Chcete-li do svého datového modelu implementovat podporu více jazyků, nemusíte znovu objevovat kolo. Tento článek vám ukáže různé způsoby, jak toho dosáhnout, a pomůže vám vybrat ten, který vám nejlépe vyhovuje.
Koncept lokalizace je zásadní pro vývoj softwarové aplikace, zejména pokud je rozsah této aplikace globální. Podpora více jazyků je hlavním aspektem, který je třeba zvážit; návrh databáze, který podporuje vícejazyčnou aplikaci, vám umožní diverzifikovat vaše cílové trhy a oslovit tak mnohem více zákazníků. Kromě toho by takový návrh databáze mohl být součástí vaší dlouhodobé strategie pro navrhování systémů připravených na lokalizaci.
Klíčem k začlenění vícejazyčné podpory do vaší aplikace je udělat to způsobem, který drasticky nezvýší náklady na vývoj nebo údržbu. Vzhledem k tomu, že databázové modelování je nedílnou součástí procesu vývoje softwaru, musíte přemýšlet o nejlepší strategii návrhu datového modelu, která vaší aplikaci poskytne vícejazyčnou podporu.
Správný datový model by vám měl umožnit upravit aplikaci nebo přidat nové funkce při zachování vícejazyčné podpory – bez dalšího úsilí nebo nákladů. Mělo by vám také umožnit začlenit nové jazyky, aniž byste se dotkli aplikace; stačí přidat odpovídající data překladu do databáze.
Jednoduchá implementace vs. flexibilita a funkčnost
Existují různé přístupy k vytvoření návrhu databáze pro vícejazyčné aplikace. Každá má své výhody a nevýhody. Ty, které se snadněji implementují, nabízejí menší flexibilitu a méně funkcí; ty, které nabízejí větší flexibilitu a funkčnost, mají složitější implementace.
Moje rada je, abyste vždy vybírali ty, které nabízejí více funkcí a flexibility , i když je jejich realizace nákladnější. Někdy děláme chybu, když si myslíme, že aplikace je příliš malá, že nemá cenu implementovat složitá schémata k řešení věcí, jako je podpora více jazyků. Nakonec se však tato aplikace rozroste a budeme litovat, že jsme se rozhodli pro „rychlý a špinavý“ přístup, který se zdál jednodušší a levnější.
Ideální pro implementaci doplňkových funkcí do aplikace – ať už jde o vícejazyčnou podporu, protokolování změn, autentizaci uživatele nebo něco jiného – je, že tato funkce má své vlastní podschéma a svou logiku zapouzdřenou do opakovaně použitelných komponent. Tímto způsobem lze jak funkcionalitu příslušenství, tak jeho podschéma začlenit do jakékoli nové aplikace s minimálním úsilím.
Inteligentní nástroj pro návrh databází a datové modelování, jako je Vertabelo, je skvělým pomocníkem pro efektivní správu vašich schémat a podschémat. Podívejte se také na tyto tipy pro lepší návrh databáze a ujistěte se, že je všechny dodržujete. Než začnete kreslit svůj ER diagram, navrhuji, abyste zvážili tuto základní řadu tipů pro modelování databáze.
Některá atraktivní (ale nedoporučovaná) řešení návrhu vícejazyčné databáze
Nejjednodušší – ale nejméně doporučené
Začněme nejméně doporučeným, ale nejjednodušším způsobem implementace vícejazyčné aplikační databáze. Umožňuje vám rychle vyřešit potřebu podpory vícejazyčné aplikace, ale přinese vám problémy, když aplikace poroste ve funkčnosti nebo v geografickém pokrytí.
Tato jednoduchá strategie spočívá v přidání dalšího sloupce pro každý sloupec textu, který potřebuje překlad, a pro každý jazyk, do kterého musí být texty přeloženy.
Například v Movies v tabulce níže je OriginalTitle pole. Pro každý jazyk k překladu je přidán další sloupec nadpisu:
| MovieId | OriginalTitle | Title_sp | Title_it | Title_fr |
|---|---|---|---|---|
| 1 | Die Hard | Duro de matar | Trappola di cristallo | Piege de cristal |
| 2 | Zpět do budoucnosti | Volver al futuro | Ritorno al futuro | Retour vers le futur |
| 3 | Jurský park | Parque jurásico | Giurassico parco | Jurský park |
Aplikace musí získat popisná data ze sloupce, který odpovídá jazyku zvolenému uživatelem. Když potřebujete přidat nový jazyk, musíte do tabulky přidat další sloupec, který bude obsahovat texty přeložené do nového jazyka. Musíte také přizpůsobit aplikaci, aby uznala přidaný jazyk a sloupce.
Toto řešení nevyžaduje složité JOINy pro získání přeložených textů ani nevyžaduje duplicitní záznamy – pouze replikaci sloupců obsahu textu. Jeho použitelnost je však omezena na situace, kdy je třeba přeložit pouze několik tabulek.
Předpokládejme například, že máte Products tabulka a Processes stůl. Každý z nich má pole Popis, které vyžaduje překlad; Zdá se to snadné, že? Pokud však celá aplikace (včetně všech možností nabídky, chybových zpráv atd.) musí být vícejazyčná, je toto řešení nepoužitelné.
Všestrannější, ale také nedoporučované
Pokračujeme v myšlence zachování překladů ve stejné tabulce, alternativou k předchozí možnosti je zvětšení textových polí. To by nám umožnilo uložit všechny překlady do stejného pole a uspořádat je do datové struktury (např. dokument XML nebo objekt JSON). Níže uvádíme příklad:
| Id filmu | OriginalTitle | Překlady |
| 1 | Die Hard | [ {"language":"sp", "title":"Duro de matar"}, {"language":"it", "title":"Trappola di cristallo"}, {"language":"fr", "title":"Piège de cristal"} ] |
| 2 | Návrat do budoucnosti | [ {"language":"sp", "title":"Volver al futuro"}, {"language":"it", "title":"Ritorno al futuro"}, {"language":"fr", "title":"Retour vers le futur"} ] |
| 3 | Jurský park | [ {"language":"sp", "title":"Parque jurásico"}, {"language":"it", "title":"Giurassico parco"}, {"language":"fr", "title":"Parc jurassique"} ] |
Tato možnost nevyžaduje další sloupce, ale zvyšuje složitost. Datové dotazy nyní musí být schopny správně zpracovat a interpretovat datovou strukturu používanou pro vícejazyčnou podporu. Pokud se například k ukládání překladů používá JSON nebo XML, musí dotazy SQL používat verzi SQL, která podporuje zvolený typ dat.
Následující příkaz SQL používá MS SQL Server OPENJSON() k použití obsahu Translations pole jako podřízená tabulka:
SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
Protože ve standardním SQL neexistují žádné funkce ani operátory pro manipulaci s daty ve formátu JSON nebo XML, jste nuceni psát své dotazy pro konkrétní RDBMS, pokud chcete použít tuto techniku k ukládání přeložených textů. Například předchozí dotaz není podporován MySQL. Pokud potřebujete číst data JSON v Movies tabulky s MySQL, napsali byste tento dotaz:
SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
Ukládání přeloženého textu do různých záznamů
Můžete si také vybrat použití různých záznamů pro každý jazyk. Musíte se však smířit se ztrátou normalizace:stejná data se opakují v několika záznamech, ve kterých se liší pouze překlad.
| MovieId | LanguageId | Název |
|---|---|---|
| 1 | cs | Die Hard |
| 1 | sp | Duro de matar |
| 1 | to | Trappola di cristallo |
| 1 | fr | Piege de cristal |
| 2 | cs | Zpět do budoucnosti |
| 2 | sp | Volver al futuro |
| 2 | to | Ritorno al futuro |
Pomocí této možnosti můžete vytvořit zobrazení každé tabulky, která vrátí pouze řádky v daném jazyce:
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
K dotazu na tabulku pak můžete použít jiný pohled podle cílového jazyka překladu. Ale normalizace modelu je ztracena a údržba tabulek je zbytečně složitá.
Ukládání přeloženého textu do samostatných tabulek
Jedním ze způsobů, jak uložit přeložené texty bez porušení relačního modelu, je mít tabulku podrobností pro každou tabulku obsahující texty k překladu. Podřízená tabulka obsahující překlady musí mít stejná klíčová pole jako mateřská tabulka plus pole udávající jazyk překladu.
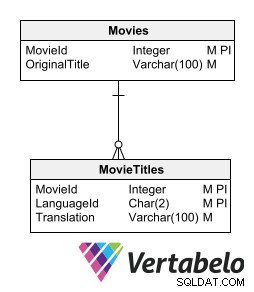
Podřízená tabulka s překlady musí mít stejná klíčová pole jako mateřská tabulka a navíc pole udávající jazyk překladu.
Tato možnost umožňuje začlenění nových jazyků bez změny struktury tabulky. Nevyžaduje generování nadbytečných informací nebo porušení normalizace modelu.
Nevýhodou této možnosti je, že vyžaduje vytvoření podřízené tabulky pro každou tabulku, která ukládá textová data vyžadující překlad. Myšlenka ukládání překladů do souvisejících tabulek nás však přibližuje k nejvhodnějšímu způsobu návrhu vícejazyčné databáze.
Univerzální řešení:Podschéma překladu
Aby aplikace a její databáze byly skutečně vícejazyčné, měly by mít všechny texty překlad do každého podporovaného jazyka – nejen textová data v konkrétní tabulce. Toho je dosaženo pomocí překladového podschéma, kde jsou uložena všechna data s textovým obsahem, která se mohou dostat do očí uživatele.
Ve webových aplikacích určených pro použití v různých jazycích je podschéma překladu nutností, nikoli možností. Cokoli jiného povede ke složitosti, která znemožní řádnou údržbu aplikace.
Klíčem k udržování překladů v samostatném schématu je udržovat indexovaný katalog se všemi texty, které potřebují překlad, ať už se jedná o popisy entit, chybové zprávy nebo možnosti nabídky. Myšlenka je taková, že žádný text, který se dostane do očí uživatele, není uložen v žádné tabulce mimo toto podschéma.
Jedním ze způsobů, jak uspořádat překladový katalog, je použít tři tabulky:
- Přehledná tabulka jazyků.
- Tabulka textů v původním jazyce.
- Tabulka přeložených textů.
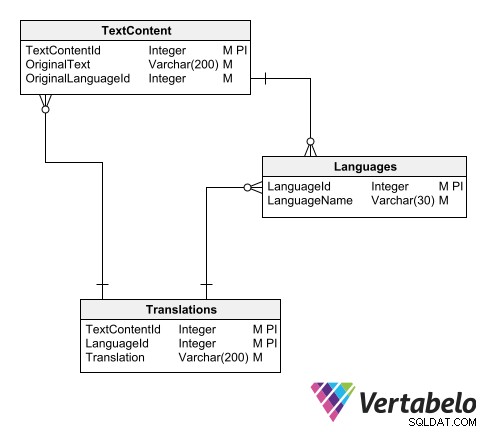
Schéma pro univerzální překladový katalog.
Do hlavní tabulky jazyků jednoduše vložíme záznam pro každý jazyk podporovaný datovým modelem. Každý z nich má ID kód a jméno:
| LanguageId | LanguageName |
|---|---|
| en | Angličtina |
| sp | španělština |
| to | Italština |
| fr | francouzština |
Textová tabulka zaznamenává všechny texty, které vyžadují překlad. Každý záznam má libovolné ID, původní text a ID původního jazyka.
V TextContent tabulka, původní text a ID původního jazyka nejsou nezbytně nutné. Ale zjednodušují dotazy, které nevyžadují překlad. Například při provádění statistických analýz nebo dotazů řízení správy (které jsou obvykle dostupné pouze uživatelům, kteří rozumí původnímu jazyku), lze dotazy zjednodušit použitím výchozích (nepřeložených) textů.
Originální texty jsou užitečné i pro ty, kteří musí vyplnit tabulku přeložených textů. Zadávání dat o překladu lze provést pomocí miniaplikace zobrazující původní text a překlady ve všech dostupných jazycích. Je také možné generovat informace pro podschéma překladu pomocí automatického procesu pomocí překladového API.
Propojení s hlavním schématem
V hlavním schématu aplikace jsou sloupce s textovými hodnotami, které je třeba přeložit, nahrazeny ID, která ukazují na tabulku přeložených textů:
Hlavní schéma je propojeno se schématem překladu prostřednictvím tabulek s texty, které vyžadují překlad.
V některých tabulkách hlavních schémat můžete ponechat původní textové pole, abyste usnadnili dotazy tam, kde překlad není vyžadován, i když to generuje nadbytečné informace. Můžeme si například ponechat ProductDescription v poli Products tabulku pro usnadnění statistických dotazů nebo pro naplnění dimenzí datového skladu, přičemž ponecháme stranou podschéma překladu, když není potřeba.
- Návrh vícejazyčné databáze:Udělejte to jednou a udělejte to správně
Viděli jsme několik alternativ pro vytvoření návrhu vícejazyčné databáze. Některé jsou snadněji a rychleji implementovatelné. Poslední řešení je o něco složitější, ale poskytuje vám mnohem větší flexibilitu. Ušetří vám to také problémy, když přijde čas na údržbu aplikace a databáze. Z dlouhodobého hlediska to tedy bude mnohem levnější.
Někdy vás nejkratší cesta v návrhu databáze svádí k přesvědčení, že ušetříte čas a úsilí. Ale když si ji vyberete, přehlížíte skutečnost, že ji pravděpodobně budete muset několikrát sejít. Pokud ignorujete osvědčené postupy pro návrh vícejazyčných databází, pravděpodobně nakonec budete dělat stejnou práci znovu a znovu.