Přemýšlíte o návrhu databáze pro protokolování auditu? Vzpomeňte si, co se stalo Jeníčkovi a Mařence:mysleli si, že zanechání jednoduché stopy ve strouhankách je dobrý způsob, jak sledovat jejich kroky.
Když navrhujeme datový model, jsme vyškoleni, abychom uplatňovali filozofii, že nyní je vše, co existuje . Pokud například navrhujeme schéma pro ukládání cen pro produktový katalog, můžeme si myslet, že databáze nám v současnosti potřebuje sdělit pouze cenu každého produktu. Pokud bychom ale chtěli vědět, zda byly ceny upraveny, a pokud ano, kdy a jak k těmto úpravám došlo, měli bychom problémy. Samozřejmě bychom mohli navrhnout databázi speciálně tak, aby uchovávala chronologický záznam změn – běžně známý jako audit trail nebo audit log.
Protokolování auditu umožňuje databázi mít „paměť“ minulých událostí. Pokračujeme-li s příkladem ceníku, správný protokol auditu nám umožní, aby nám databáze přesně sdělila, kdy byla cena aktualizována, jaká byla cena před aktualizací, kdo ji aktualizoval a odkud.
Řešení protokolování auditu databáze
Bylo by skvělé, kdyby si databáze mohla uchovávat snímek svého stavu pro každou změnu, ke které dojde v jejích datech. Tímto způsobem se můžete vrátit do libovolného bodu v čase a zjistit, jaká data byla v tom přesném okamžiku, jako byste převíjeli film. Ale tento způsob generování protokolování auditu je zjevně nemožný; výsledný objem informací a čas potřebný k vytvoření protokolů by byly příliš vysoké.
Strategie protokolování auditu jsou založeny na generování auditních záznamů pouze pro data, která lze odstranit nebo upravit. Jakákoli změna v nich musí být auditována, aby bylo možné vrátit změny, dotazovat se na data v tabulkách historie nebo sledovat podezřelou aktivitu.
Existuje několik populárních technik protokolování auditu, ale žádná z nich neslouží všem účelům. Ty nejúčinnější jsou často drahé, náročné na zdroje nebo snižují výkon. Jiné jsou levnější, pokud jde o zdroje, ale jsou buď neúplné, těžkopádné na údržbu, nebo vyžadují obětování kvality designu. Jakou strategii zvolíte, bude záviset na požadavcích aplikace a limitech výkonu, zdrojích a principech návrhu, které musíte respektovat.
Předběžná řešení protokolování
Tato řešení protokolování auditu fungují tak, že zachycují všechny příkazy odeslané do databáze a generují protokol změn v samostatném úložišti. Tyto programy nabízejí více možností konfigurace a hlášení pro sledování akcí uživatelů. Mohou protokolovat všechny akce a dotazy odeslané do databáze, i když pocházejí od uživatelů s nejvyššími oprávněními. Tyto nástroje jsou optimalizovány tak, aby minimalizovaly dopad na výkon, ale často je to finančně nákladné.
Cena specializovaných řešení auditních záznamů může být opodstatněná, pokud pracujete s vysoce citlivými informacemi (jako jsou lékařské záznamy), kde jakákoli změna dat musí být dokonale monitorována a auditovatelná a auditní záznam musí být neměnný. Pokud však požadavky na auditní záznamy nejsou tak přísné, mohou být náklady na vyhrazené řešení protokolování příliš vysoké.
Nativní monitorovací nástroje nabízené relačními databázovými systémy (RDBMS) lze také použít ke generování auditních záznamů. Možnosti přizpůsobení umožňují filtrovat, které události se zaznamenávají, aby nedocházelo ke generování zbytečných informací nebo přetěžování databázového stroje operacemi protokolování, které nebudou později použity. Takto generované protokoly umožňují podrobné sledování operací prováděných na tabulkách. Nejsou však užitečné pro dotazování na tabulky historie, protože zaznamenávají pouze události.
Nejekonomičtější možností pro udržování auditní stopy je specificky navrhnout databázi pro protokolování auditu. Tato technika je založena na tabulkách protokolů, které jsou naplněny spouštěči nebo mechanismy specifickými pro aplikaci, která aktualizuje databázi. Neexistuje žádný všeobecně přijímaný přístup k návrhu databáze protokolování auditu, ale existuje několik běžně používaných strategií, z nichž každá má své klady a zápory.
Techniky návrhu protokolování auditu databáze
Verování řádků pro protokolování auditu na místě
Jedním ze způsobů, jak udržovat auditní záznam pro tabulku, je přidat pole, které udává číslo verze každého záznamu. Vložení do tabulky se uloží s počátečním číslem verze. Jakékoli úpravy nebo odstranění se ve skutečnosti stávají operacemi vkládání, kde jsou generovány nové záznamy s aktualizovanými daty a číslo verze je zvýšeno o jedničku. Níže můžete vidět příklad tohoto návrhu protokolování auditu:
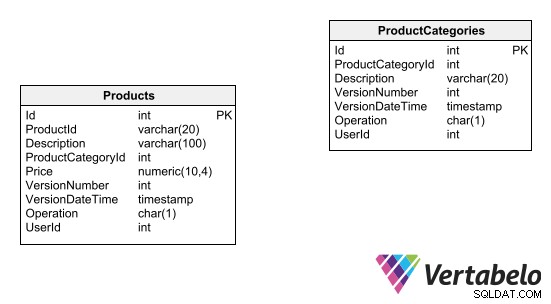
Poznámka:Návrhy tabulek s vloženým verzováním řádků nelze propojit pomocí vztahů cizího klíče.
Kromě čísla verze by měla být do tabulky přidána některá další pole, která určí původ a příčinu každé změny provedené v záznamu:
- Datum/čas, kdy byla změna zaznamenána.
- Uživatel a aplikace.
- Provedená akce (vložení, aktualizace, odstranění) atd. Aby byl auditní záznam účinný, musí tabulka podporovat pouze vkládání (aktualizace a mazání by neměly být povoleny). Tabulka také nutně vyžaduje náhradní primární klíč, protože jakákoli jiná kombinace polí se bude opakovat.
Chcete-li získat přístup k aktualizovaným datům tabulky prostřednictvím dotazů, musíte vytvořit zobrazení, které vrátí pouze nejnovější verzi každého záznamu. Potom musíte nahradit název tabulky názvem pohledu ve všech dotazech kromě dotazů, které jsou konkrétně určeny k zobrazení chronologie záznamů.
Výhodou této možnosti verzování je, že nevyžaduje použití dalších tabulek pro generování auditní stopy. Navíc je do auditovaných tabulek přidáno pouze několik polí. Má to ale obrovskou nevýhodu:donutí vás to udělat některé z nejčastějších chyb návrhu databáze. Mezi ně patří nepoužívat referenční integritu nebo přirozené primární klíče, když je to nutné, což znemožňuje použití základních principů návrhu diagramu entit-vztahů. Můžete navštívit tyto užitečné zdroje o chybách návrhu databáze, takže budete upozorněni na to, jakým dalším postupům byste se měli vyhnout.
Tabulky stínů
Další možností auditního záznamu je vygenerování stínové tabulky pro každou tabulku, kterou je třeba auditovat. Stínové tabulky obsahují stejná pole jako tabulky, které auditují, plus specifická pole auditu (stejná, jaká byla zmíněna pro techniku verzování řádků).
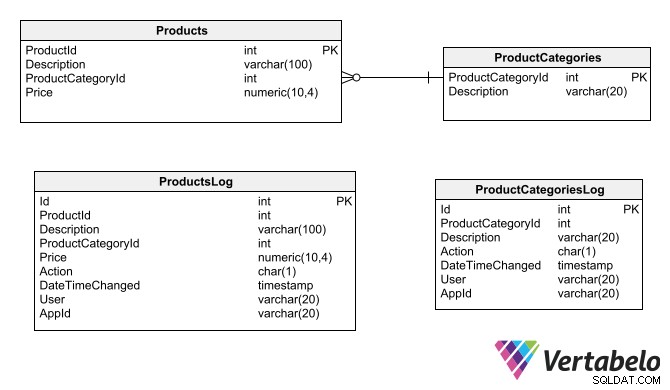
Stínové tabulky replikují stejná pole jako tabulky, které auditují, plus pole specifická pro účely auditu.
Pro generování auditních záznamů ve stínových tabulkách je nejbezpečnější možností vytvořit spouštěče vložení, aktualizace a odstranění, které pro každý dotčený záznam v původní tabulce vygenerují záznam v auditní tabulce. Spouštěče by měly mít přístup ke všem informacím o auditu, které potřebujete zaznamenat do stínové tabulky. K získání dat, jako je aktuální datum a čas, přihlášený uživatel, název aplikace a umístění (síťová adresa nebo název počítače), kde operace vznikla, budete muset použít specifické funkce databázového stroje.
Pokud použití spouštěčů není možné, logika pro generování auditních záznamů by měla být součástí zásobníku aplikací, ve vrstvě ideálně umístěné těsně před vrstvou perzistence dat, aby mohla zachytit všechny operace směřující k databázi.
Tento druh tabulky protokolu by měl umožňovat pouze vkládání záznamů; pokud umožňují úpravu nebo smazání, audit trail by již neplnil svou funkci. Tabulky také musí používat náhradní primární klíče, protože na ně nelze použít závislosti a vztahy původních tabulek.
Pokud tabulka, pro kterou jste vytvořili auditní záznam, obsahuje tabulky, na kterých závisí, měly by mít také odpovídající stínové tabulky. To proto, aby auditní záznam nezůstal osamocený, pokud jsou provedeny změny v jiných tabulkách.
Stínové tabulky jsou vhodné díky své jednoduchosti a protože neovlivňují integritu datového modelu; auditní záznamy zůstávají v samostatných tabulkách a lze je snadno dotazovat. Nevýhodou je, že schéma není flexibilní:jakákoli změna ve struktuře hlavní tabulky se musí projevit v odpovídající stínové tabulce, což ztěžuje údržbu modelu. Navíc, pokud je třeba použít protokolování auditu na velký počet tabulek, počet stínových tabulek bude také vysoký, takže údržba schématu bude ještě těžší.
Obecné tabulky pro protokolování auditu
Třetí možností je vytvořit obecné tabulky pro protokoly auditu. Takové tabulky umožňují protokolování jakékoli jiné tabulky ve schématu. Pro tuto techniku jsou vyžadovány pouze dvě tabulky:
Tabulka záhlaví, která zaznamenává:
- Datum a čas změny.
- Název tabulky.
- Klíč dotčeného řádku.
- Údaje uživatele.
- Typ provedené operace.
Tabulka podrobností, která zaznamenává:
- Názvy jednotlivých dotčených polí.
- Hodnoty polí před úpravou.
- Hodnoty polí po úpravě. (V případě potřeby jej můžete vynechat, protože jej lze získat nahlédnutím do následujícího záznamu v auditní stopě nebo odpovídajícího záznamu v auditované tabulce.)
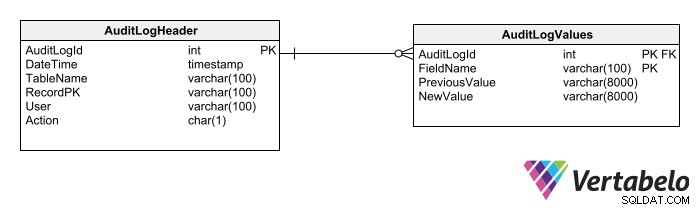
Použití obecných tabulek protokolu auditu omezuje typy dat, která lze auditovat.
Výhodou této strategie protokolování auditu je, že nevyžaduje žádné jiné tabulky než dvě výše uvedené. Také se v něm ukládají záznamy pouze pro pole, která jsou ovlivněna operací. To znamená, že není potřeba replikovat celý řádek tabulky, když je upraveno pouze jedno pole. Kromě toho vám tato technika umožňuje vést protokol o libovolném počtu tabulek – aniž byste schéma zaplnili velkým počtem dalších tabulek.
Nevýhodou je, že pole, která ukládají hodnoty, musí být jednoho typu – a dostatečně široká, aby se do nich vložilo i to největší z polí tabulek, pro které chcete generovat protokol auditu. Nejběžnější je používat pole typu VARCHAR, která přijímají velký počet znaků.
Pokud například potřebujete vygenerovat protokol auditu pro tabulku, která má jedno pole VARCHAR o délce 8 000 znaků, pole, které ukládá hodnoty v tabulce auditu, musí mít také 8 000 znaků. To platí, i když do tohoto pole uložíte pouze jedno celé číslo. Na druhou stranu, pokud vaše tabulka obsahuje pole komplexních datových typů, jako jsou obrázky, binární data, objekty BLOB atd., budete muset serializovat jejich obsah, aby bylo možné je uložit do polí VARCHAR tabulek protokolu.
Vyberte si návrh protokolu auditu databáze moudře
Viděli jsme několik alternativ pro generování protokolování auditu, ale žádná z nich není skutečně optimální. Musíte přijmout strategii protokolování, která podstatně neovlivní výkon vaší databáze, nezpůsobí její nadměrný růst a dokáže splnit vaše požadavky na sledovatelnost. Pokud chcete ukládat protokoly pouze pro několik tabulek, mohou být nejpohodlnější možností stínové tabulky. Pokud chcete flexibilitu pro protokolování jakékoli tabulky, mohou být nejlepší obecné protokolovací tabulky.
Objevili jste jiný způsob, jak vést protokol auditu pro vaše databáze? Sdílejte to v sekci komentářů níže – vaši kolegové návrháři databází vám budou velmi vděční!