Možná si myslíte, že údržba databáze není vaše věc. Pokud ale své modely navrhnete proaktivně, získáte databáze, které usnadní život těm, kteří je musí udržovat.
Dobrý návrh databáze vyžaduje proaktivitu, dobře uznávanou kvalitu v jakémkoli pracovním prostředí. V případě, že tento termín neznáte, proaktivita je schopnost předvídat problémy a mít připravená řešení, když se vyskytnou problémy – nebo ještě lépe plánovat a jednat tak, aby k problémům vůbec nedocházelo.
Zaměstnavatelé chápou, že proaktivita jejich zaměstnanců nebo dodavatelů se rovná úsporám nákladů. Proto si toho váží a povzbuzují lidi, aby to praktikovali.
Ve vaší roli datového modeláře je nejlepším způsobem, jak demonstrovat proaktivitu, navrhnout modely, které předvídají problémy, které běžně sužují údržbu databáze, a vyhýbají se jim. Nebo to alespoň podstatně zjednoduší řešení těchto problémů.
I když nejste odpovědní za údržbu databáze, modelování pro snadnou údržbu databáze sklízí mnoho výhod. Zabrání vám například, abyste byli kdykoli vyzváni k řešení nouzových situací souvisejících s daty, které vám ubírají drahocenný čas, který byste mohli strávit úkoly týkajícími se návrhu nebo modelování, které vás tak baví!
Usnadnění života IT borcům
Při navrhování našich databází musíme myslet nad rámec dodání DER a generování aktualizačních skriptů. Jakmile se databáze dostane do výroby, technici údržby se musí vypořádat s nejrůznějšími potenciálními problémy a součástí našeho úkolu jako databázových modelářů je minimalizovat pravděpodobnost, že se tyto problémy vyskytnou.
Začněme tím, že se podíváme na to, co znamená vytvořit dobrý návrh databáze a jak tato činnost souvisí s běžnými úkoly údržby databáze.
Co je datové modelování?
Datové modelování je úkolem vytvořit abstraktní, obvykle grafickou reprezentaci úložiště informací. Cílem datového modelování je odhalit atributy a vztahy mezi entitami, jejichž data jsou uložena v úložišti.
Datové modely jsou postaveny na potřebách obchodního problému. Pravidla a požadavky jsou definovány předem na základě podnětů od obchodních expertů, takže je lze začlenit do návrhu nového úložiště dat nebo upravit v iteraci stávajícího úložiště.
V ideálním případě jsou datové modely živými dokumenty, které se vyvíjejí s měnícími se obchodními potřebami. Hrají důležitou roli při podpoře obchodních rozhodnutí a při plánování architektury a strategie systémů. Datové modely musí být udržovány v synchronizaci s databázemi, které představují, aby byly užitečné pro rutiny údržby těchto databází.
Běžné výzvy údržby databáze
Údržba databáze vyžaduje neustálé monitorování, automatizované nebo jiné, aby se zajistilo, že neztratí své přednosti. Osvědčené postupy údržby databáze zajišťují, že databáze vždy uchovávají:
- Integrita a kvalita informací
- Výkon
- Dostupnost
- Škálovatelnost
- Přizpůsobivost změnám
- Vysledovatelnost
- Zabezpečení
K dispozici je mnoho tipů pro datové modelování, které vám pomohou pokaždé vytvořit dobrý návrh databáze. Níže diskutované cíle se konkrétně zaměřují na zajištění nebo usnadnění údržby výše uvedených kvalit databáze.
Integrita a kvalita informací
Základním cílem osvědčených postupů údržby databáze je zajistit, aby si informace v databázi zachovaly svou integritu. To je zásadní pro to, aby si uživatelé zachovali důvěru v informace.
Existují dva typy integrity:fyzická integrita a logická integrita .
Fyzická integrita
Udržování fyzické integrity databáze se provádí ochranou informací před vnějšími faktory, jako je selhání hardwaru nebo napájení. Nejběžnějším a široce přijímaným přístupem je adekvátní strategie zálohování, která umožňuje obnovu databáze v rozumném čase, pokud ji zničí katastrofa.
Pro správce databází a správce serverů, kteří spravují úložiště databází, je užitečné vědět, zda lze databáze rozdělit do sekcí s různou frekvencí aktualizací. To jim umožňuje optimalizovat využití úložiště a plány zálohování.
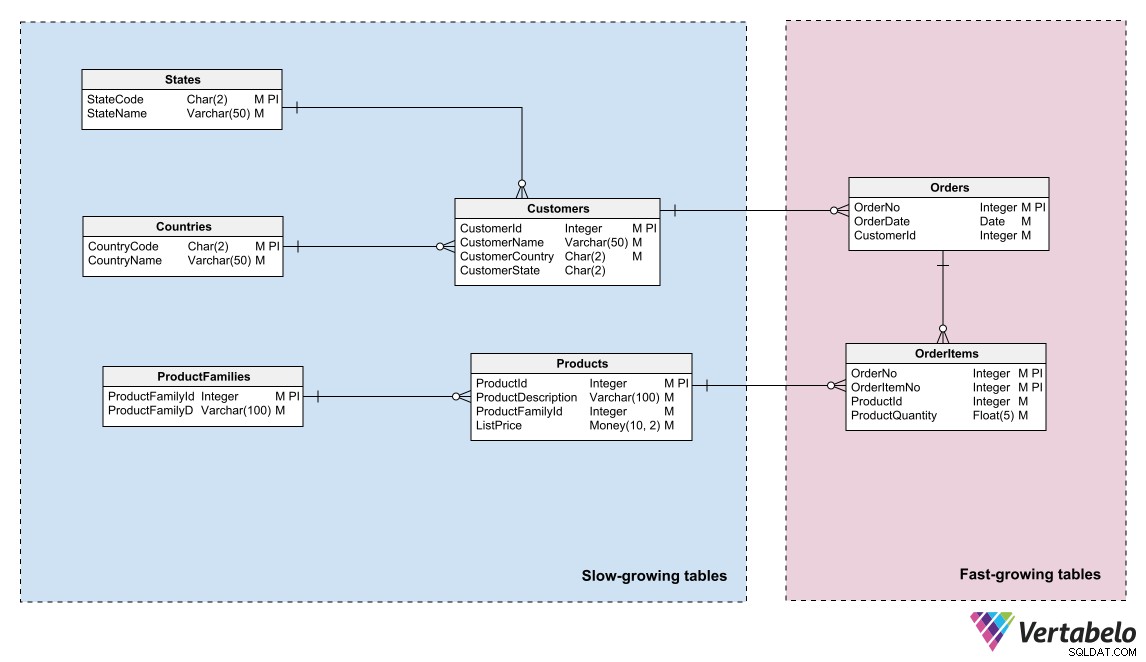
Datové modely mohou toto rozdělení odrážet identifikací oblastí s různou „teplotou“ dat a seskupením entit do těchto oblastí. „Teplota“ označuje frekvenci, s jakou tabulky přijímají nové informace. Tabulky, které jsou aktualizovány velmi často, jsou „nejžhavější“; ty, které nejsou nikdy nebo jen zřídka aktualizovány, jsou „nejchladnější“.

Datový model systému elektronického obchodování rozlišující horká, teplá a studená data.
DBA nebo správce systému může toto logické seskupení použít k rozdělení databázových souborů a vytvoření různých plánů zálohování pro každý oddíl.
Logická integrita
Udržování logické integrity databáze je zásadní pro spolehlivost a užitečnost informací, které poskytuje. Pokud databáze postrádá logickou integritu, aplikace, které ji používají, dříve nebo později odhalí nekonzistence v datech. Tváří v tvář těmto nesrovnalostem uživatelé informacím nedůvěřují a jednoduše hledají spolehlivější zdroje dat.
Mezi úkoly údržby databáze je udržování logické integrity informací rozšířením úlohy modelování databáze, pouze začíná po uvedení databáze do provozu a pokračuje po celou dobu její životnosti. Nejkritičtější částí této oblasti údržby je přizpůsobení se změnám.
Správa změn
Změny v obchodních pravidlech nebo požadavcích jsou neustálou hrozbou pro logickou integritu databází. Můžete být spokojeni s datovým modelem, který jste vytvořili, s vědomím, že je dokonale přizpůsoben podnikání, že odpovídá správnými informacemi na jakýkoli dotaz a že vynechává jakékoli anomálie vkládání, aktualizace nebo mazání. Užijte si tento okamžik uspokojení, protože je krátkodobý!
Údržba databáze zahrnuje nutnost denně provádět změny v modelu. Nutí vás přidávat nové objekty nebo měnit ty stávající, upravovat mohutnost vztahů, předefinovat primární klíče, měnit datové typy a dělat další věci, ze kterých nám modelářům běhá mráz po zádech.
Změny se dějí neustále. Může se stát, že některý požadavek byl od začátku špatně vysvětlen, objevily se nové požadavky nebo jste do svého modelu neúmyslně zavedli nějakou chybu (koneckonců, my datoví modeláři jsme jen lidé).
Vaše modely musí být snadno upravitelné, když vznikne potřeba změn. Pro modelování je zásadní používat nástroj pro návrh databáze, který vám umožní verzovat modely, generovat skripty pro migraci databáze z jedné verze do druhé a řádně dokumentovat každé rozhodnutí o návrhu.
Bez těchto nástrojů každá změna, kterou provedete ve svém návrhu, vytváří rizika integrity, která vyjdou najevo v tu nejméně vhodnou dobu. Vertabelo vám poskytuje všechny tyto funkce a stará se o udržování historie verzí modelu, aniž byste na to museli myslet.
Automatické verzování zabudované do Vertabelo je obrovskou pomocí při udržování změn v datovém modelu.
Správa změn a kontrola verzí jsou také zásadní faktory při začleňování činností modelování dat do životního cyklu vývoje softwaru.
Refaktoring
Když aplikujete změny na používanou databázi, musíte si být 100% jisti, že se neztratí žádné informace a že její integrita není v důsledku změn ovlivněna. K tomu můžete použít techniky refaktorování. Obvykle se používají, když chcete zlepšit návrh, aniž byste ovlivnili jeho sémantiku, ale lze je také použít k opravě chyb návrhu nebo přizpůsobení modelu novým požadavkům.
Existuje velké množství refaktorizačních technik. Obvykle se používají k oživení starších databází a existují učebnicové postupy, které zajišťují, že změny nepoškodí stávající informace. Byly o tom napsány celé knihy; Doporučuji vám je přečíst.
Ale abychom to shrnuli, můžeme techniky refaktoringu seskupit do následujících kategorií:
- Kvalita dat: Provádění změn, které zajistí konzistenci a koherenci dat. Příklady zahrnují přidání vyhledávací tabulky a migraci do ní dat opakovaných v jiné tabulce a přidání omezení na sloupec.
- Strukturální: Provádění změn ve strukturách tabulek, které nemění sémantiku modelu. Příklady zahrnují spojení dvou sloupců do jednoho, přidání náhradního klíče a rozdělení sloupce na dva.
- Referenční integrita: Použití změn, které zajistí, že v související tabulce existuje odkazovaný řádek nebo že lze odstranit neodkazovaný řádek. Příklady zahrnují přidání omezení cizího klíče do sloupce a přidání omezení jiné hodnoty než null do tabulky.
- Architektonické: Provádění změn zaměřených na zlepšení interakce aplikací s databází. Příklady zahrnují vytvoření indexu, vytvoření tabulky pouze pro čtení a zapouzdření jedné nebo více tabulek do pohledu.
Techniky, které modifikují sémantiku modelu, stejně jako ty, které žádným způsobem nemění datový model, nejsou považovány za techniky refaktoringu. Patří mezi ně vkládání řádků do tabulky, přidání nového sloupce, vytvoření nové tabulky nebo pohledu a aktualizace dat v tabulce.
Udržování kvality informací
Kvalita informací v databázi je míra, do jaké data splňují očekávání organizace na přesnost, platnost, úplnost a konzistenci. Udržování kvality dat v průběhu celého životního cyklu databáze je pro její uživatele životně důležité pro přijímání správných a informovaných rozhodnutí pomocí dat v ní obsažených.
Vaší povinností jako modeláře dat je zajistit, aby si vaše modely udržely kvalitu informací na nejvyšší možné úrovni. Chcete-li to provést:
- Návrh musí odpovídat alespoň 3. normální formě, aby nedocházelo k anomáliím při vkládání, aktualizaci nebo mazání. Tato úvaha se týká především databází pro transakční použití, kde jsou data pravidelně přidávána, aktualizována a mazána. Neplatí striktně v databázích pro analytické použití (tj. datových skladech), protože aktualizace a mazání dat se provádí jen zřídka, pokud vůbec.
- Datové typy každého pole v každé tabulce musí odpovídat atributu, který představují v logickém modelu. To jde nad rámec správné definice, zda je pole číselného, datového nebo alfanumerického datového typu. Je také důležité správně definovat rozsah a přesnost hodnot podporovaných každým polem. Příklad:atribut typu Date implementovaný v databázi jako pole Datum/Čas může způsobit problémy v dotazech, protože hodnota uložená s její časovou částí jinou než nula může spadat mimo rozsah dotazu, který používá časové období.
- Dimenze a fakta, která definují strukturu datového skladu, musí odpovídat potřebám podniku. Při návrhu datového skladu musí být již od začátku správně definovány rozměry a fakta modelu. Provádění úprav, jakmile je databáze v provozu, je spojena s velmi vysokými náklady na údržbu.
Řízení růstu
Dalším velkým problémem při údržbě databáze je zabránit tomu, aby její růst neočekávaně dosáhl limitu úložné kapacity. Chcete-li pomoci se správou úložného prostoru, můžete použít stejný princip jako v postupech zálohování:seskupte tabulky ve svém modelu podle rychlosti, s jakou rostou.
Obvykle postačí rozdělení na dvě oblasti. Tabulky s častým přidáváním řádků umístěte do jedné oblasti, ty, do kterých se řádky vkládají jen zřídka, do jiné. Sektorování modelu tímto způsobem umožňuje správcům úložiště rozdělit databázové soubory podle rychlosti růstu každé oblasti. Mohou distribuovat oddíly mezi různá paměťová média s různými kapacitami nebo možnostmi růstu.
Seskupení tabulek podle jejich rychlosti růstu pomáhá určit požadavky na úložiště a řídit jeho růst.
Protokolování
Vytváříme datový model, který očekává, že poskytne informace tak, jak jsou v době dotazu. Máme však tendenci přehlížet potřebu, aby si databáze pamatovala vše, co se stalo v minulosti, pokud to uživatelé výslovně nepožadují.
Součástí údržby databáze je vědět, jak, kdy, proč a kým byla konkrétní část dat změněna. Může se to týkat věcí, jako je zjištění, kdy se změnila cena produktu, nebo kontrola změn v lékařském záznamu pacienta v nemocnici. Protokolování lze použít i k opravě chyb uživatelů nebo aplikací, protože vám umožňuje vrátit stav informací do minulosti, aniž byste se museli uchýlit ke složitým postupům obnovy zálohy.
Opět, i když to uživatelé výslovně nepotřebují, zvážení potřeby proaktivního protokolování je velmi cenným prostředkem pro usnadnění údržby databáze a prokázání vaší schopnosti předvídat problémy. Logování dat umožňuje okamžité reakce, když někdo potřebuje zkontrolovat historické informace.
Existují různé strategie pro databázový model na podporu protokolování, z nichž všechny zvyšují složitost modelu. Jeden přístup se nazývá protokolování na místě, které přidává sloupce do každé tabulky pro záznam informací o verzi. Toto je jednoduchá možnost, která nezahrnuje vytváření samostatných schémat nebo tabulek specifických pro protokolování. Ovlivňuje však návrh modelu, protože původní primární klíče tabulek již nejsou platné jako primární klíče – jejich hodnoty se opakují v řádcích, které představují různé verze stejných dat.
Další možností, jak uchovávat informace protokolu, je použití stínových tabulek. Stínové tabulky jsou repliky modelových tabulek s přidáním sloupců pro záznam dat protokolu. Tato strategie nevyžaduje úpravu tabulek v původním modelu, ale musíte pamatovat na aktualizaci odpovídajících stínových tabulek, když změníte svůj datový model.
Další strategií je využít podschéma generických tabulek, které zaznamenají každé vložení, odstranění nebo úpravu jakékoli jiné tabulky.
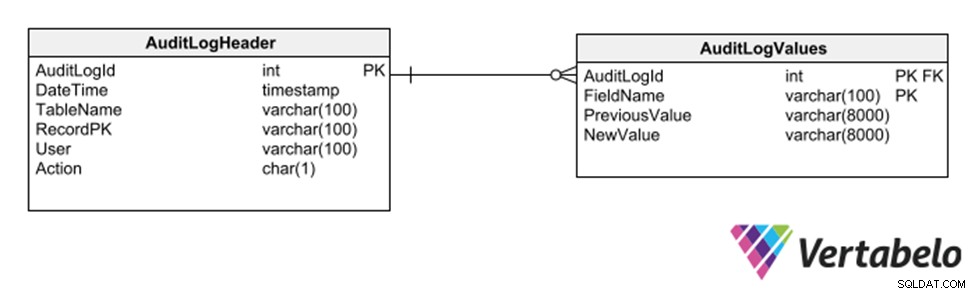
Obecné tabulky pro udržení auditní stopy databáze.
Tato strategie má tu výhodu, že nevyžaduje úpravy modelu pro záznam auditní stopy. Protože však používá obecné sloupce typu varchar, omezuje typy dat, které lze zaznamenat do protokolu.
Údržba výkonu a vytváření indexů
Prakticky každá databáze má dobrý výkon, když se teprve začíná používat a její tabulky obsahují jen několik řádků. Jakmile jej však aplikace začnou zaplňovat daty, výkon se může velmi rychle snížit, pokud při navrhování modelu nebudou přijata opatření. Když k tomu dojde, DBA a správci systému vás požádají, abyste jim pomohli vyřešit problémy s výkonem.
Automatické vytváření/návrhy indexů v produkčních databázích je užitečným nástrojem pro řešení problémů s výkonem „za tepla okamžiku“. Databázové stroje mohou analyzovat databázové aktivity, aby zjistily, které operace trvají nejdéle a kde je možné urychlit vytvářením indexů.
Je však mnohem lepší být proaktivní a předvídat situaci definováním indexů jako součásti datového modelu. To výrazně snižuje nároky na údržbu pro zlepšení výkonu databáze. Pokud nejste obeznámeni s výhodami databázových indexů, doporučuji přečíst si vše o indexech, počínaje úplnými základy.
Existují praktická pravidla, která poskytují dostatečné vodítko pro vytváření nejdůležitějších indexů pro efektivní dotazy. Prvním je generování indexů pro primární klíč každé tabulky. Prakticky každý RDBMS generuje index pro každý primární klíč automaticky, takže na toto pravidlo můžete zapomenout.
Dalším pravidlem je generování indexů pro alternativní klíče tabulky, zejména v tabulkách, pro které je vytvořen náhradní klíč. Pokud má tabulka přirozený klíč, který se nepoužívá jako primární klíč, dotazy ke spojení této tabulky s ostatními tak velmi pravděpodobně provedou pomocí přirozeného klíče, nikoli náhradního. Tyto dotazy nebudou fungovat dobře, pokud nevytvoříte index na přirozeném klíči.
Dalším pravidlem pro indexy je generovat je pro všechna pole, která jsou cizími klíči. Tato pole jsou skvělými kandidáty pro navázání spojení s jinými tabulkami. Pokud jsou zahrnuty v indexech, používají je analyzátory dotazů k urychlení provádění a zlepšení výkonu databáze.
Nakonec je dobré použít profilovací nástroj na pracovní nebo QA databázi během výkonnostních testů k odhalení jakýchkoli příležitostí k vytvoření indexu, které nejsou zřejmé. Začlenění indexů navržených profilovacími nástroji do datového modelu je mimořádně užitečné při dosahování a udržování výkonu databáze, jakmile je ve výrobě.
Zabezpečení
Ve své roli modeláře dat můžete pomoci udržovat zabezpečení databáze tím, že poskytnete solidní a zabezpečenou základnu pro ukládání dat pro ověřování uživatelů. Mějte na paměti, že tyto informace jsou vysoce citlivé a nesmí být vystaveny kybernetickým útokům.
Aby váš návrh zjednodušil údržbu zabezpečení databáze, dodržujte osvědčené postupy pro ukládání autentizačních dat, z nichž hlavní je neukládat hesla do databáze ani v zašifrované podobě. Uložení pouze jeho hash namísto hesla pro každého uživatele umožňuje aplikaci ověřit přihlášení uživatele bez rizika vystavení heslu.
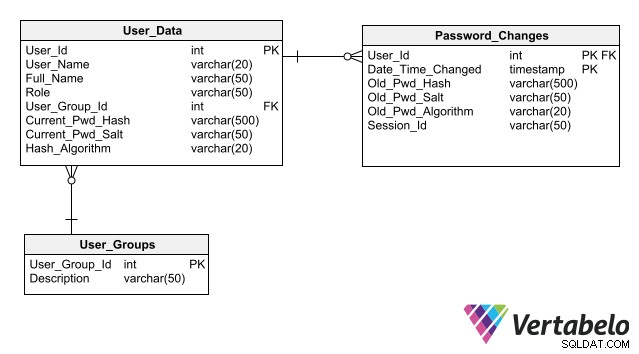
Kompletní schéma pro ověřování uživatelů, které obsahuje sloupce pro ukládání hodnot hash hesel.
Vize budoucnosti
Vytvořte si tedy své modely pro snadnou údržbu databáze s dobrým návrhem databáze, přičemž vezměte v úvahu výše uvedené tipy. S více udržovatelnými datovými modely vypadá vaše práce lépe a získáte uznání správců databází, techniků údržby a systémových administrátorů.
V klidu také investujete. Vytváření snadno udržovatelných databází znamená, že můžete strávit svou pracovní dobu navrhováním nových datových modelů, spíše než běháním po opravách databází, které nedodávají včas správné informace.