SQL Server 2005 přidal možnost zahrnout neklíčové sloupce do neklastrovaného indexu. V SQL Server 2000 a dřívějších verzích pro neklastrovaný index byly všechny sloupce definované pro index klíčovými sloupci, což znamenalo, že byly součástí každé úrovně indexu, od kořene až po úroveň listu. Když je sloupec definován jako zahrnutý sloupec, je součástí pouze úrovně listu. Books Online si všímá následujících výhod zahrnutých sloupců:
- Mohou to být datové typy, které nejsou povoleny jako sloupce indexového klíče.
- Databázový stroj je nebere v úvahu při výpočtu počtu sloupců indexového klíče nebo velikosti indexového klíče.
Například sloupec varchar(max) nemůže být součástí indexového klíče, ale může to být zahrnutý sloupec. Dále, že sloupec varchar(max) se nezapočítává do limitu 900 bajtů (nebo 16 sloupců) stanoveného pro klíč indexu.
Dokumentace také uvádí následující výhody výkonu:
Index s neklíčovými sloupci může výrazně zlepšit výkon dotazu, když jsou všechny sloupce v dotazu zahrnuty do indexu jako klíčové nebo neklíčové sloupce. Zvýšení výkonu je dosaženo, protože optimalizátor dotazů dokáže najít všechny hodnoty sloupců v indexu; není přístup k tabulkovým nebo seskupeným indexovým datům, což má za následek méně diskových I/O operací.Můžeme odvodit, že bez ohledu na to, zda jsou sloupce indexu klíčové nebo neklíčové sloupce, dosáhneme zlepšení výkonu ve srovnání s případem, kdy všechny sloupce nejsou součástí indexu. Je však mezi těmito dvěma variantami rozdíl ve výkonu?
Nastavení
Nainstaloval jsem kopii databáze AdventuresWork2012 a ověřil jsem indexy pro tabulku Sales.SalesOrderHeader pomocí verze sp_helpindex od Kimberly Tripp:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Výchozí indexy pro Sales.SalesOrderHeader
Začneme přímočarým dotazem pro testování, který načítá data z více sloupců:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Pokud to provedeme proti databázi AdventureWorks2012 pomocí SQL Sentry Plan Explorer a zkontrolujeme plán a výstup tabulky I/O, uvidíme, že dostaneme skenování clusteru indexu s 689 logickými čteními:
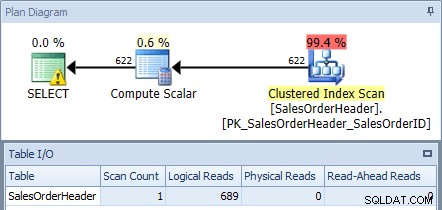
Plán provádění z původního dotazu
(V Management Studio jste mohli vidět I/O metriky pomocí SET STATISTICS IO ON; .)
SELECT má varovnou ikonu, protože optimalizátor doporučuje pro tento dotaz index:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Test 1
Nejprve vytvoříme index, který optimalizátor doporučuje (pojmenovaný NCI1_included), a také variantu se všemi sloupci jako klíčové sloupce (s názvem NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Pokud znovu spustíme původní dotaz, jednou jej naznačíme pomocí NCI1 a jednou jej naznačíme pomocí NCI1_included, uvidíme plán podobný původnímu, ale tentokrát je zde hledání indexu každého neshlukovaného indexu s ekvivalentními hodnotami pro tabulku I/ O a podobné náklady (obě přibližně 0,006):
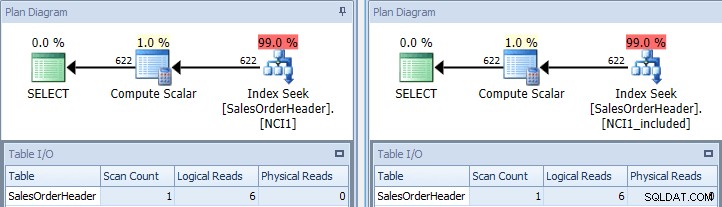
Původní dotaz s hledáním indexu – klíč vlevo, zahrnout vpravo
(Počet skenování je stále 1, protože hledání indexu je ve skutečnosti maskované skenování rozsahu.)
Nyní databáze AdventureWorks2012 nepředstavuje produkční databázi, pokud jde o velikost, a když se podíváme na počet stránek v každém indexu, vidíme, že jsou úplně stejné:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
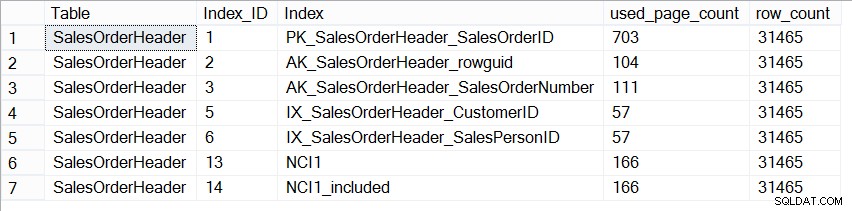
Velikost indexů na Sales.SalesOrderHeader
Pokud se díváme na výkon, je ideální (a zábavnější) testovat s větším souborem dat.
Test 2
Mám kopii databáze AdventureWorks2012, která má tabulku SalesOrderHeader s více než 200 miliony řádků (skript ZDE), takže v této databázi vytvoříme stejné indexy bez klastrů a znovu spustíme dotazy:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
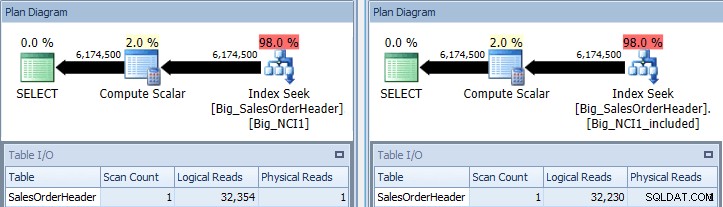
Původní dotaz s indexem hledá proti Big_NCI1 (l) a Big_NCI1_Included ( r)
Nyní získáme nějaká data. Dotaz vrací více než 6 milionů řádků a hledání každého indexu vyžaduje něco málo přes 32 000 čtení a odhadovaná cena je pro oba dotazy stejná (31 233). Zatím žádné rozdíly ve výkonu, a pokud zkontrolujeme velikost indexů, zjistíme, že index se zahrnutými sloupci má o 5 578 stránek méně:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Velikost indexů na Sales.Big_SalesOrderHeader
Pokud se do toho ponoříme mnohem dále a zkontrolujeme dm_dm_index_physical_stats, uvidíme, že existuje rozdíl mezi středními úrovněmi indexu:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
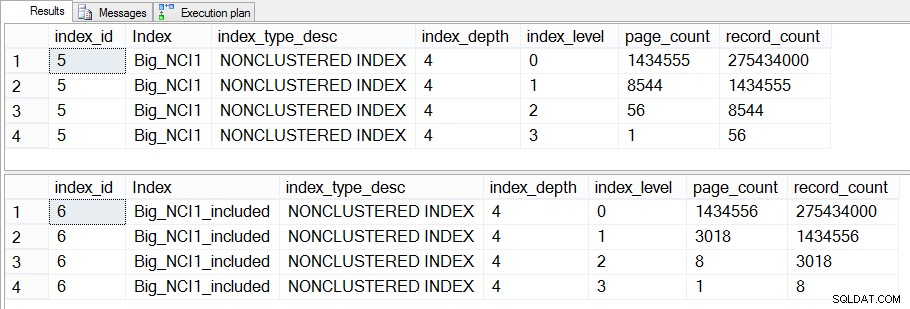
Velikost indexů (podle úrovně) na Sales.Big_SalesOrderHeader
Rozdíl mezi středními úrovněmi obou indexů je 43 MB, což nemusí být podstatné, ale pravděpodobně bych se stále přikláněl k vytvoření indexu se zahrnutými sloupci pro úsporu místa – jak na disku, tak v paměti. Z pohledu dotazu stále nevidíme velkou změnu ve výkonu mezi indexem se všemi sloupci v klíči a indexem se zahrnutými sloupci.
Test 3
Pro tento test změňme dotaz a přidejte filtr pro [SubTotal] >= 100 do klauzule WHERE:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
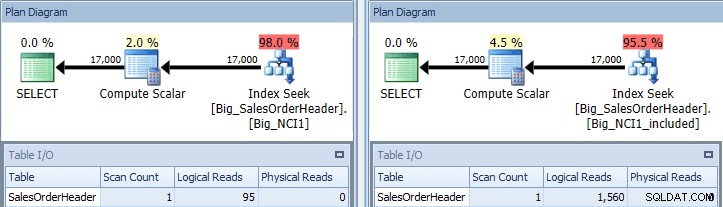
Plán provádění dotazu s predikátem Mezisoučet proti oběma indexům
Nyní vidíme rozdíl v I/O (95 čtení oproti 1 560), ceně (0,848 oproti 1,55) a jemný, ale pozoruhodný rozdíl v plánu dotazů. Při použití indexu se všemi sloupci v klíči je predikát hledání KódZákazníka a Mezisoučet:
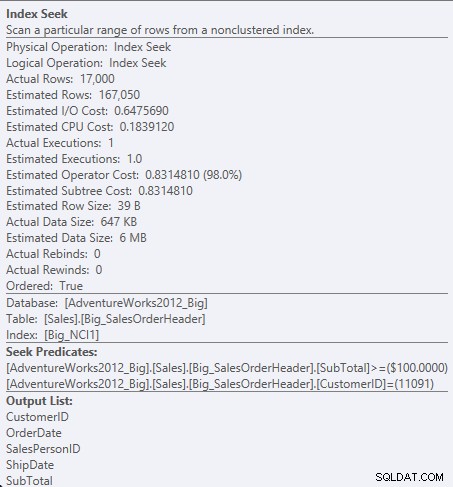
Hledat predikát proti NCI1
Protože mezisoučet je druhý sloupec v klíči indexu, data jsou uspořádána a mezisoučet existuje na středních úrovních indexu. Modul je schopen vyhledat přímo první záznam s CustomerID 11091 a mezisoučet větším nebo rovným 100 a poté číst index, dokud nebudou existovat žádné další záznamy pro CustomerID 11091.
U indexu se zahrnutými sloupci existuje Mezisoučet pouze na úrovni listu indexu, takže KódZákazníka je predikát hledání a Mezisoučet je zbytkový predikát (na snímku obrazovky je uveden pouze jako Predikát):
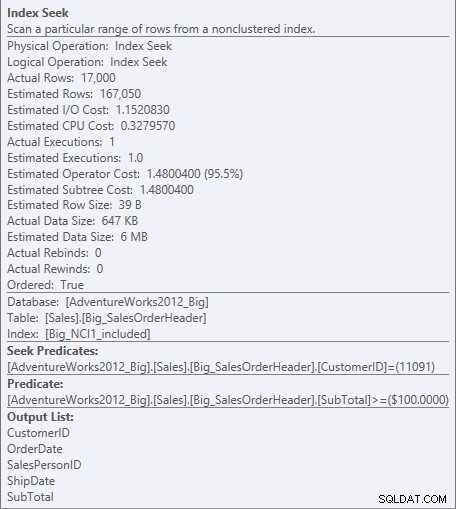
Hledat predikát a zbytkový predikát proti NCI1_included
Modul může vyhledat přímo první záznam, kde je CustomerID 11091, ale pak se musí podívat na každý záznam pro CustomerID 11091, abyste zjistili, zda je mezisoučet 100 nebo vyšší, protože data jsou řazena podle CustomerID a SalesOrderID (klastrovací klíč).
Test 4
Zkusíme ještě jednu variantu našeho dotazu a tentokrát přidáme OBJEDNÁVKU PODLE:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
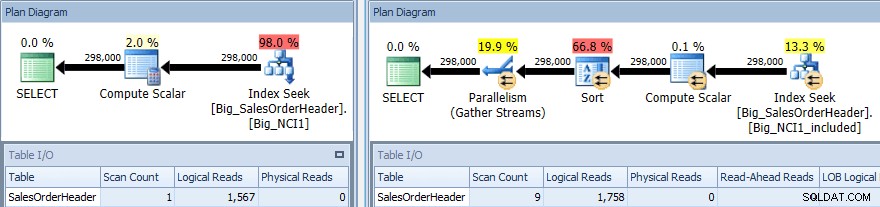
Plán provádění dotazu s SORT proti oběma indexům
Opět máme změnu v I/O (ačkoli velmi nepatrnou), změnu v nákladech (1,5 oproti 9,3) a mnohem větší změnu tvaru plánu; také vidíme větší počet skenů (1 vs 9). Dotaz vyžaduje, aby byla data seřazena podle mezisoučtu; když je mezisoučet součástí indexového klíče, je seřazen, takže když jsou načteny záznamy pro CustomerID 11091, jsou již v požadovaném pořadí.
Když SubTotal existuje jako zahrnutý sloupec, musí být záznamy pro CustomerID 11091 setříděny, než mohou být vráceny uživateli, proto optimalizátor vloží do dotazu operátor Sort. V důsledku toho dotaz, který používá index Big_NCI1_included, také požaduje (a je mu přidělen) přidělení paměti ve výši 29 312 KB, což je pozoruhodné (a nachází se ve vlastnostech plánu).
Shrnutí
Původní otázka, na kterou jsme chtěli odpovědět, byla, zda uvidíme rozdíl ve výkonu, když dotaz použije index se všemi sloupci v klíči, oproti indexu s většinou sloupců zahrnutých na úrovni listu. V naší první sadě testů nebyl žádný rozdíl, ale v našem třetím a čtvrtém testu ano. Nakonec záleží na dotazu. Podívali jsme se pouze na dvě varianty – jedna měla dodatečný predikát, druhá měla ORDER BY – existuje jich mnohem více.
Vývojáři a správci databází musí pochopit, že zahrnutí sloupců do indexu má některé velké výhody, ale ne vždy budou fungovat stejně jako indexy, které mají všechny sloupce v klíči. Může být lákavé přesunout sloupce, které nejsou součástí predikátů a spojení, z klíče a pouze je zahrnout, aby se zmenšila celková velikost indexu. V některých případech to však vyžaduje více prostředků pro provádění dotazu a může to snížit výkon. Degradace může být nevýznamná; nemusí být...nebudete to vědět, dokud nevyzkoušíte. Proto je při navrhování indexu důležité myslet na sloupce za prvním sloupcem – a pochopit, zda musí být součástí klíče (např. protože udržení uspořádaných dat přinese výhody), nebo zda mohou sloužit svému účelu jako zahrnuty. sloupců.
Jak je typické pro indexování na serveru SQL Server, musíte své dotazy otestovat pomocí svých indexů, abyste určili nejlepší strategii. Zůstává uměním a vědou – snažit se najít minimální počet indexů, abychom uspokojili co nejvíce dotazů.