Tento článek je druhým ze série o prahových hodnotách optimalizace souvisejících se seskupováním a agregováním dat. V části 1 jsem poskytl reverzně navržený vzorec pro náklady operátora Stream Aggregate. Vysvětlil jsem, že tento operátor potřebuje spotřebovat řádky uspořádané sadou seskupení (jakékoli pořadí jejích členů) a že když jsou data získána předřazená z indexu, získáte lineární škálování s ohledem na počet řádků a počet skupiny. V takovém případě také není potřeba žádné přidělení paměti.
V tomto článku se zaměřím na kalkulaci a škálování operace založené na agregaci streamu, kdy se data nezískávají předobjednaná z indexu, spíše je musí nejprve seřadit.
Ve svých příkladech použiji ukázkovou databázi PerformanceV3, jako v části 1. Zde si můžete stáhnout skript, který vytvoří a naplní tuto databázi. Než spustíte příklady z tohoto článku, ujistěte se, že jste nejprve spustili následující kód, abyste odstranili několik nepotřebných indexů:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Jediné dva indexy, které by v této tabulce měly zůstat, jsou idx_cl_od (seskupeno s orderdate jako klíč) a PK_Orders (nesdružený s orderid jako klíč).
Řadit + agregovat streamování
Cílem tohoto článku je pokusit se zjistit, jak se agregační operace proudu škáluje, když data nejsou předřazena sadou seskupení. Protože operátor Stream Aggregate musí zpracovat objednané řádky, pokud nejsou předřazeny v indexu, plán musí zahrnovat explicitní operátor řazení. Takže náklady na agregovanou operaci, které byste měli vzít v úvahu, jsou součtem nákladů operátorů Sort + Stream Aggregate.
K demonstraci plánu zahrnujícího takovou optimalizaci použiji následující dotaz (nazýváme ho Dotaz 1):
VYBERTE odesílatel, MAX(datum objednávky) AS maxod FROM (VYBRAT TOP (100) * Z dbo.Orders) AS D GROUP BY odesílatele;
Plán pro tento dotaz je znázorněn na obrázku 1.

Obrázek 1:Plán pro dotaz 1
Důvod, proč používám tabulkový výraz s TOP filtrem, je kontrola přesného počtu (odhadovaných) řádků zapojených do seskupování a agregace. Použití řízených změn usnadňuje zkoušení a zpětnou analýzu kalkulačních vzorců.
Pokud vás zajímá, proč v tomto příkladu filtrovat tak malý počet řádků, souvisí to s prahovými hodnotami optimalizace, díky kterým je tato strategie upřednostňována před algoritmem Hash Aggregate. V části 3 popíši kalkulaci a škálování hašovací alternativy. V případech, kdy optimalizátor nezvolí operaci agregace proudu sám, např. když se jedná o velký počet řádků, můžete to vždy vynutit pomocí nápovědy OPTION (SKUPINA OBJEDNÁVEK) během procesu průzkumu. Když se zaměříte na kalkulaci sériových plánů, můžete samozřejmě přidat nápovědu MAXDOP 1, abyste odstranili paralelismus.
Jak již bylo zmíněno, pro vyhodnocení nákladů a škálování nepředobjednaného algoritmu agregace streamů musíte vzít v úvahu součet operátorů Sort + Stream Aggregate. Kalkulační vzorec pro operátor Stream Aggregate již znáte z 1. části:
@numrows * 0,0000006 + @numgroups * 0,0000005V našem dotazu máme 100 odhadovaných vstupních řádků a 5 odhadovaných výstupních skupin (5 různých ID odesílatelů odhadovaných na základě informací o hustotě). Takže náklady na operátora Stream Aggregate v našem plánu jsou:
100 * 0,0000006 + 5 * 0,0000005 =0,0000625Zkusme zjistit kalkulační vzorec pro operátor Sort. Pamatujte, že se zaměřujeme na odhadované náklady a škálování, protože naším konečným cílem je zjistit prahové hodnoty optimalizace, kde optimalizátor mění své volby z jedné strategie na druhou.
Zdá se, že odhad I/O nákladů je pevný:0,0112613. Dostanu stejné I/O náklady bez ohledu na faktory, jako je počet řádků, počet sloupců řazení, typ dat atd. Pravděpodobně je to kvůli předpokládané I/O práci.
Pokud jde o náklady na CPU, Microsoft bohužel veřejně nezveřejňuje přesné algoritmy, které používá pro třídění. Nicméně mezi běžné algoritmy používané pro třídění databázovými stroji obecně patří různé implementace slučovacího třídění a rychlého třídění. Díky úsilí Paula Whitea, který se rád dívá na stopy zásobníku ladicího programu Windows (ne všichni na to máme žaludek), máme o tomto tématu trochu více vhled, publikovaný v jeho sérii „Internals of the Seven SQL Server Třídí." Podle Paulových zjištění používá obecná třída řazení (použitá ve výše uvedeném plánu) slučovací třídění (nejprve interní, poté přechodové na externí). V průměru tento algoritmus vyžaduje n log n porovnání k seřazení n položek. S ohledem na tuto skutečnost je pravděpodobně bezpečná sázka jako výchozí bod předpokládat, že část nákladů operátora na CPU je založena na vzorci, jako je:
Náklady na procesor operátora =Samozřejmě by to mohlo být přílišné zjednodušení skutečného kalkulačního vzorce, který Microsoft používá, ale chybí jakákoli dokumentace k této záležitosti, jedná se o počáteční nejlepší odhad.
Dále můžete získat náklady na CPU třídění ze dvou plánů dotazů vytvořených pro třídění různého počtu řádků, řekněme 1000 a 2000, a na základě těchto a výše uvedeného vzorce zpětně analyzovat srovnávací náklady a spouštěcí náklady. Pro tento účel nemusíte používat seskupený dotaz; stačí provést základní OBJEDNÁVKU BY. Použiji následující dva dotazy (budeme jim říkat Dotaz 2 a Dotaz 3):
SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Smyslem řazení podle výsledku výpočtu je vynutit použití operátoru Sort v plánu.
Obrázek 2 ukazuje příslušné části dvou plánů:
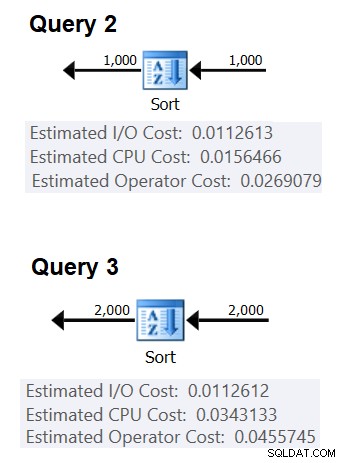
Obrázek 2:Plány pro Dotaz 2 a Dotaz 3
Chcete-li se pokusit odvodit cenu jednoho srovnání, použijte následující vzorec:
srovnávací náklady =
((
/ (
(0,0343133 – 0,0156466) / (2000*LOG(2000) – 1000*LOG(1000)) =2,25061348918698E-06
Pokud jde o počáteční náklady, můžete je odvodit na základě kteréhokoli plánu, např. na základě plánu, který seřadí 2000 řádků:
počáteční náklady =0,0343133 – 2000*LOG(2000) * 2,25061348918698E-06 =9,99127891201865E
Náš vzorec pro třídění nákladů na CPU se tak stává:
Náklady na CPU operátora řazení =9,99127891201865E-05 + @číslo řádků * LOG(@číslo řádků) * 2,25061348918698E-06Při použití podobných technik zjistíte, že faktory jako průměrná velikost řádku, počet sloupců řazení a jejich datové typy neovlivňují odhadované náklady na CPU řazení. Jediný faktor, který se zdá být relevantní, je odhadovaný počet řádků. Všimněte si, že řazení bude vyžadovat přidělení paměti a přidělení je úměrné počtu řádků (nikoli skupin) a průměrné velikosti řádku. V současnosti se však zaměřujeme na odhadované náklady na operátora a zdá se, že tento odhad je ovlivněn pouze odhadovaným počtem řádků.
Zdá se, že tento vzorec předpovídá náklady na CPU až do prahu asi 5 000 řádků. Zkuste to s následujícími čísly:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
SELECT numrows, 9,99127891201865E-05 + numrows * LOG(numrows) * 2,25061348918698E-06 AS predikovaná cena FROM (VALUES(100), (200), (300), (5000), (5000) , (2000), (3000), (4000), (5000)) AS D(čísla);
Porovnejte, co vzorec předpovídá, a odhadované náklady na CPU, které plány ukazují pro následující dotazy:
SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (100) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (200) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (300) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (400) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (3000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (4000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (5000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Mám následující výsledky:
numrows predikovaný poměr odhadovaných nákladů ----------- --------------- ------------- --- ---- 100 0.0011363 0.0011365 1.00018 200 0.0024848 0.0024849 1.00004 300 0.0039510 0.0039511 1.00003 400 0.0054937 0.0054938 1.00002 500 0.0070933 0.0070933 1.00000 1000 0.0156466 0.0156466 1.00000 2000 0.0343133 0.0343133 1.00000 3000 0.0541576 0.0541576 1.00000 4000 0.0747667 0.0747665 1.00000 5000 0.0959445 0.0959442 1.00000
Sloupec předpokládané náklady ukazuje predikci založenou na našem reverzním inženýrství, sloupec odhadované náklady ukazuje odhadované náklady, které se objevují v plánu, a sloupec poměr ukazuje poměr mezi druhými a prvními.
Predikce se zdá docela přesná až do 5 000 řádků. S čísly vyššími než 5 000 však náš reverzně vyvinutý vzorec přestává dobře fungovat. Následující dotaz vám poskytne predikce pro řádky 6K, 7K, 10K, 20K, 100K a 200K:
SELECT numrows, 9,99127891201865E-05 + numrows * LOG(čísla) * 2,25061348918698E-06 AS predikovaná cena FROM (6000), (7000), (00000000), (100000000), (100000000) ) AS D(čísla);
K získání odhadovaných nákladů na CPU z plánů použijte následující dotazy (všimněte si rady pro vynucení sériového plánu, protože s větším počtem řádků je pravděpodobnější, že získáte paralelní plán, kde jsou kalkulační vzorce upraveny pro paralelismus):
SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (6000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (7000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1);
Mám následující výsledky:
numrows predikovaný poměr odhadovaných nákladů ----------- --------------- ------------- --- --- 6000 0.117575 0.160970 1.3691 7000 0.139583 0.244848 1.7541 10000 0.207389 0.603420 2.9096 20000 0.445878 1.311710 2.9419 100000 2.591210 7.623920 2.9422 200000 5.494330 16.165700 2.9423
Jak můžete vidět, za 5 000 řádky se náš vzorec stává stále méně přesným, ale kupodivu se poměr přesnosti ustálí na přibližně 2,94 na přibližně 20 000 řádcích. Z toho vyplývá, že u velkých čísel stále platí náš vzorec, jen s vyšší srovnávací cenou, a že zhruba mezi 5 000 a 20 000 řádky postupně přechází z nižších srovnávacích nákladů na vyšší. Ale co by mohlo vysvětlit rozdíl mezi malým a velkým měřítkem? Dobrou zprávou je, že odpověď není tak složitá jako sladění kvantové mechaniky a obecné teorie relativity s teorií strun. Jde jen o to, že v menším měřítku chtěl Microsoft zohlednit skutečnost, že se pravděpodobně použije mezipaměť CPU, a pro účely kalkulace předpokládají pevnou velikost mezipaměti.
Chcete-li tedy zjistit srovnávací náklady ve velkém měřítku, chcete použít třídění nákladů na CPU ze dvou plánů pro čísla nad 20 000. Použiji 100 000 a 200 000 řádků (poslední dva řádky v tabulce výše). Zde je vzorec pro odvození srovnávacích nákladů:
srovnávací náklady =(16,1657 – 7,62392) / (200000*LOG(200000) – 100000*LOG(100000)) =6,62193536908588E-06
Dále je zde vzorec pro odvození počátečních nákladů na základě plánu pro 200 000 řádků:
počáteční náklady =16,1657 – 200000*LOG(200000) * 6,62193536908588E-06 =1,35166186417734E-04
Velmi dobře se může stát, že počáteční náklady pro malé a velké měřítko jsou stejné a že rozdíl, který jsme dostali, je způsoben chybami zaokrouhlování. V každém případě, s velkým počtem řádků se počáteční náklady stávají zanedbatelnými ve srovnání s náklady na srovnání.
Stručně řečeno, zde je vzorec pro cenu CPU operátora řazení pro velká čísla (>=20000):
Náklady na procesor operátora =1,35166186417734E-04 + @číslo řádků * LOG(@číslo řádků) * 6,62193536908588E-06Pojďme otestovat přesnost vzorce s řádky 500K, 1M a 10M. Následující kód vám poskytuje predikce našeho vzorce:
SELECT numrows, 1,35166186417734E-04 + numrows * LOG(čísla) * 6,62193536908588E-06 AS predikovaná cena FROM (VALUES(500000), (10000000), (10000000), (10000000), (10000000), (10000000), (10000000)K získání odhadovaných nákladů na CPU použijte následující dotazy:
SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECT orderid % 1000000000 jako myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); VYBERTE KONTROLNÍ SOUČET(NEWID()) jako myorderid FROM (SELECT TOP (10000000) O1.orderid FROM dbo.Orders AS O1 CROSS JOIN dbo.Orders AS O2) AS D ORDER BY myorderid OPTION(MAXDOP 1);Mám následující výsledky:
numrows predikovaný poměr odhadovaných nákladů ----------- --------------- ------------- --- --- 500000 43,4479 43,448 1,0000 1000000 91,4856 91,486 1,0000 10000000 1067,3300 1067,340 1,0000Zdá se, že náš vzorec pro velká čísla funguje docela dobře.
Dáme vše dohromady
Celkové náklady na použití agregace proudu s explicitním řazením pro malý počet řádků (<=5 000 řádků) jsou:
+ + =
0,0112613
+ 9,99127891201865E-05 + @numrows * LOG(@ numrows) * 2,25061348918698E-06
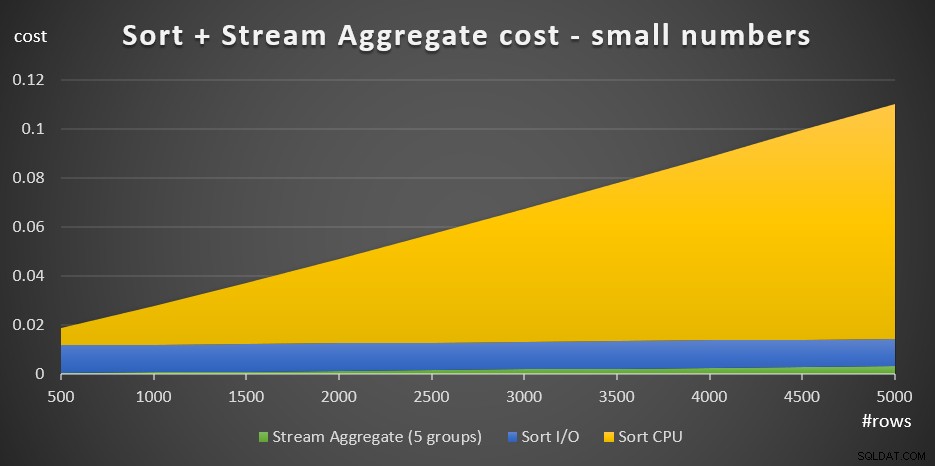
+ @numrows * 0,0000006 + @numgroups * 0,0000005Obrázek 3 obsahuje plošný graf znázorňující, jak se tyto náklady mění.
Obrázek 3:Náklady na třídění + agregace streamů pro malé počty řádkyNáklady na CPU třídění jsou nejpodstatnější částí celkových nákladů na třídění + stream. Přesto při malém počtu řádků nejsou náklady Stream Aggregate a Sort I/O část nákladů zcela zanedbatelné. Z vizuálního hlediska můžete v grafu jasně vidět všechny tři části.
U velkého počtu řádků (>=20 000) je kalkulační vzorec:
0,0112613
+ 1,35166186417734E-04 + @numrows * LOG(@numrows) * 6,62193536908588E-06
@num + @numrows *00 06 + 0,0 skupina 0,0Neviděl jsem velkou hodnotu ve sledování přesného způsobu přechodu srovnávacích nákladů z malého do velkého měřítka.
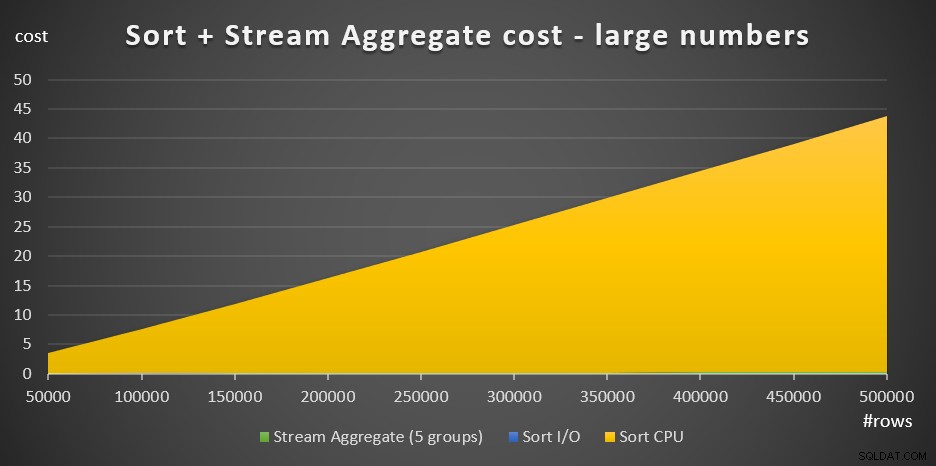
Obrázek 4 obsahuje plošný graf znázorňující, jak se měří náklady pro velká čísla.
Obrázek 4:Náklady na třídění + agregace streamů pro velký počet řádkyPři velkém počtu řádků jsou náklady Stream Aggregate a Sort I/O náklady tak zanedbatelné ve srovnání s náklady Sort CPU, že nejsou v grafu ani viditelné pouhým okem. Kromě toho je také zanedbatelná část nákladů na CPU třídění připisovaná práci při spuštění. Proto jediná část kalkulace nákladů, která má skutečně smysl, jsou celkové srovnávací náklady:
@počet řádků * LOG(@počet řádků) *To znamená, že když potřebujete vyhodnotit škálování strategie Sort + Stream Aggregate, můžete ji zjednodušit pouze na tuto dominantní část. Pokud například potřebujete vyhodnotit, jak by se náklady škálovaly od 100 000 řádků do 100 000 000 řádků, můžete použít vzorec (všimněte si, že srovnávací náklady jsou irelevantní):
(100000000 * LOG(100000000)*) / (100 000 * LOG(100 000)*) =1600To vám říká, že když se počet řádků zvýší ze 100 000 faktorem 1 000 na 100 000 000, odhadované náklady se zvýší faktorem 1 600.
Měřítko od 1 000 000 do 1 000 000 000 řádků se vypočítá takto:
(1000000000 * LOG(1000000000)) / (1000000 * LOG(1000000)) =1500To znamená, že když se počet řádků zvýší z 1 000 000 1 000, odhadované náklady se zvýší 1 500.
Toto jsou zajímavé postřehy o způsobu, jakým se strategie Sort + Stream Aggregate škáluje. Vzhledem k velmi nízkým počátečním nákladům a extra lineárnímu škálování byste očekávali, že tato strategie bude fungovat dobře s velmi malým počtem řádků, ale ne tak dobře s velkými počty. Také skutečnost, že samotný operátor Stream Aggregate představuje tak malý zlomek nákladů ve srovnání s tím, kdy je potřeba také řazení, vám říká, že můžete dosáhnout výrazně lepšího výkonu, pokud je situace taková, že jste schopni vytvořit podpůrný index. .
V další části série se budu věnovat škálování algoritmu Hash Aggregate. Pokud vás baví toto cvičení, kdy se snažíte přijít na kalkulační vzorce, zjistěte, zda to dokážete vyřešit pro tento algoritmus. Důležité je zjistit faktory, které to ovlivňují, způsob, jakým se škáluje, a podmínky, kdy se mu daří lépe než ostatní algoritmy.