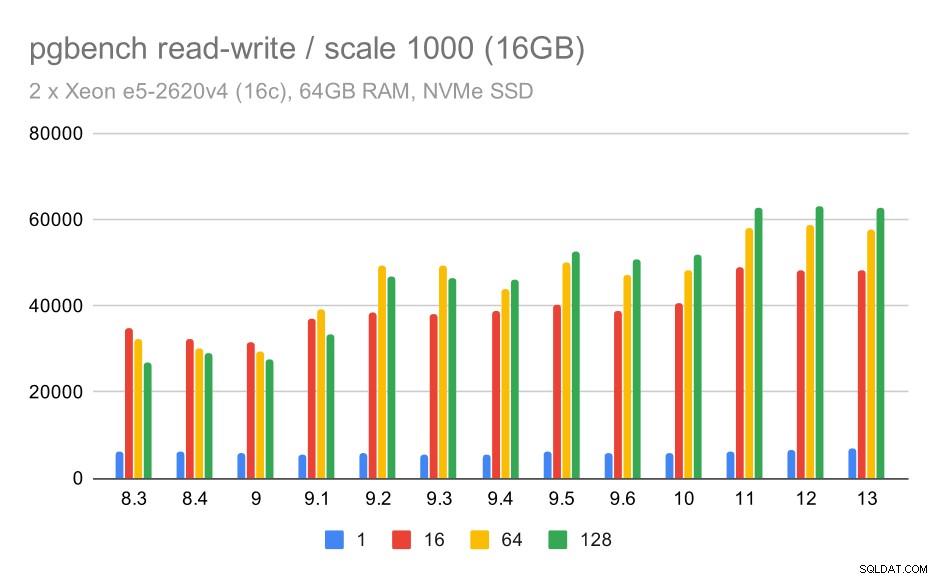
výsledky pgbench / čtení a zápis na střední datovou sadu (měřítko 1000, tj. 16 GB)
U největšího souboru dat vidíme podobné celkové zlepšení, ale zdá se, že došlo k určité regresi mezi 9,5 a 11.
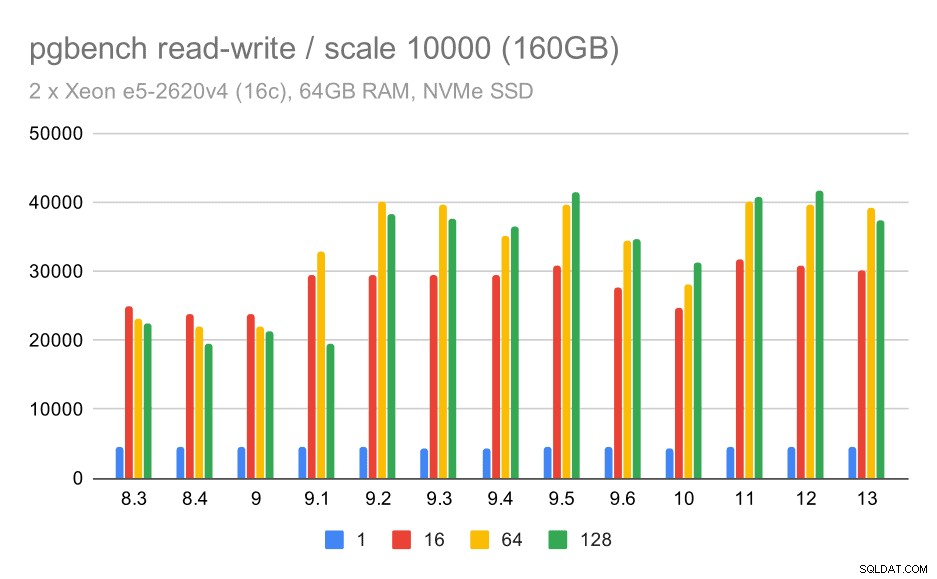
výsledky pgbench / čtení a zápis na velké datové sadě (měřítko 10 000, tj. 160 GB)
SATA RAID / pouze pro čtení
U úložiště SATA RAID nejsou výsledky pouze pro čtení tak pěkné. Můžeme ignorovat malé a střední datové sady, pro které je úložný systém irelevantní. U velkého souboru dat je propustnost poněkud hlučná, ale zdá se, že se časem snižuje – zejména od PostgreSQL 9.6. Nevím, co je toho důvodem (nic v poznámkách k vydání 9.6 nevyčnívá jako jasný kandidát), ale vypadá to jako nějaká regrese.
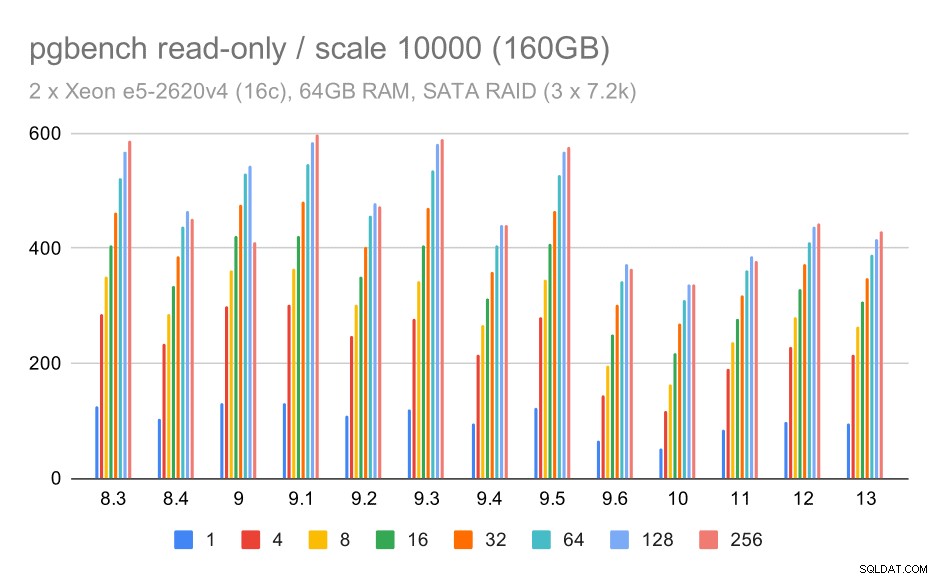
pgbench výsledky na SATA RAID / pouze pro čtení na velké datové sadě (škála 10 000, tj. 160 GB)
SATA RAID / čtení a zápis
Chování čtení a zápisu se však zdá mnohem hezčí. Na malém datovém souboru se propustnost zvyšuje z cca 600 tps na více než 6000 tps. Vsadil bych se, že je to díky vylepšením skupinového odevzdání v 9.1 a 9.2.
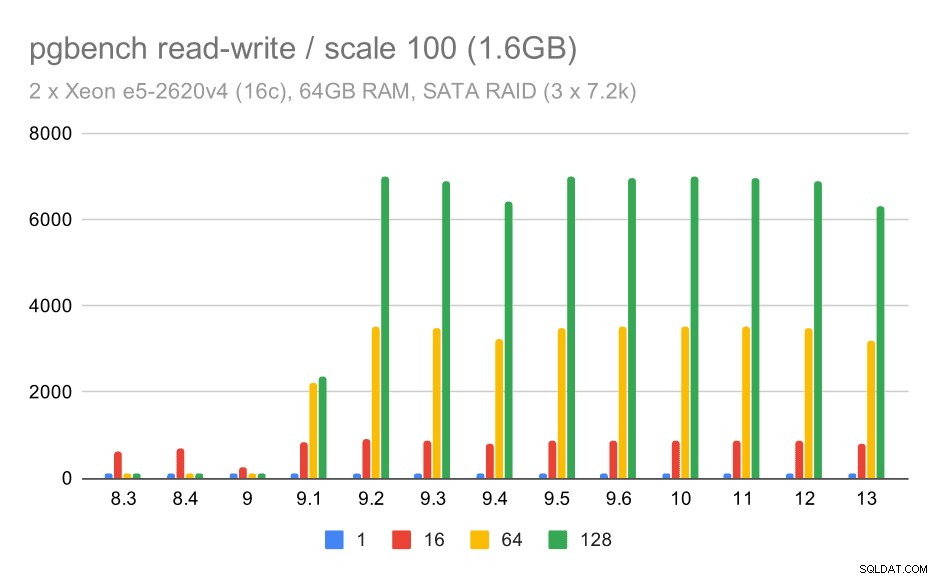
pgbench výsledky na SATA RAID / čtení a zápis na malé datové sadě (měřítko 100, tj. 1,6 GB)
U středních a velkých měřítek můžeme vidět podobná – ale menší – zlepšení, protože úložiště také potřebuje zpracovávat I/O požadavky na čtení a zápis datových bloků. Ve středním měřítku musíme provádět pouze zápisy (jak se data vejdou do paměti RAM), ve velkém měřítku musíme také provádět čtení – takže maximální propustnost je ještě nižší.
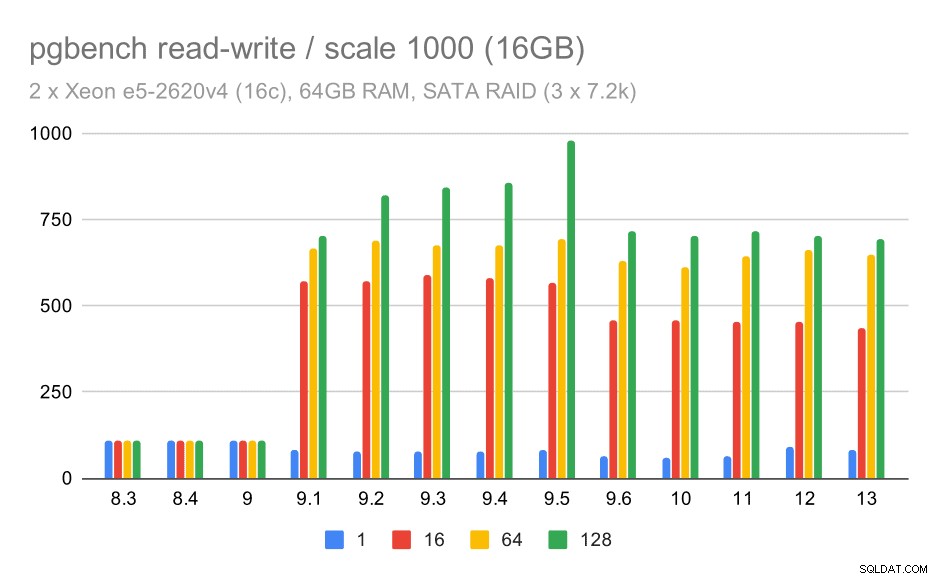
Výsledky pgbench na SATA RAID / čtení a zápis na střední datové sadě (škála 1000, tj. 16 GB)
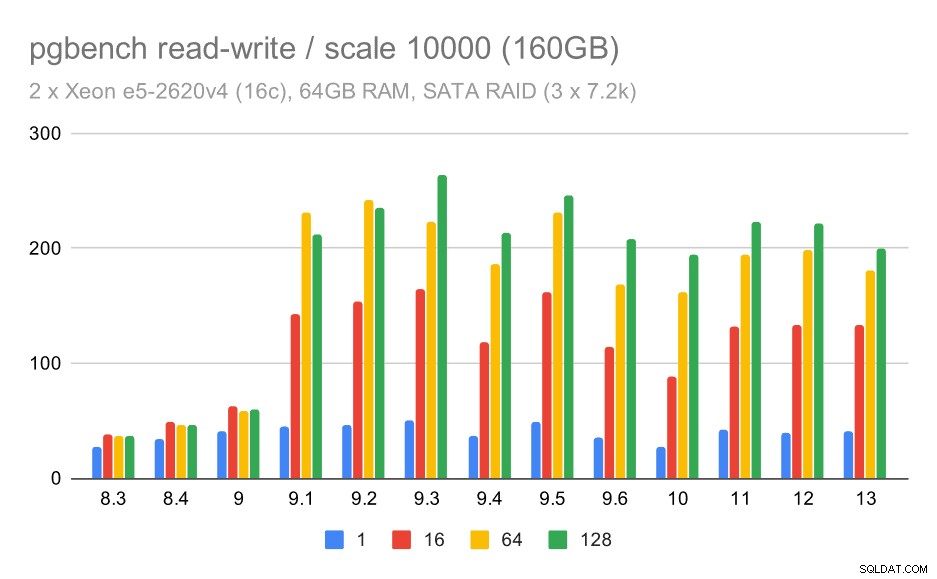
Výsledky pgbench na SATA RAID / čtení a zápis na velké datové sadě (škála 10 000, tj. 160 GB)
Shrnutí a budoucnost
Abych to shrnul, pro nastavení NVMe se závěry zdají být docela pozitivní. U zátěže pouze pro čtení je mírné zrychlení ve verzi 9.2 a výrazné zrychlení ve verzi 9.5 díky optimalizaci škálovatelnosti, zatímco u zátěže pro čtení a zápis se výkon v průběhu času zlepšil asi 2x, a to ve více verzích / krocích.
S nastavením SATA RAID jsou však závěry poněkud smíšené. V případě pracovní zátěže pouze pro čtení existuje velká variabilita / šum a možná regrese v 9.6. Co se týče zátěže čtení a zápisu, došlo ve verzi 9.1 k masivnímu zrychlení, kde se propustnost náhle zvýšila ze 100 tps na přibližně 600 tps.
A co vylepšení v budoucích verzích PostgreSQL? Nemám úplně jasnou představu, jaké bude další velké zlepšení – jsem si však jistý, že ostatní hackeři PostgreSQL přijdou s geniálními nápady, které věci zefektivní nebo umožní využít dostupné hardwarové zdroje. Patch pro zlepšení škálovatelnosti s mnoha připojeními nebo patch pro přidání podpory pro energeticky nezávislé WAL buffery jsou příklady takových vylepšení. Můžeme vidět radikální vylepšení úložiště PostgreSQL (efektivnější formát na disku, použití přímého I/O atd.), indexování atd.